Endeca text enrichment. Entities extraction, sentiment analysis, and text tagging with Lexalytics customer defined lists. I love this one!
One of the interesting options of Endeca is its integration with text mining software Lexalytics (licensed separately). Lexalytics offers many text analysis functions such as sentiment analysis, document collection analysis, named entity extraction, theme and context extraction, summarization, document classification etc. Endeca exposes some of this functionality via its text enrichment component in Clover ETL. It is worthwhile noting that not all of the text analytics functionality is exposed via text enrichment and of those features that are exposed only a limited number of methods of the Lexalytics API are exposed (more on that later). A great way of learning more about Lexalytics is to visit their website, Wiki, and blog. I will post some more stuff on text analytics and Lexalytics in particular in one of my next posts.
Text tagging with Lexalytics
In my last post on Endeca we were using the text tagger component to tag a list of 16K Irish IT job records with 30K skills extracted from LinkedIn. If you remember we saw some dreadful performance and also realised that the text tagger component is not multi-threaded and maxed out at 25% on a quad-core CPU. The text enrichment component also offers text tagging and based on the documentation is also multi-threaded. So my expectation is that the tagging process is a lot quicker. Apart from the skills tagging exercise we will also perform some entity extraction on the jobs data and focus on People, Companies, and Products.
In a first step we download Lexalytics from edelivery.

We then add the license file that comes with the download to the Lexalytics root directory. In my case E:Program Files (x86)Lexalytics

We then add the salience.properties file to our project. This configuration file sets the various properties that we can make us of, e.g which types of entities we want to extract. As you can see from the screenshot below we will extract entities of type Person, Company, Product, and List. The interesting entity is the List entity. Through the List entity we can specify our own custom lists to the Lexalytics Salience engine.

Custom lists are made available to Lexalytics in the E:Program Files (x86)Lexalyticsdatausersalienceentitieslists folder as a tab separated Customer Defined List file, which contains various values and a label separated by Tab.
One big shortcoming of the Endeca text enrichment component is that it does not extract the label that can be defined in the customer defined list, e.g. The following entry has the tab separated label of Business Intelligence. The text enrichment component does not extract this even though this is exposed by the Lexalytics API. This also means that you can only define one customer defined list per text enrichment batch, as all of your CDLs will be dumped into the List field.
OBIEE, Cognos, Micro Strategy Busines Intelligence
Anyway, below is our tab separated custom list

Next we add the location of the Lexalytics license file and the data folder as variables to our project workspace parameter file.

As in the previous post we read the scraped data of Irish IT jobs from a MySQL database. The number now stands at 21K. The data flow is a lot simpler than what we had to do with the text tagger.

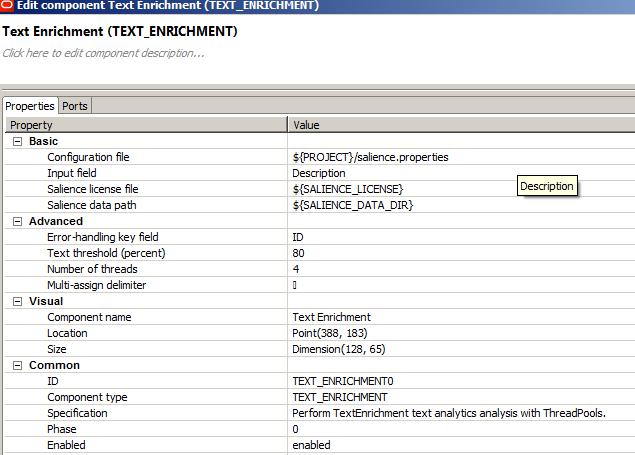
We are now ready to configure our text enrichment component. It’s all pretty straightforward. We supply:
Configuration file: This is the path to the salience properties file
Input file: This is the field in our recordset that we want to extract entities from and use for tagging.
Salience license file: Path to Lexalytics license file
Salience data path: Path to Lexalytics data folder
Number of threads: Hoooraaaay! This component is multi-threaded. During my test runs it used 1 core and maxed out at 25% CPU for 1 thread, 2 cores and maxed out at 50% CPU for 2 threads and so on.
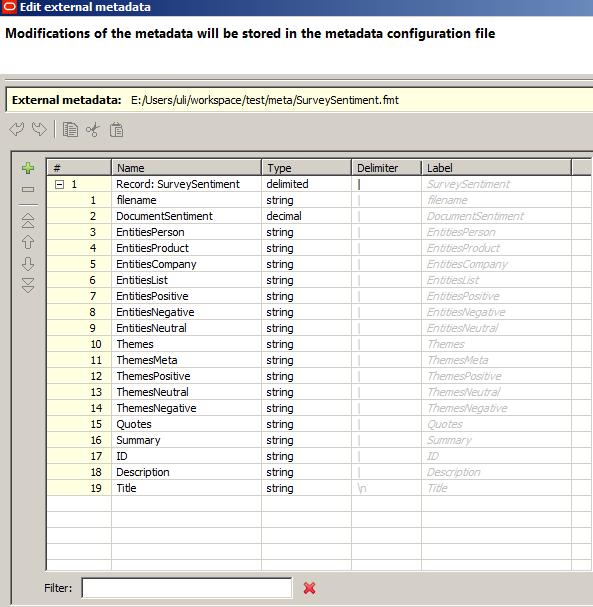
In a last step we have to define the metadata and add it to the edge of the graph.
We are now ready to run the graph. If you read my last post on text tagging you will remember that tagging with the text tagger component took a whopping 12 hours to tag 16K records against 30K skills. With the text enrichment component it took 20 minutes to tag 21K records and on top of that we also extracted Person, Product, and Company entities and did a bit of sentiment analysis as well.
Here are some of the results

Conclusion
[list_square] [li]If you have Lexalytics licensed as part of your Endeca install use it for text tagging rather than the Text Tagger component, which is pretty…, well, lame.[/li] [li]Unlike the Text Tagger component the Text Enrichment component (thanks to the underlying Lexalytics salience engine) is fine piece of software engineering. Unlike the text tagger it is multi-threaded and increasing the number of threads to 4 increased my CPU usage to 100%. It processes the incoming records in batches and it was a joy to watch how it cleared out the memory properly after each batch.[/li] [li]The text enrichment component only exposes a subset of the Lexalytics functionality. If you want to make use of the full potential of the Salience engine you need to write your own custom code.[/li][li]The text enrichment component offers a lot of room for improvement (1) It does not expose the full feature set of Lexalytics (2) The implementation of CDLs should include Label extraction. If you want to make use of the full Lexalytics functionality you would need to write a bit of custom code, which looks pretty straightforward to me.[/li] [/list_check]
In the next posts we will load the data into the MDEX engine and start our discovery process. I wonder what we will find out???