Using ODI user functions to dynamically inject SQL into Interfaces
Get our e-books Discover the Oracle Data Integrator 11g Repository Data Model and Oracle Data Integrator Snippets and Recipes
I’d like to share with you a recipe that demonstrates the power which the combination of ODI functions and Java BeanShell scripting techniques can provide.
Before I do so I will briefly describe the issue we recently had as a background for the use case.
Doesn’t matter which programming language or tool you use, it’s a widely known good practice not to hardcode static values into your code.
I’m talking here about various ‘configuration’ like values used within the code itself: thresholds, whitelists, blacklists, capex values etc..
During the code development phase those may very well seem static but later when product has gone live it is often required to adjust them which may even result in a hotfix case in the worst scenario.
To prevent it the values can be provided in many alternative ways including registry, ini and XML files or just anything sourced from network connection.
The ODI is no exception here and the generic purpose parameter table seem like the natural way to handle such situations.
[big_data_promotion]
The problem may occur when such value is to be used in an ODI interface directly.
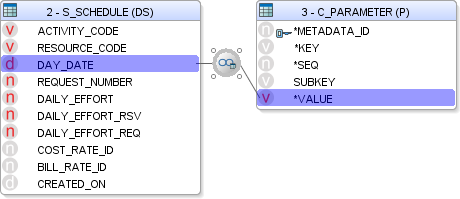
In the case we had the large table had to be filtered using such metadata stored parameter.
One way to do this would be to pull in that table directly into the interface.
It could be then used in the join:
Unfortunately, as would really expect, the join condition:
DS.DAY_DATE>to_date(P.VALUE,‘YYYY-MM-DD’) AND KEY=‘LAST_PROGRESS_DATE’
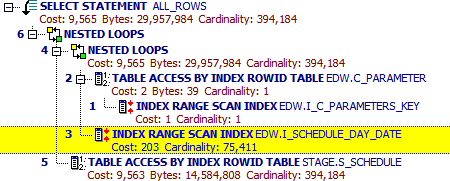
doesn’t make a great query execution plan:
What we can alternatively do is to pass it as a regular filter in the SUBQUERY form:
DS.DAY_DATE > (SELECT to_date(value,‘YYYY-MM-DD’) FROM EDW.C_PARAMETER m WHERE KEY=‘LAST_PROGRESS_DATE’)
It doesn’t improve it a bit. Still the INDEX RANGE SCAN is performed.
Both queries take between 40minutes to 1hour.
I can almost hear you shouting “Why don’t you use an ODI variable for it?” and you’re damn right, this would solve the problem.
When static value is used the query filter
DS.DAY_DATE > #V_LAST_PROGRESS_DATE
changes the plan to simply do the FULL TABLE scan which it should do in the first place;

Using an ODI variable however has also some downsides.
Each parameter introduces an overhead of dedicated ODI variable. This in practice translates to wrapping interface in the Package with separate declaration and separate refresh step.
Very often such parameters would use the same source for it but it still requires separate refresh definition. What I have in mind here is the elegant solution seen in OBIEE where variables are just different columns which can then share the same execution block.
Another thing is that with the complex logic the number of parameters usually grows fast which simply makes it difficult to manage.
Last but not least is the fact that it makes debugging difficult. Variables by default are not seen in the operator.
This can make it even harder to find out what’s happened on Production at some point in time when log is the only thing you left with.
I said ‘by default’ as there are ways to achive it. Prior to ODI version 11.1.1.6 the variable could be only printed using tricks like throwing and ignoring exceptions or switching history for variable, neither one elegant. From that version onwards there’s variable tracking feature but again as this requires running code with log level higher than 6 something not enabled by default, especially in production environment.
It turns out that with a bit of Java BeanShell scripting such parameter values can be sourced in a run-time from the database and substituted in the right place just before the query runs.
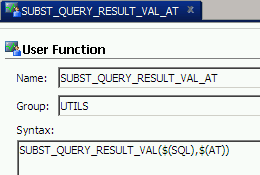
To make the code reusable we will wrap the Java BeanShell code into the function with the syntax defined as
DS.DAY_DATE > #V_LAST_PROGRESS_DATE
The first parameter $(SQL) would just specify a full text of the query to return the parameter value. This is the equivalent of ODI Variable refresh SQL text.
The second one, $(AT) would specify which connection that refresh statement should be executed at. It should only take the values either “DEST”, “SRC” or “WORKREP”. Yes, it’s possible to get runtime repository values too!
The “SRC” might be very useful when “Command on Source/Command on Target” is used or simply when some different than Target schema is to be used for getting parameter value.
The implementation goes as following:
<?
java.sql.Connection targConnection = odiRef.getJDBCConnection(“$(AT)”);
java.sql.Statement s = targConnection.createStatement();
String query=“$(SQL)”;
java.sql.ResultSet rs = s.executeQuery(query);
if (rs.next())
out.println(rs.getString(1));
else
throw new Exception(“Query “+query+” in UDF failed.”);
s.close();
?>
Now the name for our function. As you can see from the screenshot above, it is different from the one in the syntax.
I didn’t mention it before but this is where another trick comes in.
We can actually make the second function parameter optional.
While this is directly possible in many programming languages it’s not in ODI and what we need to do here instead is to leverage another paradigm taken from programming world called function overloading.
This will be achieved by creating another function that takes one parameter and executes the original one passing it and hardcoding the second one.
The name used in the syntax for both will be the same but the syntax itself will be obviously different:
| ODI function name | ODI function syntax | implementation |
|---|---|---|
| SUBST_QUERY_RESULT_VAL_AT | SUBST_QUERY_RESULT_VAL($(SQL),$(AT)) | does the heavy lifting |
| SUBST_QUERY_RESULT_VAL | SUBST_QUERY_RESULT_VAL($(SQL)) | executes the function above:SUBST_QUERY_RESULT_VAL($(SQL),DEST) |
The second’s function implementation simply calls the first one transparently passing the same SQL and defaulting the $(AT) parameter with DEST value:
SUBST_QUERY_RESULT_VAL($(SQL),DEST)
Thanks to it, the user can specify the second parameter or skip it whereby the ‘DEST’ would be used instead.
ODI will analyze the function call format used in the Interface and based on that will substitute relevant function.
I should also mention here there’s an ODI bug that may prevent from linking to the right function.
I discovered the order in which functions are created plays a role here (values of internal ODI Object IDs?).
This means if we create the the ‘wrapper’ one first, ODI will assume there’s a recurrence call even within the function even when the call doesn’t match the function syntax. It can be easily diagnosed by expanding and examining ‘uses’ contents under the function itself. The following indicates wrong recurrence:

If you created the functions in the order as described in this post you should see the calls are resolved properly:

Coming back to our use case, those functions then allow using the SQL queries directly in the interface. The SQL filter below:
DS.DAY_DATE > SUBST_QUERY_RESULT_VAL(SELECT ‘date”’||value||”” FROM C_PARAMETER WHERE KEY=‘LAST_PROGRESS_DATE’)
will be substituted nicely with
DS.DAY_DATE > date‘2013-01-13’
which in brings down the query time to less than 3 minutes.
It’s not everything, the source schema for parameter table doesn’t need to be hardcoded either!
A function with nested substitution API call would work in the same way:
DS.DAY_DATE > SUBST_QUERY_RESULT_VAL(SELECT ‘date”’||value||”” FROM “+odiRef.getObjectName(“C_PARAMETER”)+” WHERE KEY=‘LAST_PROGRESS_DATE’)
Please note that this ODI function call has one limitation though – The SQL parameter has to be all expressed within one line, doesn’t matter how long.
This however, with yet another trick can be lifted too.
[big_data_promotion]