Querying XML files with Tableau via Flexter
Tutorial – Querying XML files with Tableau
Tableau is a great visualisation tool that works with a large number of different file and data formats. One format that is not supported is data in XML files. There are some workarounds, e.g. using Excel to flatten the XML file. However, with deeply nested files or XMLs with a complex schema this approach fails. Excel won’t work either if you have multiple XML files. For those scenarios or if you don’t own a copy of Excel you can use the free online version of Flexter Data Liberator.
In the tutorial below I will walk you through the process of querying XML files with Tableau step by step.
Table of Contents
Sample Data – Clinical Studies from clinicaltrials.gov
We will use some sample data from the www.clinicaltrials.gov website. Data exchange standards in health care and life sciences are predominantly based on XML. The clinicaltrials.gov website is maintained by the National Library of Medicine (NLM) at the National Institutes of Health (NIH). Information on ClinicalTrials.gov is provided and updated by the sponsor or principal investigator of the clinical study.
[flexter_banner]
Create target schema and CSVs
In a first step we download the XML schema file (XSD) from the clinicaltrials.gov website. If you would like find out more about the various download options you can visit the Downloading Content for Analysis page.
We then download the XML files about the clinical studies we are interested in, e.g. trials about the Ebola virus.
https://clinicaltrials.gov/search?term=ebola&resultsxml=true
Once we have downloaded both the XSD and XML files we can process them through Flexter into tab or comma separated files, which is a format that Tableau can consume. Flexter supports many other data formats, e.g. any relational database such as Oracle, SQL Server, MySQL or big data formats such as Parquet.
Let’s first go to the Flexter .
In step one we upload our XSD file.
In step two we upload our XML files. We also register our account so that we can come back to process other XML files
Next we activate our account
Once you have activated your account by following the link in your welcome e-mail you will be able to browse the source schema
Drill into the source schema
Browse the optimized target schema
Drill into the target schema
…and most important of all, download your data for querying in Tableau.
We can see that 21 tables of our target schema were populated with data from our sample trials.

Once you have downloaded the data and extracted it to a folder on the PC where you have Tableau installed you can import it. Flexter automatically creates primary and foreign keys as part of the transformation from XML to TSV. Those keys let you join the data.

We first import the main text file clinical_study.tsv, which sits at the root of our schema. For each output file, Flexter auto-generates a primary key and where relevant a foreign key. In this case it creates the primary key PK clinical study.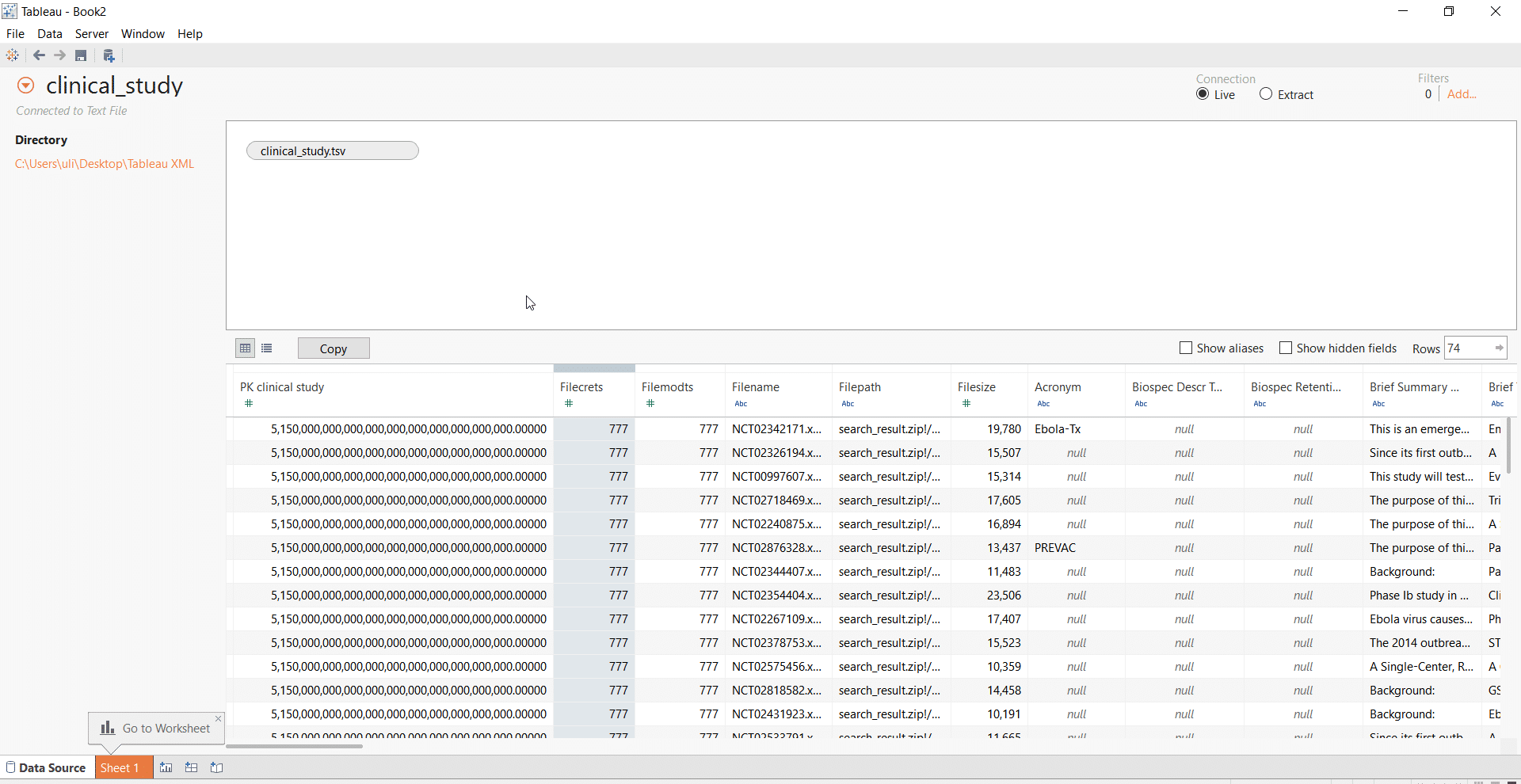
We change the data type of the primary key to String to get around a Tableau limitation when dealing with very large numbers.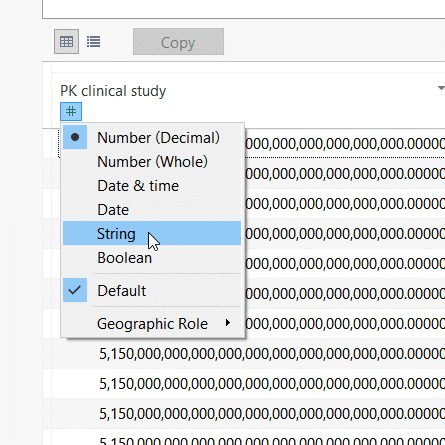
Next we add two more text files, e.g. collaborator.tsv and authority.tsv. Both data sources contain foreign keys to the clinical_study.tsv file. Both foreign keys were auto-generated by Flexter so that we can join the various output files on common keys.

Once again we change the data type to String
We are now ready to query the data by going to the worksheet
We convert each primary and foreign key to a Tableau Dimension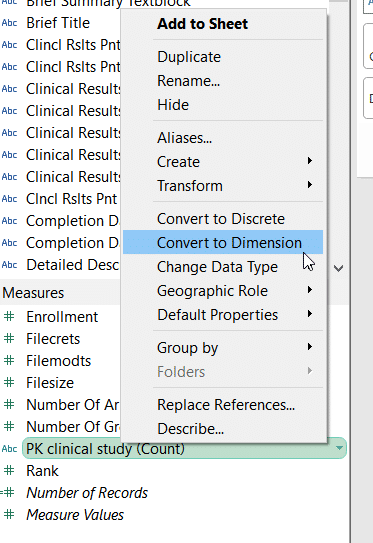


…and define relationships between our text files
Select Custom and Click the Add… button
We map the primary key of clinical study to the foreign keys in authority and collaborator

Finally we are ready to commence our analysis.
Number of clinical studies by phase
Number of Ebola studies by party type
Which data formats apart from XML also give you the heebie jeebies and need to be liberated? Please leave a comment below or reach out to us.


