Converting XML to TSV on HDInsight
In this post we will show you detailed steps on how to convert XML files on HDInsight to text (TSV/CSV). We will use Flexter, our ETL tool for XML and JSON to convert the XML files. HDInsight is the Hortonworks Hadoop distribution.
Table of Contents
Create HDInsight Cluster
To create an HDInsight cluster we add a new resource to the Azure dashboard

Select Spark version 2.1.0 and desirable number of nodes.
After HDInsight cluster has been created we add an edge node to it, by clicking on this link, which contains a template for edge nodes
https://portal.azure.com/#create/Microsoft.Template/uri/https%3A%2F%2Fraw.githubusercontent.com%2FAzure%2Fazure-quickstart-templates%2Fmaster%2F101-hdinsight-linux-add-edge-node%2Fazuredeploy.json
Select the same resource group and cluster name as per HDInsight cluster configuration.


[flexter_button]
Once the edge node has been added to the cluster you can see it in the dashboard

To connect to the edge node via SSH we go to Secure Shell (SSH) section on the cluster’s dashboard in Azure.
Select edge node and copy ssh command (node has the same SSH user and password that we set for the cluster during creation)

* If for some reasons domain name of edge node is not resolved, we can connect to edge node through cluster itself.
* Connect to the cluster via ssh.

Determine edge node inner IP through Ambari

Connect to this IP ( in our case it’s 10.0.0.5 ) from Cluster’s SSH
Flexter installation
In a next step we install Flexter on the edge node. We don’t go through the details here, but feel free to reach out to us if you would like to run a trial with Flexter.
Convert XML on HDInsight
In a last step we run Flexter from the edge node to process our XML files.
|
1 2 3 4 |
$ wget https://sonra.io/customer/service/donut.zip $ xsd2er -RF -g1 donut.zip $ hdfs dfs -copyFromLocal donut.zip . $ xml2er -l 1 -o donut_out/ -f tsv -Y 1 -z none donut.zip |
We redirect the output to Hive
|
1 2 3 |
// output to hive $ hive -e 'create database donut' $ xml2er -l 1 -e d -VE donut donut.zip |
Testing Flexter output in Hive

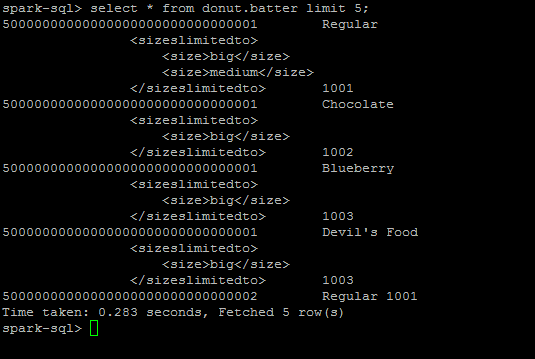
The data can also be quereied from spark-sql:
To get access to Spark-History server or Yarn Resource manager, use the Azure Dashboard




That’s it.
What is your XML data standard? Share your experience of converting big data XML in the comments or drop us a mail.
[faq_button]


