Converting clinical trials XML data to Snowflake and Quicksight with Flexter
In this blog post we will show case Flexter, Sonra’s ETL tool for complex XML/JSON data standards. We will convert a large number of XML documents into a relational data warehouse. The documents contain information about clinical trials. The XML files are publicly available on ClinicalTrials.gov. As of March 2019, 299,015 XML documents are available for download. This translates to ~6.5 GB of raw (uncompressed) XML data. Flexter will process this data set into Snowflake, a popular cloud data warehouse platform with a pay per use model. Flexter is a Spark application written in Scala. It provides native connectivity to Snowflake via the Snowflake Spark connector. This connector is ideal for batch loads from Spark RDDs or data frames. Once the XML data has been converted to Snowflake, we will use AWS Quicksight to generate some dashboards and to summarise the data.
For this blog post we will use the managed cloud version of Flexter. Flexter SaaS is built on top of container technology. You can make calls to its end points via a RESTful API. It currently supports Snowflake, S3, and Redshift as targets. We will add onto this list over time and will also add calls to APIs to transform JSON and XML on the fly. This will let you generate a relational data model from any API you consume in seconds.
Table of Contents
The data from ClinicalTrials.gov
ClinicalTrials.gov is a website that provides access to clinical studies on a wide range of diseases and conditions. Studies are submitted to the website when they start, and the information is updated throughout the study. Sometimes results are submitted after the study ends.
All clinical studies on the website are available for download.
What information can you find in the clinical trials data?
Each XML document presents summary information about a study and includes:
- Disease or condition
- Intervention (for example, the medical product, behavior, or procedure being studied)
- Title, description, and design of the study
- Requirements for participation (eligibility criteria)
- Locations where the study is being conducted
- Contact information for the study locations
- Links to relevant information on other health Web sites, such as NLM’s MedlinePlus® for patient health information and PubMed® for citations and abstracts of scholarly articles in the field of medicine
Some records also include information on the results of the study, such as:
- Description of study participants (the number of participants starting and completing the study and their demographic data)
- Outcomes of the study
- Summary of adverse events experienced by study participants
Records for download can be found here.
Inside of ClinicalTrials.gov Data
We downloaded a zip with 299,015 studies in XML format from the ClinicalTrials.gov website.
Inside the zip, we found 388 folders. Each folder contains hundreds or thousands of XML files. One for each clinical trial.
Each XML document contains information about a clinical trial, e.g. facilities or sites where the study is performed, names of doctors and other study personnel etc.
Why Snowflake?
Snowflake is a data warehouse platform designed and built from scratch for the cloud. It follows a pay per use model. You are billed by the second and can scale the platform elastically based on workloads and number of concurrent users.
At Sonra we love Snowflake. It is very easy and straightforward to use and a perfect match for the output of Flexter. Snowflake separates compute from storage. You can scale each independently from the other. When we need to query our data we can do so on demand and only pay for the compute resources we use.
We have written extensively about Snowflake in other parts of the blog:
- e-book: A comparison of cloud data warehouse platforms
- The evolution of cloud data warehousing
- Comparing Snowflake cloud data warehouse to AWS Athena query service.
Processing data with the Flexter
Flexter exposes its functionality through a RESTful API. Converting XML/JSON to Snowflake can be done in a few simple steps.
Step 1 – Authenticate yourself against the API
Step 2 – Define your source, e.g. S3
Step 3 – Generate schema (target data model)
Step 4 – Define your sink, e.g. Snowflake
Step 5 – Process your XML/JSON data
Let’s go through the steps in detail. We will use our XML data about the clinical trials.
Step 1 – Authentication
For calls to the REST API we need to provide an access_token. To get the access_token we need to make a call to the /oauth/token endpoint with three parameters:
username=YOUR_EMAIL
password=YOUR_PASSWORD
grant_type=password
|
1 2 3 4 |
curl --location --request POST "https://api.sonra.io/oauth/token" \ --header "Content-Type: application/x-www-form-urlencoded" \ --header "Authorization: Basic NmdORDZ0MnRwMldmazVzSk5BWWZxdVdRZXRhdWtoYWI6ZzlROFdRYm5Ic3BWUVdCYzVtZ1ZHQ0JYWjhRS1c1dUg=" \ --data "username=XXXXXXXXX&password=XXXXXXXXX&grant_type=password" |
Example of output
|
1 2 3 4 5 6 7 8 |
{ "access_token": "eyJhbG........", "token_type": "bearer", "refresh_token": "..........", "expires_in": 43199, "scope": "read write", "jti": "9f75f5ad-ba38-4baf-843a-849918427954" } |
In the next step we create an AWS S3 source.
Step 2 – Create a source
As part of the call we need to supply two mandatory parameters (name, path) and one optional parameter roleArn.
The name parameter defines a unique name of the Sink, which you will use in subsequent calls as a reference.
Parameter path is a full path to your S3 Object. It can be a bucket or folder.
The optional parameter roleArn is a name of an AWS Role with at least Read access to the given path in your AWS Account.
|
1 2 3 4 5 |
curl --location --request POST "https://api.sonra.io/source/create/s3" \ --header "Authorization: Bearer <access_token>" \ --data "{\"name\": \"clinicaltrials\", \"path\": \"s3://iebucketencpt/donut.zip\", \"roleArn\": \"arn:aws:iam::111111111111:role/SomeS3RoleForAssumeRole\",\"type\": \"xml\"}" |
Example of output
|
1 2 3 4 5 |
{ "status": "ok", "file": "s3sink", "type": "S3_EXTERNAL" } |
Step 3 – Create schema (target data model)
Next we use the XSD from clinicaltrials.gov with intelligence to generate our target schema.
|
1 2 3 4 5 |
curl --location --request POST "https://api.sonra.io/source/create/file" \ --header "Authorization: Bearer <access_token>" \ --form "type=xsd" \ --form "name=clinicaltrials_schema" \ --form "file=@"\ |
Explanation of parameters:
| type | xml | xsd | json Type of Source, can be “xml” , “xsd”, “json” |
| name | my_first_file Name of your source. You will use this name to put a reference to the Source |
| file | File to upload |
Flexter can generate a target schema from an XSD, a representative sample of XMLs, or a combination of the two. For any questions please refer to our Flexter XML FAQ.
Example of output
|
1 2 3 4 5 |
{ "status" : "ok", "file" : "clinicaltrials_schema", "type" : "xsd" } |
And now we create the target model.
|
1 2 3 4 5 6 7 |
curl --location --request POST "https://api.sonra.io/schema/create" \ --header "Authorization: Bearer <access_token>" \ --header "Content-Type: application/json" \ --data "{ \"name\": \"clinicaltrials-schema\", \"xsd\": \"clinicaltrials_schema\" }" |
The information on the target data model is stored as metadata. It is persisted in Flexter’s metadata repository. The metadata can be used to generate DDL scripts, compare different schema versions, generate data lineage, generate an ER diagram etc.
Flexter generates the following relational target model from the XSD. You can download a PDF version here.
Step 4 – Create sink
Next we create Snowflake as a sink. We provide connection details to our Snowflake data warehouse, e.g. login, database, virtual warehouse etc.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
curl --location --request POST "https://api.sonra.io/sink/create/snowflake" \ --header "Authorization: Bearer <access_token>" \ --header "Content-Type: application/json" \ --data "{ \"name\": \"snowflake_sink\", \"jdbc\": \"snowflake://xxxxxx.eu-central-1.snowflakecomputing.com\", \"username\": \"username\", \"password\": \"password\", \"db\": \"DEFAULT_DB\", \"schema\": \"PUBLIC\", \"warehouse\": \"DEFAULT_WH\" }" |
Example of output
|
1 2 3 4 5 |
{ "status": "ok", "file": "snowflake", "type": "SNOWFLAKE" } |
And now we can process and convert our data to Snowflake
|
1 2 3 4 5 6 7 8 |
curl --location --request POST "https://api.sonra.io/data/process" \ --header "Authorization: Bearer <access_token>" \ --header "Content-Type: application/json" \ --data "{ \"schema\": \"clinicaltrials-schema\", \"source\": \"clinicaltrias\", \"sink\": \"snowflake_sink\" }" |
Example of output
|
1 2 3 4 |
{ "status": "OK", "uuid": "data-2400eb32-0a80-496d-a203-7fad46eca4d3" } |
And we have successfully converted ClinicalTrials.gov data to Snowflake.
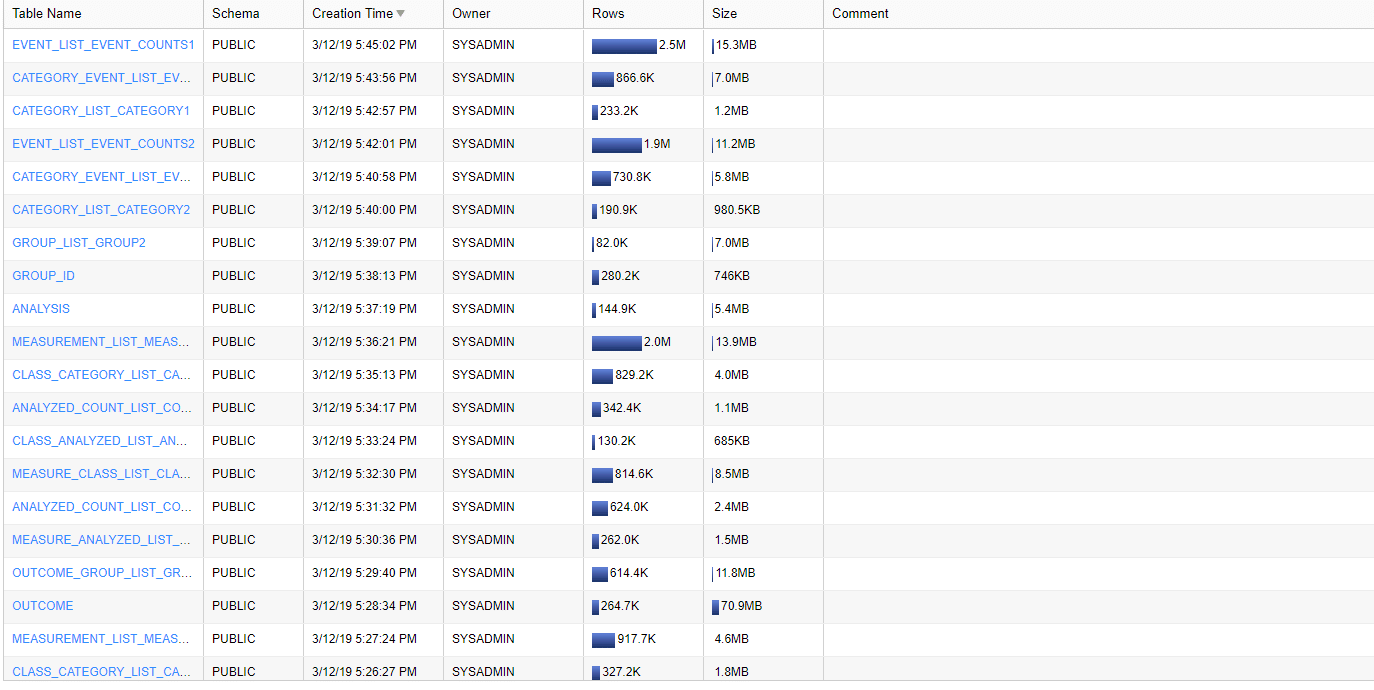
Analysis in AWS Quicksight
Great. We now have our data in Snowflake. In a last step we will use Quicksight to query this data. Quicksight is a nice and lean BI tool. It is straightforward to use and is not overloaded with hundreds or thousands of features. If you are looking for something nice and simple, Quicksight will do the trick. It also follows a pay per use model for Reader access.
With Quicksight you can either generate SQL queries to run directly against Snowflake or you can create a Spice cube (columnar compressed in-memory data storage). For this particular use case we have imported our data into Quicksight Spice for in-memory processing. Like everything in life this has advantages and disadvantages. With Spice your queries will run faster. On the downside you will need to keep Spice in sync with Snowflake. Syncing requires overhead and adds additional points of failure to your pipeline. Unlike Snowflake, Quicksight can’t scale across multiple nodes. For very large volumes of data you are better off to push down the analysis into Snowflake.
Let’s select the CLINICAL_STUDY data set and run some sample queries against it.
As an example we can create a diagram that shows us the average number of patients enrolled in the different types of clinical studies.
As expected, Phase 3 studies on average have the highest number of enrolled subjects (clinical trial speak for patients).
You can read this document (PDF) to know how o signup for a free trial.
Summary
So there you have it. We did in a few minutes what normally would take a few days.
- We converted a large number of complex XML documents into a relational database
- We ran some SQL queries against the data in Snowflake
- We imported some data into Quicksight Spice and created various visualisations
Reach out to us if you would like to find out more about Flexter.
Contact us if you would like to get access to the clinical trials data via Snowflake or Quicksight.
Contact us for expert services on Snowflake.
Enjoyed this post? Have a look at the other posts on our blog.
Contact us for Snowflake professional services.
We created the content in partnership with Snowflake.
In this video, we use Flexter to automatically convert very complex FpML XML to Snowflake tables. Book a demo to see the power of Flexter in action!


