Data discovery and the unfulfilled promises of self-service Business Intelligence
Self-service BI is all about allowing business users or non-technical staff to generate insights from data. It is about to make its breakthrough in the enterprise! Happy days. Unfortunately, this has been the headline prediction for the last ten years. The hype has never really materialised. So why has self-service BI struggled so much to gain traction in the enterprise?

Self-service BI and raw data?
In order to get to the root of the problem we first need to understand what the problems are that Business Inteligence and BI tools are solving. Business Intelligence is all about finding insights from cleansed and integrated data. The data has gone through various steps of modelling, transformation, and integration. The data that is exposed to BI tools is well understood as it has been analysed and profiled by a legion of data analysts. The best friend of Business Intelligence is the data warehouse. What about Business Intelligence tools? They are good at querying transformed and cleansed data. They are bad at transforming data. As a result they are limited to ad-hoc querying against pre-defined structures (star schemas or dimensional models). This is the core reason why self-service BI has not taken off. BI tools are expected to do something that they were not built for. Get insights from raw data. Raw data has various defects and first needs to be put into shape. Not something a BI tool can do for us. This step typically requires the involvement of IT and the much dreaded ETL. Self-service goes out the window. In summary, Business Intelligence is limited to run ad-hoc queries against a pre-built star schema. This is as far as it gets with self-service BI.
Self-service BI and Multiple Data Sources
Another area where BI tools struggle is when data from multiple sources needs to be queried. This is somewhat related to the raw data conundrum that I have described above. Data quality across systems is typically worse than just in one source. So there will be even more demand for data transformations and integrations. Another problem is related to query performance. A lot of BI tools use data federation to stitch the data together. This approach tends to suffer from performance problems and business users quickly give up due to poor response times.
Availability of integrated data
Another major limiting factor for Business Intelligence is the availability of data. It takes between 3-9 months to ingest a new data source into the warehouse. The consequence is that only core data sets get ingested and transformed (not more than 15-20 sources). The so called long tail of data is left out. This typically includes important spreadsheets or some small legacy databases that large parts of the business run on. This also applies to data from social media and other external data sources. Whilst important, this data rarely makes it into the data warehouse. What happens if a question needs to be answered from data that hasn’t been loaded it into the warehouse? A poor soul is tasked with stitching data together in Excel from these untapped sources. Not nice!
The Future of Self-service
So what can be done to make self-service a success? The solution to this problem requires an entirely new approach. First of all, we need to have a central location for all of our raw enterprise data and not just the 10-20 most important sources. This also needs to include unstructured data. Secondly, we need a tool that allows non-techies to easily transform the data and put it into shape for the need at hand. The first problem is solved by the data lake. The second problem is solved by data discovery tools, which are a new breed of tools for self-service BI. While these tools best work with a central data hub, a data lake is not a must-have. Besides self-service BI these tools also allow for self-service analytics. You can find out more about data discovery tools in my article The two Use Cases of Data Discovery Tools.
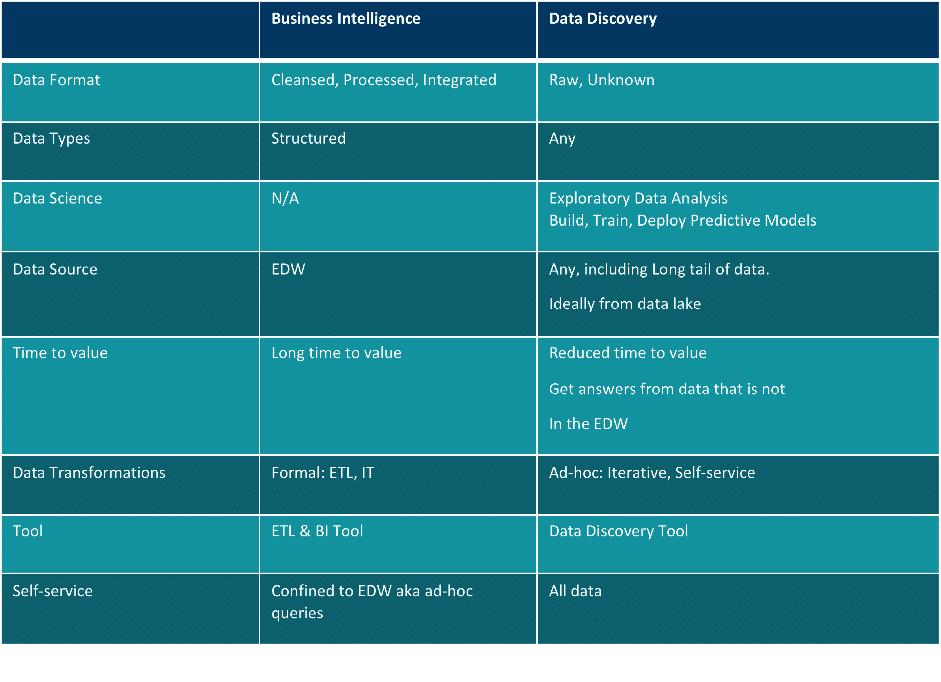
Below is a summary of the differences between BI and data discovery:
About Sonra
We are a Big Data company based in Ireland. We are experts in data lake implementations, clickstream analytics, real time analytics, and data warehousing on Hadoop. We can help with your Big Data implementation. We also chair the Hadoop User Group Ireland. You can get in touch today, we would love to hear from you!