Rocketship Performance for Snowflake with Clustering Keys

Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Introduction
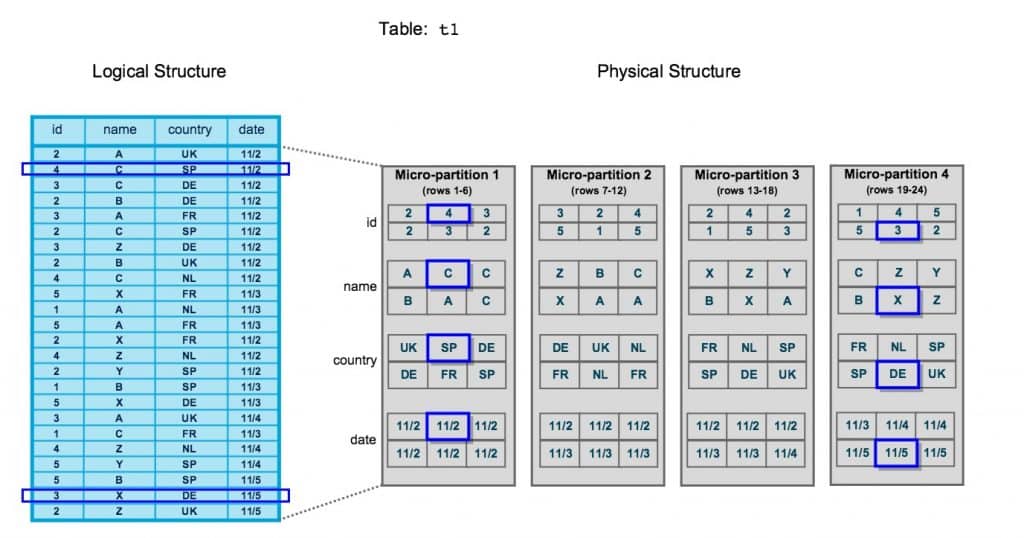
Snowflake stores tables by dividing their rows across multiple micro-partitions (horizontal partitioning). Each micro-partition automatically gathers metadata about all rows stored in it such as the range of values (min/max etc.) for each of the columns. This is a standard feature of column store technologies. For example Apache ORC format (optimized row columnar) keeps similar statistics of its data. This metadata helps Snowflake prune certain micro-partitions if it sees that values specified in the query are not stored in that micro-partition.
Within each micro-partition, the data is vertically partitioned and stored in column stores. Column stores within each micro-partition store data in a compressed format that is based on the properties of the data type. For example, a column containing addresses can build a dictionary of all addresses and then store only the relevant dictionary value instead of full strings thereby greatly reducing the storage footprint.
The rows in a micro-partition are sorted by the clustering key (if one exists). Redshift has a similar feature named sort key. When the rows are stored in sorted order they can act like indexes on columns. This is because a value in a sorted array can be located in approximately log n operations using a simple binary search algorithm compared to n operations when your data is not ordered and you have to look at every value. Practically if your array has 1 billion values in it, then simply searching for a value in an unsorted array would require scanning all 1 billions values. If instead the array was sorted we could use the binary search algorithm and find the value with only 30 lookups.
Reach out for expert Snowflake implementation and performance tuning if you are encountering performance bottlenecks.
A diagram from the official Snowflake documentation explains how micropartitions and column stores work:
Clustering keys are a new feature (currently in preview mode) of Snowflake that are explicitly designated for co-locating data in the same micro-partitions.
Co-locating similar rows in the same micro-partitions improves scan efficiency in queries by skipping large amounts of data that does not match filtering predicates (micro-partition metadata). It also improves seek performance because values can be found in sorted data much faster
Once you define a clustering key, you have to recluster the table using the RECLUSTER command. The RECLUSTER operation organizes the records for the table based on the clustering keys, so that related records are relocated to the same micro-partition. This involves deleting and re-inserting data based on the clustering key. The RECLUSTER operation in Snowflake is very similar to the VACUUM operation on Redshift which reclaims space and resorts rows of the specified table.
The following illustration from official Snowflake documentation clearly demonstrates this process:
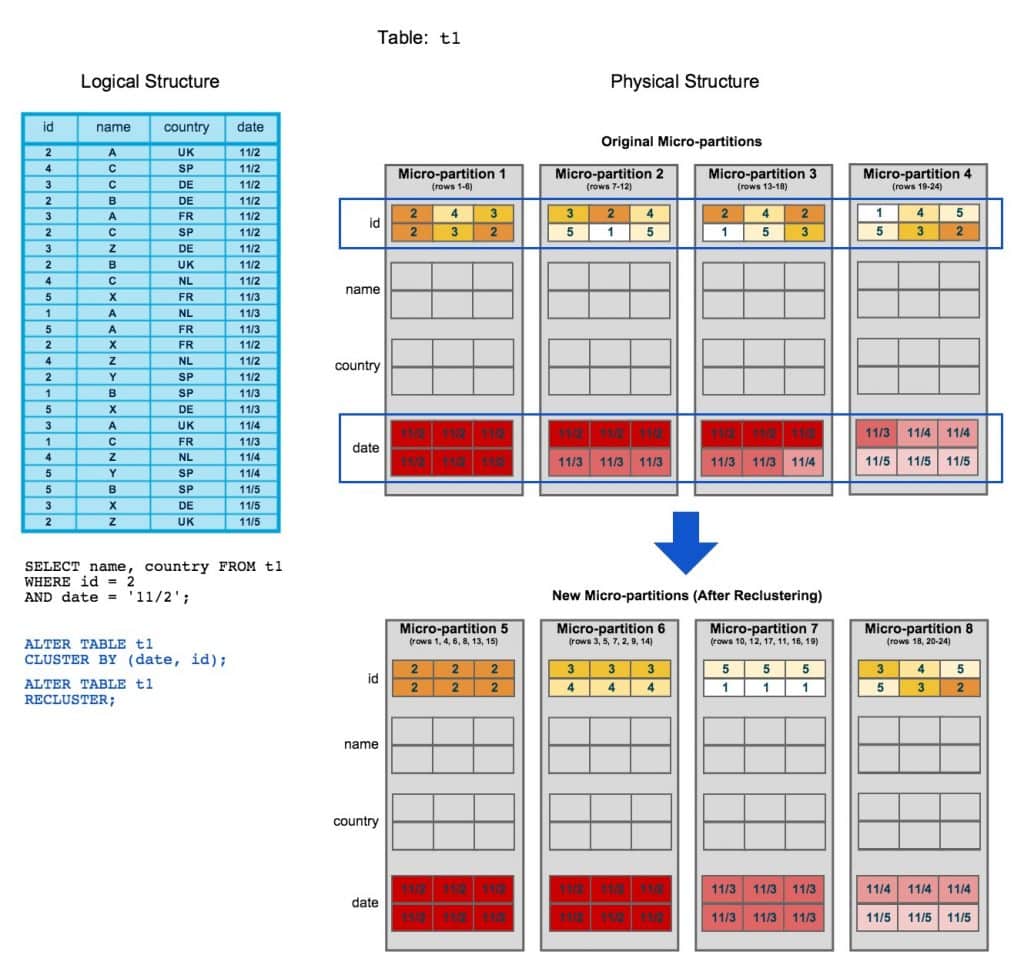
After the data was reclustered into new micro-partitions, the rows are now ordered by the date column. In practice this means that to find a record whose date column value is 11/2 we only have to scan two (instead of all) micro-partitions. This significantly reduces I/O, the amount that needs to be read from disk.
Measuring the impact of clustering keys
First we will load a new dataset containing the records of all individual housing transactions in England and Wales since 1995. The dataset has around 22 millions rows which are stored on approximately 60 micro-partitions.
Now let’s imagine we have to run the following query on our dataset:
SELECT
sales.*,
AVG(price) OVER (PARTITION BY datetime),
MIN(price) OVER (PARTITION BY datetime),
MAX(price) OVER (PARTITION BY datetime),
row_number() OVER (PARTITION BY town_city ORDER BY datetime),
dense_rank() OVER (PARTITION BY town_city ORDER BY datetime)
FROM
sales
WHERE
datetime > '2012-01-01'
AND datetime < '2013-01-01'
ORDER BY
datetime ASC ;
We can choose any of the columns as the clustering key. It’s best to choose columns which are used in queries for filtering (WHERE, JOIN, GROUP BY, PARTITION BY clause) or ordering (ORDER BY clause). Because we mainly use the columns datetime and town_city_name for ordering in the window functions and filtering let’s see how creating a clustering key on either of those would work.
We start off by running the query without a clustering key and checking the resulting execution plan. If you aren’t familiar with execution plans in Snowflake or operators that we show in this post, please refer to the official Snowflake documentation which is excellent. Almost everything is covered and well documented.
The resulting execution plan is:
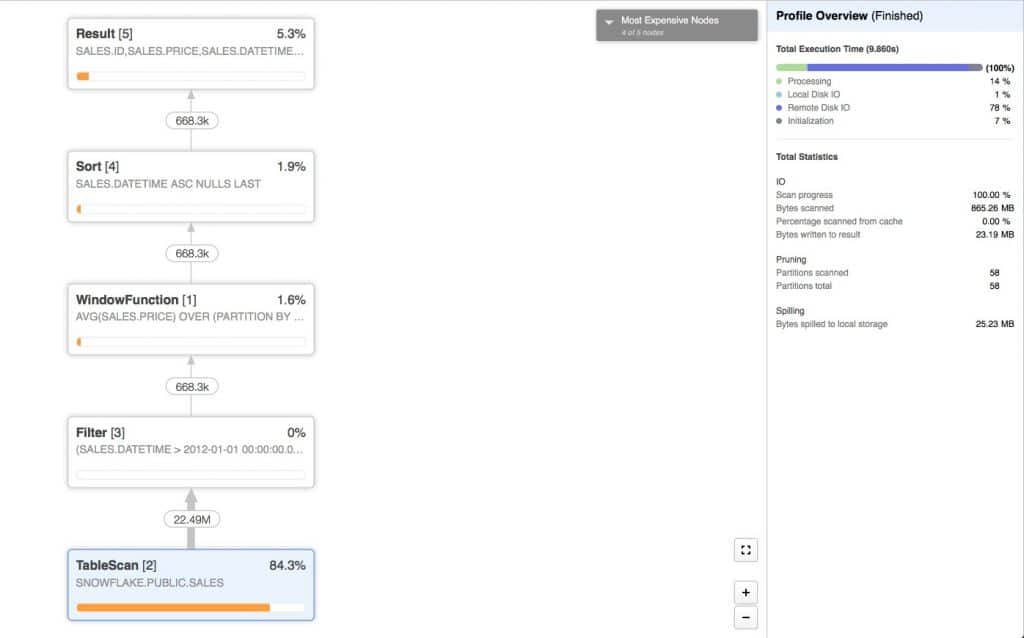
You can see that the query actually scans every row (22 million) in the database searching for rows with the datetime in required range.
This means it would make more sense to cluster the table on the datetime column as we use it for filtering of rows. We will now set a clustering key on the datetime column and recluster the table:
ALTER TABLE sales CLUSTER BY (datetime); ALTER TABLE sales RECLUSTER;
After rerunning the previous query, we get the following execution plan:
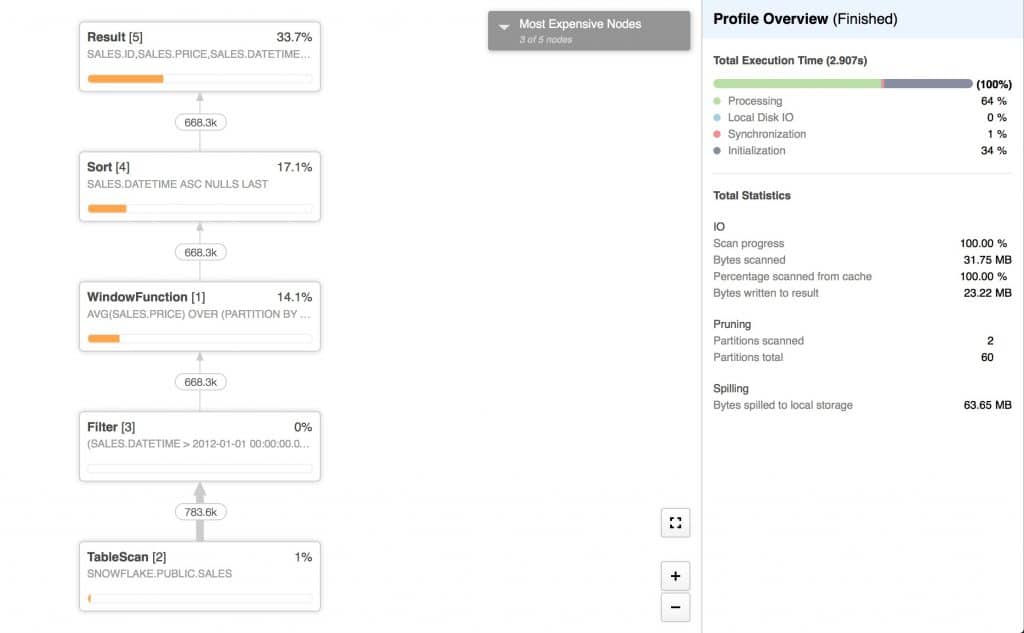
We can see that only 783 thousand out of 20 million (4%) were scanned.
In practice this means 31.8MB of data was scanned when datetime was used as clustering key compared to 904MB as in the initial case.
We can also see how effective pruning really is. 58 out of 60 partitions were pruned before being scanned and filtered. We only scanned 2 micro-partitions that had the datetime values for our filter out of 60 possible.
Why reclustering is necessary
In normal use we can expect some data to be inserted into our table. Let’s simulate this and see how it affects our clustering key.
First we will make a copy of our table. To copy not only the data but other properties such as clustering keys we will use the CLONE command:
CREATE TABLE sales_2 CLONE sales ;
Next we will populate the new table with 25% of it’s rows randomly sampled from the table using the excellent SAMPLE feature of Snowflake:
INSERT INTO sales_2 SELECT * FROM sales_2 SAMPLE (25);
Now we can re-run our main query from above.
The resulting execution plan is:
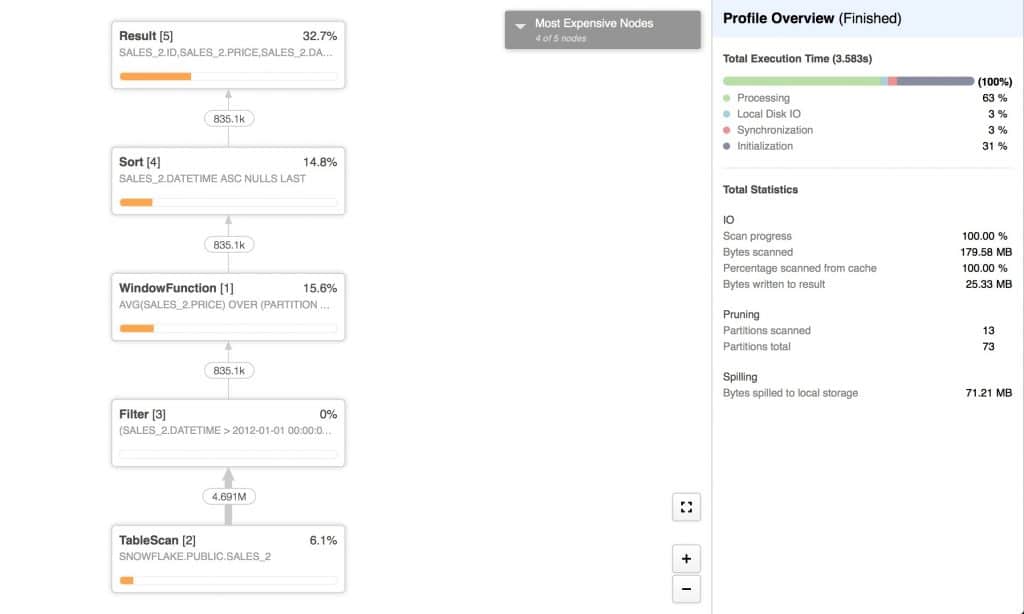
We can see that 13 new partitions were created and we have 73 partitions in total compared to initial 60.
After the insert of 5.5 million new rows, 13 partitions were scanned while before we only scanned 2 out of 60 partitions. Because the 13 new partitions don’t keep data sorted according to our clustering key, 11 out of those 13 new partitions had to be scaned as Snowflake couldn’t guarantee they didn’t contain dates in the range we are interested in.
This is why it’s very useful to run the RECLUSTER operation periodically after loading large amounts of data.
Conclusion
Unfortunately, there are still some limitations to clustering keys. We noticed that after reclustering a table, selecting some data from it and then sorting it with ORDER BY clause based on the clustering key, the explain plan in query explorer shows that a SORT operation was required even though the data should be ordered by the clustering key. We did not notice this behaviour on other cloud data warehouses.
While this is a limitation, we expect it will be fixed quickly as the clustering key feature is still in preview mode. We also posed a question on the very helpful Snowflake community support forum.
To conclude, clustering keys behave as indexes in columnar databases as they avoid costly scans by providing precise filtered scans using pruning techniques. In theory they should also improve the performance of JOIN, GROUP BY and ORDER BY clauses as well as window functions.
Enjoyed this post? Have a look at the other posts on our blog.
Contact us for Snowflake professional services.
We created the content in partnership with Snowflake.
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: