Create your own custom aggregate (UDAF) and window functions in Snowflake

In this post we will show you how to create your own aggregate functions in Snowflake cloud data warehouse. This type of feature is known as a user defined aggregate function. Most big data frameworks such as Spark, Hive, Impala etc. let you create your own UDAFs. Also traditional databases such as Oracle or SQL Server have this feature. However, with these data stores we typically need to write Java code that we need to compile, which makes it awkward and time consuming to deploy.
With Snowflake it’s much easier. You can write these functions in plain Javascript. No need to compile them. No need for the DBAs to deploy them. It makes these functions so much more accessible to developers.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Why custom aggregate functions (UDAFs)?
Few developers know about user defined aggregate functions and even less use them. I think they are more widely used on big data frameworks such as Spark, Hive etc.
You might be wondering why you would need to create your own aggregate function. Here are some examples
- Randomly select one of the values from a GROUP BY
- Get the greatest common divisor (GCD)
- Get the lowest common denominator (LCD)
- Calculate Median (not supported by some databases)
Similar to functions in programming languages, user defined aggregate functions in the database world accept parameters (usually multiple rows) as input, perform some aggregate operations such as finding the maximum or average value of the input and then return the result of that operation.
In this post we will be working with our dataset of telecommunications top-ups.
FlowForward.
All Things Data Engineering
Straight to Your Inbox!
UDAFs in Snowflake
Snowflake provides a number of pre-defined aggregate functions such as MIN, MAX, AVG and SUM for performing operations on a set of rows. A few database systems such as Oracle and SQL Server however allow you to define custom aggregate functions. This process is usually very tedious. Oracle for example requires you to write Java code than then has to be compiled and deployed by the DBAs. SQL Server requires custom CLR code written in C#.
Snowflake supports Javascript table UDFs which output an extra column containing the result of applying a UDF to your collection of rows. They are very simple to create using Javascript and even easier to deploy.
Let’s first create a table UDF (UDAF) which will output the multiplication of all values in the input:
create or replace function AGG_MULTIPLY(ins double)
returns table (num double)
language javascript
as '{
processRow: function (row, rowWriter) {
this.cMult = this.cMult * row.INS;
},
finalize: function (rowWriter, i) {
rowWriter.writeRow({NUM: this.cMult});
},
initialize: function() {
this.cMult = 1;
}}';
You can see that to implement a table UDF we have to define a Javascript object with three functions:
- initialize – in this function we create the constants that are stored by this object and can be updated by other functions
- processRow – in this function we receive as the value for each row in input. We can also choose to output a row using the rowWriter
- finalize – this function is called after the last row in the input is processed. Here we can do the final calculations and also output them as a new row
In the example we defined that the input is named “ins” which we can only refer to with capital letters inside Javascript code. The output of the function is a table with a column named “num” of type double.
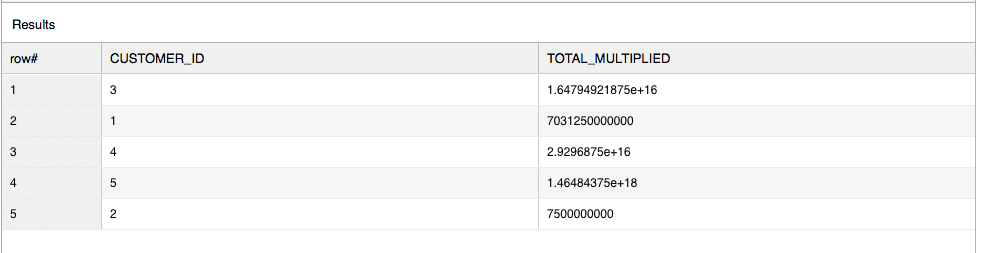
We can use this UDAF to multiply the value of all top-ups a customer has made:
SELECT
customer_id,
res.num AS total_multiplied
FROM
top_ups,
TABLE(AGG_MULTIPLY(topup_value)
OVER (PARTITION BY customer_id) ) AS res
Unfortunately, Snowflake does not support the use of table UDFs (UDAFs) with the GROUP BY clause. We had to use the TABLE function with our table UDF and the OVER clause for defining the input rows.
The result of our query is the following:
UDAFs with window function in Snowflake
While table UDFs cannot be natively utilized by window functions, there are some workarounds we will show you.
We will first show you a simple modification to use Snowflake UDAFs as window functions with a RANGE clause from UNBOUNDED PRECEDING and CURRENT ROW work. These are also called running aggregates.
We will create a function RUN_MULTIPLY which multiplies the value of all topups in the input rows (we will use it to multiply all of the topup values on the same date).
For every row in the input it will output the current (running) value of the multiplications:
create or replace function "RUN_MULTIPLY"(ins double)
returns table (num double)
language javascript
as '{
processRow: function (row, rowWriter) {
this.cMult = this.cMult * row.INS;
rowWriter.writeRow({NUM: this.cMult});
},
finalize: function (rowWriter, i) {
},
initialize: function() {
this.cMult = 1;
}}';
Compared to AGG_MULTIPLY function you can notice that the finalize function does not output a row while the processRow function does.
Using a specific syntax we can apply this Javascript table UDF to every partition that is created based on the date column.
SELECT
*
FROM
top_ups ,
TABLE(RUN_MULTIPLY(topup_value)
OVER (
PARTITION BY date
ORDER BY topup_value ASC)) as num
ORDER BY
date ASC, topup_value ASC ;
In the output of this query you can see an extra column for each date (our partition key) that contains the value of our Javascript table UDF named RUN_MULTIPLY:
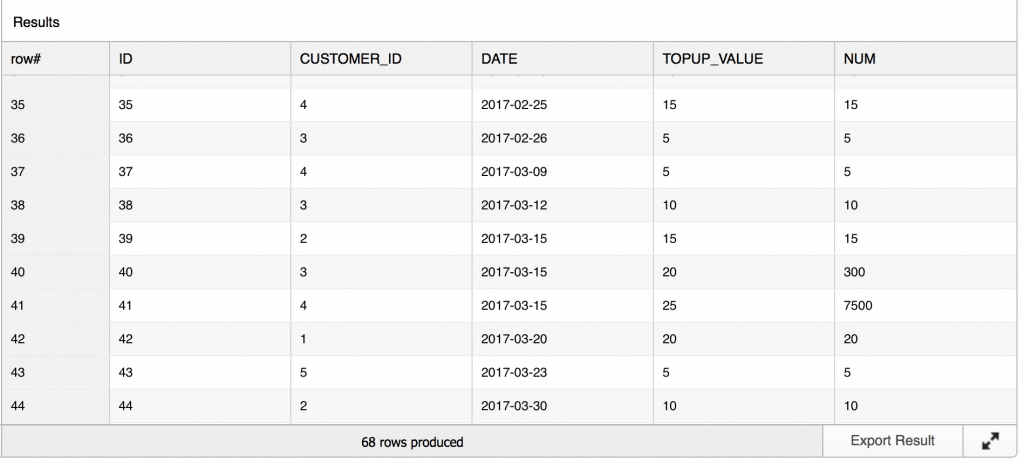
On date 2017-03-15 we had three topups by customers with CUSTOMER_ID 2,3,4. They topped up by an amount of 15,20,25 bitcoins. The running product for the topups on this day is 15, 300 (15*20), 7500 (15*20*25).
When developing the Javascript table UDFs we experienced some complications with data type conversions which will hopefully get improved. Specifically the Javascript table UDFs do not accept integers as inputs because integers do not exist as a datatype in Javascript. To combat this problem we had to change the fields with integer data type to be of type float.
Tell us what custom aggregate or window functions have you created. Leave a comment in the section below.
Enjoyed this post? Have a look at the other posts on our blog.
Contact us for Snowflake professional services.
We created the content in partnership with Snowflake.
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: