Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
MedVault, an organization offering data management services in primary healthcare, identified the need for a platform which would help their clients to really unlock the value of their data. This required a scalable, compliant, and secure analytics platform which would monitor and measure healthcare practice performance across thousands of data points, identify patient cohorts in seconds, increase reimbursement, and improve patient care.
The overall goal was to bring insights and analysis to primary healthcare clinics and consultants. The is based on a variety of data sources including various health practice applications and primary care reimbursement service datasets. In other words, to report on medical practice management both from a workflow and a financial perspective to improve patient primary care, increase reimbursement returns, and reduce needless admin.
Why Snowflake
The solution needed to support up to 200 data sources of a varying data footprint and data processing load. Key Snowflake Cloud Data Platform features led to the selection of Snowflake:
No capital expenditure barrier to entry plus the utility billing approach whereby you only pay for what you use
This billing approach combined with elastic scalability ensures cost effective data processing particularly as more data sources are on-boarded over time
The solution
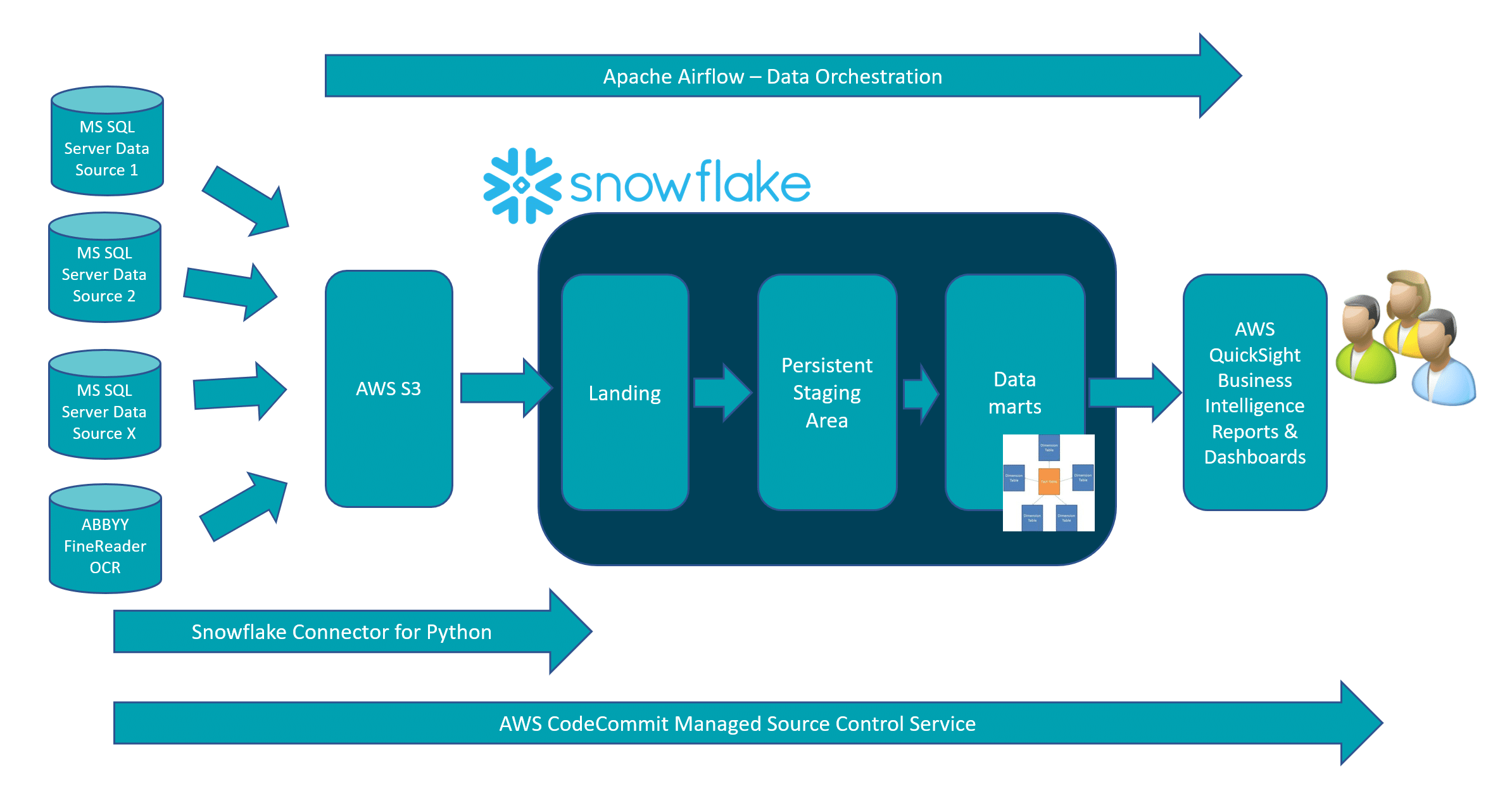
The below diagram illustrates the overall solution which will be described in the following sections.
Snowflake Virtual Warehouse configuration
The solution uses various Snowflake virtual warehouses to separate analytical workloads from data extraction, load, and transformation workloads. A virtual warehouse is a cluster of compute resources in Snowflake. This provides the necessary CPU, memory, and temporary storage required to perform DML operations which require compute resources.
The configuration of multiple virtual warehouses ensures that the various workloads can run simultaneously without one workload impacting another workload.
From a cost management perspective, virtual warehouses auto-suspend and auto-resume settings are configured to ensure that Snowflake credits are consumed when only the virtual warehouses are being used.
The following SQL DDL demonstrates how to create a “Medium” sized virtual warehouse (four node compute cluster) , which as part of the solution is used for analytical workloads:
1
2
3
4
5
CREATE ORREPLACE WAREHOUSE ANALYTICS_WH
WITH WAREHOUSE_SIZE='MEDIUM'
AUTO_SUSPEND=300
AUTO_RESUME=TRUE
COMMENT='Analytical workload processing.'
As indicated in the above example, if there is no activity for 5 minutes then the virtual warehouse switches to the ‘suspended’ state and stops billing. If a new SQL statement is submitted to the virtual warehouse, then that warehouse automatically resumes processing.
Data extraction
A variety of data source applications and suppliers are required as inputs into the solution. While it’s often the case that data can be extracted using third party applications or services which pull data from the relevant data sources, in this instance given the source security configurations, that was not a suitable option. Therefore a customized data extraction application was developed to push the data from source based on the following criteria:
Developed using Python
The application incorporates the Snowflake Connector for Python which is an interface for developing Python applications that can connect to Snowflake and perform all standard operations
Push those outputs to specific paths within AWS S3 buckets
Each instance of the data extraction application is configured with its own AWS IAM policies associated with a specific S3 path.
This ensures that one data extraction application instance cannot access data from another data extraction application instance which has been pushed to S3 and vice versa.
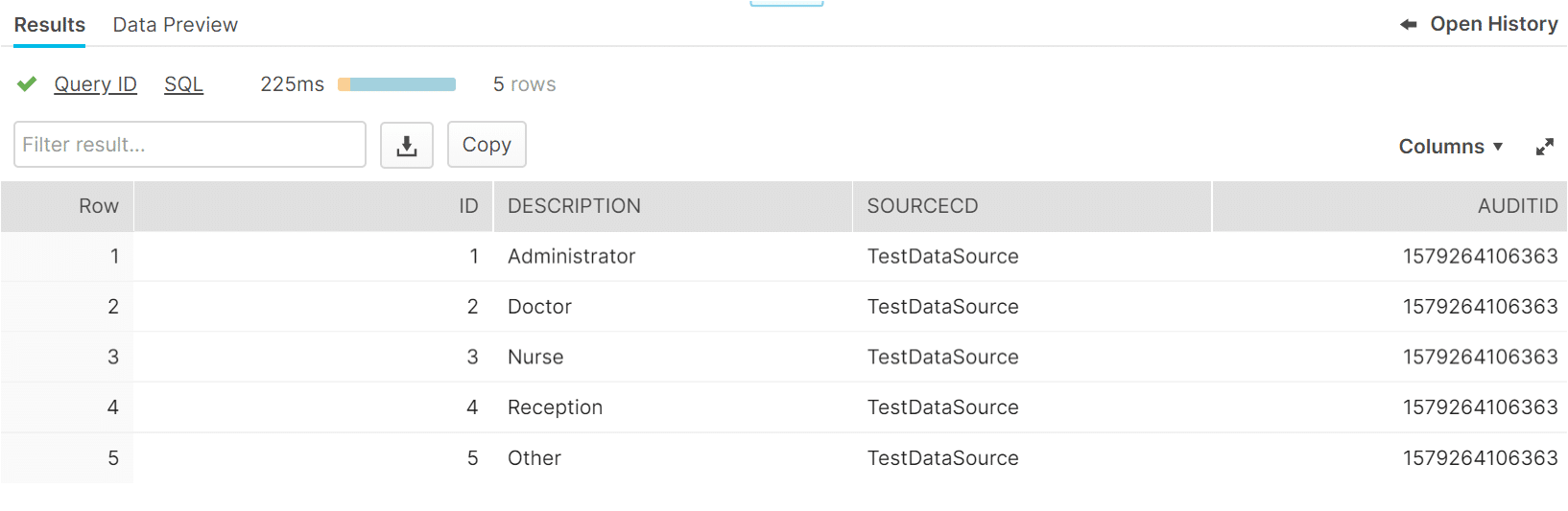
Metadata is added to each row of extracted data to indicate which data source that row originated from and as a basis for row level permissions. The following screenshot illustrates data (columns 1 & 2), and associated row labelling (columns 3 & 4):
PDF documents are another type of data source used in this solution. These documents are parsed and converted to flat file using ABBYY FineReader optical character recognition.
The data is landed on Snowflake via logic configured using the above mentioned Snowflake Connector for Python.
Encryption
Data source to AWS S3 encryption along with Snowflake’s end to end data encryption ensures that data is encrypted both in transit and at rest throughout the data pipeline.
Snowflake Role-based Access Control
Snowflake’s role based access control determines which users can access and perform operations on specific objects within Snowflake. Each solution user or process, whether landing, transforming, or reading data from data marts, is assigned minimum required permissions. In other words, access is granted on a ‘need-to-know’ basis.
Persistent Staging Area
A Persistent Staging Area (PSA) is a staging area that is not truncated between data loads. It instead contains an audit history of the data loaded from upstream data sources.
While an upstream data source typically doesn’t track it’s own history, requirements can change which can lead to new data marts / refactoring of current data marts. A PSA mitigates the risk in relation to these possible events. Also, availability of audit history can assist in relation to operational support.
Along with automatically determining and tracking the delta between the landed data and the PSA contents, current state SQL views are automatically configured in the PSA to present the latest version of the data as inputs into data mart processing.
Each row in the PSA is labelled indicating whether the row has been inserted, updated or deleted
An updated row results in a new row being added to the PSA and this row being treated as the latest version of that row
If a new table is landed this is automatically picked up in the above steps
Data processing within the PSA and throughout the solution is designed to be idempotent so that if the upstream data has not changed, then there will be no change downstream.
Snowflake zero-copy cloning
Version control and release management take place using AWS Code Commit. The solution environments follow the typical Development, Test, and Production approach. Depending on the type of change being released, a clone of production may also be taken in line with solution governance using Snowflake zero-copy cloning.
The zero-copy cloning feature is used to take a “snapshot” of the relevant database / schema / table depending on the checks taking place. A clone is writable and is independent of its source (i.e. changes made to the source or clone are not reflected in the other object). This means that the creation of the cloned database is instant and likewise can be dropped once the necessary checks are complete. The following is an example of cloning syntax where a database clone called DB_CLN is created based on a database called DB:
1
CREATE ORREPLACE DATABASE DB_CLN CLONEDB
Datamarts
At the data mart layer where users run various analytical workloads, role-based access control permissions are applied also.
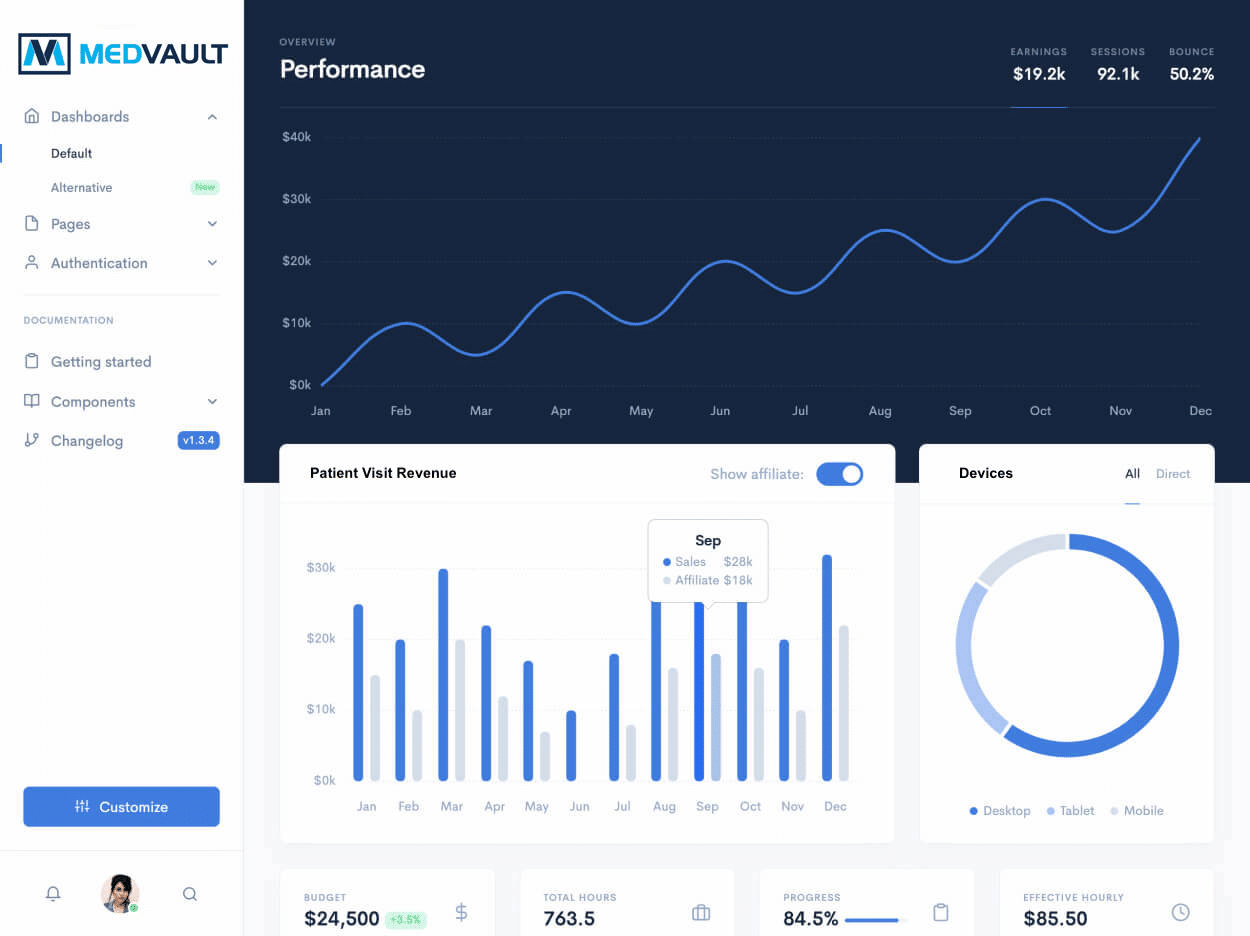
The data marts are accessed using AWS Quicksight. AWS Quicksight is a business intelligence service that is used to create and publish interactive dashboards which include machine learning insights. The below screenshot shows a MedVault Analytics demo dashboard which illustrates primary healthcare practice performance.
Data Orchestration
Data orchestration is managed using Apache Airflow.
Apache Airflow is an open-source workflow management platform. It is written in Python, and workflows are created via Python scripts. Airflow is designed under the principle of “configuration as code”. Developers can use Python to import libraries and classes to help them create their workflows. The workflow concept is based on directed acyclic graphs (DAGs), which make the workflow tasks and dependencies easier to manage. Separate DAGs are used in the solution for various data import steps, PSA processing, and data mart processing.
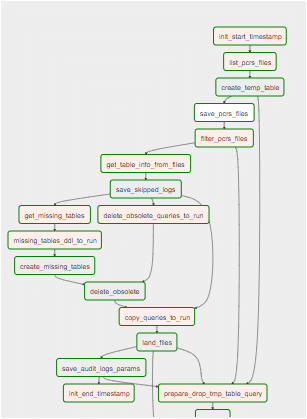
Most significantly, the Airflow configuration pushes the workload down to Snowflake which makes the most of Snowflake’s parallel processing power. The following is an example of an Apache Airflow DAG used to load OCR process outputs into Snowflake.
Conclusion
The MedVault Analytics secure healthcare platform allows General Practitioners to learn a lot more about their primary healthcare medical practice workflows, demographics, and clinical insights. It leads to reduced administration for clinical staff and monetary benefits in the form of increased reimbursement for work completed. This amounts to thousands of euros in savings and increased reimbursement per primary health care practice annually. The solution, based on the Snowflake Cloud Data Platform and delivered by Sonra Intelligence, allows primary care medical practices to focus on what they do best – treat patients.
The Snowflake Cloud Data Platform’s scalability, separation of workloads, end to end encryption of data whether in transit or at rest, and the ‘pay for what you use’ approach are cornerstones to a successful MedVault Analytics platform solution.
Quoting Tony Ryan, co-founder and CEO of MedVault:
“Snowflake has been fantastic in providing a robust and secure service with transparent pricing. There are no huge up front costs which allowed our team to invest more in developing great tools for doctors.
Likewise, Sonra Intelligence have been fantastic and professional to deal with. Their experience and passion for both data engineering and data architecture have been invaluable in the success of our project”.
We created the content in partnership with Snowflake.
Enjoyed this post? Have a look at the other posts on our blog. Contact us for Snowflake professional services.
We created the content in partnership with Snowflake.
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Cookie
Duration
Description
__cfruid
session
Cloudflare sets this cookie to identify trusted web traffic.
cookielawinfo-checkbox-marketing
1 month
This cookie is set by the GDPR Cookie Consent plugin to store the user consent for the cookies in the category "Marketing".
cookielawinfo-checkbox-necessary
1 month
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-preferences
1 month
This cookie is set by the GDPR Cookie Consent plugin to check if the user has given consent to use cookies under the "Preferences" category.
cookielawinfo-checkbox-statistics
1 month
This cookie is set by the GDPR Cookie Consent plugin to store the user consent for the cookies in the category "Statistics".
cookielawinfo-checkbox-unclassified
1 month
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Unclassified".
CookieLawInfoConsent
1 month
Records the default button state of the corresponding category & the status of CCPA. It works only in coordination with the primary cookie.
csrftoken
1 year
This cookie is associated with Django web development platform for python. Used to help protect the website against Cross-Site Request Forgery attacks
Statistic cookies help website owners to understand how visitors interact with websites by collecting and reporting information anonymously.
Cookie
Duration
Description
AnalyticsSyncHistory
1 month
Linkedin set this cookie to store information about the time a sync took place with the lms_analytics cookie.
bcookie
2 years
LinkedIn sets this cookie from LinkedIn share buttons and ad tags to recognize browser ID.
bscookie
2 years
LinkedIn sets this cookie to store performed actions on the website.
lang
session
LinkedIn sets this cookie to remember a user's language setting.
li_gc
2 years
Linkedin set this cookie for storing visitor's consent regarding using cookies for non-essential purposes.
lidc
1 day
LinkedIn sets the lidc cookie to facilitate data center selection.
mgref
1 year
This cookie is set by Eventbrite to deliver content tailored to the end user's interests and improve content creation. It is also used for event-booking purposes.
mgrefby
1 year
This cookie is set by Eventbrite to deliver content tailored to the end user's interests and improve content creation. It is also used for event-booking purposes.
UserMatchHistory
1 month
LinkedIn sets this cookie for LinkedIn Ads ID syncing.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.
Cookie
Duration
Description
G
1 year
Cookie used to facilitate the translation into the preferred language of the visitor.
SERVERID
session
This cookie is set by Slideshare's HAProxy load balancer to assign the visitor to a specific server.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers..
Cookie
Duration
Description
_ga
2 years
The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors.
_ga_7H38LVR4Z5
2 years
This cookie is installed by Google Analytics.
_gat_gtag_UA_44804396_1
1 minute
Set by Google to distinguish users.
_gat_UA-44804396-1
1 minute
A variation of the _gat cookie set by Google Analytics and Google Tag Manager to allow website owners to track visitor behaviour and measure site performance. The pattern element in the name contains the unique identity number of the account or website it relates to.
_gcl_au
3 months
Provided by Google Tag Manager to experiment advertisement efficiency of websites using their services.
_gid
1 day
Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously.
CONSENT
2 years
YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data.
SIDCC
6 Months
The "SIDCC" cookie is used as security measure to protect users data from unauthorised access
test_cookie
15 minutes
The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies.
VISITOR_INFO1_LIVE
5 months 27 days
A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface.
YSC
session
YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
yt-remote-device-id
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
yt.innertube::nextId
never
This cookie, set by YouTube, registers a unique ID to store data on what videos from YouTube the user has seen.
yt.innertube::requests
never
This cookie, set by YouTube, registers a unique ID to store data on what videos from YouTube the user has seen.