ODI JDBC variable binding: 500% performance gains, Array Fetch Size, Batch Update Size, Row Prefetching, and the Array Interface; and an issue when running the agent in Weblogic.

Get our e-books Discover the Oracle Data Integrator 11g Repository Data Model and Oracle Data Integrator Snippets and Recipes
This is a bit of mouthful of a title. But there is a lot to cover here.
Have you ever wondered what the Array Fetch Size and Batch Update Size in the ODI Topology module are all about?

FlowForward.
All Things Data Engineering
Straight to Your Inbox!
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Row prefetching
What ODI calls Array Fetch Size is commonly known as row prefetching:
“The concept of row prefetching is straightforward. Every time an application asks the driver to retrieve a row from the database, several rows are prefetched with it and stored in client-side memory. In this way, several subsequent requests do not have to execute database calls to fetch data. They can be served from the client-side memory”. Quote from the excellent (the best?) book on Oracle performance tuning by Christian Antognini, Troubleshooting Oracle Performance.
For ODI this means that the higher you set this value the more rows will be retrieved per request to the source and then stored in the memory of the agent.
The main advantage is that you don’t have to re-read the same block multiple times from the source and as a result reduce the number of consistent gets. A database block typically holds more than one row, if you have set your Array Fetch Size to a low number, e.g. 1 and you have 5 rows on a block the database needs to read this block five times to retrieve all rows. Another advantage is that you need fewer roundtrips to the server.
Array Interface
What ODI calls Batch Update size is commonly known as the Array Interface:
“The array interface allows you to bind arrays instead of scalar values. This is very useful when a specific DML statement needs to insert or modify numerous rows. Instead of executing the DML statement separately for each row, you can bind all necessary values as arrays and execute it only once, or if the number of rows is high, you can split the execution into smaller batches.”, Christian Antognini, Troubleshooting Oracle Performance.
The advantage is that you need fewer round trips to the database and decrease network traffic.
This is applicable for any of the Knowledge Modules that use binding between source and target, e.g. LKM SQL to Oracle.
Impact on performance
Let’s see for ourselves what impact changing of these parameters has on execution times and agent memory consumption.
I will perform test runs where we set these values to 1, 30, 100, 500, 1000, and 20000. We will use the products table in the SH sample schema and pump it up to 72K records.
create table sh.products_big as
select * from sh.products a cross join
(
SELECT
level-1 n
FROM
DUAL
CONNECT BY LEVEL <= 1000
);
We will load this table into another schema on the same database using the LKM SQL to Oracle. We will use the Staging Area Different from Target to achieve this. Our interface looks as follows:
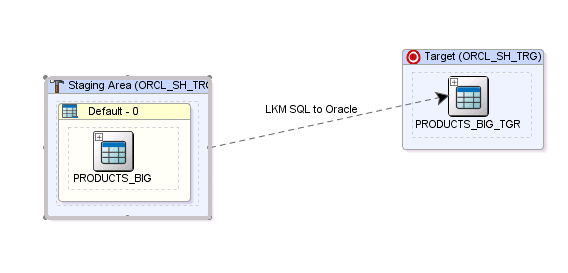
The above setup is only used for test and demonstration purposes. In a real world scenario you should use an LKM that uses database links to load from Oracle to Oracle as demonstrated in my post Load Knowledge Module Oracle to Oracle using database links.
Test case 1: Array Fetch Size and Batch Update Size at 1
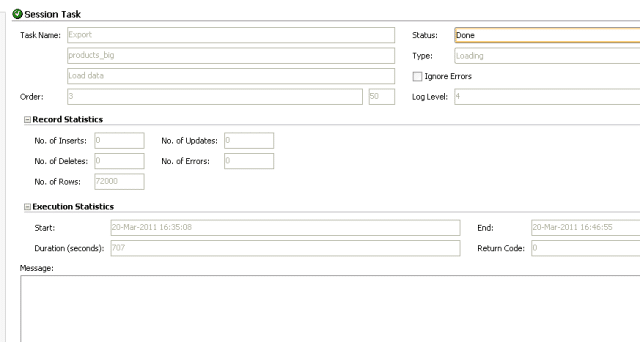
This took a whopping 707 seconds.

CPU usage of the agent is between 0 and 5%. Memory usage zig zags between 100 MB and 150 MB.
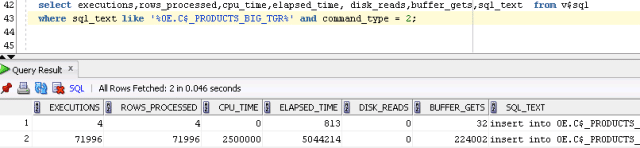
Logical I/O is at a very high 224002.
Test case 2: Array Fetch Size and Batch Update Size at 30
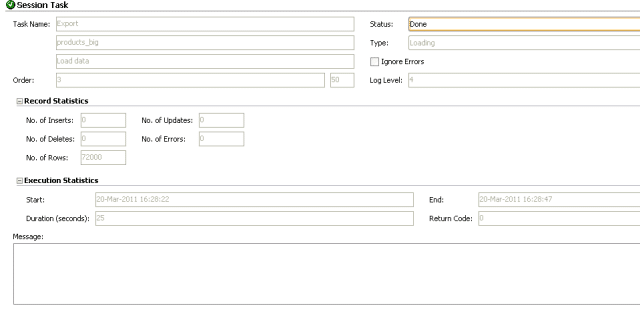
The step to load 72K records into the C$ table took 25 seconds. The step started at 16:28:22 and ended at 16:28:47.
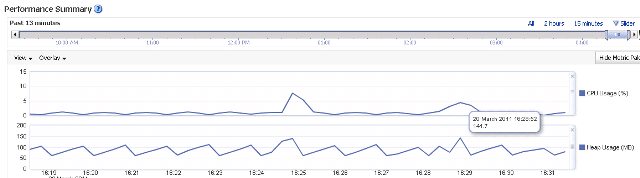
We have a peak in heap memory usage of the agent’s JVM at 16:28:52 with 141.7 MB. I am using a Weblogic (JAVA EE) agent and the Fusion Middleware Enterprise Manager to retrieve these values.
This roughly coincides with the end time of our step.
We also see some increase in CPU usage.
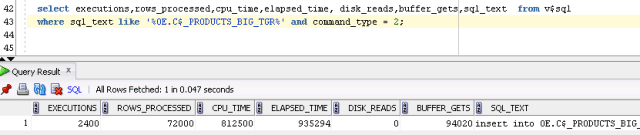
Querying v$sql shows us that the insert was executed 72000/30 = 2400 times. Logical I/O stands at 94020
Test case 3: Array Fetch Size and Batch Update Size at 100
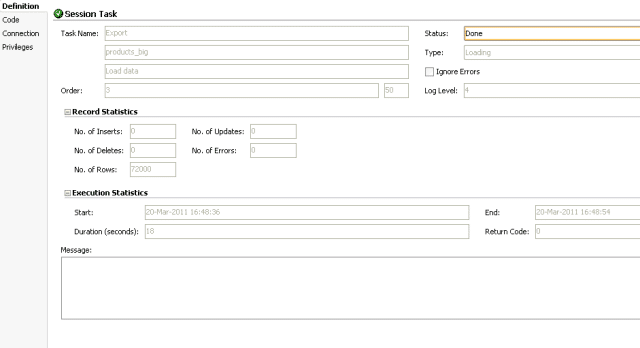
The step started at 16:48:36 and finished at 16:48:54. A delta of 18 seconds.
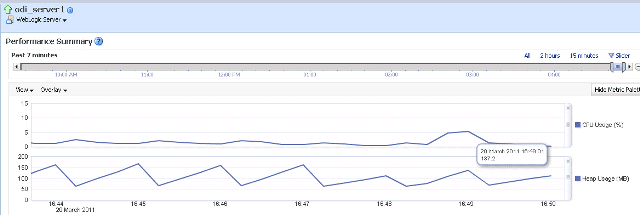
The memory peaked at 16:49:01 with 137.2 MB. CPU usage increased to about 5%.

We have 720 executions with 91196 logical I/O.
Test case 4: Array Fetch Size and Batch Update Size at 500
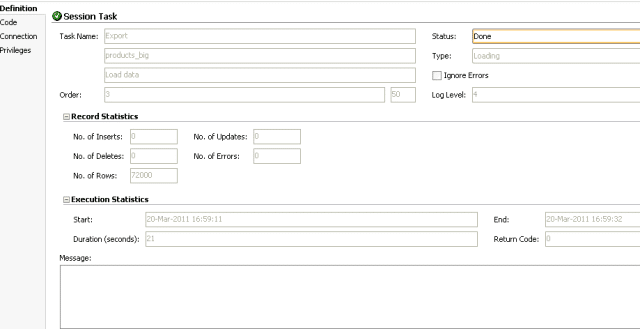
Loading of data took 21 seconds. This is not in line with expectations. An explanation follows further down.

Heap usage of agent JVM goes up to about 160 MB. CPU usage increases to about 12%.
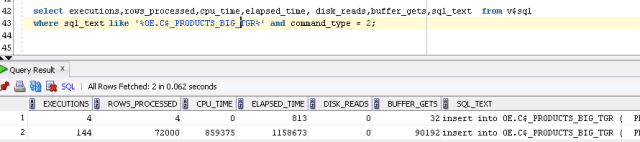
We have 144 executions with 90192 logical I/O.
Test case 5: Array Fetch Size and Batch Update Size at 1000
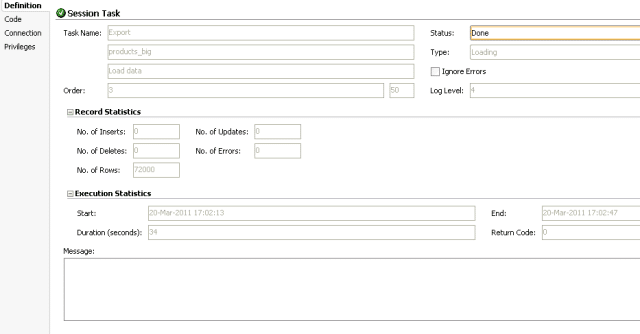
It now took 34 seconds to load data.
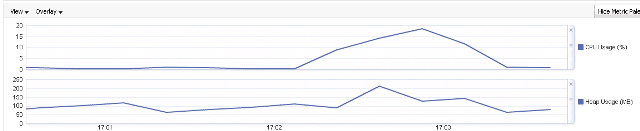
Heap usage went above 200 MB and CPU touched 20%.
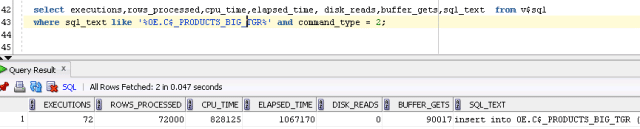
We had 72 executions with 90017 buffer gets.
Why does a setting of array size 500 and 1000 take longer to execute than the one with 100?
I was trying to find a good answer to this question but could not really come up with any. Eventually I decided to rerun test cases 4 and 5 using a standalone agent to get a second opinion.
Test case 4 rerun standalone agent
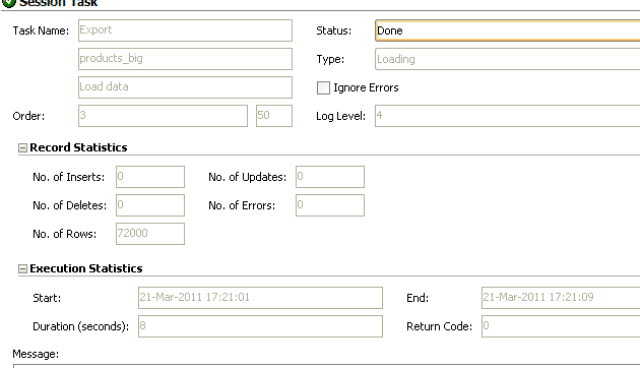
This now just took 8 seconds compared to the 21 previously with the Weblogic agent. This is more in line with expectations.

CPU usage peaked at 13%. Similar to what we got in the Weblogic agent.
Test case 5 rerun with standalone agent
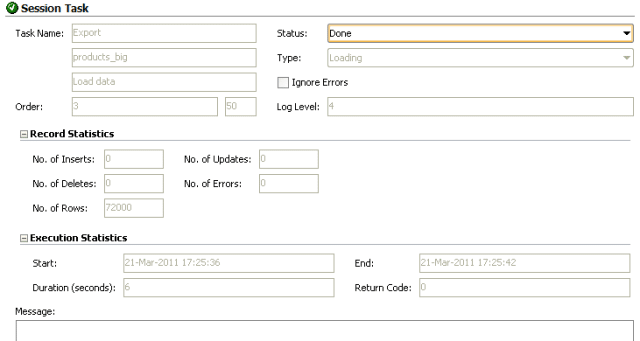
This took just 6 seconds now. A 500% performance improvement to the default settings

CPU usage peaked at 18.46%. Memory usage peaked at 124 MB.
Test case 6 Array Fetch Size and Batch Update Size at 20000

Failed initially due to insufficient agent memory.
I doubled heap allocation to 512 MB for the agent and reran.
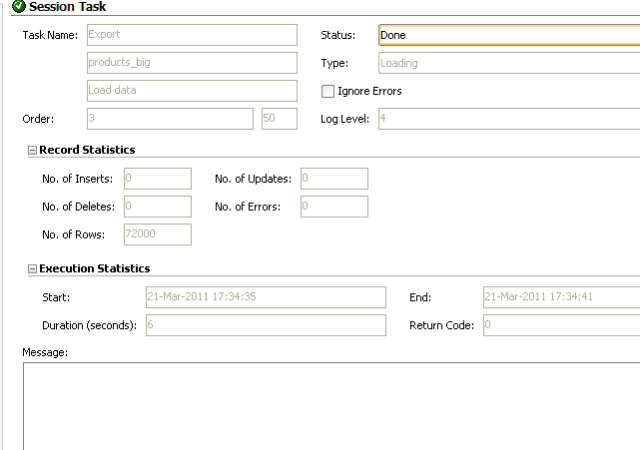
Once again it took 6 seconds.

Memory usage jumped up to 522.8 MB. CPU usage peaked at 28.03%.
Conclusion
– You can not ignore prefetch and array size in a comprehensive ODI performance tuning strategy.
– There seems to be an issue or rather some mysterious inefficiency when running the agent in Weblogic. Both the standalone agent and the Weblogic agent were using the same JDK version. This can’t be the issue then. If I find some time I will log an SR with Oracle on this.
– We get diminishing returns for increasing the array size: There comes a point when increasing the prefetch and array size becomes counter-productive as resource usage jumps up with only slightly improved response time.
– There is no such thing as a free lunch: Increasing prefetch and array size increases CPU and memory usage on the agent.
– Increasing prefetch and array size reduces the number of logical I/O.
– Finding the correct prefetch and array size is both art and science. Finding the optimal value depends on your environment (resources available, concurrency, workload etc.), and the size of the source table. As a general rule for the source table: The smaller and narrower your source table the higher you can set the prefetch and array size.
– As the optimal array and prefetch size is partly determined by the size of the source table it would make a lot more sense to be able to set the Array Fetch Size and Batch Update Size at the interface level rather than at the data server level.
Related links
David Allan from Oracle has pointed out that Data Direct have some next generation JDBC drivers for bulk loading large data volumes. There is also an LKM in ODI 11g that makes use of them.
Some performance tests for Data Direct drivers
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: 