Converting DITA XML to a database (MySQL)

In this post we will convert the DITA XML standard used in Publishing. We will convert it to a MySQL database with Sonra’s data warehouse automation tool for XML, JSON, and industry data standards Flexter.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
XML Publishing
Traditional publisher workflows rely on print-first content. The print-first workflow makes editing harder, since the entire document needs to be opened for even minor changes. It also makes it harder for the content to be prepared for conversion into different digital formats.
Some advantages of going with XML-first workflow:
- Documents that adapt easily to any publishing medium.
- Independent sections that can be modified by different editors at the same time
- Ability to do style changes globally with ease
All those advantages reduce the cost and time you need to invest into preparing a document for digital publication. It makes XML-first workflow and XML publishing the obvious choice.
DITA
The Darwin Information Typing Architecture or Document Information Typing Architecture (DITA) is an open XML standard for publishing.
It was developed to meet IBM’s requirements for technical documentation, but since DITA architecture is general it can be used for any kind of document (technical documentation, commercial Publishing, pharmaceutical information, standards, training materials and much more).
One big advantage of DITA is that it guarantees interoperability between different XML documents. You can simply extend or constrain the out-of-the-box DITA vocabulary as your understanding and requirements evolve.
[flexter_banner]
Processing masked XML with Flexter
Flexter exposes its functionality through a RESTful API. Converting XML/JSON to SQL Server can be done in a few simple steps.
Step 1 – Authenticate
Step 2 – Define Source Connection (Upload or S3) for Source Data (JSON/XML)
Step 3 – Optionally define Source Connection (Upload or S3) for Source Schema (XSD)
Step 4 – Define your Target Connection, e.g. Snowflake, Redshift, SQL Server, Oracle etc.
Step 5 – Convert your XML/JSON from Source to Target Connection
Step 1 – Authenticate
To get an access_token you need to make a call to /oauth/token with Authorization header and 3 form parameters:
- username=YOUR_EMAIL
- password=YOUR_PASSWORD
- grant_type=password
You will get your username and password from Sonra when you sign up for the service.
|
1 2 3 4 |
curl --location --request POST "https://api.sonra.io/oauth/token" \ --header "Content-Type: application/x-www-form-urlencoded" \ --header "Authorization: Basic NmdORDZ0MnRwMldmazVzSk5BWWZxdVdRZXRhdWtoYWI6ZzlROFdRYm5Ic3BWUVdCYzVtZ1ZHQ0JYWjhRS1c1dUg=" \ --data "username=XXXXXXXXX&password=XXXXXXXXX&grant_type=password" |
Example of output
|
1 2 3 4 5 6 7 8 |
{ "access_token": "eyJhbG........", "token_type": "bearer", "refresh_token": "..........", "expires_in": 43199, "scope": "read write", "jti": "9f75f5ad-ba38-4baf-843a-849918427954" } |
Step 2 – Define Source Connection (Upload) for Source Data (DITA XML)
In a second step we will upload our DITA XML source data
|
1 2 3 4 5 |
curl --location --request POST "https://api.sonra.io/data_sources/dita" \ --header "Authorization: Bearer <access_token>" \ --form "source_type=uploaded_file" \ --form "file=@<file_path>" \ --form "data_type=xml" |
Example of output
|
1 2 3 4 5 6 7 8 |
{ "name" : "dita", "type" : "xml", "source_type" : "uploaded_file", "path" : "file-06e2f2b9-84cb-4332-ae60-e10f99bf8ffd", "size" : 327765, "create_date" : "2019-10-01T13:41:02.423+0000" } |
Step 3 – Define Target Connection (MySql)
Since we don’t have a Source Schema we skip the optional step of defining a Source Schema.
We define our Target connection. We give the Target Connection a name and supply various connection parameters to the MySQL database.
|
1 2 3 4 5 6 7 |
curl --location --request POST "https://api.sonra.io/target_connections/dita" \ --header "Authorization: Bearer <access_token>" \ --form "target_type=mysql" \ --form "host=xxxxxxxxxxxxxxxxx.eu-west-1.rds.amazonaws.com" \ --form "username=user" \ --form "password=password" \ --form "database=database" |
Example of output
|
1 2 3 4 5 6 |
{ "name" : "dita", "target_type" : "mysql", "path" : "xxxxxxxxxxxxxxxxx.eu-west-1.rds.amazonaws.com", "create_date" : "2019-10-01T14:02:06.653+0000" } |
Step 4 – Convert XML data from Source Connection (Upload) to Target Connection (MySQL)
In the last step we convert DITA XML. Data will be written to MySQL Server Target Connection.
|
1 2 3 4 |
curl --location --request POST "https://api.sonra.io/conversions/dita" \ --header "Authorization: Bearer <access_token>" \ --form "data_source=dita" \ --form "target=dita" |
Example of output
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
{ "name" : "dita", "schema_source_connection" : null, "data_source_connection" : { "name" : "dita", "type" : "xml", "source_type" : "uploaded_file", "path" : "file-fa622ed6-6c93-4bd7-9901-b5d122187da3", "size" : 327765, "create_date" : "2019-10-01T13:47:50.480+0000" }, "target_connection" : { "name" : "dita", "target_type" : "dita", "path" : "xxxxxxxxxxxxxxxxxxxxxxxxxx1.rds.amazonaws.com", "create_date" : "2019-10-01T13:34:10.769+0000" }, "create_date" : "2019-10-01T13:48:04.705+0000", "status" : "I", "download_link" : null, "full_status" : "INITIALIZED" } |
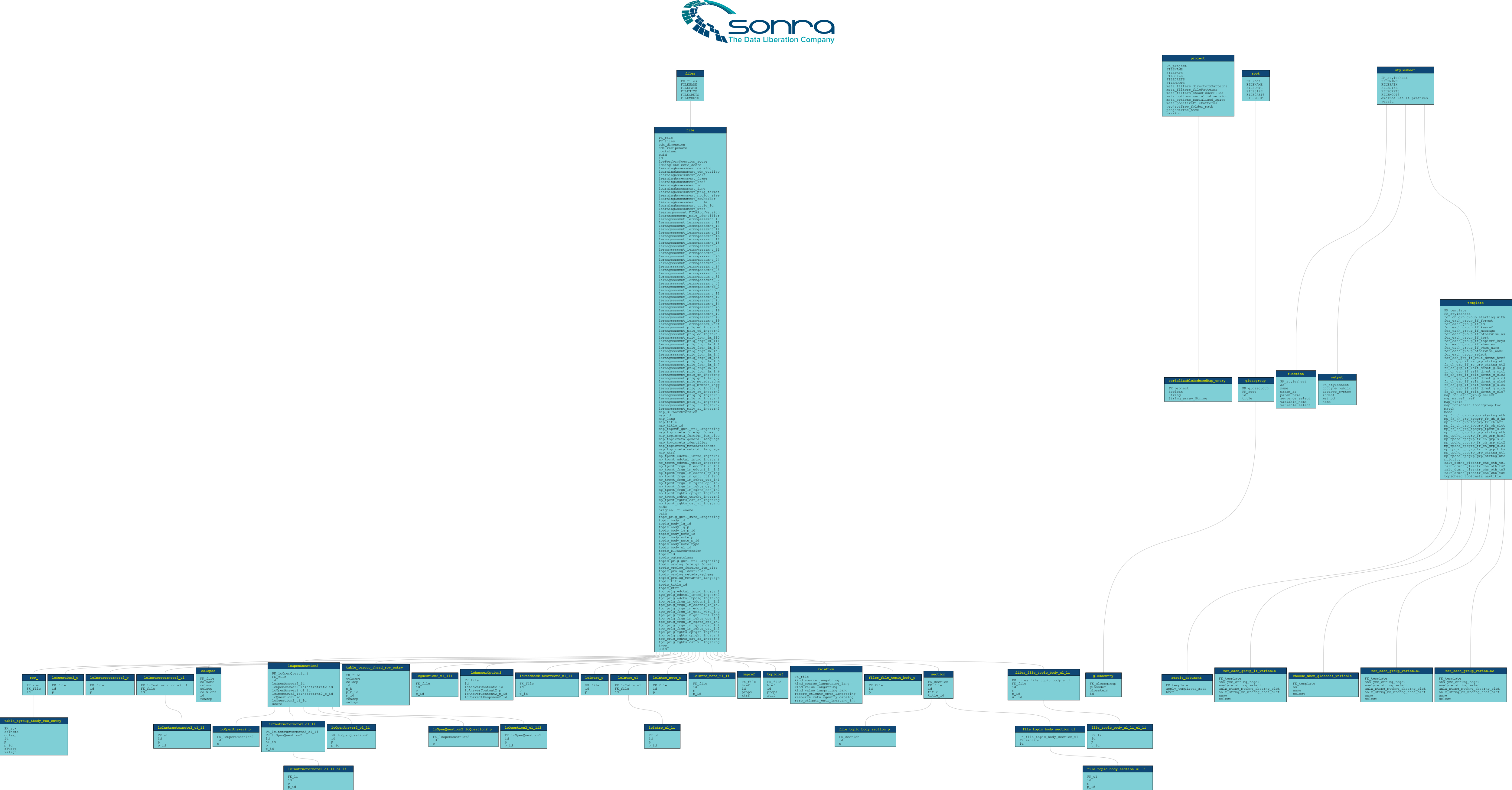
ER Diagram
We can create and download an ER Diagram of the model that Flexter generated by making a GET call.
|
1 2 |
curl --location --request GET "https://api.sonra.io/conversions/dita" \ --header "Authorization: Bearer <access_token>" |
Example of output
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
{ "name" : "dita", "schema_source_connection" : null, "data_source_connection" : { "name" : "dita", "type" : "xml", "source_type" : "uploaded_file", "path" : "file-68009cc1-1cc7-4aeb-ad3f-84dbf8ef5ebf", "size" : 327765, "create_date" : "2019-10-01T14:31:14.094+0000" }, "target_connection" : { "name" : "dita", "target_type" : "mysql", "path" : "xxxxxxxxxxxxxxxxxxxxxxxxxx1.rds.amazonaws.com", "create_date" : "2019-10-01T15:02:02.273+0000" }, "create_date" : "2019-10-01T15:02:24.844+0000", "status" : "C", "download_link" : null, "diagram_link" : "<ER Diagram Download Link>", "mapping_link" : "<Mapping Download Link>", "credit_usage" : 0, "full_status" : "COMPLETED" } |
We can just copy paste download link to the browser and the ER Diagram will be downloaded.
If you want to view the ER Diagram you can find it here.
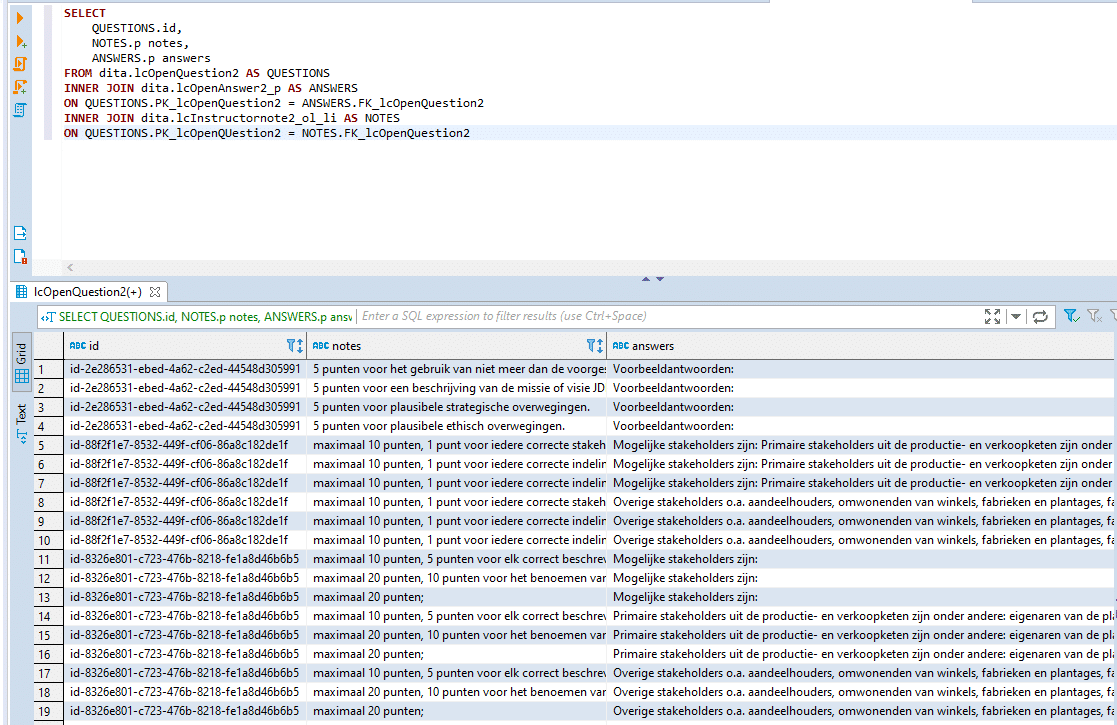
Next we will run an SQL Query that will return Question and Answer columns.
|
1 2 3 4 5 6 7 8 9 |
SELECT QUESTIONS.id, QUESTIONS.p questions, ANSWERS.p answers FROM dita.lcOpenQuestion2 AS OPEN_QUESTIONS INNER JOIN dita.lcOpenAnswer2_p AS ANSWERS ON OPEN_QUESTIONS.PK_lcOpenQuestion2 = ANSWERS.FK_lcOpenQuestion2 INNER JOIN dita.lcQuestion2_p AS QUESTIONS ON QUESTIONS.FK_File = OPEN_QUESTIONS.FK_File |
Conclusion
With DITA and Flexter you can reduce cost and time that you need to invest into publishing and converting data. This post have show you how easy and fast it is to convert your data to MySQL database with Flexter.
Our enterprise edition can be installed on a single node or for very large volumes of XML on a cluster of servers.
If you have any questions please refer to the Flexter FAQ section. You can also request a demo of Flexter or reach out to us directly.




{kind=link}