No Code XML Conversion to Oracle

In a previous post we demonstrated how to use Flexter to convert XML data into TSV files.
This was just an introduction demonstrating some basic features of Flexter including concepts around XML schema normalization and optimization.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Converting XML into an Oracle Database
This time we are going to show you a more interesting and common use case. Querying XML in the context of data analytics. Our requirement is to create some reports or dashboards over data in XML files. We could use XQuery to do this. Unfortunately, none of the BI or visualisation tools really support this. XQuery is really awkward to use and most XQuery engines don’t have support for running queries across multiple XML files. They also lack a query optimizer and as a result queries don’t perform well. Finally, very few developers possess XQuery skills. A much better approach is to convert the XML files into a relational schema in a database and use SQL, the lingua franca for data, to query it.
Loading XML into the the Oracle database using Flexter is pretty easy. Let’s take the same pain.001.001.03 schema and data example we have used before. The first step is the same: analyse the XML schema and extract the metadata to create the target schema. As we’ve done that already in the first post I’m going to skip it.
Instead we reuse the metadata and point Flexter to our Oracle database to create the target schema.
regsch {psch_name=>'SepaDB', jdbc_url=>'jdbc:oracle:thin:@//oracledemo.sonra.io:11521/orcl', login=>'edw_staging'}
provide password: *******
# target schema created:
out: 420
org: 1
Target schema registered.
Loading XML to the Oracle database
That’s it – we are now ready to process the data. It’s as simple as running Flexter’s xml2er command line tool.
-x 1496 this is to specify what is the expected layout of the XML (we processed schema in previous post)
-l 420 this is to specify where to write the output (we’ve just registered the staging schema in Oracle)
xml2er -x 1496 -l 420 tmp/sepa/pain.001.001.03.xmls.zip
18:21:09.444 INFO Registering new job
18:21:10.462 INFO Loading metadata
[Stage 1:=> (6 + 1) / 200]
[Stage 1:=> (7 + 1) / 200]
[Stage 1:==> (9 + 1) / 200]
[Stage 1:====> (15 + 1) / 200]
[Stage 1:=====> (20 + 1) / 200]
[Stage 1:=======> (27 + 1) / 200]
[Stage 1:==========> (36 + 1) / 200]
[Stage 1:============> (44 + 1) / 200]
[Stage 1:==============> (50 + 1) / 200]
[Stage 1:================> (59 + 1) / 200]
[Stage 1:===================> (69 + 1) / 200]
[Stage 1:=====================> (78 + 1) / 200]
[Stage 1:========================> (88 + 1) / 200]
[Stage 1:==========================> (93 + 1) / 200]
[Stage 1:=============================> (106 + 1) / 200]
[Stage 1:=================================> (120 + 1) / 200]
[Stage 1:====================================> (134 + 1) / 200]
[Stage 1:========================================> (147 + 1) / 200]
[Stage 1:==========================================> (155 + 1) / 200]
[Stage 1:=============================================> (166 + 1) / 200]
[Stage 1:=================================================> (180 + 1) / 200]
[Stage 1:=====================================================> (195 + 1) / 200]
18:21:22.838 INFO Parsing data
18:21:28.197 INFO calculating data
18:21:33.275 INFO creating table GrpHdr_InitgPty_Id_OrgId_Othr
18:21:33.290 INFO creating table GrpHdr_InitgPty_Id_PrvtId_Othr
18:21:33.291 INFO creating table Document
18:21:33.296 INFO creating table CdtTrfTxInf_Cdtr_Id_OrgId_Othr
18:21:33.296 INFO creating table CdtTrfTxInf
18:21:33.318 INFO creating table Cdtr_PstlAdr_AdrLine
18:21:33.319 INFO creating table Strd
18:21:33.320 INFO creating table Ustrd
18:21:33.320 INFO creating table UltmtCdtr_Id_OrgId_Othr
18:21:33.320 INFO creating table PmtInf_Dbtr_Id_OrgId_Othr
18:21:33.320 INFO creating table PmtInf_Dbtr_PstlAdr_AdrLine
18:21:33.320 INFO creating table PmtInf
18:21:33.323 INFO creating table PmtInf_UltmtDbtr_Id_OrgId_Othr
18:21:37.564 INFO writing tables
18:21:37.568 INFO writing table GrpHdr_InitgPty_Id_OrgId_Othr
18:21:39.688 INFO writing table GrpHdr_InitgPty_Id_PrvtId_Othr
18:21:39.952 INFO writing table Document
18:21:40.269 INFO writing table CdtTrfTxInf_Cdtr_Id_OrgId_Othr
18:21:40.480 INFO writing table CdtTrfTxInf
18:21:40.936 INFO writing table Cdtr_PstlAdr_AdrLine
18:21:41.156 INFO writing table Strd
18:21:41.396 INFO writing table Ustrd
18:21:41.641 INFO writing table UltmtCdtr_Id_OrgId_Othr
18:21:41.847 INFO writing table PmtInf_Dbtr_Id_OrgId_Othr
18:21:42.066 INFO writing table PmtInf_Dbtr_PstlAdr_AdrLine
18:21:42.297 INFO writing table PmtInf
18:21:42.585 INFO writing table PmtInf_UltmtDbtr_Id_OrgId_Othr
18:21:43.041 INFO calculating statistics
18:21:43.359 INFO writing statistics rows
18:21:43.719 INFO Registering success of job 3750
18:21:43.732 INFO Finished successfully in 58030 milliseconds
# schema
xml: 1496
logical: 420
org: 1
job: 3750
# statistics
load: 37137 ms
parse: 5359 ms
schema: 9366 ms
write: 5210 ms
stats: 946 ms
xpaths: 515
As per our previous post when we were parsing XML into TSV files we have created the same 13 datasets. This time as regular Oracle tables.
Pain of loading XML to a Database
Pretty simple, right? Compare this to the manual steps it takes to load the data into a database:
- the XML needs to be manually normalized
- the target tables need to be modelled in the database
- table relationships need to be established and created
- surrogate keys for parent-child relationships need to be generated.
- keys need to be globally unique (no conflicts when loading multiple XML files)
- each target table needs to be mapped manually
- each mapping needs to be orchestrated into a data flow
- each source XML file needs to be loaded into the target schema
As you can imagine this is very labour intensive and boring. It also requires a lot of time to implement.
Benefits of using Flexter to load XML to a Database
With Flexter the whole process is quick and fully automated. Developers can focus on creating real value, e.g. writing the SQL to generate reports or loading and integrating the data into a data warehouse.
What makes the analysis or downstream development even easier and faster is the fact that the number of the tables has been highly reduced by applying some of Flexter’s optimization algorithms. From 940 possible XML entities we went down to just 13 relational tables populated with data:
|
XSD |
xsd2er |
XML map (940 entities) |
calcmap |
logical Layout (58 tables) |
xml2er |
Target (13 tables) |
|
→ |
→ |
→ | ||||
|
schema |
layout |
xml data |
This simply means less (a lot less!) tables to focus on when working with the output:
less tables → less joins → optimized performance
In terms of supported target platforms Flexter works with multiple RDBMS engines, e.g. Oracle, DB2, Teradata etc.. Besides TSV files, Flexter can also generate Parquet files which can be loaded into your Data Lake, and read through Hive, Impala, Spark, Drill, Flink or a similar data processing engine.
NDC. A more complex schema example
940 XML elements seems like a lot. In fact most industry XML standards contain a lot more. Their schemas are often highly modularized and with multiple XSD files that cross-reference each other. In those complex XML schemas we typically have one or two XSD files that contain all of the reusable types – reference data in other words. The other XSDs typically contain different types of transactions or messages, e.g. bookings or orders.
To illustrate this better, let’s take a look at the NDC (New Distribution Capability) XML standard. This standard is developed by IATA.
The list of XSD files and modules is quite comprehensive (60!):
ls -lS Flexter/data/NDC/ndc-XMLSchemas-master/*.xsd -rwxr-xr-x 1 flexter 1264395 Jan 20 2016 edist_commontypes.xsd -rwxr-xr-x 1 flexter 149654 Jan 20 2016 edist_structures.xsd -rwxr-xr-x 1 flexter 66901 Jan 20 2016 ItinReshopRS.xsd -rwxr-xr-x 1 flexter 37806 Jan 20 2016 OrderListRQ.xsd -rwxr-xr-x 1 flexter 33067 Jan 20 2016 OrderChangeRQ.xsd -rwxr-xr-x 1 flexter 31845 Jan 20 2016 OrderCreateRQ.xsd -rwxr-xr-x 1 flexter 31242 Jan 20 2016 OrderRetrieveRQ.xsd -rwxr-xr-x 1 flexter 30388 Jan 20 2016 OrderViewRS.xsd -rwxr-xr-x 1 flexter 29101 Jan 20 2016 AirShoppingRQ.xsd -rwxr-xr-x 1 flexter 19996 Jan 20 2016 FlightPriceRS.xsd -rwxr-xr-x 1 flexter 19681 Jan 20 2016 AirShoppingRS.xsd -rwxr-xr-x 1 flexter 19128 Jan 20 2016 ItinReshopRQ.xsd -rwxr-xr-x 1 flexter 17494 Jan 20 2016 ShopProductRS.xsd -rwxr-xr-x 1 flexter 16877 Jan 20 2016 BaggageChargesRS.xsd -rwxr-xr-x 1 flexter 16623 Jan 20 2016 BaggageChargesRQ.xsd -rwxr-xr-x 1 flexter 16533 Jan 20 2016 OrderHistoryRS.xsd -rwxr-xr-x 1 flexter 15739 Jan 20 2016 SeatAvailabilityRS.xsd -rwxr-xr-x 1 flexter 15494 Jan 20 2016 ServicePriceRQ.xsd -rwxr-xr-x 1 flexter 15196 Jan 20 2016 SeatAvailabilityRQ.xsd -rwxr-xr-x 1 flexter 14971 Jan 20 2016 ServiceListRQ.xsd -rwxr-xr-x 1 flexter 14647 Jan 20 2016 ServicePriceRS.xsd -rwxr-xr-x 1 flexter 14420 Jan 20 2016 FlightPriceRQ.xsd -rwxr-xr-x 1 flexter 14330 Jan 20 2016 ServiceListRS.xsd -rwxr-xr-x 1 flexter 14092 Jan 20 2016 BaggageAllowanceRS.xsd -rwxr-xr-x 1 flexter 14062 Jan 20 2016 OrderHistoryNotif.xsd -rwxr-xr-x 1 flexter 13938 Jan 20 2016 BaggageAllowanceRQ.xsd -rwxr-xr-x 1 flexter 13755 Jan 20 2016 AirDocDisplayRS.xsd -rwxr-xr-x 1 flexter 13620 Jan 20 2016 OrderChangeNotif.xsd -rwxr-xr-x 1 flexter 13604 Jan 20 2016 BaggageListRQ.xsd -rwxr-xr-x 1 flexter 12418 Jan 20 2016 BaggageListRS.xsd -rwxr-xr-x 1 flexter 11231 Jan 20 2016 AirDocRefundRS.xsd -rwxr-xr-x 1 flexter 11201 Jan 20 2016 InvGuaranteeRQ.xsd -rwxr-xr-x 1 flexter 11113 Jan 20 2016 ShopProductRQ.xsd -rwxr-xr-x 1 flexter 10956 Jan 20 2016 xmldsig-core-schema.xsd -rwxr-xr-x 1 flexter 10680 Jan 20 2016 FileRetrieveRS.xsd -rwxr-xr-x 1 flexter 10501 Jan 20 2016 OrderCancelRS.xsd -rwxr-xr-x 1 flexter 10197 Jan 20 2016 CustomerInputRS.xsd -rwxr-xr-x 1 flexter 10132 Jan 20 2016 OrderListRS.xsd -rwxr-xr-x 1 flexter 9442 Jan 20 2016 InvGuaranteeRS.xsd -rwxr-xr-x 1 flexter 8450 Jan 20 2016 CustomerInputRQ.xsd -rwxr-xr-x 1 flexter 6513 Jan 20 2016 FareRulesRQ.xsd -rwxr-xr-x 1 flexter 6084 Jan 20 2016 FareRulesRS.xsd -rwxr-xr-x 1 flexter 6014 Jan 20 2016 AirDocCancelRS.xsd -rwxr-xr-x 1 flexter 5963 Jan 20 2016 AirDocHistoryRS.xsd -rwxr-xr-x 1 flexter 5695 Jan 20 2016 AirDocVoidRS.xsd -rwxr-xr-x 1 flexter 5563 Jan 20 2016 InvReleaseNotif.xsd -rwxr-xr-x 1 flexter 5039 Jan 20 2016 AirDocIssueRQ.xsd -rwxr-xr-x 1 flexter 4913 Jan 20 2016 AirDocExchangeRQ.xsd -rwxr-xr-x 1 flexter 4719 Jan 20 2016 AirDocDisplayRQ.xsd -rwxr-xr-x 1 flexter 4372 Jan 20 2016 FileRetrieveRQ.xsd -rwxr-xr-x 1 flexter 4009 Jan 20 2016 OrderRulesRS.xsd -rwxr-xr-x 1 flexter 3880 Jan 20 2016 AirDocCancelRQ.xsd -rwxr-xr-x 1 flexter 3800 Jan 20 2016 AirDocRefundRQ.xsd -rwxr-xr-x 1 flexter 3661 Jan 20 2016 OrderCancelRQ.xsd -rwxr-xr-x 1 flexter 3616 Jan 20 2016 OrderRulesRQ.xsd -rwxr-xr-x 1 flexter 3449 Jan 20 2016 OrderHistoryRQ.xsd -rwxr-xr-x 1 flexter 3258 Jan 20 2016 _GlobalNamingTest.xsd -rwxr-xr-x 1 flexter 2237 Jan 20 2016 Acknowledgement.xsd -rwxr-xr-x 1 flexter 2223 Jan 20 2016 AirDocVoidRQ.xsd -rwxr-xr-x 1 flexter 2156 Jan 20 2016 AirDocHistoryRQ.xsd
We can use Flexter to show us all of the root elements across the 60 XSDs. From this information we get an overview on the type of messages and data we are dealing with. Let’s run the Flexter xsd2er tool with a couple of extra options:
xsd2er -s -RF /mapr/prd.hw.sonra.io/tmp/ndc/
-s Skip writing to Flexter’s metadata repository (dry run)
-R Unreferenced elements will be considered roots
-F Unreferenced files will be considered root files
For each XSD, Flexter prints out the root elements and types that were detected
⋮ 11:30:37.201 INFO Root elements: Acknowledgement.xsd - Acknowledgement edist_structures.xsd - MetadataKey - DateTime - Day - MonthYear - ShortDate - Timestamp - Year - YearMonth FileRetrieveRS.xsd - FileRetrieveRS - MediaDescriptions FlightPriceRQ.xsd - FlightPriceRQ FlightPriceRS.xsd - FlightPriceRS edist_commontypes.xsd - ISO_CurrencyCode - MessageCurrencies - MediaID - MediaAttachment - CampaignReferral - PaymentForms - AwardRedemption - AdjustedFixedAmount ⋮
As you can see, the edist_comontypes.xsd contains a lot of different types such as Currencies or PaymentForms. These types are the reusable reference data of the standard. The output from Flexter (represented in the diagram below) visualises this information and gives us a nice overview of the standard in general. For each XSD file we get a list of the available types.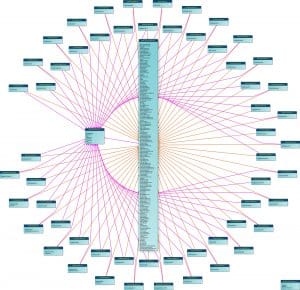
XML Processing with the NDC Standard
Let’s see Flexter in action. We have collected some sample data for the FlightPriceRS type, which if you remember from the output above is one of the XSD files. As usual, we analyse the schema in a first step. We will use an extra filter to only process the FlightPriceRS type as this is the one that we have sample data for.
xsd2er -r FlightPriceRS /mapr/prd.hw.sonra.io/tmp/ndc/
⋮
06:56:34.254 INFO Root elements:
FlightPriceRS.xsd
- FlightPriceRS
- PricedFlightOffer
06:56:34.260 INFO Building metatada
06:56:34.703 INFO Writing metatada
06:56:49.946 INFO Registering success of job 117
06:56:50.007 INFO Finished successfully in 21178 milliseconds
# schema
schemaXml: 36
org: 1
job: 117
elements: 4012
# statistics
load: 2605 ms
parse: 2823 ms
build: 447 ms
write: 15244 ms
This resulted in 4012 entry elements. The root element filter for FlightPriceRS we applied above reduced the number of elements. Out of curiosity, we analysed the whole XSD (all 60 files and not just the FlightPriceRS XSD) and this resulted in a whopping 219k XML elements. I won’t make an attempt to visualise that here 😉
Calculating the target schema and mapping is next on our list. We will use both of Flexter’s optimization modes
Elevation. This optimization detects one-to-one relationships and merges them into parent entities
Reusability. This optimization de-duplicates the occurrence of reference tables. Without this optimization we would get a separate table each time a reference type is used. (single, multi-parent table if the type referenced multiple times)
calcmap -x 36 -l 421 {true, true}
Let’s process the sample data straight away:
xml2er -x 36 -l 421 /mapr/dev.sonra.io/tmp/ndc/NDC.FlightPriceRS/
this time we will store the result into Flexter’s metadata repository.
⋮
11:35:17.573 INFO writing tables
11:35:17.577 INFO writing table FlightPriceRS
11:35:26.929 INFO writing table PricedFlightOfferAssocType
11:35:27.198 INFO writing table FlightSegmentReference
11:35:27.394 INFO writing table FareComponentType
11:35:27.936 INFO writing table Remark
11:35:28.149 INFO writing table Detail1
11:35:28.398 INFO writing table Amount
11:35:28.643 INFO writing table SegmentReferences
11:35:28.845 INFO writing table Media2
11:35:29.104 INFO writing table Flight
11:35:29.406 INFO writing table AnonymousTraveler
11:35:29.636 INFO writing table OriginDestination
11:35:29.850 INFO writing table FlightSegment
11:35:30.227 INFO writing table Service
11:35:30.787 INFO writing table Descriptions_Description1
11:35:31.041 INFO writing table Associations
11:35:31.291 INFO writing table Price
11:35:31.612 INFO writing table PriceClass
11:35:31.884 INFO writing table PricedFlightOffer
11:35:32.229 INFO writing table PricedFlightOffer_OfferPrice
11:35:32.631 INFO writing table OtherMetadata
11:35:32.837 INFO writing table AugPointType
11:35:33.105 INFO writing table DescriptionMetadata
11:35:33.349 INFO writing table CurrencyMetadata
11:35:34.173 INFO calculating statistics
11:35:34.833 INFO Removing RDD 124 from persistence list
11:35:34.859 INFO writing new xpaths
11:35:35.291 INFO writing statistics rows
11:35:35.909 INFO Registering success of job 3823
11:35:35.928 INFO Finished successfully
# schema
xml: 1507
logical: 439
org: 1
job: 3823
Let’s focus on the output now. Flexter was able to reduce the target schema to just 24 tables!. Flexter’s optimizations did a great job. We now have 99.5% less tables to query, join and analyse.
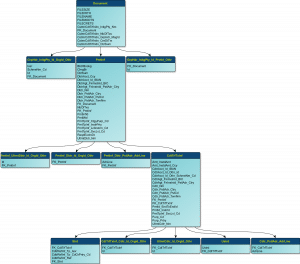
If we compare the input schema of the XSD to the final target schema in the database we see the difference straight away. Pretty impressive.

Source Schema (if we don’t apply any optimizations this would be the Target Schema as well)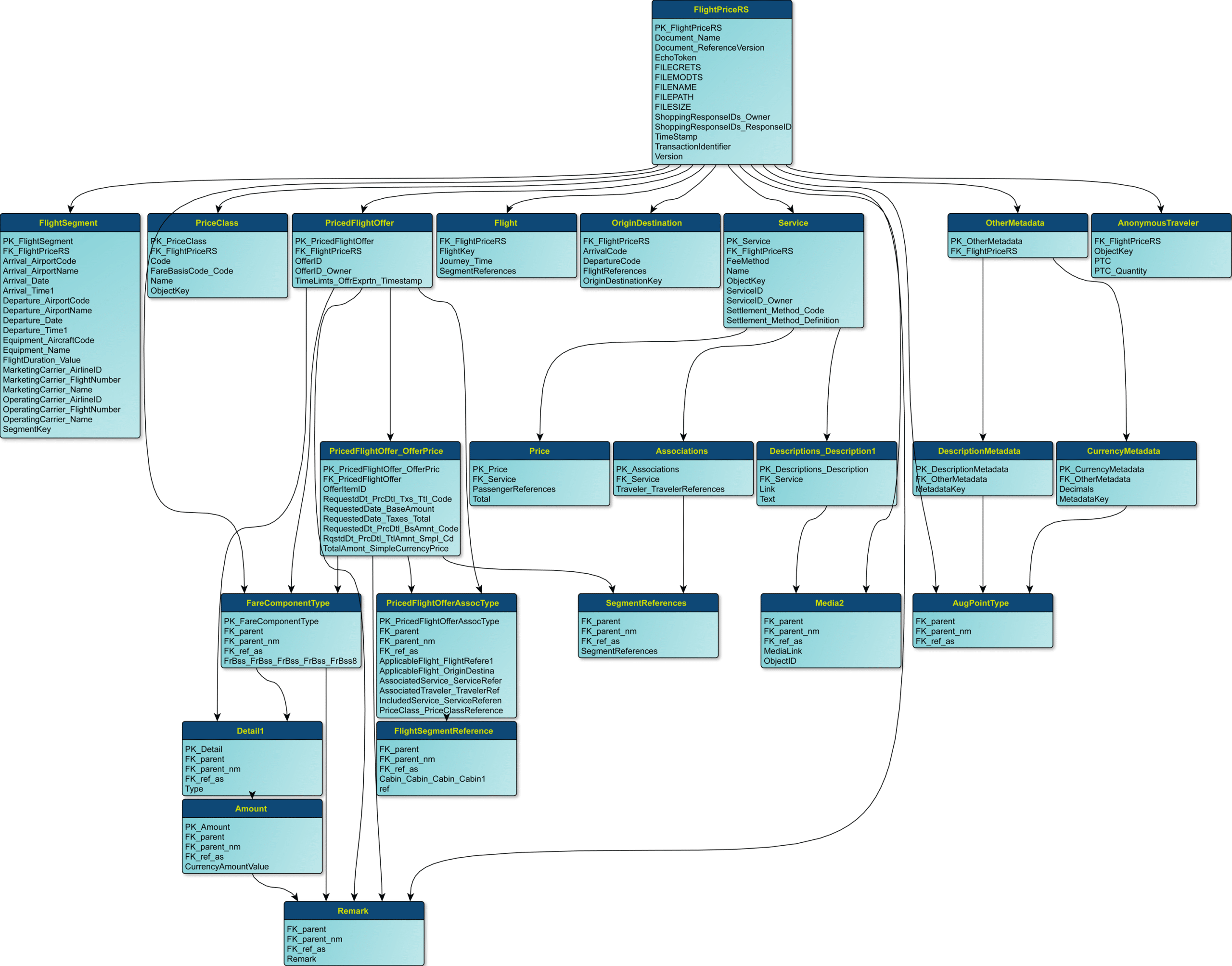
Flexter Data Lineage. From XML Source elements to Oracle table columns
You might think that this is pretty awesome. But hold on, there is even more. If you check the staging schema generated by Flexter you will notice that tables and columns are commented. The commentary provides source to target mappings, e.g. we can see that column JOURNEY_TIME comes from /FlightPriceRS/DataLists/FlightList/Flight/Journey/Time.
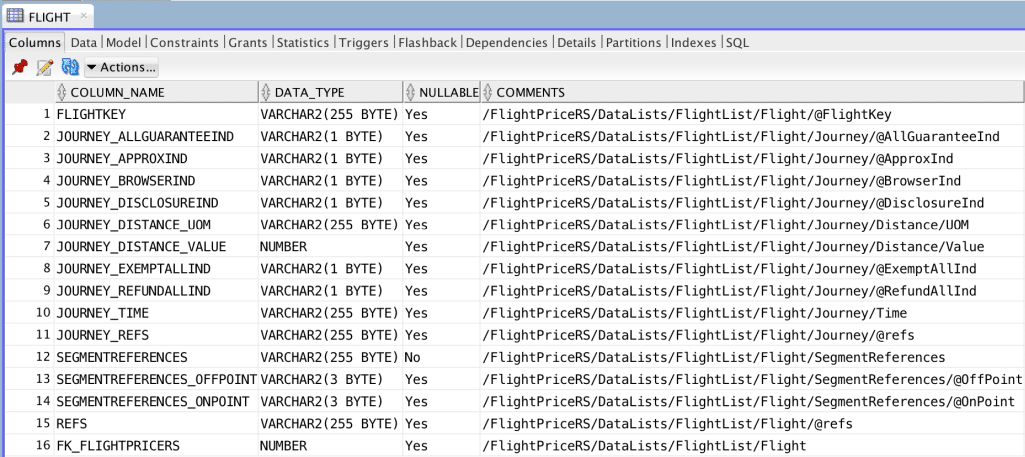
Flexter also provides full documentation on data lineage and the mappings:
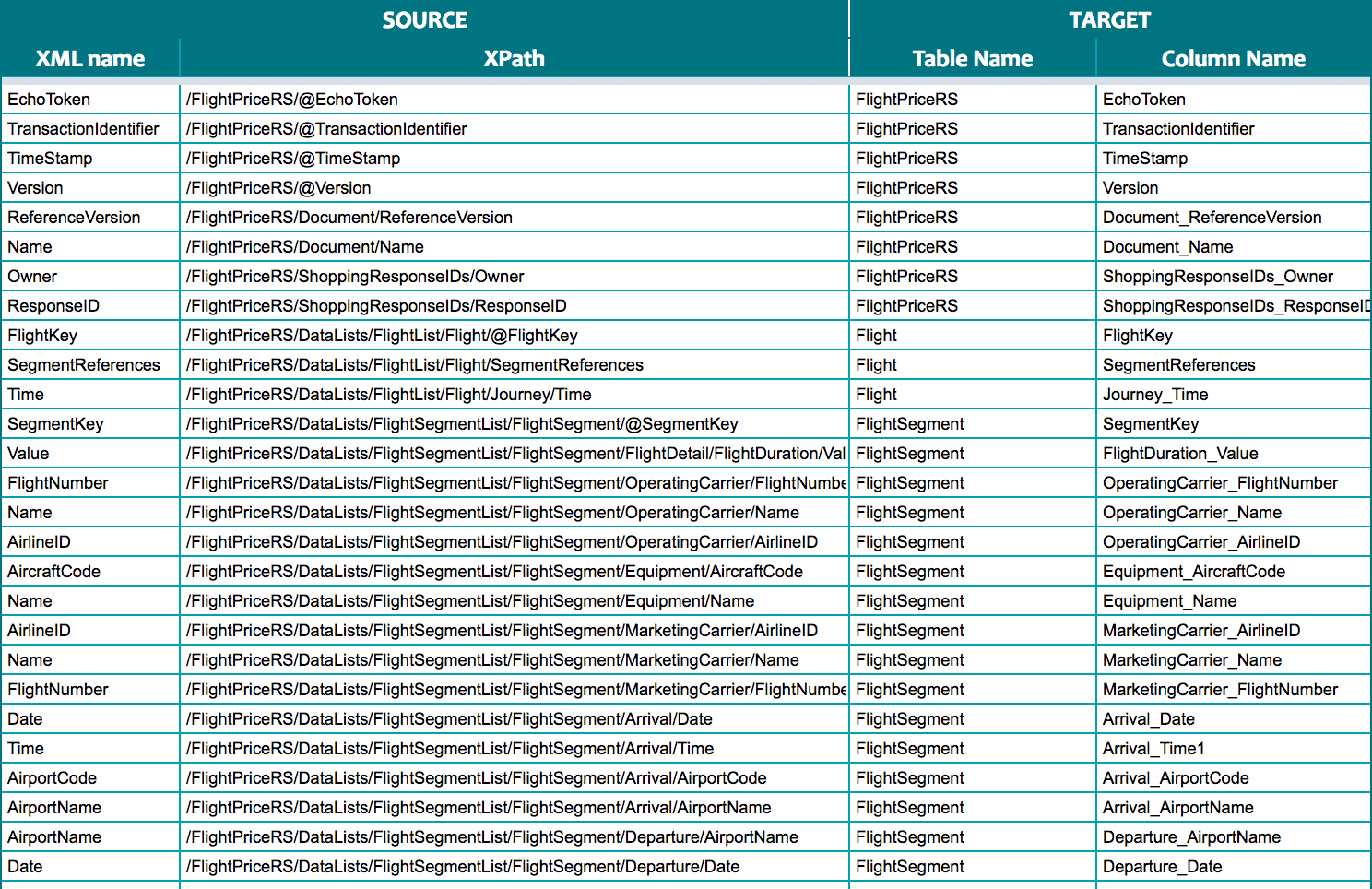
Both data lineage and the optimized target schema make it easy and fast to query, analyse, and visualise our flight data for downstream data analytics and reporting.
SELECT r.fileName, r.fileSize, r.fileModTS, f.flightKey, f.journey_time, f.segmentReferences ,fs.departure_airportCode, fs.departure_date, fs.departure_time1 ,fs.arrival_airportCode, fs.arrival_date, fs.arrival_time1 ,fs.operatingCarrier_name, fs.equipment_name, fs.marketingCarrier_flightNumber ,pfo.timeLimts_offrExprtn_timestamp ,a.currencyAmountValue FROM FLIGHTPRICERS r JOIN FLIGHT f ON f.fk_flightpricers=r.pk_flightpricers JOIN FLIGHTSEGMENT fs ON fs.fk_flightpricers=r.pk_flightpricers JOIN PRICEDFLIGHTOFFER pfo ON pfo.fk_flightpricers=r.pk_flightpricers JOIN FARECOMPONENTTYPE fct ON fct.fk_parent=pfo.pk_pricedflightoffer JOIN DETAIL1 d ON d.fk_parent=fct.pk_farecomponenttype JOIN AMOUNT a ON a.fk_parent=d.pk_detail
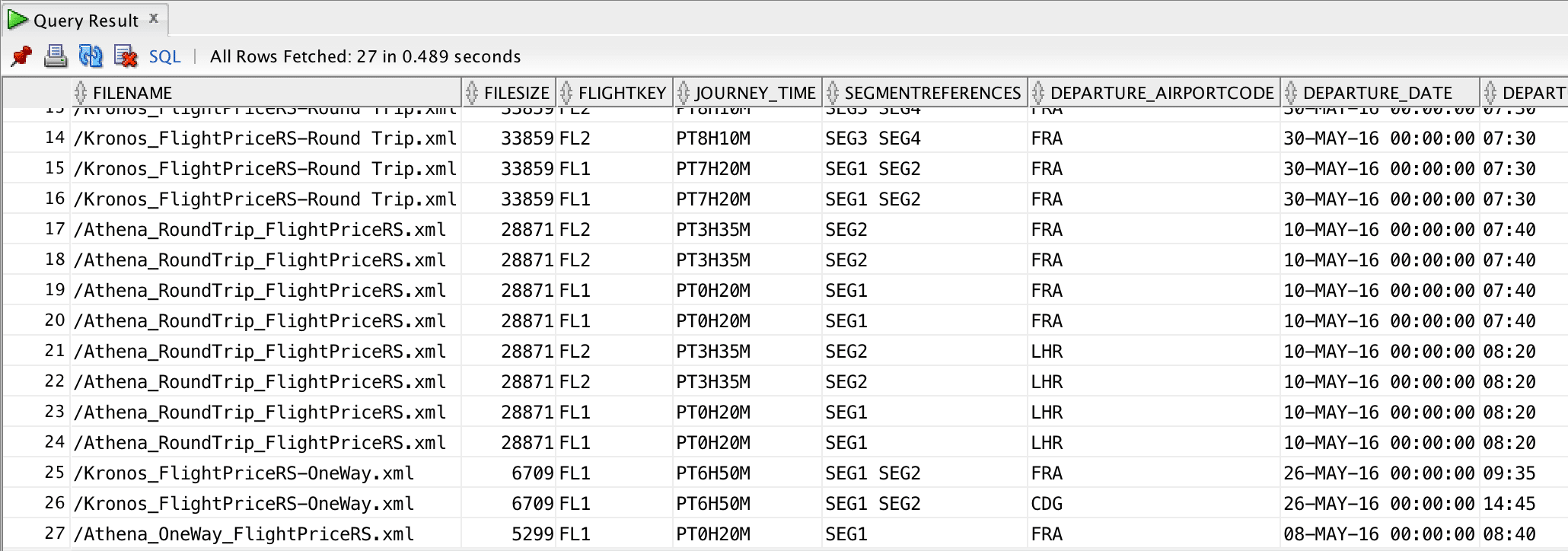
One last thing to notice is the extra columns Flexter generates that allow querying of some of the metadata, like source filename, size, last modification timestamp etc… which might be very useful for XML content validation, reconciliation, troubleshooting etc…
Which data formats apart from XML also give you the heebie jeebies and need to be liberated? Please leave a comment below or reach out to us.