SQL on Hadoop, BigQuery, or Exadata. Please don’t call them MPP.

I often hear people referring to SQL engines running against HDFS or object storage as MPP. Strictly speaking this is incorrect. Let me first explain what an MPP database is and then explain why engines such as Presto etc. should not be called an MPP engine.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
MPP
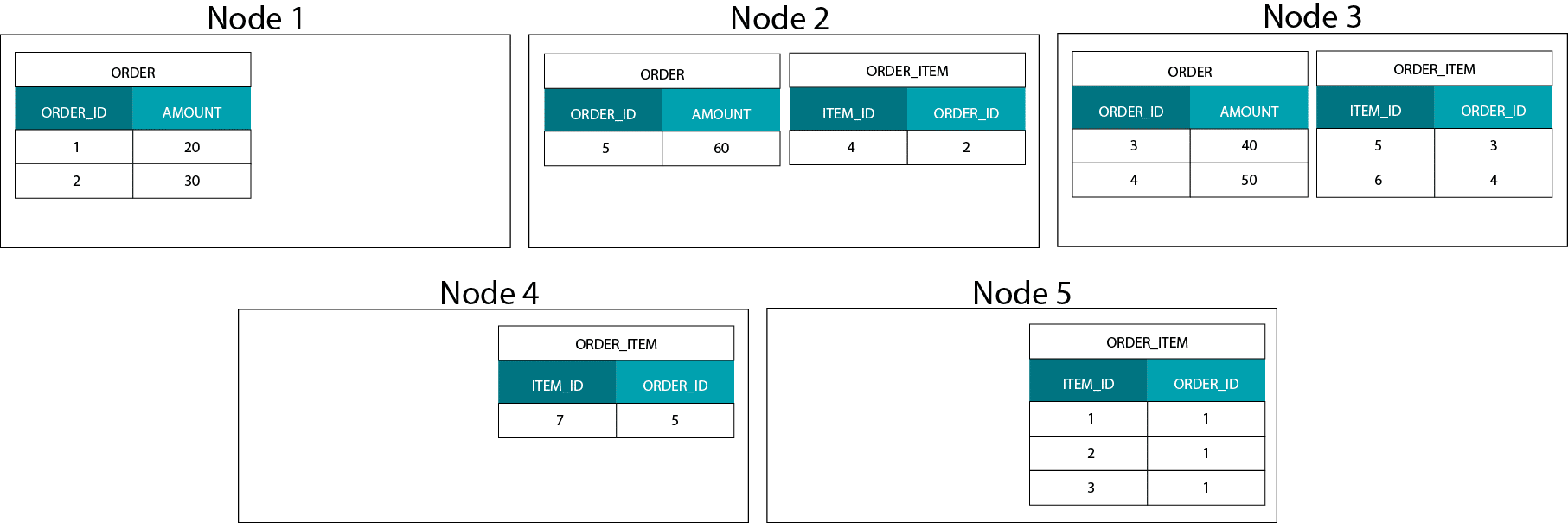
In an MPP engine we evenly distribute data across all of the nodes in a cluster. If we have a transaction table such as ORDER with 100 M rows and 10 nodes then (ignoring data skew) each node will get 10 M rows. When we run a query on our cluster then (typically) all of the nodes take part in processing this data. If we now have a second transaction table ORDER_ITEM we can co-locate order items for the same order on the same node using the ORDER_ID as distribution key. The big advantage of data co-location is that joins between ORDER and ORDER_ITEM are fast because no data needs to travel across the network. Here is an image that should illustrate the point.
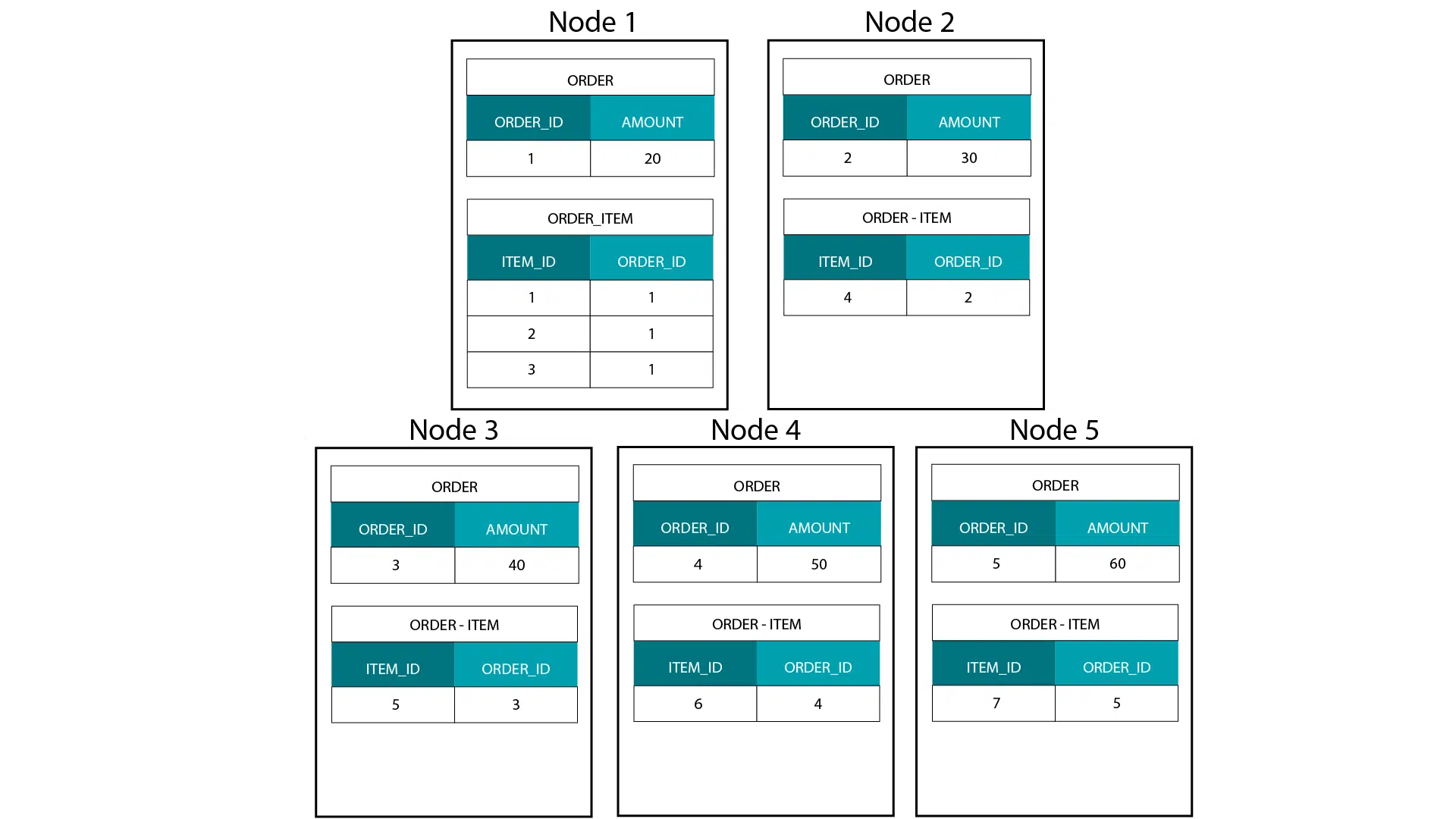
The other important concept that we need to understand in relation to an MPP is that all nodes take part in the processing when we run a query against the ORDER or ORDER_ITEM table or join them together.
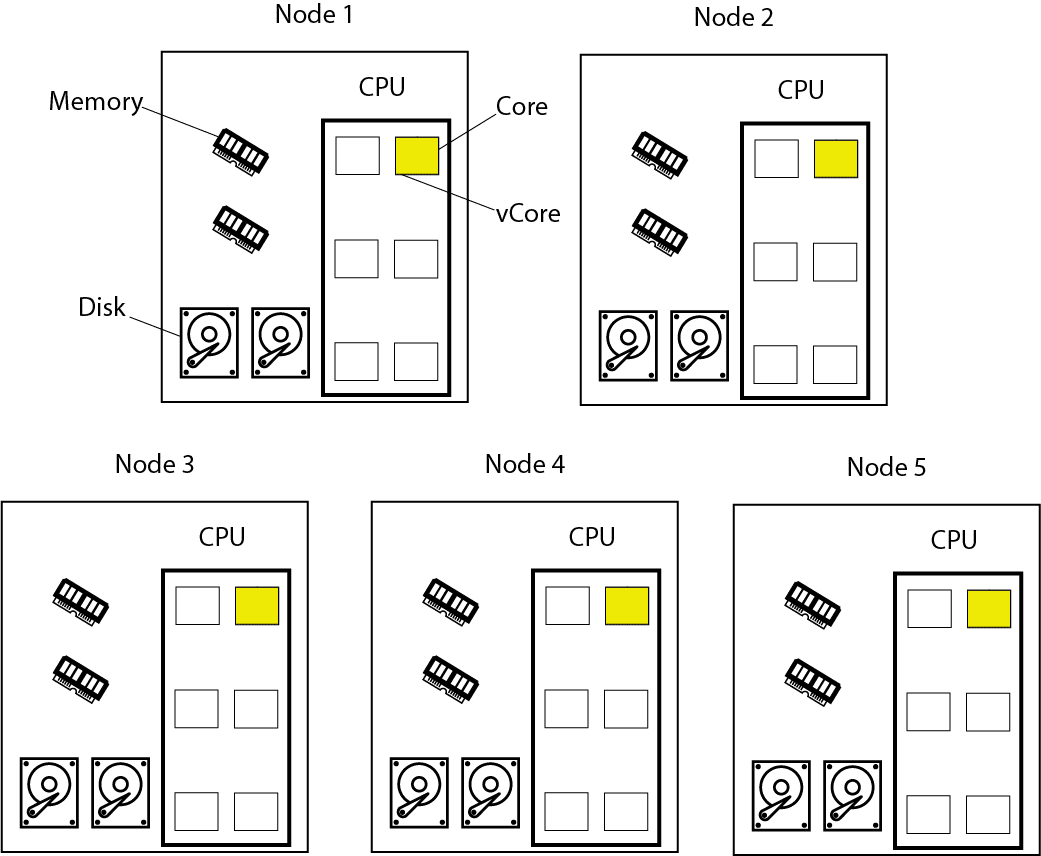
Hadoop/HDFS
So what happens on Hadoop or more correctly when we run SQL against HDFS? On HDFS we don’t distribute data at the granular row level across the cluster. Rather we take big chunks of data and spread them around the cluster based on some internal algorithm that we typically don’t have any control over. We can’t co-locate data.
Neither is there the concept of a distribution key on HDFS. As data is not evenly distributed across all nodes in the cluster not all of the nodes participate in processing.
SQL on Hadoop
When we use an SQL engine such as Presto or Impala against HDFS not all of the nodes take part in processing the data. For joins of very large tables there is a high probability that data needs to travel across the network to be joined together. One exception here is running Impala against Kudu storage. Kudu storage follows the same paradigm as traditional MPP databases with a distribution key and evenly spread data across the nodes in a cluster.
BigQuery
What about BigQuery? BigQuery is built on conceptually similar technology than SQL engines on Hadoop. It is also based on a distributed file system. In this case ColossusFS a proprietary distributed file system developed by Google. You can think of BigQuery as Hadoop SQL on steroids.
Exadata
What about Exadata? Exadata separates storage cells from compute cells. The data is stored on the storage cells and only transferred to the compute cells when data is queried. Similar to HDFS, data is not co-located. Exadata relies on storage indexes, predicate pushdown, columnar projection, and extensive caching on compute cells to achieve high performance.
Final thoughts
I accept that there are other definitions for MPP, e.g. any system that executes SQL on a distributed system in parallel. I disagree with this definition as it blurs the significant differences between these systems and as a result is less concise. If we want to trace back the in my opinion incorrect usage of MPP we should start with the time when Hadoop vendors started to market Hadoop SQL engines not using MapReduce as an execution engine. They probably thought that MPP is associated with fast performance and as a result stuck the label (incorrectly) to their very own SQL engines.
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: