Deep dive on caching in Snowflake

In this post we will explain the clever caching strategies Snowflake uses for performance optimization. In the process we will also cover related internals of Snowflake.
A lot of information is from the official research paper created by the Snowflake authors which explains the architecture of Snowflake in depth.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Caching in virtual warehouses
Snowflake strictly separates the storage layer from computing layer.
The database storage layer (long-term data) resides on S3 in a proprietary format. This means you can store your data using Snowflake at a pretty reasonable price and without requiring any computing resources.
The database compute layer (virtual warehouses), which has to be turned on for data loading, manipulation or querying, uses AWS EC2 instances to perform computation on your data. Each EC2 instance has a SSD disk along with RAM memory.
When the user runs a query on Snowflake, the data is read from the database storage layer (cold data) on S3 into the memory of EC2 instance where operations are performed.
What is important is that the data which was retrieved then also gets cached into local SSD storage. Because Snowflake is a column oriented database, usually a limited number of columns will get retrieved from S3 and cached in the SSD disk. Also Snowflake might retrieve only some rows of the table if particular micro-partitions can be pruned.
This in turn greatly improves the performance of future queries that might be ran on the same data because it can be loaded extremely quickly from a local SSD compared to loading from S3 through a fast network. When the virtual warehouse is shut down, cache on the local SSD is lost.
The main storage elements in Snowflake are:
- S3 which is used for persistent storage of data. It can handle huge amounts of data but has a high latency. While the database files are stored on S3 it is not transparently accessible to the user.
- Local SSD on Virtual Warehouses (EC2 machine) that caches the data retrieved from S3 and acts like a buffer pool. Has a much better latency than S3 but is volatile memory that gets erased after it’s shutdown
- RAM memory is only used for operational purposes and there is no buffer pool
Usually a DBMS has a buffer pool with most recent pages it accessed stored in there (in RAM memory), but Snowflake doesn’t have a buffer pool. Instead it allocates memory for operations like join/group by/order/filter… The reasoning behind that is that if you scan large amounts of data you don’t need a buffer pool because your data will enter and exit the buffer pool very quickly. The local SSD rather acts like a buffer pool because the latest data (on a column level) that was used in queries is stored there for faster access.
The following chart of the architecture also showcases what we explained:
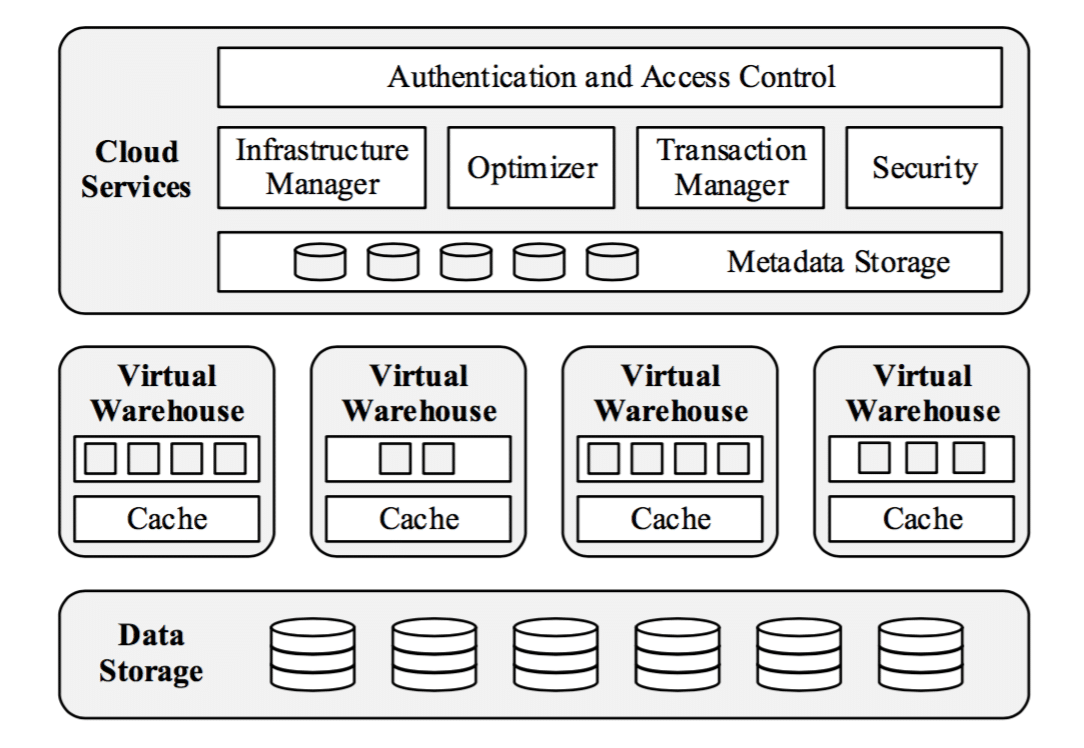
SNOWFLAKE INTERNAL ARCHITECTURE RETRIEVED FROM https://dl.acm.org/citation.cfm?id=2903741
We will show you in a couple of examples how this works.
We will use this dataset containing the records of all individual housing transactions in England and Wales since 1995. The dataset has around 22 millions rows which are stored on approximately 60 micro-partitions.
After turning on our virtual warehouse, we will select the price, datetime and property type for all houses sold after 1st of January 2000.
SELECT price, datetime, prop_type FROM sales WHERE datetime > '2000-01-01'
Because the virtual warehouse was just turned on, its local SSD cache will be empty.
We expect that data will be fetched from S3, processed and then cached in local SSD storage. Only 3 columns will be fetched from S3 and all the rows from micro-partitions where the datetime column falls within this range.
The actual query plan is as follows:
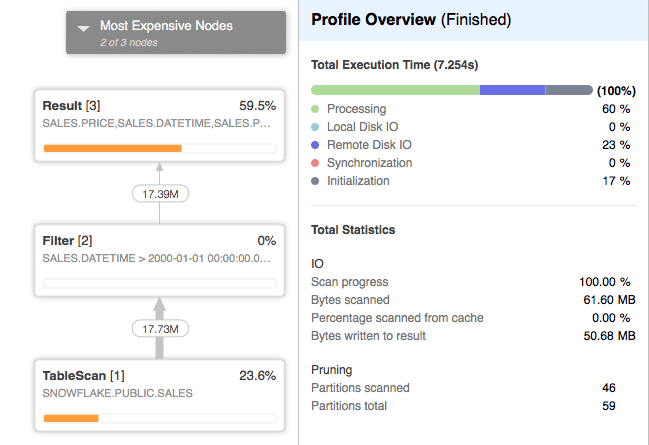
We can indeed see that 0% of the data was scanned from cache. Also notice that 23% of the query cost was spent on Remote Disk IO.
Now we want to run the same query but with an additional filter on the price of a house:
SELECT price, datetime, prop_type FROM sales WHERE datetime > '2000-01-01' and price > 100000
We expect that this query will be able to read all the data from local cache because the previous query fetched all of that data into the local SSD cache.
The actual query profile looks as follows:
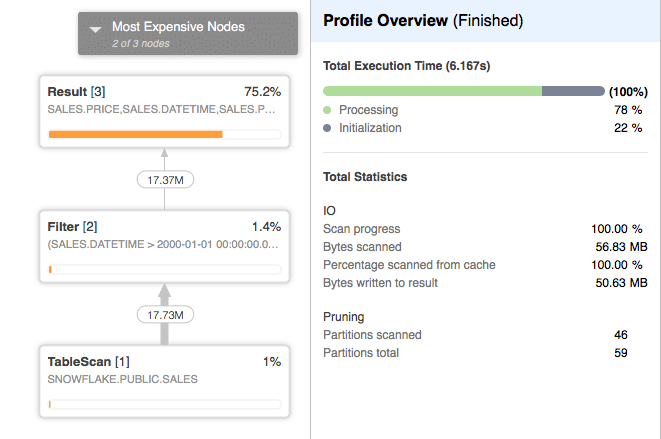
We can observe that 100% of the data was scanned from the local SSD cache in this case. This greatly reduced the cost of scanning a table and the cost TableScan operator fell from 22% to 1%.
Now we will create a new table from the same dataset of Housing Prices that we have on our stage and then immediately run a very simple query on top of it.
The query is as follows:
CREATE TABLE sales_load AS SELECT * FROM sales WHERE 0=1; COPY INTO sales_load FROM @my_csv_stage; SELECT price, datetime, prop_type FROM sales_load WHERE datetime > '2000-01-01';
And the actual execution plan is:
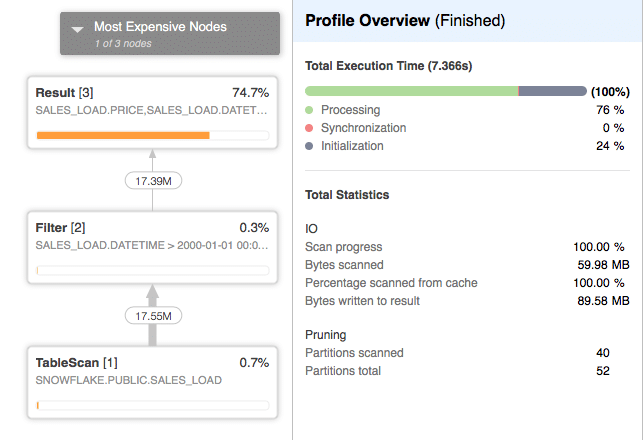
We can notice that this time all of the data was scanned from the local SSD cache. This can be explained with the fact that loading the data from the staging area into a database is done on the EC2 instance(s) of our virtual warehouse. Because the loading is done on the EC2 instance, it would be very easy for Snowflake also to cache the data.
Caching of result sets
Snowflake has another very useful feature and that is caching of result sets.
Imagine executing a query that takes 10 minutes to complete. Now if you re-run the same query later in the day while the underlying data hasn’t changed, you are essentially doing again the same work and wasting resources.
Instead Snowflake caches the results of every query you ran and when a new query is submitted, it checks previously executed queries and if a matching query exists and the results are still cached, it uses the cached result set instead of executing the query. This can greatly reduce query times because Snowflake retrieves the result directly from the cache.
Typically the query and the result set are stored in the Metadata repository. But large result sets are stored on S3 storage and while we couldn’t find documentation how the storage is priced, we assume it’s the same model as normal database storage.
Update: Craig Collier, a technical architect from Snowflake, explained in the comment section that Snowflake actually stores large result sets in a proprietary key/value store managed by the Snowflake service. As the costs for data stored in Snowflake’s Cloud Services layer (Metadata repository) are currently not passed on to the customer this means that even large result sets are stored free of additional charge.
Query result sets are by default stored for the next 24 hours. If you access the result set again in those 24 hours, it will extend the time period for 24 more hours.
To showcase how result sets are cached, we will run a simple aggregation query on the sales_load table from the previous section.
SELECT
AVG(price),
datetime
FROM
sales_load
GROUP BY
datetime
ORDER BY
datetime
The query plan is the following:
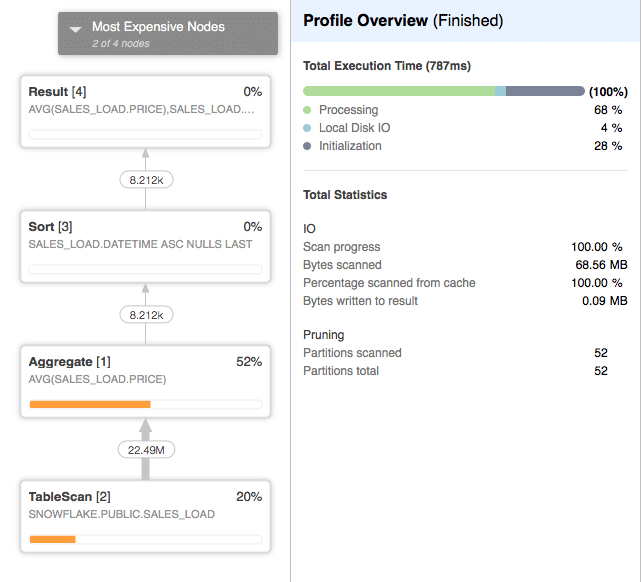
Now if we re-run the same query again we expect that Snowflake’s result caching will come into account and that the query won’t even be executed, rather the engine will only use the result set from the previous query.
The resulting query plan is:
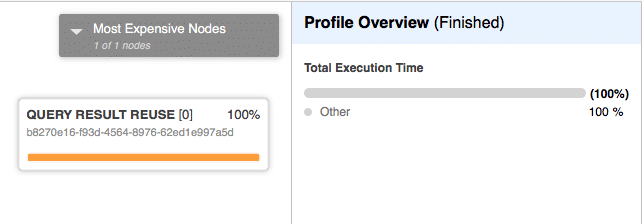
This shows how Snowflake saves us compute time by re-using the previous result set of our query instead of computing a new one.
Unfortunately the caching of result sets is still somewhat primitive. Imagine that we wanted to run the same query but with a filter in the form of a HAVING clause. Technically the solution could be re-computer from the cached result set by applying a simple filter but Snowflake will instead query the data again. If your team needs to systematically diagnose similar query execution issues or performance bottlenecks, our Snowflake data warehouse consultants can conduct a technical health audit of your environment.
Enjoyed this post? Have a look at the other posts on our blog.
Contact us for Snowflake professional services.
We created the content in partnership with Snowflake.
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: