Convert MISMO XML to Hive and Parquet

In this walkthrough, we will convert the MISMO (The Mortgage Industry Standards Maintenance Organization) XML files to Parquet and query in Hive. The XML files are converted to Parquet using the enterprise version of Flexter. The enterprise version provides users with numerous additional features which aren’t available on the free version of Flexter (try for free).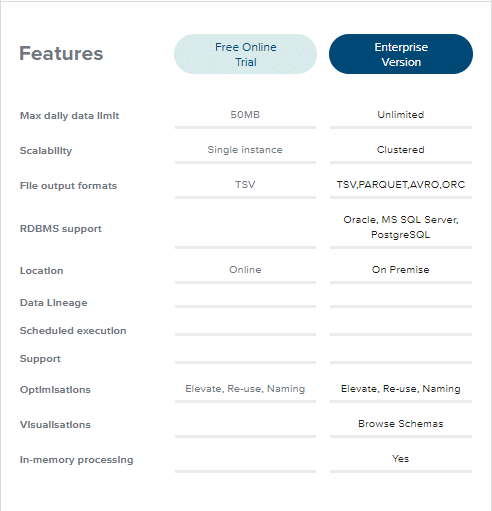
In the following steps, we discuss the process of setting up Flexter Enterprise and running commands for XML parsing into Hive as Parquet tables.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
About MISMO XML
MISMO is a subsidiary of the Mortgage Banker’s Association which aims at delivering technology standards for residential and commercial property transactions in the US markets. The core aim of MISMO is to create standards that have improved data consistency, transparency and have a cost-effective method of implementation. It has a comprehensive set of standards and data points for all stages of the mortgage loan life cycle like underwriting, mortgage insurance application and credit reporting amongst others. By constructing a standard approach using XML, MISMO enables two business related firms to streamline shared data as reports.
After downloading MISMO XML, the files are processed using Flexter as shown below.
How Flexter XML Converter Works
A detailed description of how Flexter works is provided here (FAQ).
The Flexter platform consists of three pluggable modules:
Schema Analyser (xsd2er)
Mapping generator (CalcMap)
Xml Processor (xml2er)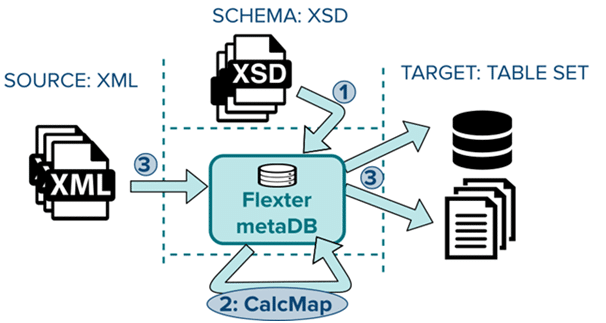
Step 1: The Schema Analyser is a dedicated module that loads, parses out, processes and stores the XML schema information in Flexter’s internal metadata DB. This step is only required to be performed once for each schema to be processed. You can either supply an XSD or a representative sample of XML files for this step.
Step 2: Now that we know the exact layout of the source XML it is possible to generate the relational equivalent. Flexter’s module, Mapping Generator generates the output schema layout and the mapping to it. Various optimisations of the target schema can be applied during this step.
Step 3: The XML Processor module takes the information generated from the two previous steps, processes the XML, and writes the data to the relational target schema.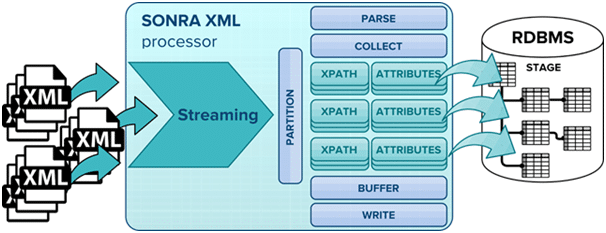
[flexter_banner]
Convert MISMO XML to Parquet and Hive
Generating the metadata and logical schema
In the following steps, we describe the process of generating the logical schema for this exercise.
Step1. After installing the xsd2er package, go to command prompt and enter xsd2er. The xsd2er command processes the schema and stores the information in the internal metadata DB. When this command is executed, the input and metadata processing options are displayed on the screen. Based upon the requirements, the command can be configured.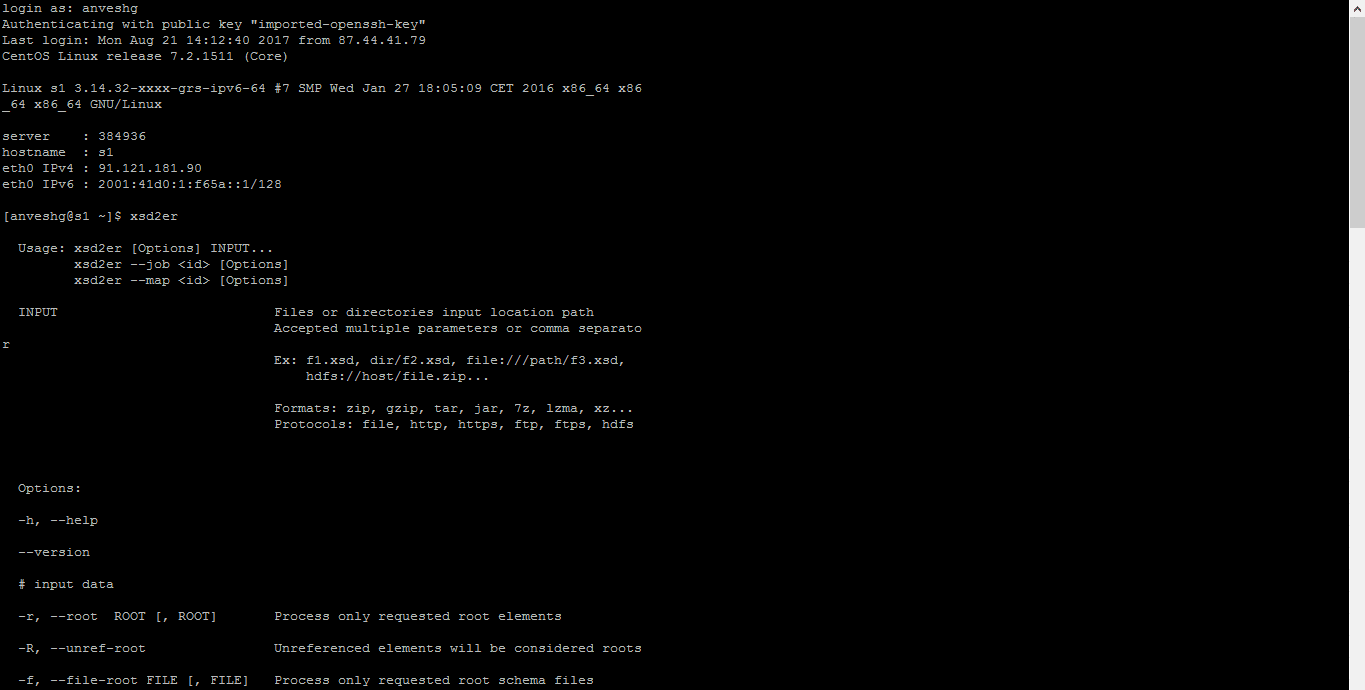
Step2. Specify the command to analyse the XSD file. In this step, we process the XSD file to obtain the metadata information and store it in Flexter’s DB
xsd2er -g3 /home/centos/MISMO/MISMO_3_0.xsd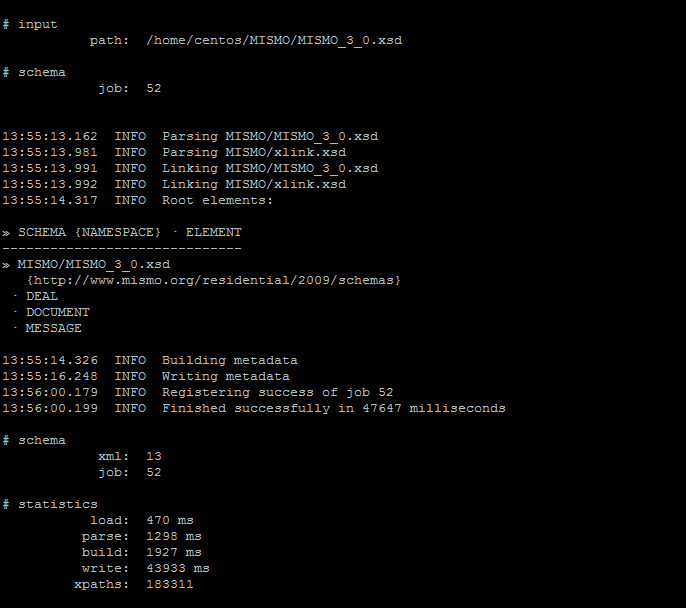
The logical schema number can be seen from the output. Note down this number which is to be used in xml2er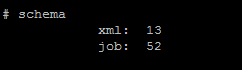
Logical schema number: 13
Extracting Parquet output from MISMO using Flexter Enterprise
In the following steps, we describe the loading of XML data into the Hive database
Step 1. After installing the xml2er package, go to command prompt
Step 2. Enter xml2er. The output is shown below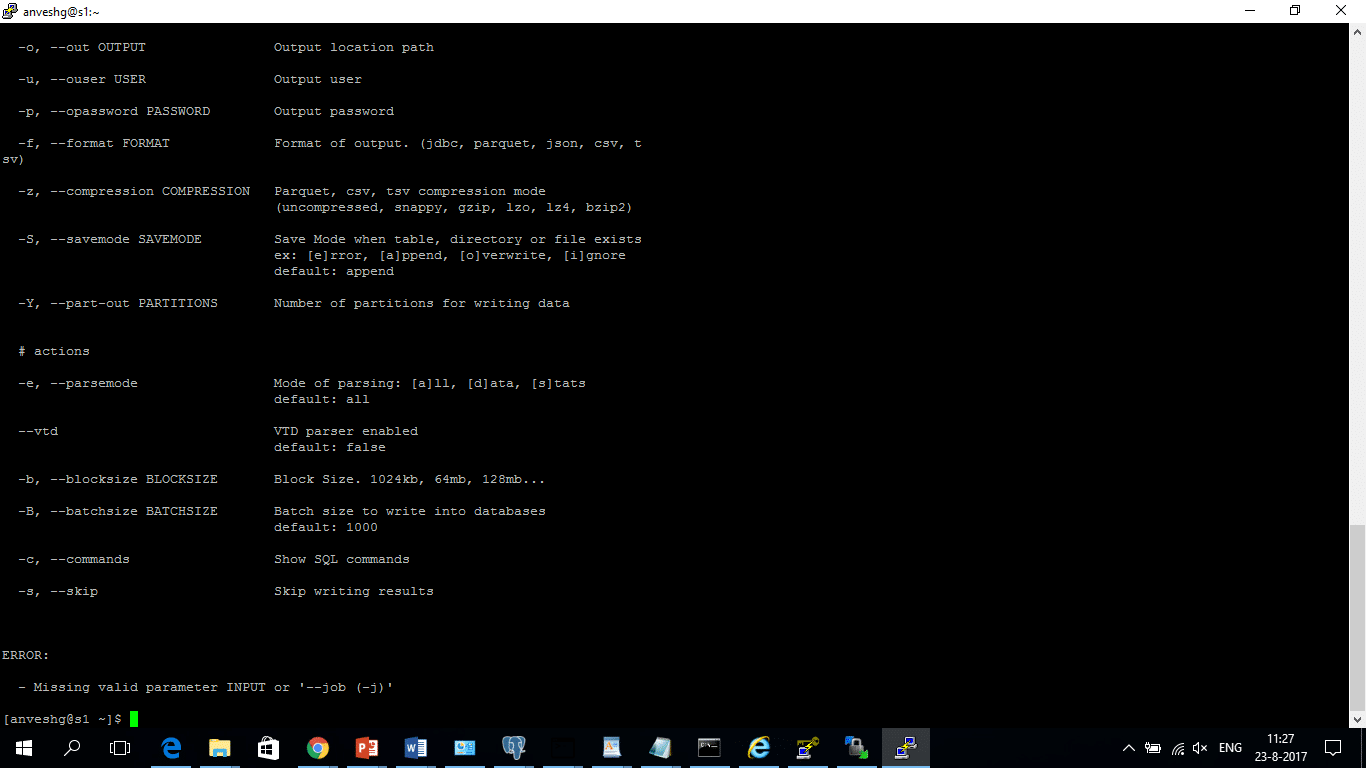
This command displays the various options that are provisioned in Flexter enterprise. The command for processing the XML files can be modified based upon these options. There are various switches provisioned in Flexter which can be used to configure the output data. Based upon the output requirement, the switch can be selected. For example, if the output is supposed to be a Parquet file, then select the format as -f parquet
| Command | Description |
|---|---|
| -o, | Output location path |
| -u, | Output user |
| -p, | Output password |
| -f, | Format of output. (jdbc, parquet, json, csv, tsv) |
| -z, | Parquet, csv, tsv compression mode (uncompressed, snappy, gzip, lzo, lz4, bzip2) |
| -S, | Save Mode when table, directory or file exists ex: [e]rror, [a]ppend, [o]verwrite, [i]gnore default: append |
| -Y, | Number of partitions for writing data |
| -e, | Mode of parsing: [a]ll, [d]ata, [s]tats default: all |
| -b, | Block Size. 1024kb, 64mb, 128mb… |
| -B, | Batch size to write into databases default: 1000 |
| -c, | Show SQL commands |
| -s, | Skip writing results |
Step 3. The target output is the local system the path for which is to be specified in the command.
Step 4. In the next step, we run the xml2er command to process the XML data. On the command prompt, enter
xml2er -l13 -o /home/centos/MISMO /home/centos/MISMO/ Test_MESSAGE2.xml
The description of the attributes in the command is given below
L13 – logical schema number obtained from xsd2er
o – output path
/home/centos/MISMO – output path
/home/centos/MISMO/ Test_MESSAGE2.xml – input path
Step 5. Run the command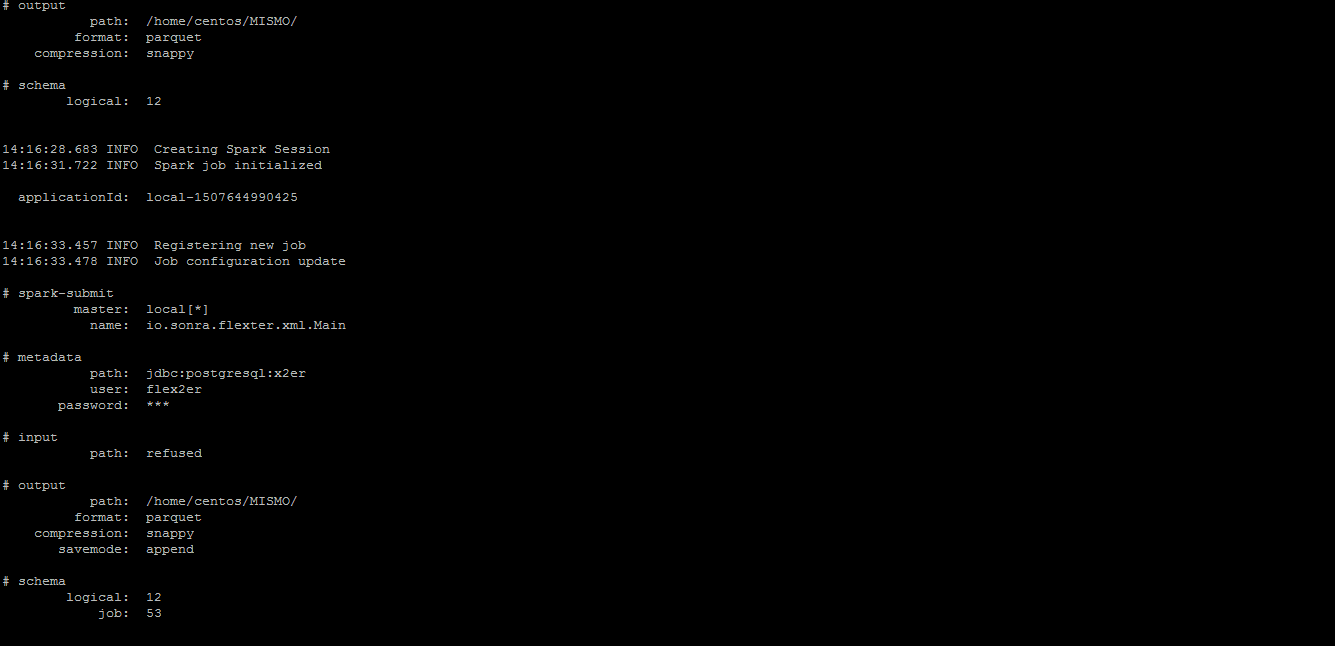
Step 6. After job completion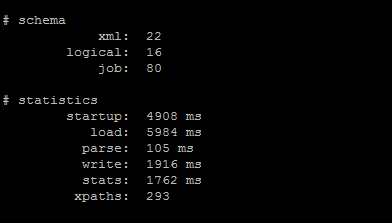
Step 7. The job is completed and the data is copied to the local server to be loaded into hive
Loading Parquet Files to Hive and Querying Data
The ER diagram generated by Flexter for the MISMO data is shown below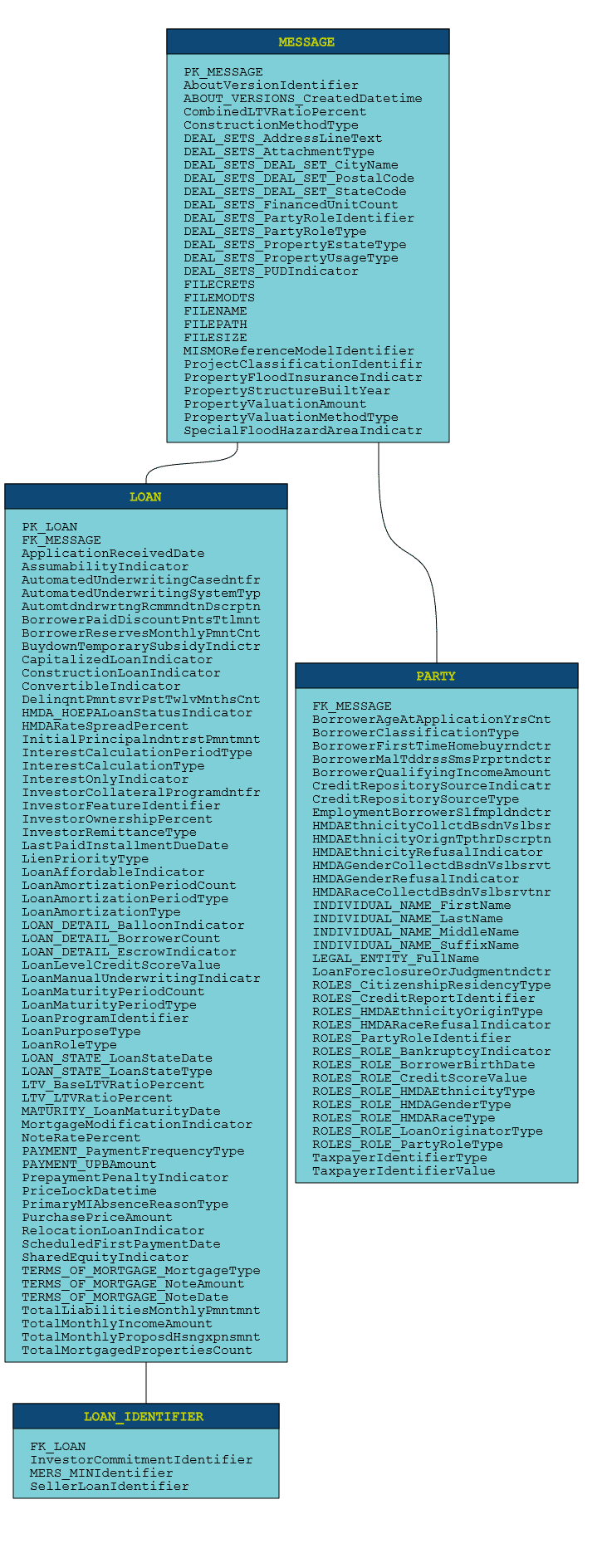
The tables in Hive are created as shown below
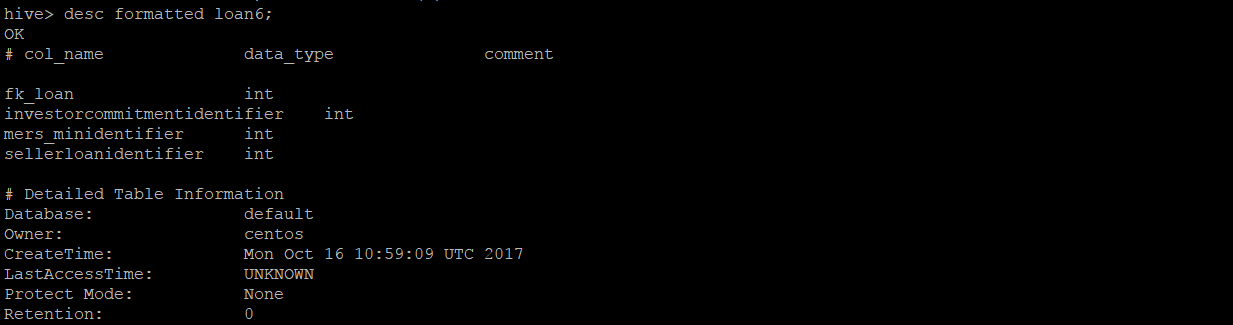
The DDL for the LOAN_IDENTIFIER table is:
create table loan_identifier (FK_Loan int, InvestorCommitmentIdentifier string, MERS_MINIdentifier string, SellerLoanIdentifier string) STORED AS PARQUET tblproperties (“parquet.compress”=”SNAPPY”);;
The data can be loaded into Hive table with the load command
Load data inpath ‘/user/centos/loan/LOAN.parquet’ into table loan_identifier;
A sample query is shown below