Liberating data from spreadmarts and Excel (aka OOXML)

In this blog post we liberate data and metadata from the shackles of Excel. We convert all of the content of an Excel file to a relational database and then query the output to determine data lineage, formulas used, formatting used, tables and pivot tables inside Excel, errors in formulas and their dependencies etc.
Few people are aware that Excel workbooks are just a bunch of XML files packaged up in an archive. You can easily check for yourself. Right click on any Excel file (.xlsx) and extract it with a tool such as 7zip.
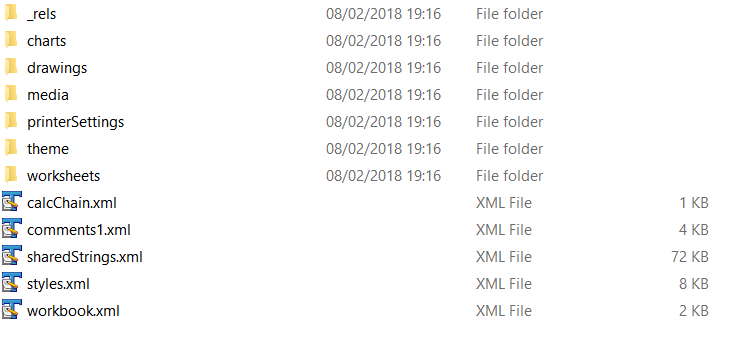
As you can see, there are various XML files inside the package. The files themselves are organised in a hierarchy and a list of all XML files in the package is available in the [Content_Types].xml file

Let’s open this file in a text editor.

Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Excel Relationships
The various XML files that make up an Excel package are linked through relationship files. The root relationship file _rels contains links to other XML files a level further down in the hierarchy, e.g. xl/workbook.xml. The relationships at each level are numbered with a unique and sequential ID, e.g. rId3.

The workbook.xml file can be found in the xl folder. Let’s have a look at its content.
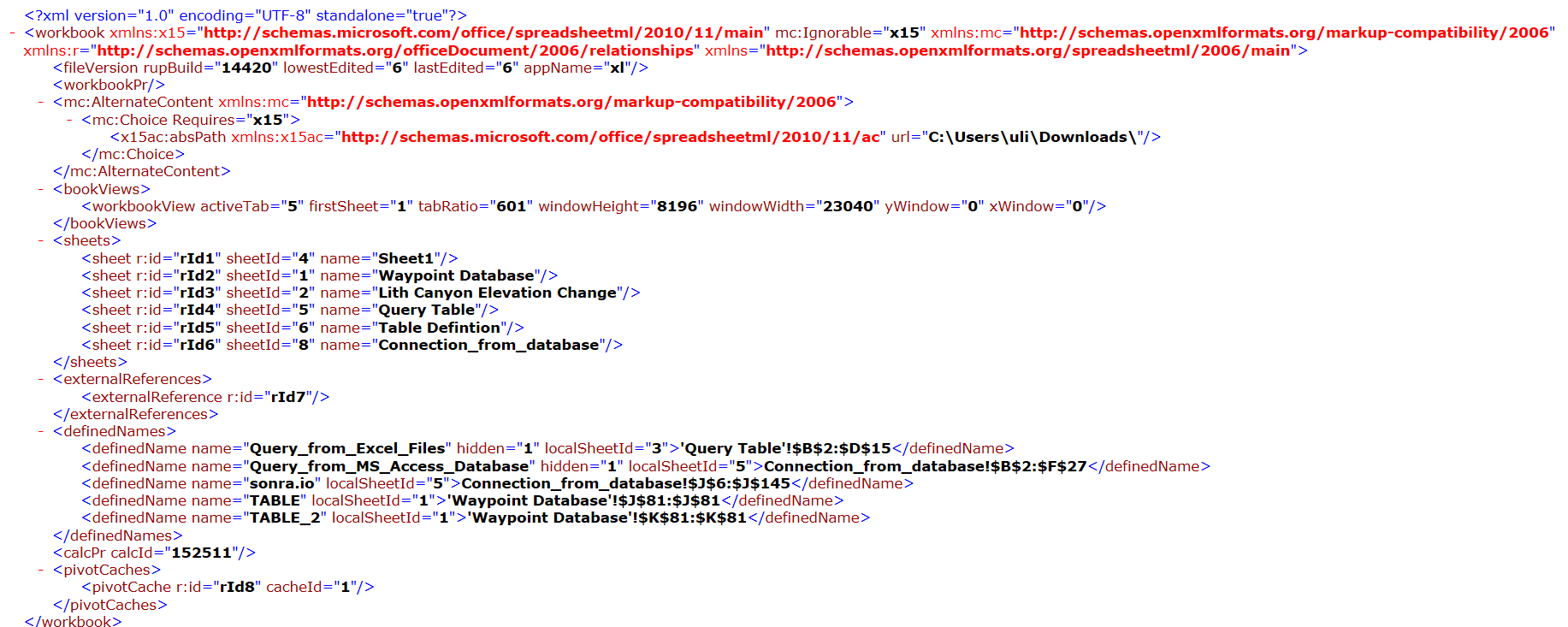
As you can see, the workbook contains various references to sheets. These are linked via relationship Ids, e.g. rId2 to the XML sheet files. We can find out the file names of the sheet XML files by looking at the _rels file at this level in the hierarchy. It’s called workbook.xml.rels.

As you can see rId2 is linked to the file in worksheets/sheet2.xml. Let’s have a look at this file.
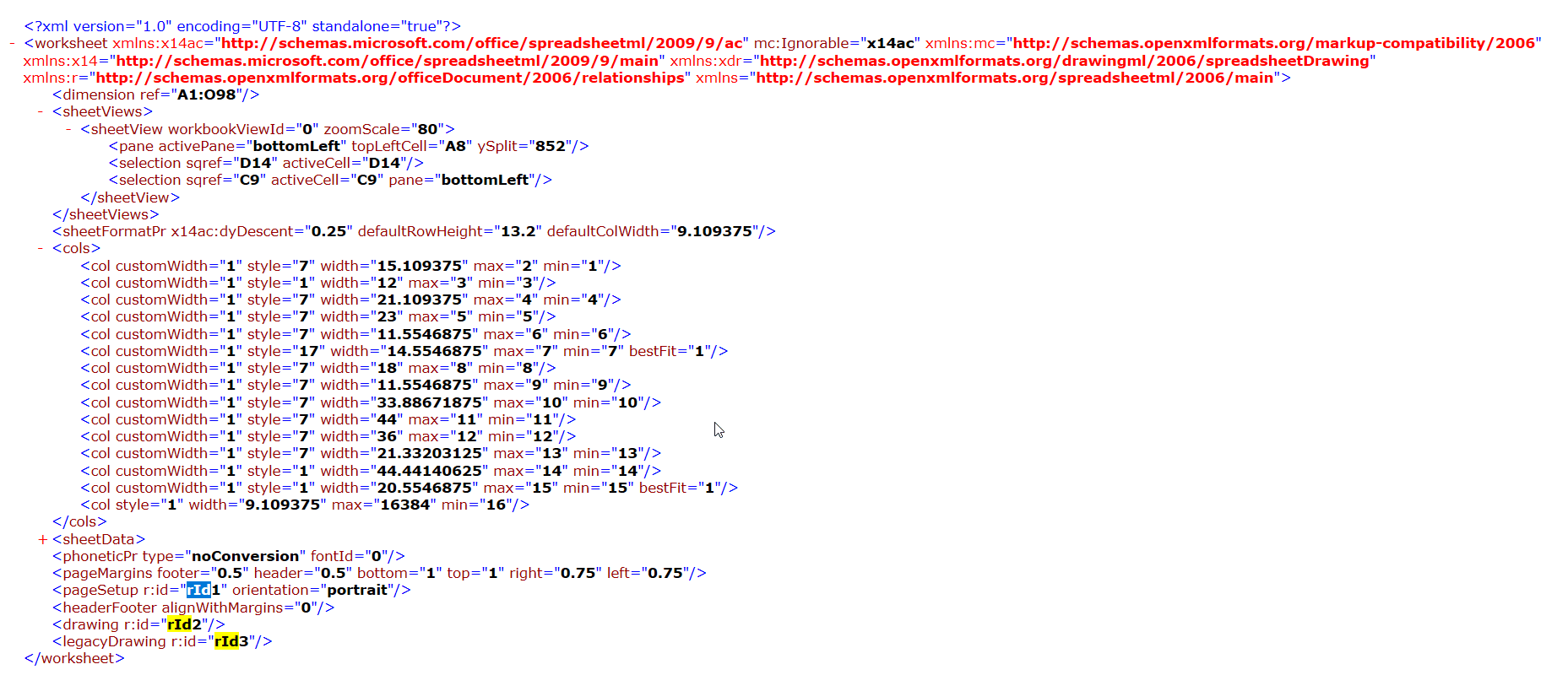
Making sense of the XML content
Let’s take a peek inside some of the other XML files in the package, e.g. let’s have a look at the sharedStrings.xml file.

The sharedStrings.xml contains a unique list of strings that occur anywhere in the cells of your workbook. These are instantiated in the cells of our worksheets when we open the workbook in Excel. Each unique string in an Excel sheet is only stored once to reduce the overall size of the Excel file on disk. In other words the strings are stored in a normalised format. In this particular file we can find a total number of 593 strings (count) and 428 (uniqueCount) of them are unique.
You might be wondering how I figured out this piece of information. As you can imagine there is extensive documentation on the various OOXML packages.
Making sense of the XML content is a two step process. In section 12.3 Part Summary we get a brief overview on the various parts that make up the overall Excel package, e.g. 12.3.15 Shared String Table Part contains information about the sharedStrings.xml file. There we find:
An instance of this part type contains one occurrence of each unique string that occurs on all worksheets in a workbook. A package shall contain exactly one Shared String Table part, and that part shall be the target of an implicit relationship from the Workbook part.
If we require more detailed information on the various elements/attributes that can occur in sharedStrings.xml we need to look at section 18. SpreadsheetML Reference Material. There under 18.4 Shared String table we find further information, e.g. on count and uniqueCount

Ok, this is great, but how can we query and analyse all of this rich information? It’s quite simple. We can use Flexter the ETL tool for XML and JSON to convert the OOXML/Excel file to tables in a database and then use SQL to analyse the Excel data and metadata
Converting Excel data and metadata to a database
We have created this short video that shows you how you can convert any .xlsx Excel file to text files.
As part of the output from the conversion process we get an ER diagram that helps us to make sense of the data.
Here is an extract of the diagram, but you can also download the whole relational model of the OOXML model.

Analysing Connections, Tables, QueryTables
In this analysis we want to dive deeper into where the external data in our Excel workbook is coming from.
Connections
Let’s first have a look at the connections that have been defined for this Excel file.
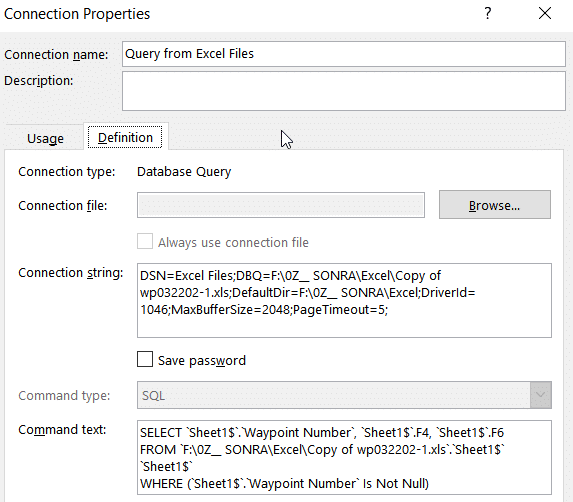
In the Excel file itself we can see that we have defined a connection to another Excel workbook and an MS Access database.
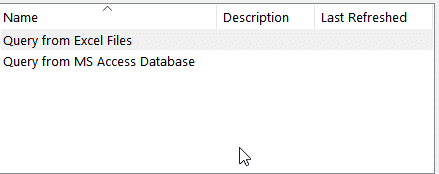
We can see that the connection Query from Excel Files connects to another Excel workbook and selects a couple of data points.
As we can see from the ER diagram, the connection details can be found in tables connections and connection:
Let’s have a look at those tables.

We can find the connection information in our output table. Let’s have a look in the documentation what some of these attributes mean, e.g. savedata. This can be found in section 18.13.1 connection

So now we know that the data that we retrieve from the external Excel workbook will be saved together with the Excel sheet.
Let’s now have a look at how data is injected via a connection into our worksheet.
Tables
Worksheets contain tables, which are connected via so called QueryTables to Connections.
The relationship of worksheets to tables is defined in the sheet.xml.rels, e.g.

In the sheet2.xml.rels we reference table2.xml.
In the output from Flexter these hierarchical/recursive relationships are reflected in the tables relationships and relationship. We can create a database view to reflect this hierarchy.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE VIEW relship AS SELECT a.pk_relationships as relationships_parent_id, a.filename as rel_filename, replace(a.filename,'.rels','') as parent_filename, b.fk_relationships as relationships_child_id, b.target as child_filename, (regexp_split_to_array(b.target, '\\|/'))[array_upper(regexp_split_to_array(b.target, '\\|/'), 1)] as lastofchildfile FROM "public"."relationships" a JOIN "public"."relationship" b on (a.pk_relationships = b.fk_relationships); |
We can see from the Flexter ER diagram that Excel workbook table information is stored in the following tables.
QueryTable
QueryTable information is contained in the following tables
Let’s bring all of this information together in one query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT b.filename sheet_file_name, d.filename table_file_name, d.ref, d.tablecolumns_count, d.tabletype, f.filename query_table_file_name, f.name as query_name, g.name as column_name, h.dbpr_command, h.dbpr_connection from relship a join worksheet b on a.lastofchildfile = b.filename join relship c on b.filename = c.parent_filename join table_ d on d.filename = c.lastofchildfile join relship e on d.filename = e.parent_filename join queryTable f on f.filename = e.lastofchildfile join queryTableField g on f.pk_querytable = g.fk_querytable join connection h on f.connectionid = h.id; |
… and have a look at the output

As you can see, there are two tables in our Excel workbook using the Excel and Access connection. We can also see the worksheets and the table cells where these tables have been created.
Let’s have a look at the connection information


Flexter for Excel. Governance for spreadsheets
Thanks to the power of Flexter, our ETL tool for XML and JSON, it’s quite straightforward to extract data and metadata from Excel workbooks. It is then easy to analyse the output, e.g. identify where the data in worksheets comes from, identify tables, find errors or inconsistencies in formulas, provide lineage for formulas etc.
Do you have any governance issues of spreadsheets? We are working on a set of spreadsheet governance features, e.g. Excel versioning, automated header detection, lineage for Excel formulas, detecting PII.




