How Snowflake EXCLUDE and ILIKE protects you from bad SQL. ILIKE it like that.


One of the most common and impactful SQL anti patterns is the use of SELECT *. In this article we will explain what an SQL anti pattern is and how SELECT * impacts Snowflake performance and increases your Snowflake costs. We will then walk you through how some new Snowflake SQL features can protect you from this anti pattern. Last but not least we will show you how FlowHigh helps you to detect this and many other SQL anti patterns.
FlowForward.
All Things Data Engineering
Straight to Your Inbox!
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
What is an anti pattern?
Anti patterns identify common but problematic solutions in the software industry, much like how design patterns highlight best practices. They often arise from a lack of experience or misapplying good strategies in the wrong situations. By recognizing these anti patterns, professionals can understand the root causes of certain issues. These patterns not only point out problems but also offer detailed plans to fix them.
What is an SQL anti pattern?
SQL, like other coding languages, has its anti patterns. These bad practices can make code slow, hard to read, or even produce wrong outcomes. While some problems are specific to certain databases, many bad practices are common across SQL databases. It’s essential to recognize and address these issues, but sometimes fixing one can lead to another, requiring a balanced approach.
Why SELECT * is bad
Utilizing SELECT * in SQL might seem convenient, but it carries a lot of drawbacks. This approach often fetches unnecessary columns, straining system resources, especially in columnar databases where only specific columns should ideally be read. This indiscriminate fetching can increase costs. The excess data also amplifies serialization overheads and consumes more network bandwidth. Cache inefficiencies arise as unneeded data is stored, potentially evicting essential data. Moreover, for wide tables with many columns, the resource impact is even more visible. From a maintenance perspective, SELECT * can cloud code clarity and disrupt downstream processes if table schemas change. Given these issues, it’s advisable to specify columns explicitly in SQL queries to ensure efficiency and clarity.
Why People Fall for the SELECT * anti pattern
SQL developers and data professionals often resort to using SELECT * for a variety of reasons:
- Simplicity and Convenience: Writing SELECT * is straightforward and doesn’t require knowledge of all column names. This makes it an attractive choice, especially when quickly drafting queries or exploring unfamiliar tables.
- Exploratory Analysis: When initially getting a feel for a dataset or trying to understand a table’s structure, using SELECT * can provide a quick overview. It’s a common method for initial data examination before diving into more detailed analysis.
When Using SELECT * is Legitimate
While generally considered an anti-pattern, there are situations where SELECT * can be deemed appropriate:
- Temporary Analysis: For one-time, quick analyses where a complete view of the data is necessary, SELECT * can be useful. It’s beneficial when the primary goal is to get a snapshot of the data without concern for performance or long-term implications. Ideally it should be used together with the LIMIT or TOP clause
- Full Data Extraction: In situations where the intention is genuinely to extract or backup the entire table, SELECT * is not only legitimate but also the most direct method to achieve this.
- Some data engineers use SELECT * for automatic schema evolution and infer the schema at runtime. There are pros and cons to this approach. Maybe the topic for another day
Leveraging Snowflake EXCLUDE and ILIKE to address the SELECT * anti pattern
So what can you do to address the anti pattern. Using an IDE that features autocomplete is one way of handling this. More recently databases have added new features to SQL to mitigate the issue.
Snowflake has introduced EXCLUDE and ILIKE. Both EXCLUDE and ILIKE reduce the negative impact of SELECT * by offering a neat way to include or exclude columns based on naming and patterns.
Let’s go through some examples. We will use the following table structure
CREATE TABLE products ( product_id INT PRIMARY KEY, desc_english VARCHAR(255), desc_french VARCHAR(255), price DECIMAL(10, 2), stock INT );
SELECT * ILIKE:
Snowflake’s SELECT * ILIKE feature provides enhanced granularity when dealing with tables that have numerous columns, especially when you want to narrow down to specific naming patterns.
For instance, imagine an e-commerce database where the products table has varied columns for product descriptions in multiple languages: desc_english, desc_french, alongside other columns like price and stock. Instead of employing the usual anti pattern of fetching all columns and subsequently filtering out the required language columns in the application layer, you can harness Snowflake’s feature. By executing a query like SELECT * ILIKE ‘desc%’ FROM products;, you’re able to directly retrieve only the product descriptions. This not only enhances data fetch efficiency but also minimizes the processing overhead in your application.
Query:
SELECT * ILIKE 'desc%' FROM products';
| DESC_ENGLISH | DESC_FRENCH |
|---|---|
| Laptop | Ordinateur portable |
| Mouse | Souris |
| Keyboard | Clavier |
| Monitor | Moniteur |
| Speaker | Haut-parleur |
Using ILIKE matching is case insensitive.
EXCLUDE Keyword in Snowflake:
If you have a table with numerous columns and you want most of them but wish to exclude a few, the EXCLUDE function provides a straightforward approach. Instead of listing all the columns you want, you can simply specify the ones you don’t want.
For instance, given our previous e-commerce product table, if you’re interested in all details except descriptions in English, you’d use the EXCLUDE clause to leave out the desc_english column.
Query:
SELECT * EXCLUDE (desc_english) FROM products;;
Result:
| PRODUCT_ID | DESC_FRENCH | PRICE | STOCK |
|---|---|---|---|
| 1 | Ordinateur portable | 1,000 | 10 |
| 2 | Souris | 50 | 50 |
| 3 | Clavier | 70 | 35 |
| 4 | Moniteur | 150 | 20 |
| 5 | Haut-parleur | 80 | 45 |
Some databases such as BigQuery have the same feature but instead of EXCLUDE they use the EXCEPT clause to exclude columns in your results. This is not ideal as In many SQL dialects, EXCEPT has a different job. It is a synonym of MINUS and compares two SELECT result sets and shows rows from the first that aren’t in the second. This dual use can be confusing, so it’s important to know how your database handles EXCEPT, MINUS, and EXCLUDE.
Using FlowHigh UI to Detect the SELECT * anti pattern
We have created a module in FlowHigh to detect anti patterns in SQL, e.g. the SELECT * anti pattern.
In this section, we’ll guide you through the process using the FlowHigh UI to detect the SELECT * anti pattern.
Gain access to FlowHigh today.
We’ll use the below query as input to detect anti patterns.
WITH RecentOrders AS (
SELECT *
FROM Orders
WHERE order_date BETWEEN '2022-01-01' AND '2022-12-31'
),
TopProducts AS (
SELECT product_id, SUM(sold_quantity) AS total_sold
FROM Sales
GROUP BY product_id
HAVING SUM(sold_quantity) > 100
),
PreferredShippers AS (
SELECT shipper_id
FROM Shippers
WHERE rating > 4.5
)
SELECT *
FROM RecentOrders r
JOIN Customers c ON r.customer_id = c.customer_id
JOIN Products p ON r.product_id = p.product_id
JOIN Shipping s ON r.shipping_id = s.shipping_id
JOIN TopProducts tp ON r.product_id = tp.product_id
JOIN PreferredShippers ps ON s.shipper_id = ps.shipper_id
LEFT JOIN (
SELECT customer_id, AVG(order_total) AS avg_order_total
FROM Orders
GROUP BY customer_id
) AS AverageOrders ON c.customer_id = AverageOrders.customer_id
WHERE c.customer_type = 'Premium'
AND p.product_category IN ('Electronics', 'Apparel')
AND s.shipping_type = 'Express'
AND tp.total_sold > 200
AND AverageOrders.avg_order_total > 100
ORDER BY r.order_date DESC, tp.total_sold DESC;
Follow these steps:
- Access FlowHigh: Log in to FlowHigh’s web interface and select the “optimise sql” option from the left panel.
- Submit the Query: Paste the SQL query into the editor and click “Optimise”.
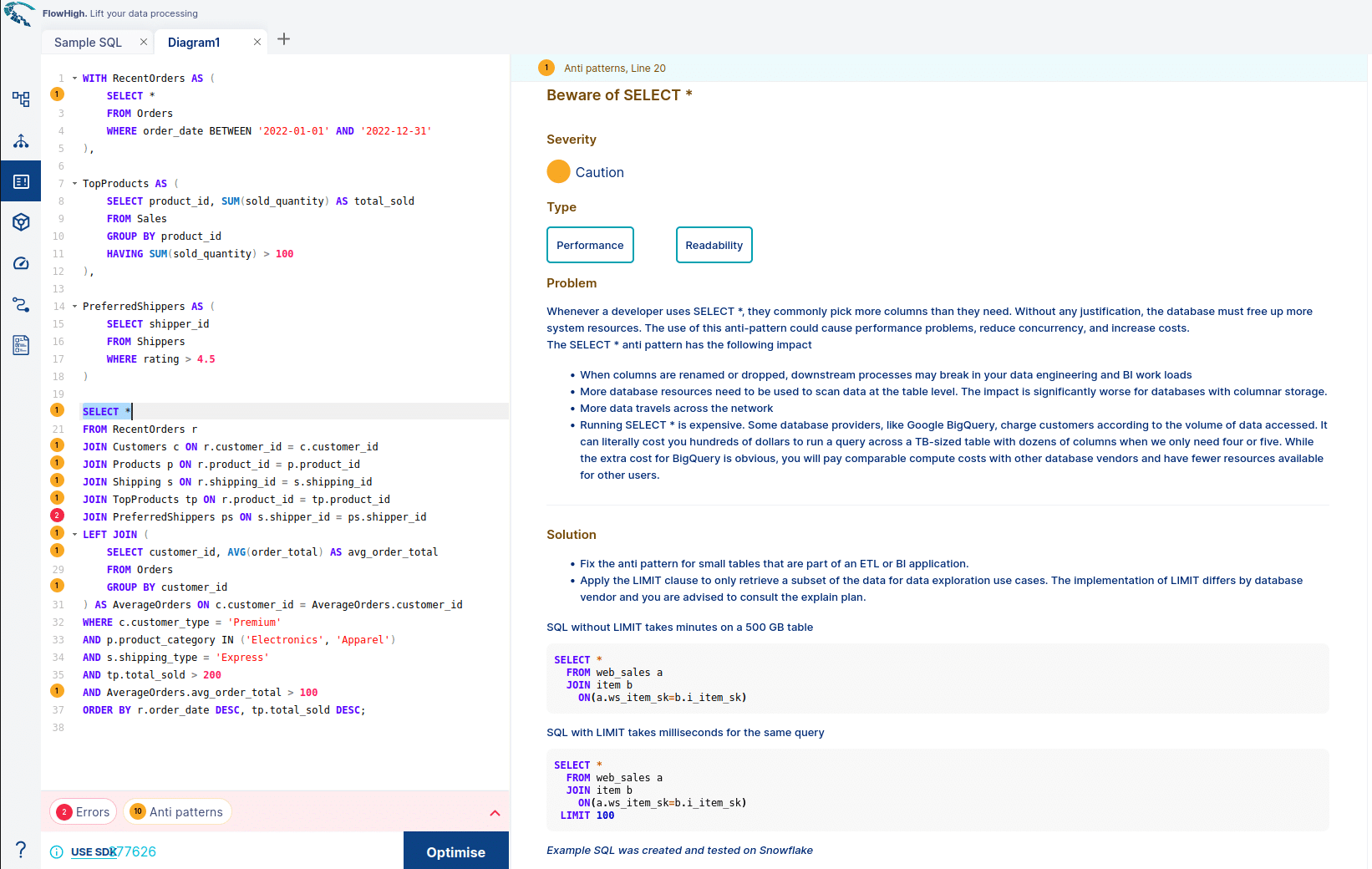
FlowHigh’s analysis will identify instances of the SELECT * anti pattern. If multiple anti patterns are detected in the same query, FlowHigh will highlight them individually.
On the right side, you’ll receive clear descriptions of detected anti patterns, along with explanations, types (Readability, Performance, Correctness), and suggestions for resolution.
Using FlowHigh SDK to Detect the SELECT * anti pattern
The FlowHigh SDK is very useful to programmatically detect anti patterns in your SQL code for automation purposes. As an example you could have a process that scans the Snowflake query history from time to time and detects any bad SQL.
Follow these steps to use the FlowHigh SDK:
- Import the SDK: Begin by importing the required modules from the FlowHigh SDK in your Python script.
- Instantiate FlowHighSubmissionClass: Create an instance of the FlowHighSubmissionClass by passing your SQL query to the constructor:
fh = FlowHighSubmissionClass.from_sql(query_txt)
- Retrieve Anti Patterns: Utilize the instantiated object to extract all anti pattern details present in your SQL code. By using the get_all_antipatterns() method, you’ll obtain a list of anti pattern instances detected within the query.
antipatterns = fh.get_all_antipatterns()
Source code to detect anti patterns.
import requests
import pandas as pd
from datetime import datetime
from flowhigh.model import AntiPattern
from flowhigh.utils.converter import FlowHighSubmissionClass
fh_ap_doc = requests.get("https://docs.sonra.io/flowhigh/master/docs/sql-optimiser/index.json")
json_data = fh_ap_doc.json()
ap_dict = {k: v for dic in json_data["data"] for k, v in dic.items()}
query_log = []
data = []
# function to return antipattern details
def get_antipattern_details(ap: AntiPattern):
severity = "Notice" if ap.severity == 3 else ("Caution" if ap.severity == 2 else "Warning")
performance_flag = ap.performance if ap.performance != ' ' else 'N'
readability_flag = ap.readability if ap.readability != ' ' else 'N'
correctness_flag = ap.correctness if ap.correctness != ' ' else 'N'
ap.p
for position in ap.pos:
start, length = map(int, position.split('-'))
end = start + length
yield [ap.type_, ap_dict[ap.type_], start, end, str(query_txt[start:end]),
severity, ap.link, performance_flag, readability_flag, correctness_flag,
datetime.now().strftime('%Y-%m-%d %H:%M:%S')]
# Query to check for antipattern
query_txt = '''
<insert the query that needs to be optimised>
'''
fh = FlowHighSubmissionClass.from_sql(query_txt)
antipatterns = fh.get_all_antipatterns()
for ap in antipatterns:
data.extend(list(get_antipattern_details(ap)))
# converting the list to dataframes to load the data into table
df = pd.DataFrame(data, columns=['AP_ID', 'AP_NAME', 'POS_START_INDEX', 'POS_END_INDEX', 'QUERY_SECTIONS_OF_AP',
'SEVERITY', 'AP_LINK', 'PERFORMANCE_FLAG', 'READABILITY_FLAG',
'CORRECTNESS_FLAG', 'TIME_STAMP'])
print(df)
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: