Oracle EXTRACT & EXTRACTVALUE for XML (Guide & Examples)


When you need to extract and/or query an Oracle database for XML data, there are two SQL functions that come to mind, ‘EXTRACT’ and ‘EXTRACTVALUE’. I’m going to delve into these two functions and provide some examples. But first, a note of caution:
Both EXTRACT and EXTRACTVALUE serve similar purposes, but they each have their own characteristics and are suited for different use cases.
Let’s take a look at how the EXTRACT and EXTRACTVALUE functions work, which will help you understand their subtle, but important differences. Then I’ll dive deep into a few use cases and examples.
Finally, I’ll wrap up the blog post with alternative methods of converting XML to Oracle tables and SQL.
Important note
Both EXTRACT and EXTRACTVALUE have been deprecated for newer versions than Oracle Database 11g Release 2 (11.2). I recommend users to transition to alternative XML processing methods covered at the end of this article. EXTRACT and EXTRACTVALUE should only be used for legacy implementations and purposes.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Understanding Oracle SQL Functions – EXTRACT and EXTRACTVALUE for XML
EXTRACT
Let’s first have a look at EXTRACT
Purpose: EXTRACT retrieves XML fragments from an XMLType instance
An XML fragment is just that, a fragment of an XML document with well-formed XML content in it, yet is not a complete document in itself. A complete XML document usually has a single root element, maybe a prolog, and follows a rigid structure. On the other hand a fragment can be a snippet of XML code representing part of a larger document.
Look at this well formed XML document
|
1 2 3 4 5 6 7 |
<?xml version="1.0" encoding="UTF-8"?> <books> <book> <title>XML for Beginners</title> <author>John Doe</author> </book> </books> |
An XML fragment based on this XML document could look like this
Example:
|
1 2 3 4 |
<book> <title>XML for Beginners</title> <author>John Doe</author> </book> |
This is an XML fragment because it shows only part of a bigger XML document.
Return type: XMLType
Syntax: EXTRACT(XMLType_instance, XPath_string [, namespace_string ])

Fig 1: XML Extraction Functions Overview
The syntax structure diagram illustrates the process of retrieving data from XML documents in Oracle using the SQL function EXTRACT. It returns an XML fragment as an Oracle XML data type.
Note
XMLType_instance, XPath_string both are mandatory in the Extract Function. Parameter namespace_string is optional
Let’s go through an example with some sample XML data
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<students> <student> <name>John Doe</name> <age>20</age> <grade>A</grade> </student> <student> <name>Jane Smith</name> <age>22</age> <grade>B</grade> </student> </students> |
Example query:
|
1 2 3 4 |
SELECT EXTRACT(xml_data, '/student/name') AS student_name FROM students_table; |
Output:
|
1 |
<name>John Doe</name> |
EXTRACTVALUE
Purpose: Retrieves the text value of an XML fragment
Return Type: VARCHAR2
Syntax: EXTRACTVALUE(XMLType_instance, XPath_string [, namespace_string ])

Fig 2: XML Extraction Functions Overview
The diagram above illustrates the process of retrieving data from XML documents in a database using SQL function EXTRACTVALUE and returns scalar values.
Note: XMLType_instance and XPath_string are mandatory in the EXTRACTVALUE Function. The parameter namespace_string is optional, just as in EXTRACT.
Example
|
1 2 3 4 |
SELECT EXTRACTVALUE(xml_data, '/student/name') AS student_name FROM students_table; |
Output
|
1 |
John Doe |
XPath and namespaces in EXTRACT and EXTRACTVALUE
Both the EXTRACT and EXTRACTVALUE functions accept an XPath and a namespace as parameters. Now, let’s take a look at Xpath and namespace in more detail.
XPath
XPath, (XML Path Language), is a query language that’s used with EXTRACT and EXTRACTVALUE for extraction of certain specific information from an XML document. It works by identifying and selecting nodes (elements, attributes, text) that are based on the hierarchical structure of the document.
EXTRACT and EXTRACTVALUE both support XPath 1.0, which is itself a subset of XPath. Therefore, some advanced XPath 1.0 features aren’t fully supported. The latest version of XPath is 2.0.
Supported Features:
- Basic Path Expressions: You can select nodes using expressions like /, //, and specific node names.
- Attribute Selection: Attributes can be selected using the @ symbol.
XPath expressions are formulated using a combination of path expressions and node tests. The basic syntax includes:
- Relative XPath: Starts with double forward slashes //, allowing searches anywhere in the document. For instance, //name retrieves all name elements regardless of their position in the hierarchy.
- Absolute XPath: Begins with a single forward slash /, indicating the root node. For example, /School/class/name selects the name element of all class nodes.
Example EXTRACT with relative XPath:
|
1 2 3 4 |
SELECT EXTRACT(xml_data, '//class/name').getStringVal() AS class_names FROM xml_table; |
As you can see, this query uses the XPath expression //class/name to find all <name> elements that are children of <class> elements. The getStringVal() method converts the extracted XML nodes into string values.
Output:

Example: EXTRACTVALUE with absolute XPath:
|
1 2 3 4 |
SELECT EXTRACTVALUE(xml_data, '(/student/name)[1]') AS student_name FROM xml_table; |
The XPath expression(/student/name)[1] is used to select only the first <name> element under <student>. This allows for precise extraction of information based on attributes.
Output:

XML namespaces
To avoid the element name conflicts that can occur with XML documents, I use XML namespaces. This allows me the ability to use prefixes linked to specific URIs, Uniform Resource Identifiers), to create a unique identifier for each element and attribute.
For example, when combining XML documents from different sources or apps, this can be very useful.It’s not uncommon to have elements that have the same name but different structures or meanings, which can cause confusion.
Namespaces are defined using the xmlns attribute, either with a prefix (e.g., xmlns:prefix=”URI”) for specific elements or as a default namespace (xmlns=”URI”) for all child elements.
By using namespaces, developers can ensure that their XML documents remain unambiguous and can be correctly interpreted by parsers and applications.
Comparison of EXTRACT and EXTRACTVALUE
You should use EXTRACT when you need the full context of the data within its XML structure. For instance, if you’re working with complex XML documents where relationships between elements are important.
You should use EXTRACTVALUE for queries where you only need specific values. For example, extracting a single value like a product price or order number without needing additional context.
Here is a comparison table that shows the differences between EXTRACT and EXTRACTVALUE
| EXTRACT | EXTRACTVALUE | |
|---|---|---|
|
Return Data Type |
XMLType |
VARCHAR2 |
|
Input |
XML document(XML data) |
XML document(XML data) |
|
Output |
XML fragment with tags |
Text content only |
|
Use Case |
When XML structure is needed |
When only text value is needed |
|
Data Handling |
It operates on a single column |
It can navigate complex XML structures. |
|
Syntax |
EXTRACT(XMLType_instance, XPath_string [, namespace_string ]) |
EXTRACTVALUE(XMLType_instance, XPath_string [, namespace_string ]) |
Oracle EXTRACT and EXTRACTVALUE Examples for XML
In this section I’ve compiled some common scenarios, use cases, and examples for using EXTRACT and EXTRACTVALUES
I’ve created two XML sample files. One sample without namespaces and a second example that contains namespaces.
Sample XML 1 without namespaces:
Step 1: Creating a table for XML data named xml_table_sample1.
|
1 2 3 4 |
CREATE TABLE xml_table_sample1 ( id NUMBER PRIMARY KEY, xml_data XMLType ); |
Step 2: Inserting data into xml_table_sample1
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
INSERT INTO xml_table_sample1 (id, xml_data) VALUES (1, XMLType(' <school> <classes> <class id="C001"> <name>Advanced Mathematics</name> <teacher>Prof. Einstein</teacher> <students> <student id="S001"> <name>Rick Grimes</name> <age>35</age> <subjects> <subject>Calculus</subject> <subject>Linear Algebra</subject> </subjects> <info> <gender>Male</gender> <hobby>Leadership</hobby> </info> </student> <student id="S002"> <name>Michonne Hawthorne</name> <age>30</age> <subjects> <subject>Statistics</subject> <subject>Number Theory</subject> </subjects> <info> <gender>Female</gender> <hobby>Sword Fighting</hobby> </info> </student> </students> </class> <class id="C002"> <name>World History</name> <teacher>Dr. Who</teacher> <students> <student id="S003"> <name>Daryl Dixon</name> <age>33</age> <subjects> <subject>Ancient Civilizations</subject> <subject>Modern Warfare</subject> </subjects> <info> <gender>Male</gender> <hobby>Archery</hobby> </info> </student> </students> </class> </classes> </school>' )); |
Sample XML 2 with namespaces:
Step 1: Creating a table for XML data named xml_table_sample2.
|
1 2 3 4 |
CREATE TABLE xml_table_sample2 ( id NUMBER, xml_data XMLTYPE ); |
Step 2: Inserting Data into xml_table_sample2:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
INSERT INTO xml_table_sample2 (id, xml_data) VALUES (1, XMLType(' <school xmlns="http://teresian.com/school" xmlns:extra="http://teresian.com/extra"> <classes> <class id="C001"> <name>Advanced Mathematics</name> <teacher>Prof. Einstein</teacher> <students> <student id="S001"> <name>Rick Grimes</name> <age>35</age> <subjects> <subject>Calculus</subject> <subject>Linear Algebra</subject> </subjects> <extra:info> <extra:gender>Male</extra:gender> <extra:hobby>Leadership</extra:hobby> </extra:info> </student> <student id="S002"> <name>Michonne Hawthorne</name> <age>30</age> <subjects> <subject>Statistics</subject> <subject>Number Theory</subject> </subjects> <extra:info> <extra:gender>Female</extra:gender> <extra:hobby>Sword Fighting</extra:hobby> </extra:info> </student> </students> </class> <class id="C002"> <name>World History</name> <teacher>Dr. Who</teacher> <students> <student id="S003"> <name>Daryl Dixon</name> <age>33</age> <subjects> <subject>Ancient Civilizations</subject> <subject>Modern Warfare</subject> </subjects> <extra:info> <extra:gender>Male</extra:gender> <extra:hobby>Archery</extra:hobby> </extra:info> </student> </students> </class> </classes> </school> ')); |
Example 1: EXTRACTVALUE Tag
Extracting the value of a tag is the simplest, most basic use of the EXTRACTVALUE function.
Tags (or elements) are components of XML that define the document’s structure. They can hold text or other tags (or sometimes both). Every tag has an opening tag (e.g., <person>) as well as a closing tag (e.g., </person>).
Example code: – Extracting the Teacher Name for the class Id – “C001”
|
1 2 3 4 5 |
SELECT EXTRACTVALUE( xml_data, '/school/classes/class[1]/students/student[1]/name') AS student_name FROM xml_table_sample1; |
- This string, ‘/school/classes/class[1]/students/student[1]/name’ for example, is an XPath expression that will specify the correct path to the specific element in the XML document you’re looking for.
- /school: This indicates the start of the root element <school>.
- /classes: This navigates down to the <classes> child element within <school>.
- /class[1]: This selects the first <class> element (indexing starts at 1).
- /students: This navigates to the <students> child element of that class.
- /student[1]: This selects the first <student> element within that class.
- /name: Finally, this retrieves the content of the <name> element nested within that specific student.
Output:

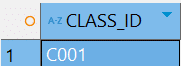
Example 2: EXTRACTVALUE Attribute
Attributes are pieces of additional information which provide specific details about elements and are always a name-value pair. The name identifies the attribute’s, and the value is the data or information that goes with that name. Take a look at this example.
Example code: – Extracting the First Student’s id Attribute
|
1 2 3 4 5 |
SELECT EXTRACTVALUE( xml_data, '/school/classes/class[@id="C001"]/@id' ) AS class_id FROM xml_table_sample1; |
- The string ‘/school/classes/class[@id=”C001″]/@id’ is an XPath expression that specifies how to locate a specific attribute in the XML document.
- /school: This indicates the start of the root element <school>.
- /classes: This navigates down to the <classes> child element within <school>.
- /class[@id=”C001″]: This selects a specific <class> element that has an attribute id with the value “C001”. The @ symbol denotes that we are referring to an attribute rather than a child element.
- /@id: Finally, this retrieves the value of the id attribute of that specific class..
Output:
Example 3: EXTRACTVALUE from file
I’ve created an XML file and used SQL*Loader to upload this file to Oracle. I’ll then use EXTRACTVALUE in this example.
Step 1. Create a table with XMLType data type to store XML data.
|
1 2 3 4 |
CREATE TABLE xml_table_sample3( FILENAME VARCHAR2(255), xml_data XMLTYPE ) |
Step 2. Prepare a control file (.ctl) for the SQL*Loader
|
1 2 3 4 5 6 7 8 9 10 11 |
LOAD DATA INFILE * REPLACE INTO TABLE xml_table_sample3 FIELDS TERMINATED BY ',' TRAILING NULLCOLS ( FILENAME, xml_data LOBFILE(FILENAME) TERMINATED BY EOF ) BEGINDATA /home/oracle/Downloads/DUMPS/SampleXML1withoutnamespaces.xml |
Step 3. Run below SQL*Loader command to load sample.xml file into the xml_tab1 table.
|
1 |
$ sqlldr system/oracle@orcl control=control_file.ctl log=loader_log.log |
|
1 |
SELECT * FROM xml_table_sample3; |
Example:
|
1 2 3 4 5 6 7 |
SELECT EXTRACTVALUE( xml_data, '/school/classes/class[1]/name' ) AS class_name FROM xml_table_sample3; |
Output:

Example 4: EXTRACTVALUE Namespace
As I’ve mentioned, namespaces are used in XML to prevent naming conflicts and to define a scope for element and attribute names. When an XML document uses namespaces its elements are often prefixed or associated with a URI.
In the XML data above, the default namespace is http://teresian.com/school, and there is an additional namespace for elements prefixed with “extra”.
Example code: To extract gender and hobby of the first student:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT EXTRACTVALUE( xml_data, '(/s:school/s:classes/s:class/s:students/s:student)[1]/e:info/e:gender', 'xmlns:s="http://teresian.com/school" xmlns:e="http://teresian.com/extra"' ) AS first_student_gender, EXTRACTVALUE( xml_data, '(/s:school/s:classes/s:class/s:students/s:student)[1]/e:info/e:hobby', 'xmlns:s="http://teresian.com/school" xmlns:e="http://teresian.com/extra"' ) AS first_student_hobby FROM xml_table_sample2 |
The following query extracts the gender and hobby of the first student in the first class. The first EXTRACTVALUE call retrieves the gender and the second EXTRACTVALUE call retrieves the hobby of the first student and both XPath expressions include a namespace declaration: (xmlns=”http://teresian.com/school“) (xmlns:extra=”http://teresian.com/extra”‘) of the first student:
Output:

Example 5: EXTRACTVALUE CLOB
A data type used in Oracle to store large amounts of character data, (up to 4 GB) is known as a CLOB (Character Large Object). Basically it’s a container for text data, anything from XML content to long documents. While XML is a data format, CLOB is a storage type. A CLOB can contain XML, as well as other types of text data.
Pro tip
When working with Oracle, use XMLType data type instead of a CLOB to store XML data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT EXTRACTVALUE( XMLType(xml_clob), '/school/classes/class[@id="C001"]/name' ) AS class_name, EXTRACTVALUE( XMLType(xml_clob), '/school/classes/class/students/student/@id' ) AS student_id, EXTRACTVALUE( XMLType(xml_clob), '/school/classes/class/students/student/info/hobby' ) AS student_hobby FROM clob_table; |
The above example query returns a single row with three columns: the class name with id “C001”, the ID and the hobby of the first student in the XML. Note that “first student” in this example means the first one in the XML structure, not necessarily the student with id “C001”.
Output:

Example 6: EXTRACTVALUE multiple nodes
In this example, EXTRACTVALUE is used to pull values from multiple nodes in the XML data stored in the xml_table.
|
1 2 3 4 5 6 7 |
SELECT EXTRACTVALUE(xml_data, '/school/classes/class[1]/name') AS class_name, EXTRACTVALUE(xml_data, '/school/classes/class[1]/teacher') AS teacher_name, EXTRACTVALUE(xml_data, '/school/classes/class[1]/students/student[1]/name') AS student_name, EXTRACTVALUE(xml_data, '/school/classes/class[1]/students/student[1]/age') AS student_age FROM xml_table_sample1; |
This example query will return a single row with six columns, each containing specific values extracted from the XML data.
The class_name column will hold the name of the first class in the <classes> section, while the teacher_name column will display the name of the teacher for that class.
The student_name column will show the name of the first student in the first class, and the student_age column will provide the age of that student.
Additionally, the student_gender column will display the gender of the first student, and the student_hobby column will contain the hobby of the same student.
Output:

Limitations of EXTRACT and EXTRACTVALUE
As I mentioned at the beginning of this article, EXTRACT and EXTRACTVALUE are legacy functions for working with XML in Oracle. They have some severe limitations because of this.
- XPath support: Both EXTRACT and EXTRACTVALUE functions support a subset of XPath 1.0 only. Because of this, more advanced XPath features (like XPath 2.0 functions, expressions, and constructs) aren’t available. For example, complex queries that involve functions like concat(), contains(), or expressions that use advanced operators (for, some, every, etc.) cannot be used with these functions.
- Performance Bottlenecks: Both functions can be slow, particularly when dealing with large XML documents or large datasets with many rows. Since these functions are not designed for high-performance querying, using them on large-scale XML data can result in significant overhead and slower queries.
- Repeated Parsing: Every time you call EXTRACT or EXTRACTVALUE, Oracle parses the XML document to retrieve the result. This repeated parsing degrades performance when querying the same document multiple times, especially in larger datasets.
- Legacy: As of Oracle 12c, EXTRACTVALUE has been officially deprecated. Oracle now recommends using XMLQuery and XMLTable for XML processing because they offer better performance and more flexibility.
- Handling of Large Data: Both EXTRACT and EXTRACTVALUE have limitations when dealing with very large XML data. When extracting data, especially scalar values using EXTRACTVALUE, the size of the returned value is limited by the maximum length of Oracle’s VARCHAR2 (up to 4000 bytes in SQL and 32767 bytes in PL/SQL).
- Limited XML Functionality: These functions are mainly designed for simple data retrieval, making them less suitable for complex XML transformations or handling large hierarchical XML structures.
Recommended alternatives to EXTRACT and EXTRACTVALUE
While they still have their uses in certain situations, I’ve recommended some alternatives for you due to limitations you might encounter when using EXTRACT and EXTRACTVALUE.
They offer more robust and efficient ways to handle XML data compared to the deprecated functions EXTRACT and EXTRACTVALUE.
Recommended Oracle Approaches:
I have written a separate blog post about parsing and converting XML to Oracle tables where I discuss the recommended Oracle way of working with XML in detail.
XMLTable
XMLTable is an SQL/XML function that allows for querying XML data using SQL syntax. It converts XML data into a relational format, making it easier to query and manipulate.
Example code: – It retrieve the names and ages of all students, along with their class name
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT c.class_name, s.student_name, s.student_age FROM xml_table, XMLTABLE( XMLNAMESPACES(DEFAULT 'http://teresian.com/school'), '/school/classes/class' PASSING xml_data COLUMNS class_name VARCHAR2(100) PATH 'name', students XMLTYPE PATH 'students' ) c, XMLTABLE( XMLNAMESPACES(DEFAULT 'http://teresian.com/school'), '/students/student' PASSING c.students COLUMNS student_name VARCHAR2(100) PATH 'name', student_age NUMBER PATH 'age' ) s WHERE xml_table.id = 1; |
Output:

For a more detailed explanation of XMLTable refer to my other blog post where I cover even more XMLTable examples.
XMLQUERY
XMLQUERY embeds XQuery expressions in SQL statements, replacing the deprecated EXTRACT function and allowing querying of XML data with results returned as XML.
Example Code:
|
1 2 3 4 5 6 7 8 9 |
SELECT XMLQUERY( 'declare default element namespace "http://teresian.com/school"; for $s in /school/classes/class/students/student return <student xmlns="http://teresian.com/school">{$s/name/text()}</student>' PASSING xml_data RETURNING CONTENT ) AS student_names FROM xml_table WHERE id = 1; |
Output:

Output Value:
|
1 |
<student xmlns="http://teresian.com/school">Rick Grimes</student><student xmlns="http://teresian.com/school">Michonne Hawthorne</student><student xmlns="http://teresian.com/school">Daryl Dixon</student> |
XMLCAST used with XMLQUERY casts XML data to SQL data types such as VARCHAR2.
Example code: It extract the age of a specific student, such as “Rick Grimes” and casts to VARCHAR2(100)
|
1 2 3 4 5 6 7 8 9 |
SELECT XMLCAST( XMLQUERY('declare default element namespace "http://teresian.com/school"; (/school/classes/class)[1]/name/text()' PASSING xml_data RETURNING CONTENT ) AS VARCHAR2(100) ) AS first_class_name FROM xml_table WHERE id = 1; |
Output:

XML converters
For complex XML conversion tasks, using an XML converter tool such as Flexter can be a smart choice over manual coding with Oracle’s native features.

XML conversion tools save you time and effort by automating the process, reducing project risks, and speeding up the conversion. This means you can make your data available to decision-makers much faster.
Plus, they handle large data sets more efficiently, making the process smoother and easier to scale as your needs grow. Overall, an XML converter simplifies your project and gets results quicker.

Sonra’s Flexter automates converting complex XML and JSON into easy-to-use formats. It works on-premise or in the cloud (AWS, GCP, Azure) and supports various databases like Oracle, Snowflake, BigQuery, and more.
Flexter handles everything automatically, including data lineage and models, optimizing the data for clarity. It can be set up quickly, helping you go live in just hours or days instead of weeks.
Talk to one of our XML conversion experts to discuss your XML conversion use case and get personalised advice.
Further reading
Flexter
EXTRACT & EXTRACTVALUE
XPath & namespaces