Learn Window Functions on Snowflake. Become a cloud data warehouse superhero.

In a recent post we compared Window Function Features by Database Vendors. In this post we will give you an overview on the support for various window function features on Snowflake.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Window functions are essential for data warehousing
Window functions are the base of data warehousing workloads for many reasons.
First of all they are very similar to the GROUP BY clause as they run on a set of rows instead of a single one but, but unlike the GROUP BY clause we do not lose the individual rows. To remedy this we could perform a self join with the result of GROUP BY operation but window functions implement the same functionality in a more efficient way that gives better performance.
Window functions also provide complex functions that are based on the (requested) order of rows such as DENSE_RANK which would be hard to implement with traditional SQL. Using window functions you can avoid writing procedural SQL code. I haven’t come across a requirement where a problem could not be solved with window functions.
Just as a reminder, window functions are used with the following syntax:
|
1 2 3 4 5 |
<function> ( [ <argument1> [ , ... , <argumentN> ] ) OVER ( [ PARTITION BY <expr1> ] [ ORDER BY <expr2> ] [ frame_definition ] ) |
Window Functions on Snowflake
Please don’t mix up the cloud data warehouse Snowflake here with the dimensional modelling design pattern. Snowflake is the first cloud native data warehouse with fully decoupled storage and compute. It is optimized for analytical workloads as data is stored in columnar format and micro-partitoned. Find out more about the unique Snowflake architecture on their website.
We will now walk you through window function support on Snowflake. Let’s first have a look at the dataset.
The dataset
We will use a dataset of phone top-ups. Here is the schema of our dataset:
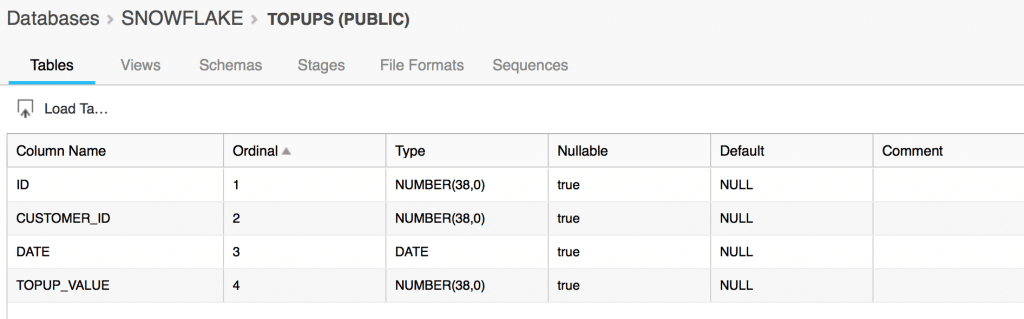
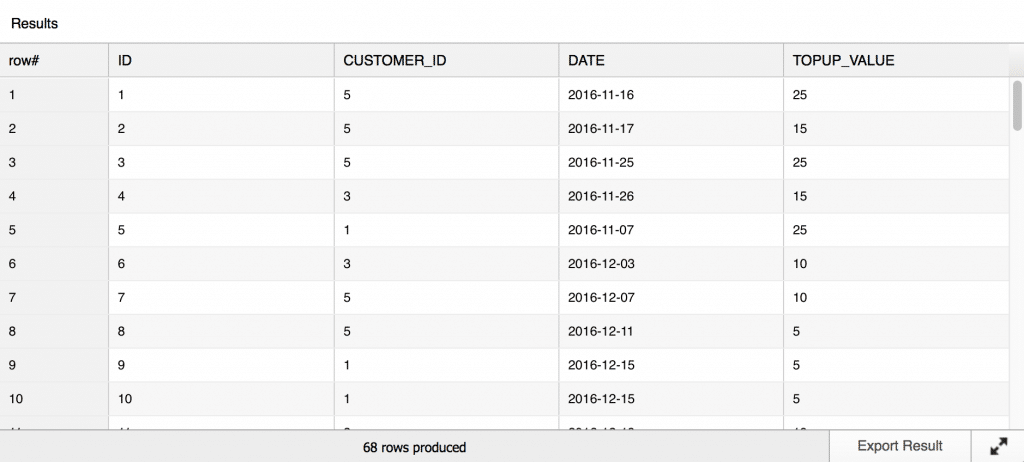
Sample rows of the dataset:
Aggregate and sequencing functions on Snowflake
Aggregate functions perform operations that take into account all values across a window.
Sequencing functions produce output based on the position of the row in the window.
Aggregate functions supported by Snowflake are:
- AVG
- COUNT
- MAX
- MIN
- SUM
Sequencing and ranking functions in Snowflake are:
- ROW_NUMBER
- LAG
- LEAD
- FIRST_VALUE
- LAST_VALUE
- NTH_VALUE
- RANK
- PERCENT_RANK
- DENSE_RANK
- CUME_DIST
- NTILE
- WIDTH_BUCKET
Overall there is not much more that you can wish for.
Snowflake has plenty of aggregate and sequencing functions available.
Analytical and statistical function on Snowflake
Analytical and statistical functions provide information based on the distribution and properties of the data inside a partition.
Analytical and statistical functions in Snowflake:
- MEDIAN
- CORR – correlation with non-null pairs in a partition/group
- COVAR_POP – population covariance for non-null pairs in a partition/group
- COVAR_SAMP – sample covariance for non-null pairs in a partition
- VARIANCE
- STDDEV
- PERCENTILE_CONT
- REGR_* – linear regression
- HLL_* – cardinality estimation
- APPROXIMATE_JACCARD_INDEX – similarity estimation
- APPROX_TOP_K – frequency estimation
- APPROX_PERCENTILE – percentile estimation
Please note the approximate query functions APPROX_TOP_K etc. The rationale behind approximate query functions is to trade off performance against accuracy. Some calculations such as calculating TOP N are very expensive as they require a lot of sorting and looking at the whole data set. Using sampling techniques you can speed up these calculations by an order of magnitute and not all use cases require 100% accuracy. We cover approximate query functions in our popular training course Big Data for Data Warehouse Professionals in more detail.
Analytical functions are also very well supported on Snowflake.
Support for flexible frame definition
Partitions can be further subdivided into frames. Frames are those rows over which window functions inside the partition are applied.
For example if we wanted to get an alert when the user tops up his account with more credits than in the last two top ups combined we could run the following query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT customer_id, date, topup_value > COALESCE(SUM(topup_value) OVER ( PARTITION BY customer_id ORDER BY date ROWS BETWEEN 2 PRECEDING AND 1 PRECEDING) , 0) AS is_alert FROM topups ORDER BY date; |
In the ROWS clause we specified that the we are interested in the two rows preceding the current one.
Generally, Snowflake distinguishes between Cumulative and Sliding window frames.
1) Cumulative window frames are defined as either:
- { ROWS | RANGE } BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
- { ROWS | RANGE } BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
The ROWS option computes the aggregate for the current row using all rows from the beginning or end of the partition to the current row according to the specified ORDER BY subclause. RANGE is similar to ROWS, except it only computes the aggregate for rows that have the same value as the current row and according to the specified ORDER BY subclause.
2) Sliding window frames are defined as one of:
- ROWS BETWEEN <N> { PRECEDING | FOLLOWING } AND <N> { PRECEDING | FOLLOWING }
- ROWS BETWEEN UNBOUNDED PRECEDING AND <N> { PRECEDING | FOLLOWING }
- ROWS BETWEEN <N> { PRECEDING | FOLLOWING } AND UNBOUNDED FOLLOWING
Unfortunately Snowflake does not currently support numerical values in the RANGE clause. The RANGE clause can only be used with CURRENT ROW and UNBOUNDED PRECEDING/FOLLOWING. This is a limitation in situations where you want to monitor the product usage of a customer for only the last 24 hours. We explained this scenario in more depth in our previous blog post comparing the ROWS and RANGE functionality of Redshift and BigQuery.
Distinct inside window function
If we want to count the number of distinct ID’s that made a call each day we have to use the DISTINCT clause within the window function.
The example query is following:
|
1 2 3 4 5 6 7 |
SELECT t.*, COUNT(DISTINCT id) OVER (PARTITION BY date) FROM topups AS t ORDER BY date ASC ; |
Snowflake does support the DISTINCT clause in window functions for most but not all of them.
Sequencing and ranking functions do not support the DISTINCT clause.
Most of the general aggregation functions (SUM, COUNT, AVG, HASH_AGG, LISTAGG, STDDEV…) mentioned in Snowflakes documentation do support DISTINCT clause.
In the official documentation for each function it is noted whether it supports the DISTINCT clause.
LISTAGG – Aggregation into strings
If we want to concatenate all values of a partition into a single string with a specific delimiter we can use the LISTAGG function.
Here is an example of a query utilizing the LISTAGG function:
|
1 2 3 4 5 6 7 |
SELECT t.*, LISTAGG(topup_value,',') OVER (PARTITION BY date) FROM topups AS t ORDER BY date ASC ; |
And the result of this query: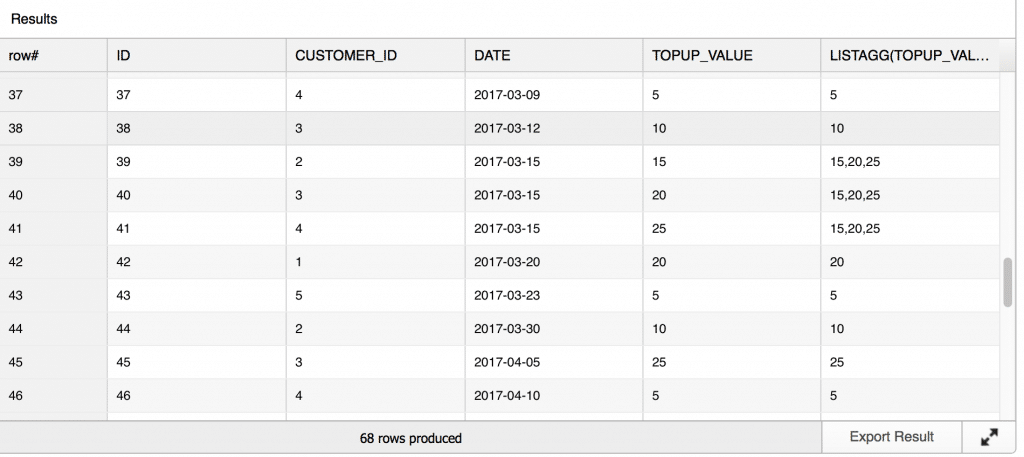
Unfortunately, we weren’t able to use the WITHIN GROUP clause to concatenate the top up values in the order based on their values. This is a small limitation of Snowflake but we expect it will be fixed soon given that similar functions support this clause.
ARRAYS – Aggregation into arrays
Similarly to LISTAGG, If we want to create an array with all the values of a partition we can use the ARRAY_AGG function. This could be useful if we want to denormalise our data to avoid costly joins between very large transaction tables such as ORDER and ORDER_ITEM.
For the ARRAY_AGG function Snowflake does support the WITHIN GROUP clause to order the top ups based on their value:
|
1 2 3 4 5 6 7 8 9 |
SELECT t.*, ARRAY_AGG(topup_value) WITHIN GROUP ( ORDER BY topup_value ASC ) OVER (PARTITION BY date) FROM topups AS t ORDER BY date ASC ; |
The result of this query is: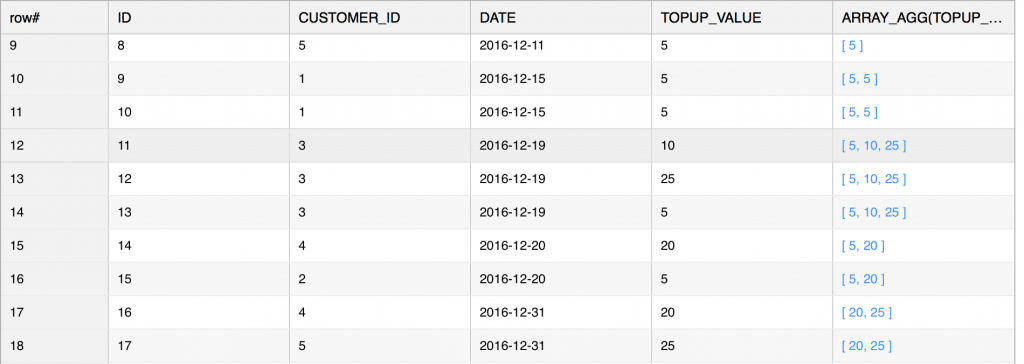
WINDOW CLAUSE – Clause for the WINDOW declaration
When a query involves multiple window functions, it is possible to write out each one with a separate OVER clause, but this is duplicative and error-prone if the same windowing behavior is wanted for several functions. Instead, each windowing behavior can be named in a WINDOW clause and then referenced in OVER.
For example
|
1 2 3 4 5 6 7 |
SELECT sum(topup_value) OVER w, max(topup_value) OVER w, avg(topup_value) OVER w FROM topups WINDOW w AS (PARTITION BY date ORDER BY id); |
Snowflake does not currently support WINDOW declaration.
UDAF – User-defined aggregate functions
Snowflake provides a number of pre-defined aggregate functions such as MAX, MIN, and SUM for performing operations on a set of rows. You can, however, define custom aggregate functions your specific data. Here is more information on how user defined aggregate functions work on the Oracle database.
User-defined aggregate functions are supported by Snowflake.
Snowflake allows using Javascript table UDFs which output an extra column that contains the result of applying a UDF to your table (or the partition you define).
They are not perfect as there are limitations when using them with window functions. However, we have found a nice workaround to make it work.
In our next post we will cover UDFs and table UDAFs in more depth. It’s very exciting.
Join the conversation: What is your favourite window function? When did a window function help you with a difficult problem?
Enjoyed this post? Have a look at the other posts on our blog.
Contact us for Snowflake professional services.
We created the content in partnership with Snowflake.
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: