To hell and back with ETL. The unstoppable rise of data warehouse automation.

Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
A brief history of ETL
The rise of ETL and the rise of the data warehouse are tightly coupled. It’s like the chicken and the egg. There would be no data warehouse without ETL and no ETL without data warehouse. Once in a while non-sense such as data virtualisation or NoETL will pop up. However, if you want success with your data warehouse you will need ETL.
You get an indication of the close knit relationship between ETL and data warehousing by looking at the graph below.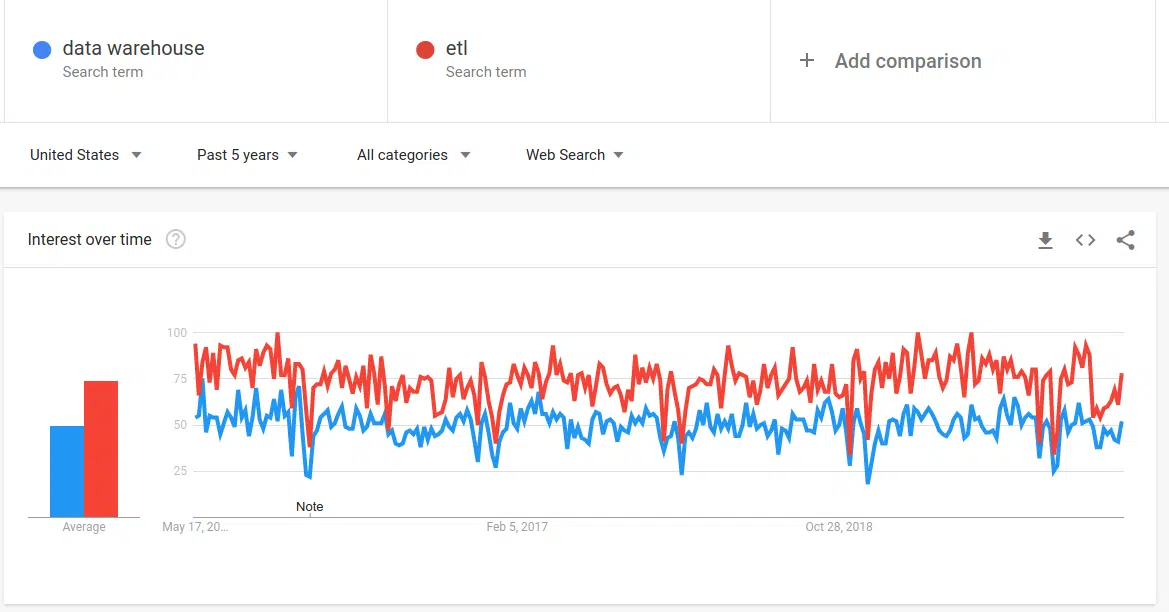
https://trends.google.com/trends/explore?date=today%205-y&geo=US&q=data%20warehouse,etl
The first ETL programs were custom developed in Cobol, C or C++. These days these languages are quite alien to data engineers. As you can imagine using low level languages like these was a very manual and labour intensive process. It required very specialised skills.
ETL tools started to become more and more popular in the 90s. They took care of some of the complexity and abstracted some of the recurring patterns into a GUI. The idea was for less technical people to click together ETL pipelines in a graphical user interface. This is the reason why these tools often are referred to as point and click tools.
The failure of ETL tools
Over time it became obvious that point and click ETL tools have serious limitations.
- The abstractions that these tools offer to implement business logic are not rich enough to meet requirements. It takes more than a lookup to implement complex business logic, e.g. inter row calculations or oven moderately complex logic is impossible to implement.
- Closely related to the issue of poor abstraction capabilities is poor productivity. Let me call it the death by a thousand clicks. It is a lot quicker to write an SQL statement than to click and map something together in a point and click GUI. I know of many ETL tool implementations where the tool is only used for data orchestration. All of the transformation logic is built in SQL and then the tool is just used to build the pipeline and workflow. A very expensive way of dealing with your workflow or data orchestration requirement. 🙂
- In many cases ETL tools offer poor performance as they use a row based rather than a set based approach. Some don’t have the ability to scale out across a cluster of nodes.
- Poor transparency. The code that ETL tools generate internally is a blackbox. It is not transparent to the data engineer, which makes it difficult to debug and requires long sessions with the vendor’s support team.
- Poor integration with source control. A GUI is just a lot harder to integrate with granular version control than code.
- Lineage. Paradoxically ETL tools claim to offer data lineage support. However, as few people use them in the pointy and clicky way they are intended and instead write the business logic in SQL, lineage does not exist.
- Limited or no automation. Each data flow or layer in the data warehouse has to be clicked together.
- While metadata may be stored somewhere it is often not accessible to the ETL engineers.
- Fool with a tool syndrome. When hiring ETL engineers, management looks for tool knowledge rather than data warehouse foundational knowledge. This is a recipe for disaster. I once interviewed an ETL engineer with many years of point and click experience who had never touched SQL. How it would be possible to create a successful data warehouse implementation with such resources is beyond me.
- The business transformation and the data integration logic are tightly coupled. You will see business logic such as transformations mixed with data integration logic such as truncating a table, disabling indexes, collecting table statistics, CDC logic etc. You can’t change the business logic without having to change the data integration logic. Re-use of the data integration logic is not possible.
What is the alternative?
As a result of these limitations a new breed of tools emerged in the early noughties. About 15 years ago I had the pleasure myself to work with one of these tools for the first time. At the time the tool was called Sunopsis. Later on it was acquired by Oracle and licensed as Oracle Data Integrator. It is still widely used today and we still get thousands of hits a month on our website in relation to it.
Sunopsis was probably one of the first data warehouse automation tools on the market. Sunopsis was particularly popular with Teradata implementations as it used the Teradata MPP engine to scale ETL on a cluster of nodes. It followed a push down ELT approach where it generated SQL code and executed the SQL code directly on the data warehouse platform.
It had some core features of what now is referred to as data warehouse automation.
- ELT. The tool generated SQL code and executed the code directly on the data warehouse platform of choice. You don’t need separate hardware. You avoid the blackbox approach. ELT can be combined with point and click and in this incarnation should we avoided, e.g. Oracle Warehouse Builder follows this approach.
- Automation was achieved through re-usable code templates which are fed by metadata and generate the ETL code in SQL. You can think of a code template as a function where you pass in a data set as input and get a data set as output. Optionally you can also design the function to pass in additional parameters to complement what you have in your metadata or to override it.
- Separation of business logic from data integration logic. You can change one without affecting the other. You can re-use both.
We will go through some examples in a minute.
Automation
But let’s take a step back. Before we look at automation in a data warehouse context, let’s take a look at what automation means in general and what its benefits are?
Automation or robotization, is the method by which a process or procedure is performed with minimal human assistance and intervention.
Before a process can be automated a couple of things need to fall into place:
- A pattern of recurring steps exists and we are able to identify it.
- We need to perform the pattern more than just a few times. Otherwise the overhead of automation is greater than the benefits.
The pattern needs to be well understood. There is no point of automating something that needs to be changed over and over again.
- Automation is cheaper than running the process manually
- The type of automation does not require human domain knowledge. Some recurring patterns can not be automated because they require human intervention, e.g. driving a car can still not be automated. The same applies for creating an enterprise data model.
- Even though you can automate something it may not be desirable for ethical reasons because of the side effects, e.g. mass unemployment.
Benefits of automation
- Increase in productivity
- Faster time to market. No long project and development lifecycles.
- Increase in accuracy. Humans make mistakes. By automating a process you eliminate errors and as a result increase quality.
- Decrease in boredom and alienation from repetitive tasks. Resources can work on interesting problems that add value to the organisation.
Data warehouse automation
How does the concept of automation relate to the idea of automating a data warehouse?
First of all a word of warning. Data warehouse automation is not a silver bullet. It does not automagically build the data warehouse for you. However, there are recurring patterns when building a data warehouse that can be automated. Some others can’t.
As an example: There are some tools that use a rules based approach to generate data models for you. This is non-sense and results in data source centric data models. Data modeling requires human domain knowledge and can not be automated without external context. If at all possible the way to go is with semantics, ontologies, and taxonomies. My advice is to stay away from these types of tools.
Data warehouse automation follows the same principle as automation in general. It also has the same benefits.
In data warehousing and data integration we come across recurring patterns like in most other domains. Any of these patterns lend themselves to automation taking the caveats I mentioned earlier on into account, e.g. the overhead of automation should not exceed the benefits.
Some examples of recurring patterns in data integration.
- Loading a staging area
- Loading a persistent staging area
- Loading a Slowly Changing Dimension
- Loading a Hub in a Data Vault
We can automate all of these processes with the right metadata. Let’s take the loading of a staging area as an example. If you have a relational database as a source, all you need to know is the connections and the names of the tables you want to load to fully automate the generation of your staging area. Using this input you can connect to the source database, collect metadata from the information schema, translate this information, e.g. data types to your target technology and pull the data across to the target data warehouse. You can take this a step further and also automatically maintain the full history of changes in a Persistent Staging Area. The only additional information you need is a unique key. You can either get this information from the information schema of the source database, derive it from samples, or feed it into the process from outside as a parameter. You can take this one step further and also build some sort of simple schema evolution into the process. By monitoring the columns in the information schema of the source database and checking if any columns were added or deleted. Based on this information you can dynamically adapt the structure of your staging table and the SQL you generate to load the data.
What all of these examples have in common is that they rely on a rich set of metadata being available.
Metadata is everywhere
Let’s take a common scenario as an example: Loading a fact table in overwrite mode from a couple of staging tables.
Both the source tables and the target table come with metadata, e.g. the names of the columns, the data types, information on keys and relationships, the mapping between source and target columns etc. This information can be stored as metadata in a metadata catalog, e.g. an information schema in a database is such a metadata catalog.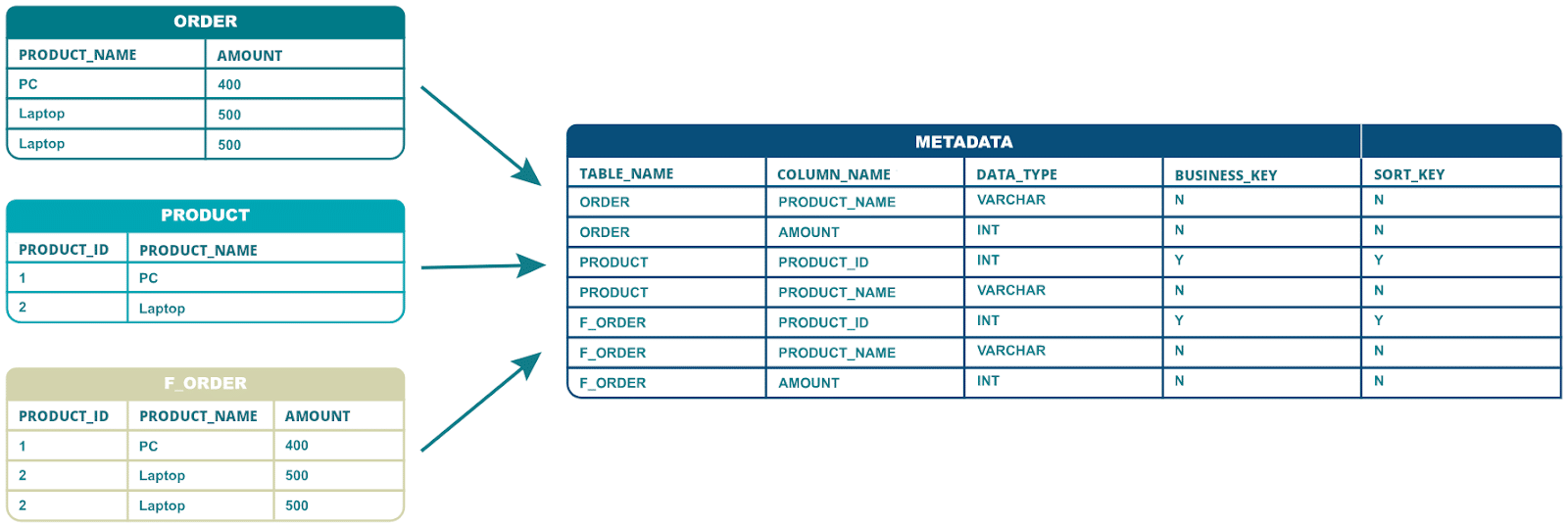
We add the data integration logic and the business transformation logic to the metadata mix and can now fully automate the process.
The business transformation logic comes in the form of an SQL statement. In this particular example a very simple one.
The data transformation logic comes in a metadata driven and paramterised code template (a function). In this particular example our data integration logic is a simple overwrite in an Oracle database.
The advantage is that we separate the business transformation logic from the data integration logic. Making a change in a code template / function will be applied to all instances where the code template is used. Making a change in the business logic does not require a change in the data integration logic.
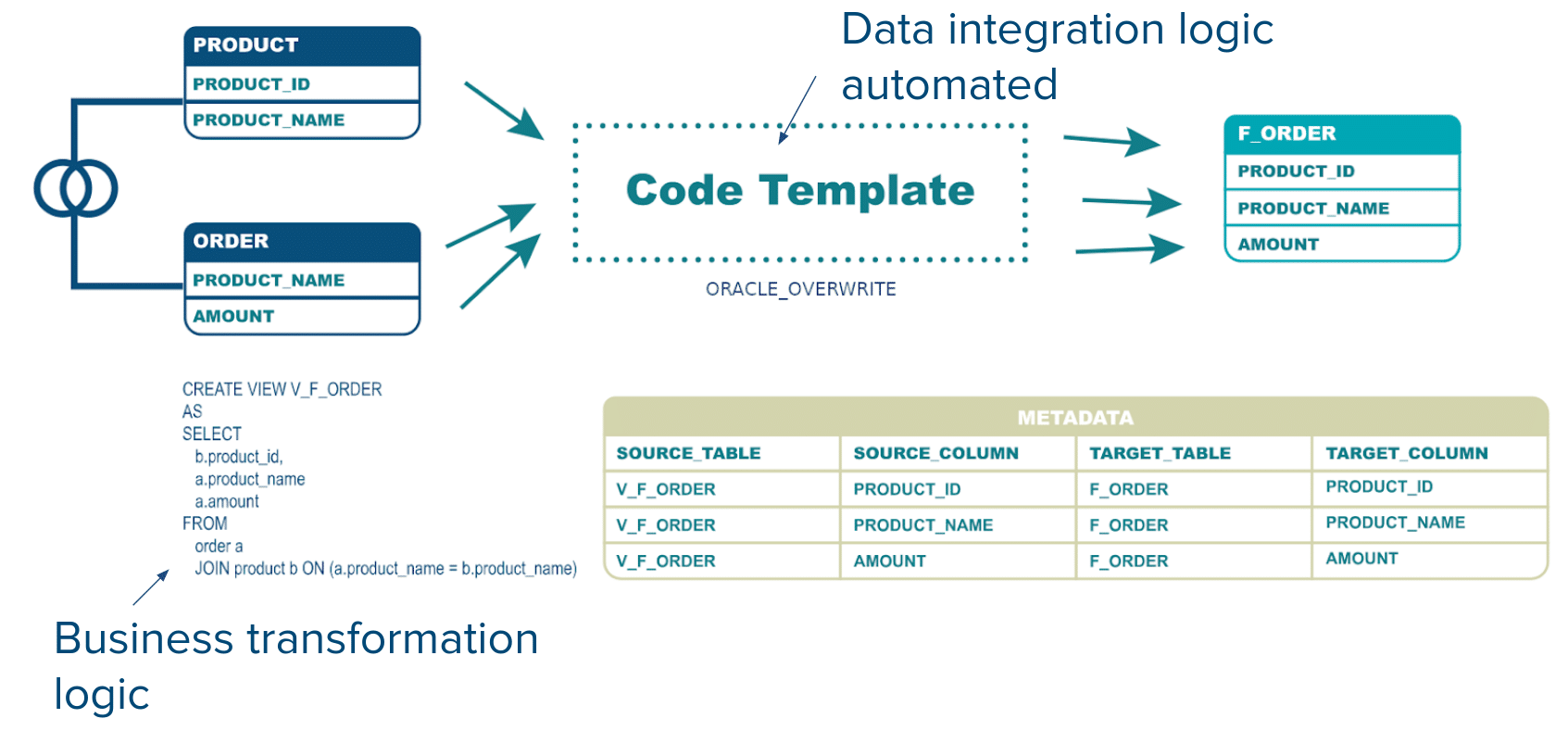
Let’s have a look inside the code template
Our code template / function is pretty simple for illustration purposes. In the real world you can implement any level of complexity. It comprises three recurring steps. In the first step we truncate the target table. We get the information on the target table name from the metadata.
In the second step we inject the metadata such as target table, source table name (in our case a database View), and source column to target column mappings into the code template to generate the INSERT logic. Optionally we add an ORDER BY clause to presort the data. The name of the sort column can be retrieved from the metadata or we can override it by passing in the name as a parameter.
In the last step we collect statistics against the target table for the optimizer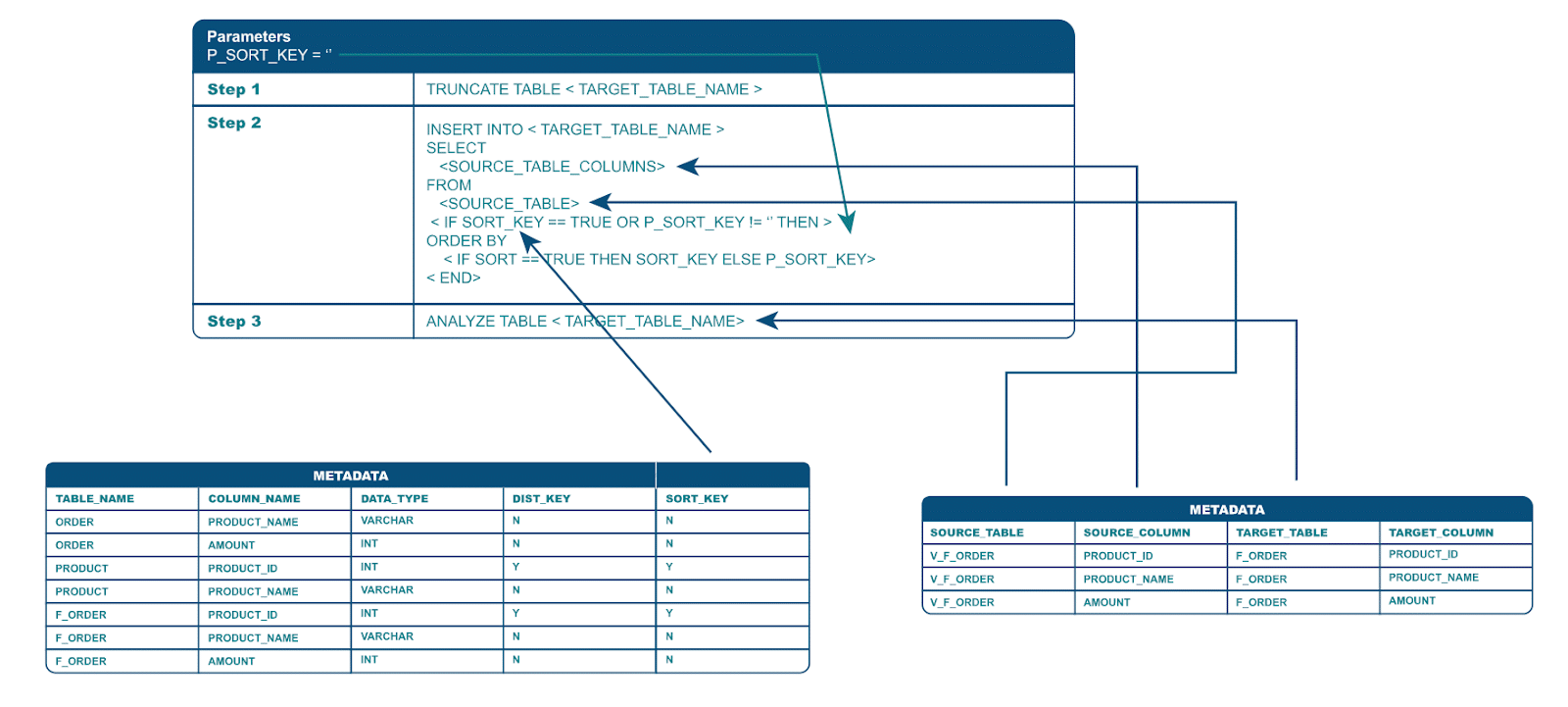
We can now re-use the code template to load other target tables, e.g. F_ORDER_ITEM instead of F_ORDER
We could easily swap out the code template for an Upsert / Merge if our data integration requirement changes.
We can easily modify the business logic in case it changes.
Everything can be easily put under source control.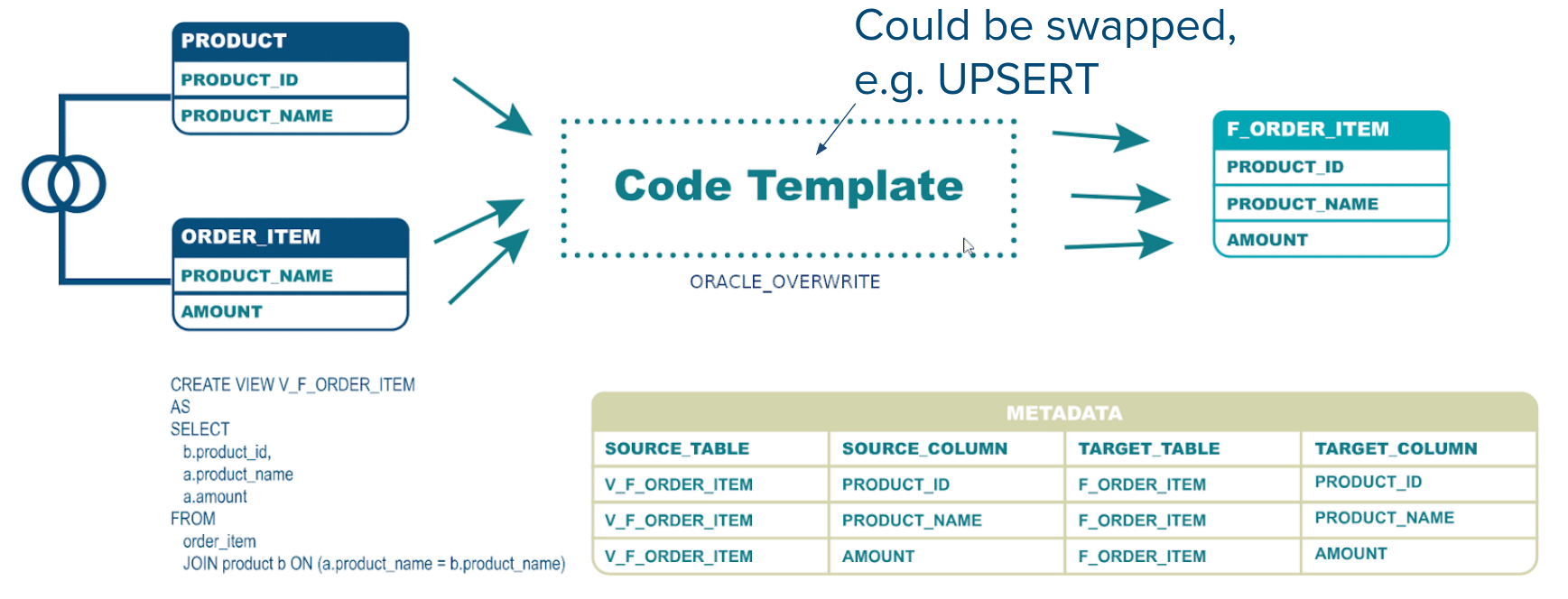
Here is a final example.
We can easily swap out the target table, e.g. F_ORDER_AGG instead of F_ORDER. Also notice the change in business transformation logic.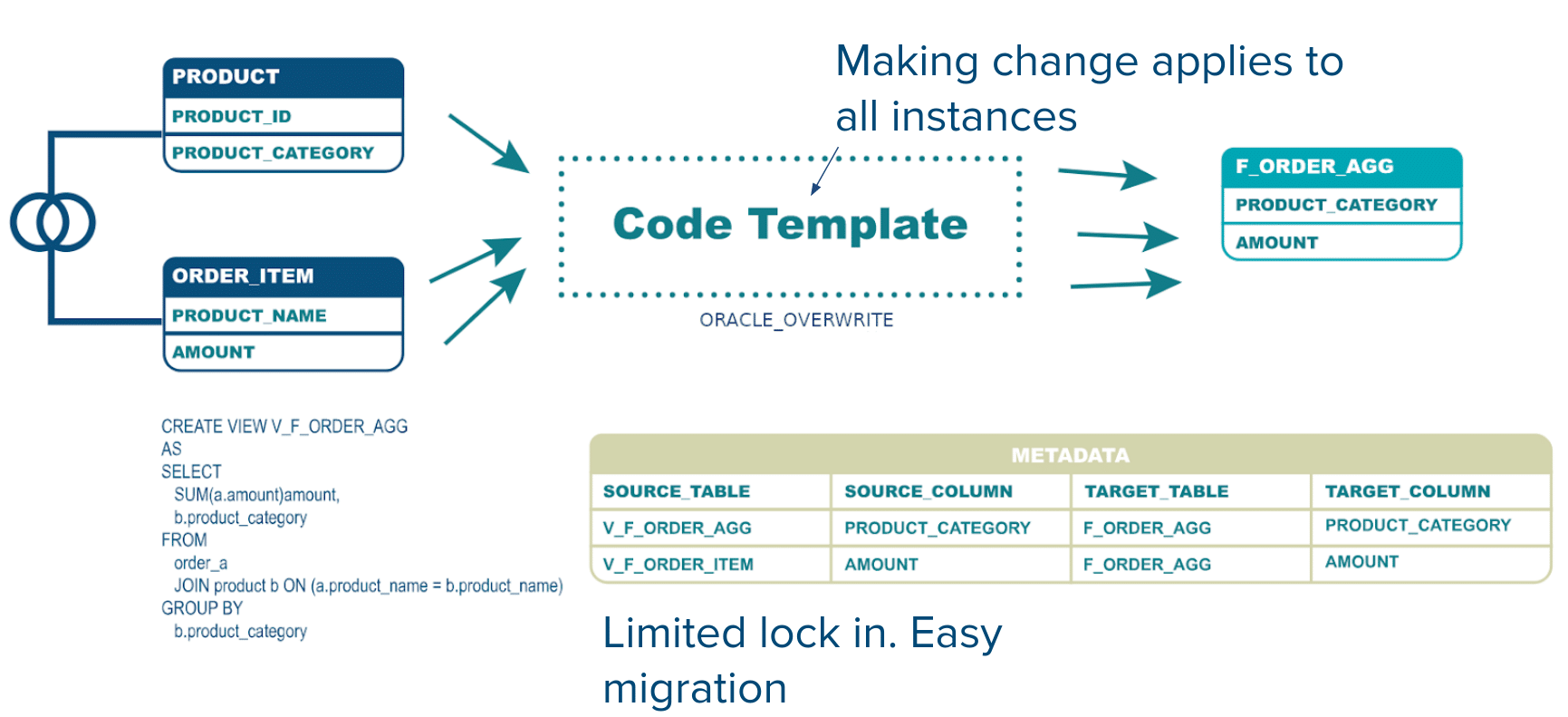
Data warehouse automation for automated XML converter and JSON
The last example I have is of using data warehouse automation to convert XML to CSV online or JSON to a relational format. For simple XML it may make sense to write some code to do it.
However, once your XML gets complex or you have large volumes of data, the overhead of developing and maintaining the conversion manually quickly becomes too much.
In the image below we have reverse engineered the XSDs of the FpML standard in an XML editor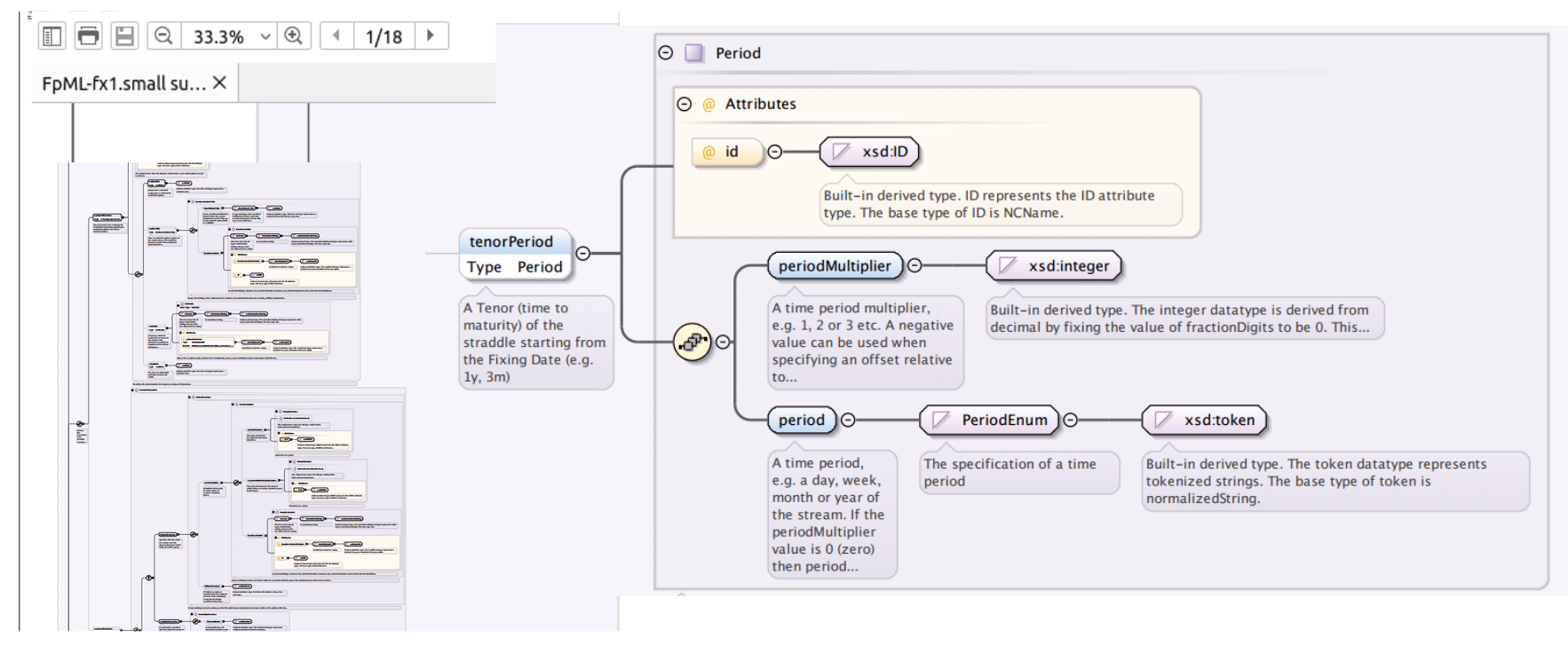
As you can see the PDF goes across 18 pages with thousands of elements. Having to deal with this manually will add a lot of overhead.
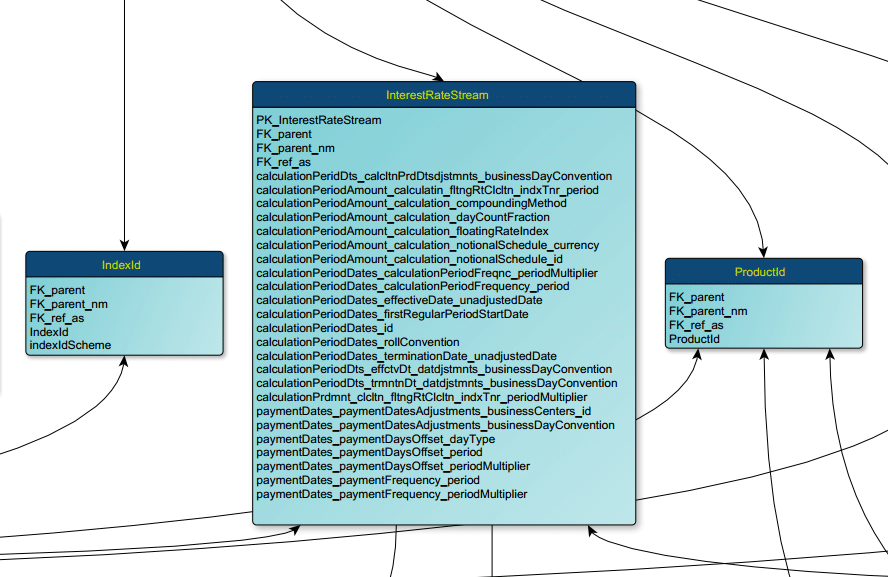
Our own tool Flexter can fully automate the conversion of XML or JSON to a relational database, text, or big data formats Parquet, ORC, Avro.
Here is the optimised target schema that Flexter generates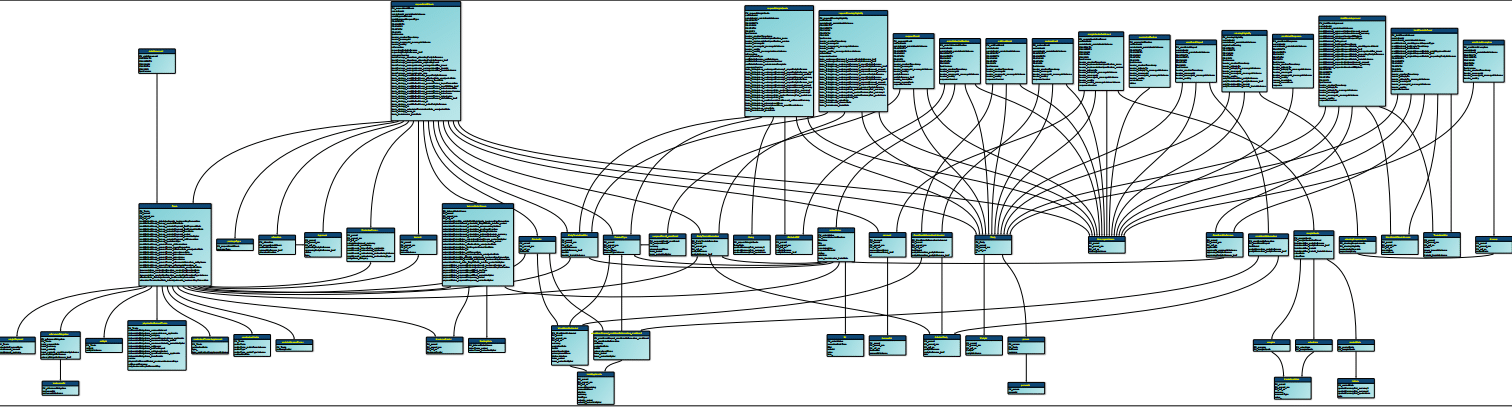
Conclusion
So what are my recommendations? Both manual coding and point and click ETL tools should be avoided. I am also not convinced of any of the existing data warehouse automation tools I have seen apart from one. You can reach out to find out more.
At Sonra, we use Apache Airflow to build our own re-usable data warehouse automation templates. We have written a blog post that illustrates how you can leverage Airflow to automate recurring patterns in ETL. We have implemented this appraoch on Snowflake with many of our clients and it just works 🙂
If you need help or have any questions contact us.
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: