Tips for parsing and loading complex NDC XML files in ODI

This is the second part in a multi part series on XML processing in ODI. In our previous post Tips for Reverse Engineering complex XSDs such as SEPA and NDC in ODI (URL) we have shown you a lot of useful tips for reverse engineering complex XSDs in ODI. The third part compares ODI to Flexter, our very own dedicated enterprise XML parser.
In this post, we will show you more useful tips. This time on how to parse and load the SEPA and NDC XML files into an Oracle database. We will also show you some best practices on orchestrating and building your data flow.
The data load part is pretty straightforward. We build mappings from the XML source Model into the target Model of the database.
Get our e-books Discover the Oracle Data Integrator 11g Repository Data Model and Oracle Data Integrator Snippets and Recipes
[flexter_banner]
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Create Mappings to load XML
So far we have only worked with the XSD schema. From now on we will work with sample XML files to test and validate any mappings we create. We need to alter the JDBC URL in the Physical Schema slightly and give it the name of the XML file:
file=Kronos_FlightPriceRS-Round_Trip.xml.
Now, it’s time to build the mappings from the XML ODI Model into the target database ODI Model. Hold on though. What is missing for the mappings are the target datastores. We first need to model them in the target (Staging) area.
This is best done by using the Copy & Paste functionality in ODI.
TIP 1. Use copy & paste functionality available for datastores:
Once you paste into the target model, the datatypes will be automatically converted into relevant technology (here Oracle). When you create the mappings you need to switch on the option CREATE_TARGET_TABLE in the Knowledge Module and ODI will create the target tables.
Building those mappings doesn’t seem to be challenging job. Yes unfortunately, and the really bad news here for the developer are that this needs to be done for all relevant tables. As mentioned in the previous post, identifying subset of the tables from the model that should be copied over to the Staging area poses a challenge itself.
There can be a lot of tables (2333 for FlightPrice schema!) and no simple way to query it as those are not in the regular database yet.
The following picture shows the reverse engineered FlightPriceRS model by ODI. You basically need to figure out now for which tables from the following model you need to create Mappings. Alternatively you can map them all…
TIP 2. To examine the content of the XML datastores you may try to use native ODI functionality by using option “Data” or “View Data” from the datastore’s pop up menu.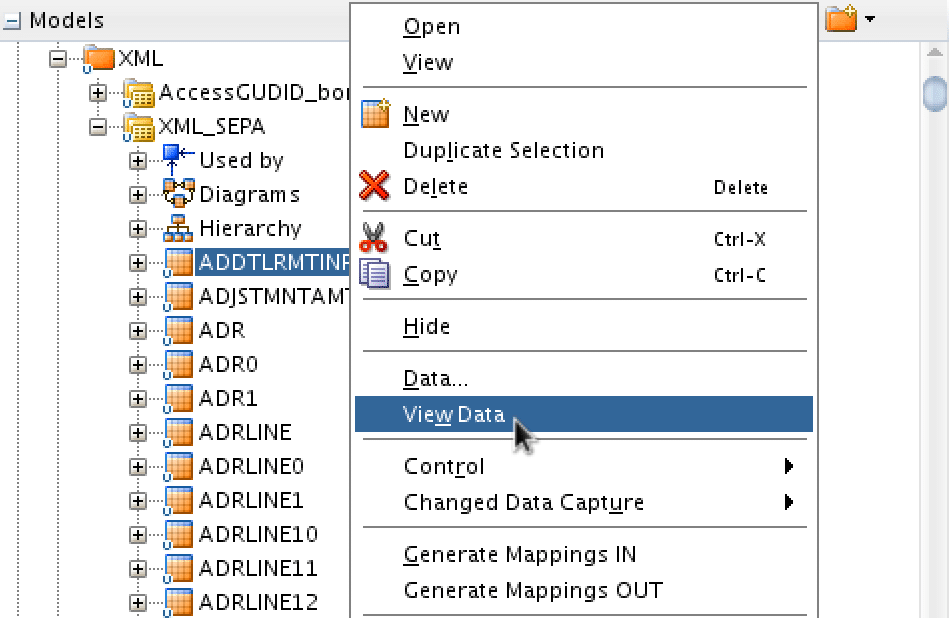
Once the tables to copy are identified it’s time for a long and boring task of creating all the required mappings.
From our experience about 10-15% of the total number tables have data and are relevant for further downstream processing. In our case that gives us 200-300 tables that we need to create mappings for.
Orchestrating a data flow for XML in ODI
Now, that we have mapped all the relevant XML data into our target schema we’re good to go …for a single XML file.
If we expect more, which usually is the case, we need to create a loop over all of the available XML files. That is our only option. There is no bulk loading facility for XML in ODI. It’s procedural all the way.
The usual approach to loop over files, a very ODI-way of doing things, goes as follows
1) run OS command (dir or ls depending on host OS) to dump the list of files into another file
2) read that file into ODI, file by file
a) create physical server for File technology. Point to the file created using OS dir/ls command
b) create logical server for this, assign context
c) reverse engineer file into ODI model
d) read data from the datastore
3) Create an ODI Package with a loop
a) add steps for variable initialisation and its refresh from the datastore
b) conditional expression to exit once no more files left
I bet this looks very familiar to any seasoned ODI developer. And if you think about it, it’s true overkill, cracking a nut with a sledgehammer. I’m not going to cover those steps in any more detail. Instead, I’m going to do something different. I’ll show you a leaner, faster and more elegant way.
TIP 3: Build your data orchestration with Java BeanShell scripting.
Java BeanShell is dead for more than 10 years now. It just supports JDK 1.4 syntax and ODI is probably the last place on earth where it’s still in use, but it’s used big time!
In comparison to other ODI scripting languages like Jython or Groovy its biggest advantage in ODI is that it can be used inside any other ODI Technology: Oracle, MS SQL, DB2, HSQLDB, OS command or even ODI tool – you name it.
It’s the underlying technology that all Knowledge Modules heavily depend on, doing all the magic and substituting all the relevant bits from the ODI repository into the SQL code templates. ODI wouldn’t be a metadata driven tool without it.
My improved solution requires two steps:
- pulling the list of files into memory
- reading subsequent elements from that list into an ODI variable.
For (1) we need a single task procedure. Pick Java BeanShell technology and put the code to execute as below:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
/*<? import java.io.File; import java.util.ArrayList; import java.util.List; int i = 0; File folder=new File("<%out.print(odiRef.getOption("SOURCEPATH"));%>"); File[] list = folder.listFiles(); List files = new ArrayList(); for (File item : list) { files.add(item.getAbsolutePath()); } ?> */ |
This will create the list of all the files inside a directory and store it inside a Java BeanShell variable. The path to search is passed through a procedure’s option SOURCEPATH:
The 2nd step is quite simple – we need to pass the value from Java BeanShell variable onto the ODI variable. The variable refresh step is the following one-liner:
|
1 |
SELECT '<?=i<files.size()?files.get(i++):""?>' FROM DUAL |
To exit the loop, we need to evaluate the variable and check that it’s not empty. For this we simply need to put ‘<>‘ as the operator 🙂
It has less steps, no dependency on File or other data sources and it’s OS independent. To sum up, we have gone through each of the three steps to load XML data using ODI and highlighted the potential pitfalls. Let’s move onto the biggest problem when loading XML files with ODI. Performance.
ODI Performance Problems when loading XML files
I hear you. All of this looping and procedural logic is a real pain, time consuming, and costs money. However, it gets worse and you may have guessed it. Creating all of those loops comes with a performance penalty. A serious one that is. Think about it for a minute. We have 300 data stores that we need to load. Each time we load one of the target stores we need to iterate over the XML file. For one XML file that makes 300 iterations, for two XML files 600 iterations, for three XML files 900 iterations. You see where I’m going with this. The maths has no mercy here. Once the complexity of the XML file goes beyond a certain limit and you have a large volume of XML files you will break ODI’s neck. A mere 50,000 files will require 15M iterations. In travel, healthcare, or finance this is a common requirement. This all means the load process goes from table to table and then repeats that all over again, file by file. This makes the whole procedure a very long sequence of I/O operations interwoven with micro inserts.
This process could be greatly improved by performing those operations in bulk. Or even better: performing these operations in bulk, parallelising them across CPU vcores, and parallelising them across multiple servers. This is what Flexter, our very own XML Enterprise parser does.
In the next post we are going to show you how Flexter solves all of these problems automatically, in bulk, and without any coding or complex configuration:
- automatically create an optimized relational target schema
- automatically load files in parallel into memory
- automatically transform data
- automatically write data in parallel to output
Flexter reduces the development effort for parsing and loading XML files by about 99.9%.
If you can’t wait for our next post feel free to dive right into Flexter with our free online version
Which data formats apart from XML also give you the heebie jeebies and need to be liberated? Please leave a comment below or reach out to us.




