How to Convert ISO 20022 XML to a Relational Database

ISO 20022 XML solves the financial messaging problem.
It does not solve your data engineering problem.
Can your systems send, receive, and validate a pain.001 or pacs.008 message?
Good.
Can your analysts query payments, accounts, parties, agents, references, and statuses in SQL without XPath gymnastics?
That’s a totally different problem.
ISO 20022 messages are hierarchical, not relational.
Valid XML is only the starting point. The real job is preserving the business structure inside queryable database tables.
That is where ISO 20022 stops being a messaging format and becomes a data modelling problem.
This guide closes that gap.
What works:
- ISO 20022 XML works well for exchanging structured financial messages.
- XSD schemas are available online for this ISO and work well for validating message structure.
- Raw XML loading and storage work for archiving and inspection.
- Native XML support in databases such as Snowflake can help with quick exploration.
- Custom code can work for you if your project only involves a single stable message type and a single narrow use case.
What does not work:
- Loading ISO 20022 XML and calling it “converted”.
- Flattening everything into one giant table.
- Hard-coding XPath logic for every message version.
- Assuming ISO 20022 message families share the same structure.
- Expecting analysts to query deeply nested XML directly from the database.
- Treating one ISO 20022 version as if it will survive every counterparty, schema change, and production edge case.
To make ISO 20022 data searchable, queryable, and analytics-ready for your use case, you need to convert the XML hierarchy into relational tables.
That means preserving the core business structure: headers, payments, transactions, parties, accounts, agents, references, and parent-child relationships.
In this guide, I’ll show why ISO 20022 XML to database conversion gets messy, and how automation can turn ISO 20022 XML into SQL tables without manual code and brittle custom mappings.
I know you’re busy. Here’s a TL;DR for this blog post:
- ISO 20022 works well for messaging. It gives financial systems a common XML format for payments, accounts, parties, and status updates.
- It does not work as a database model.
painandpacsmessages are hierarchical XML documents, not relational tables. You can query them only through XML-aware functions or XPath/XQuery-style logic, unless you first convert them into SQL tables. - Loading XML is only step one. Storing raw ISO 20022 XML helps with archiving and inspection, but not with analytics.
- The hard part is relational modelling. You need tables, keys, and relationships that preserve the original payment hierarchy.
- Manual parsing gets fragile. XPath logic breaks when message versions, namespaces, optional branches, or counterparties change.
- Automation is safer for real-world projects that need to scale.
- Dedicated XML to SQL converters can read the ISO 20022 XSD and generate SQL-ready tables, mappings, and relationships automatically.
Too tired to read through?
Jump straight to the comparison table for the ISO 20022 XML to database options.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
What Is ISO 20022 XML?
ISO 20022 is the financial messaging standard behind a huge part of the world’s money movement.
It uses XML as its data exchange format and is used by financial institutions in more than 70 countries.
ISO 20022 is not limited to payments. It covers 20 business domains, including payments, securities, cash management, and trade services.
So it’s not just one XML being moved around from one bank to another.
It is a family of message types used across a payment flow:
- One message can start a payment.
- Another can move it between institutions.
- Another can report its status.
- Another can show the final result in account reporting.
The figure below shows how these message types connect in a Payment Flow example: 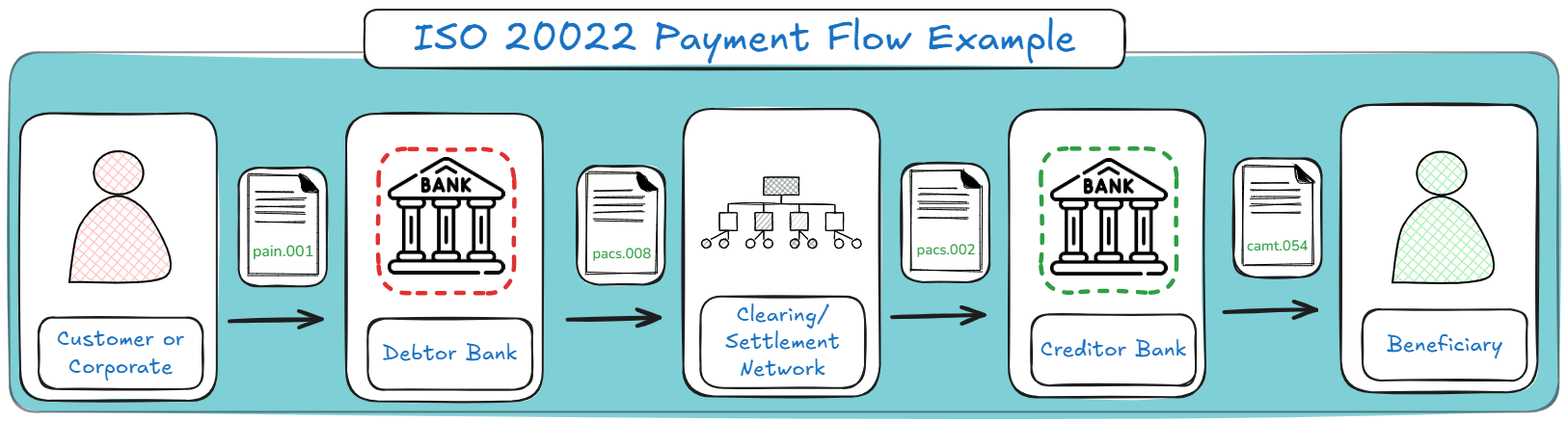
A pain.001 message can initiate a payment. A pacs.008 message can move that payment between financial institutions. A pacs.002 message can report the payment status during processing. A camt.053 can report the account statement later; camt.054 can report debit/credit notifications.
All of them are ISO 20022 XML. And none of them are shaped like clean database tables.
Pro tip
ISO 20022 names are structured, not random.
In pain.001.001.09, pain is the business area, the first 001 is the message functionality, the second 001 is the flavour, and 09 is the version.
Same pattern for pacs.008.001.09.
That final version number matters. Parsing logic built for one version may break on another.
ISO 20022 is useful because it provides a common way for systems to describe the same payment data.
That is why ISO 20022 shows up in payment workflows such as Swift CBPR+, SEPA, and Fedwire.
Info box
The names sound more complicated than they are:
- Swift is the messaging network banks use to send financial messages.
- Swift CBPR+ is the ISO 20022 rulebook for cross-border payments on the Swift network.
- SEPA is used for euro payments in Europe.
- Fedwire is used for high-value payments in the US.
Different names. Same idea: they all need a clear way to describe payment data.
But that only solves the messaging problem.
Once ISO 20022 messages arrive in your systems, the goal is no longer just to receive them.
The goal is to analyse the data and answer business questions.
You are no longer just asking:
“What is ISO 20022?”
You are asking:
- “How many payments did we process this week?”
- “What was the total payment volume by currency?”
- “Which payments failed?”
- “Which accounts were credited or debited?”
- “Which transactions need investigation?”
These are simple questions to ask.
They are much harder to answer when the data is still buried inside nested XML.
That is where the engineering problem starts:
“How do I validate this XML, parse it, flatten it, store it, and query it without turning my pipeline into a pile of custom mappings?”
Continue reading to find out.
Pro tip
When you look at an ISO 20022 XML file, you are not just looking at “some XML”.
You are looking at the XML representation of a formal financial data model.
That distinction matters because the structure was designed for precise financial messaging, not for easy SQL querying. The XML is the “transport” format.
The hard part is turning the underlying model into tables that your analysts and downstream systems can actually use.
ISO 20022 Message Families and Types
ISO 20022 message types are not random XML files.
They are organised into message families, each covering a different stage of the financial transaction lifecycle (as I showed you in the section above).
A payment might start as a pain.001 customer credit transfer initiation, move across the banking network as a pacs.008 interbank credit transfer, get a status update through pacs.002, and later show up in account reporting through camt.054.
That is the important bit.
These messages are connected. Identifiers such as EndToEndId, original transaction references, and settlement references tie them together across the flow.
So if you treat each ISO 20022 message as a standalone XML file, you miss the bigger picture.
Here are the main ISO 20022 message families you will usually run into:
|
Message Family |
Business Domain |
Most Common Messages |
Typical Use Case |
|---|---|---|---|
|
pain |
Payment Initiation |
pain.001, pain.002, pain.007, pain.008 |
Customer credit transfers, direct debits, payment reversals, and payment status reports. This is what people often mean by ISO 20022 pain XML. |
|
camt |
Cash Management |
camt.052, camt.053, camt.054, camt.056 |
Account reports, bank-to-customer statements, debit/credit notifications, and cancellation requests. |
|
pacs |
Payments Clearing and Settlement |
pacs.002, pacs.003, pacs.008, pacs.009 |
Interbank payment status, direct debits, customer credit transfers, and financial institution credit transfers. |
|
sese |
Securities Settlement |
sese.023, sese.024, sese.025, sese.026 |
Securities settlement instructions, confirmations, allegements, and status messages. |
|
acmt |
Account Management |
acmt.001, acmt.002, acmt.003 |
Account opening, account details confirmation, and account modification. |
|
tsmt |
Trade Services Management |
tsmt.001 through tsmt.055 |
Trade finance workflows, including matching, baseline, and trade services processes. |
|
fxtr |
Foreign Exchange |
fxtr.008, fxtr.014, fxtr.015 |
FX trade status notifications, trade instructions, and trade instruction amendments. |
With these in mind, what you should know next is that the ISO 20022 Repository and the ISO 20022 Messages Archive give you access to any of the raw materials for the message families:
- message definitions,
- message sets,
- documentation,
- and XSD downloads.
So if you check this material on the ISO 20022 Repository, you will find the XML messages used in business areas such as Account Management, Cash Management, Payments Clearing and Settlement, Payments Initiation, and Foreign Exchange Trade.
So, is the ISO 20022 standard useful and valuable for you and your team? Yes, without a doubt.
Is it simple to use? Not really.
For data engineering, each family brings its own structure.
A pain.001 payment initiation message does not look like a camt.053 bank statement. And a securities settlement message won’t behave like an FX trade notification.
Different families mean different nesting patterns, repeating groups, parent-child relationships, and target table designs.
And a lot of headaches if you try to manually convert each message family to a database across your ISO 20022 workflows.
So yes, ISO 20022 is a valuable standard. But it is not one single XML shape.
And that is where manual parsing and converting start to get ugly.
In the next section, I’ll show you exactly how these XML and XSD messages look, so that you get a glimpse of the workload involved in parsing and analysing them one by one.
The Structure of an ISO 20022 XML Message
So far, we have talked about ISO 20022 message types. Now let’s look at the XML’s structure itself.
Every ISO 20022 XML message is defined by an XSD. XSD stands for XML Schema Definition.
Think of the XML as the actual payment message, and the XSD as the rulebook for that message:
- The XML contains the data: payment IDs, amounts, parties, accounts, dates, and references.
- The XSD defines whether that data is structurally valid: which elements are allowed, which are required, which can repeat, what data types they must use, and in what order they must appear.
That matters because before you can safely parse ISO 20022 XML into database tables, you need to know the structure you are parsing. The XSD gives you that structure.
Next, I’ll show you two examples from the ISO 20022 payment lifecycle introduced earlier:
- The pain.001.001.09 message starts the payment from the customer side.
- The pacs.008.001.09 message carries the same payment between banks.
The useful part is that some fields, such as EndToEndId, can be carried from one message to the next.
That makes the payment easier to trace throughout the payment lifecycle.
If you stick with me, in the next few subsections, I’ll show you how EndToEndId is used in practise.
Pro tip
EndToEndId is one of the most useful fields for ISO 20022 analytics.
It lets you connect the original customer instruction in pain.001 with the later bank-to-bank message in pacs.008, as well as the rest of the messages in the payment flow.
That matters for reconciliation, tracking, audit checks, and other challenges of payment lifecycle analysis.
Downloading the pain.001.001.09 XSD
Before examining the XML example, I’ll first show where to find and download the corresponding XSD.
The pain.001.001.09 XSD can be downloaded from the ISO 20022 Messages Archive.
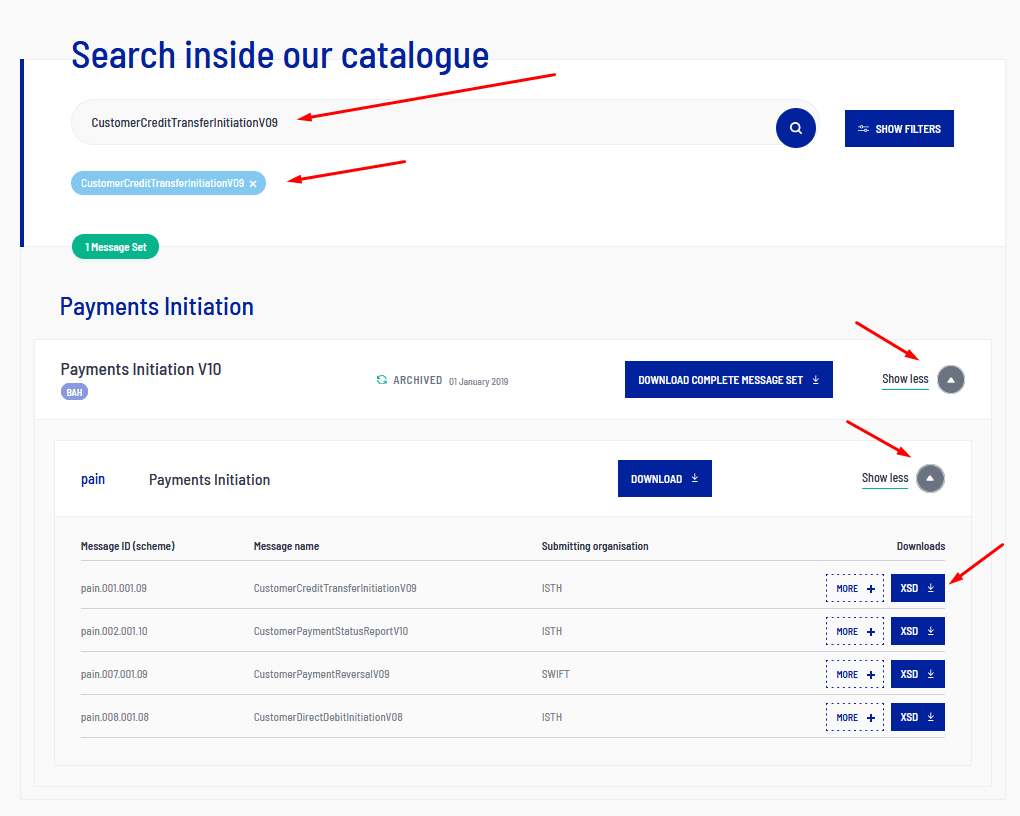
In the screenshot below, the ISO 20022 message catalogue is filtered for pain.001.001.09.
The result appears if you search for CustomerCreditTransferInitiationV09 and under Payments Initiation V10.
Example 1: pain.001.001.09 XML message
After downloading the XSD as shown in the previous section, you can use it as a reference for the XML message structure.
The following is a simplified pain.001.001.09 XML example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
<?xml version="1.0" encoding="UTF-8"?> <Document xmlns="urn:iso:std:iso:20022:tech:xsd:pain.001.001.09" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="urn:iso:std:iso:20022:tech:xsd:pain.001.001.09 pain.001.001.09.xsd"> <CstmrCdtTrfInitn> <GrpHdr> <MsgId>ACMECORP-20260423-0001</MsgId> <CreDtTm>2026-04-23T09:15:00Z</CreDtTm> <NbOfTxs>1</NbOfTxs> <CtrlSum>1000.00</CtrlSum> </GrpHdr> <PmtInf> <PmtInfId>PAYRUN-20260423-01</PmtInfId> <PmtMtd>TRF</PmtMtd> <ReqdExctnDt> <Dt>2026-04-23</Dt> </ReqdExctnDt> <Dbtr> <Nm>Acme Corporation SA</Nm> </Dbtr> <DbtrAcct> <Id> <IBAN>GR1601101250000000012300695</IBAN> </Id> </DbtrAcct> <CdtTrfTxInf> <PmtId> <InstrId>AP-20260423-0001</InstrId> <EndToEndId>INV-984533-2026-04</EndToEndId> </PmtId> <Amt> <InstdAmt Ccy="EUR">1000.00</InstdAmt> </Amt> <Cdtr> <Nm>Supplier Industries GmbH</Nm> </Cdtr> <CdtrAcct> <Id> <IBAN>DE89370400440532013000</IBAN> </Id> </CdtrAcct> <RmtInf> <Ustrd>Invoice 984533 April 2026</Ustrd> </RmtInf> </CdtTrfTxInf> </PmtInf> </CstmrCdtTrfInitn> </Document> |
At a high level, the structure looks like this:

The Group Header (GrpHdr) describes the file.
The Payment Information block (PmtInf) describes the payment batch.
The Credit Transfer Transaction Information block (CdtTrfTxInf) contains the actual payment.
That is where you find the amount, currency, payment reference, debtor, creditor, account details, and remittance text.
As I told you before, the most important element is the EndToEndId. In this example, the value is INV-984533-2026-04 and is located under CdtTrfTxInf.
That value can (and will) travel with the payment as it moves through subsequent messages in the flow (see Example 2 below).
Example 2: pacs.008.001.09 XML message
The pain.001 message shows the customer-to-bank instruction.
The pacs.008 message is used in the next step, which is the bank-to-bank message used to move the same payment forward.
Here is a simplified pacs.008.001.09 example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
<?xml version="1.0" encoding="UTF-8"?> <Document xmlns="urn:iso:std:iso:20022:tech:xsd:pacs.008.001.09" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="urn:iso:std:iso:20022:tech:xsd:pacs.008.001.09 pacs.008.001.09.xsd"> <FIToFICstmrCdtTrf> <GrpHdr> <MsgId>ETHNGRAAXXX-20260423-0001</MsgId> <CreDtTm>2026-04-23T09:16:00Z</CreDtTm> <NbOfTxs>1</NbOfTxs> <CtrlSum>1000.00</CtrlSum> <TtlIntrBkSttlmAmt Ccy="EUR">1000.00</TtlIntrBkSttlmAmt> <IntrBkSttlmDt>2026-04-23</IntrBkSttlmDt> </GrpHdr> <CdtTrfTxInf> <PmtId> <InstrId>AP-20260423-0001</InstrId> <EndToEndId>INV-984533-2026-04</EndToEndId> <TxId>ETHN-20260423-TX0001</TxId> </PmtId> <IntrBkSttlmAmt Ccy="EUR">1000.00</IntrBkSttlmAmt> <IntrBkSttlmDt>2026-04-23</IntrBkSttlmDt> <Dbtr> <Nm>Acme Corporation SA</Nm> </Dbtr> <DbtrAcct> <Id> <IBAN>GR1601101250000000012300695</IBAN> </Id> </DbtrAcct> <DbtrAgt> <FinInstnId> <BICFI>ETHNGRAAXXX</BICFI> </FinInstnId> </DbtrAgt> <CdtrAgt> <FinInstnId> <BICFI>COBADEFFXXX</BICFI> </FinInstnId> </CdtrAgt> <Cdtr> <Nm>Supplier Industries GmbH</Nm> </Cdtr> <CdtrAcct> <Id> <IBAN>DE89370400440532013000</IBAN> </Id> </CdtrAcct> </CdtTrfTxInf> </FIToFICstmrCdtTrf> </Document> |
At a high level, the pacs.008.001.09 message has the following structure:

This looks similar to the pain.001 message. But it is not the same shape.
The pain.001 message has a PmtInf block because it is a customer payment initiation file.
The pacs.008 message does not use the same structure. It focuses on interbank credit transfers.
That is one of the first things data engineers (like you) will notice with ISO 20022 XML.
One single business payment can include different XML message types.
Those message types can share important identifiers, but their XML structures are different.
And in case you didn’t notice, the EndToEndId is under CdtTrfTxInf with the value of INV-984533-2026-04.
Other Messages in the Payment Lifecycle
The two examples above show the first two steps from the workflow we saw earlier:
- pain.001 starts the payment from the customer side.
- pacs.008 moves the same payment between banks.
But the payment lifecycle does not stop there. After the payment is sent, other ISO 20022 messages can appear:
- pacs.002 is commonly used to report payment status.
- camt.054 is used later on the account side.
It notifies the customer about debit or credit entries on the account.
So the workflow looks like this:

I won’t include XML snippets for pacs.002 and camt.054 in this section and the blog post.
But it is important for you to take away that ISO 20022 messages are connected. They are not just isolated XML files.
Pro tip
Need more detail on individual ISO 20022 message structures?
Then you should take a look at Swift’s free “ISO 20022 for Dummies” ebook.
Why does all this matter for databases?
These examples are small. Real ISO 20022 XML files can be much larger and more complex.
They can include many payments, many repeating blocks, optional fields, nested parties, addresses, agents, account details, and references.
That is fine for XML. It is not fine for a relational database.
A database wants tables. ISO 20022 gives you hierarchies.
Before you can analyse the data with SQL, you need to convert the XML structure into tables, columns, and relationships.
That is where the conversion problem starts. Let’s dive into ISO 20022 XML conversion to Relational tables in my next section.
Why Converting ISO 20022 XML to Relational Tables Is Challenging
Loading an ISO 20022 XML file into a database is not the hard part.
Many modern database platforms can store raw XML. Snowflake, for example, can ingest XML into a semi-structured column and let you query it later.
That sounds useful.
And it is, up to a point.
But storing ISO 20022 XML is not the same as converting ISO 20022 XML to relational tables.
A database wants rows and columns. ISO 20022 gives you a financial message hierarchy.
That mismatch is where the work begins.
Next, let me walk you through the full list of challenges that you will face in a ISO 20022 to SQL project.
Version fragmentation
The first challenge is version fragmentation.
As I showed you in the previous sections, a pain.001.001.09 message does not use the same XSD as pacs.008.001.09.
The same applies across other ISO 20022 message types. A bank, payment processor, or financial institution may receive multiple versions from different counterparties simultaneously.
That creates a simple but painful problem.
If your parsing logic is hard-coded for one version, it will break when another version arrives:
- A field may move.
- A structure may change.
- A rule may be different.
- An optional element may suddenly become important.
That is why ISO 20022 XML & XSD handling matters. You are not just parsing XML tags. You are working with formal message definitions that can vary by version.
Deeply nested structures
The second challenge is the structure itself.
In the previous section, I showed you a pain.001.001.09 XML message.
Even that small example already had several levels:

That is the friendly version:
- One payment.
- One payment information block.
- One credit transfer transaction.
- A few fields that are easy enough to follow.
But even here, the structure is already hierarchical. The amount is not neatly arranged in a column.
It is under CdtTrfTxInf > Amt > InstdAmt. The currency is not a separate element. It is an attribute of InstdAmt. The debtor account is under DbtrAcct > Id > IBAN. The remittance text is under RmtInf > Ustrd.
That is perfectly reasonable for an ISO 20022 payment message.
And real ISO 20022 XML can be much more deeply nested than this example.
So the problem is not just “XML has tags.”
The problem is that ISO 20022 XML uses nested financial business objects, which do not map directly to a single flat SQL table.
As I showed in my XML converter tool comparison post, most converters cannot automatically interpret nested XML structures.
They cannot reliably decide which block should become the parent table, which repeating block should become the child table, or which keys should link the two.
Pro tip
There are exceptions.
Generic XML converters flatten tags.
Flexter reads the ISO 20022 XSD and generates a relational model with tables, keys, and source-to-target mappings.
That matters because ISO 20022 is not just nested XML. It is a financial data model in XML form.
So, before you can analyse ISO 20022 data with SQL, and if you’re not using a dedicated XML to SQL converter, you need to turn the ISO 20022 data model into a relational model.
That means tables. And relationships. And repeatable conversion logic.
Not just “load the XML and hope for the best.”
In my figure below, you can see how the XML hierarchical tree structure of a pain.001.001.03 message (left side) can be translated into a relational schema (right side) with Primary Keys (PKs) and Foreign Keys (FKs).

Pro tip
Normalisation is the step where you turn an XML hierarchy into separate but related database tables.
For ISO 20022 XML, that means avoiding one giant flattened table and instead preserving relationships between headers, payments, transactions, parties, accounts, and remittance details.
I explain the difference between flattening, denormalisation, and normalisation in more detail here:
Repeating groups and table design
Repeating groups are where manual conversion gets especially messy.
A single pain.001 payment initiation file with 500 credit transfer transactions, each with 30+ sub-fields, already contains 15,000+ data points in one XML file.
A standard SQL INSERT statement cannot consume that directly.
You first need to flatten the hierarchy. But if you flatten everything into one giant table, you risk duplication, cartesian products, and useless reporting tables that nobody wants to maintain.
The better approach is usually to create separate but connected tables.
For the simplified pain.001.001.09 example above, that could mean tables such as:
- message_header
- payment_information
- credit_transfer_transaction
- party
- account
- remittance_information
That structure is much more useful for analytics.
But designing it manually for every ISO 20022 message type is not exactly a relaxing afternoon.
Manual coding burden
Most teams start with custom code.
Usually Python. Sometimes Java, C#, or even XSLT (rarely nowadays).
That can work for a narrow use case.
If you only need to parse one message type, one version, from one counterparty, and into one target database, custom code may be sufficient.
The trouble starts when the scope grows:
- You need custom logic for each source structure.
- You need mappings for each target schema.
- You need tests for every version.
- You need someone who understands both ISO 20022 and the target database model.
- You need maintenance every time a schema changes.
This is how a small XML parsing script turns into a long-term engineering liability.
Pro tip
If your ISO 20022 conversion logic depends on hard-coded XPath expressions scattered across Python scripts, then you, my friend, do not have a data pipeline.
You have a future incident report.
Hard-coded parsing can work for a demo. It becomes fragile when message versions, optional branches, namespaces, or counterparty-specific implementation rules change.
Scale
The final challenge is scale.
Large financial institutions do not process five ISO 20022 messages on a laptop.
They may process thousands or millions of payment, clearing, settlement, and account reporting messages per day.
At that point, manual or semi-automated conversion does not scale well.
The question is no longer:
“Can I parse this one XML file?”
The question becomes:
“Can I process ISO 20022 messages reliably across message families, schema versions, counterparties, and downstream analytics requirements?”
Which involves a series of pain points:
- Manual parsers break when ISO 20022 message versions change.
- Hard-coded XPath logic becomes difficult to test, debug, and maintain.
- Generic XML flattening can destroy parent-child relationships.
- Repeating payment blocks can easily produce cartesian products if handled badly.
- Schema drift creates rework whenever a new XSD version or counterparty variation appears.
- Missing source-to-target mappings make audits and governance more difficult.
- No lineage means analysts cannot easily trace a SQL column back to the original XML element.
- Large message volumes expose the limits of desktop scripts and traditional parsers.
- Manual conversion projects often grow from a quick parser into a long-term maintenance burden.
And this is why converting ISO 20022 XML to relational tables needs more than a generic XML parser.
That means your conversion process must:
It needs a repeatable and scalable way to read the XML and XSD, generate the relational model, and keep that model under control as schemas change.
- derive tables, columns, keys, and relationships from the ISO 20022 structure,
- preserve parent-child relationships across nested payment objects,
- generate source-to-target mappings and lineage,
- detect schema changes and support schema evolution,
- keep track of versions, metadata, and conversion rules,
- and scale beyond a few test files on a laptop.
If those capabilities are missing from your workflow, you are not really converting ISO 20022 XML to a database.
You are just moving the mess from one format into another.
Pro tip
Do you have an XML file, but no XSD? Don’t worry. I’ve got your back.
Check out my guide on how to derive an XSD from your XML in just a few steps.
Converting ISO 20022 XML to a Relational Database
So, how do you actually convert ISO 20022 XML to a relational database?
There are three main approaches:
- Load the XML into a database such as Snowflake, and query it with native XML functions.
- Write custom parsing and XML conversion code in Python, Java, or C#.
- Use a dedicated XML conversion tool that automates the process for you.
All three can work.
In short, the right choice depends on how many ISO 20022 message types you need to process, how stable your schemas are, how quickly you need the data, and whether this is a one-off project or a production pipeline.
If you want the long version, I’ll walk you through the options next.
Option 1: Load ISO 20022 XML to database and query it natively
Modern databases can store XML as semi-structured data. For example, Snowflake can store XML in columns using the VARIANT type.
That means you can load ISO 20022 XML into an SQL database first, and then query it using native XML functions, FLATTEN, and lateral joins.
This is useful if your first goal is inspection.
You can load the raw XML, explore the structure, check values, and test how your pain.001 or pacs.008 messages behave inside Snowflake.
For small XML files and simple structures, this can be enough.
With this option, you don’t need:
- A separate conversion tool.
- An external parsing script.
- A target relational model upfront.
That is the upside.
However, while most modern databases can store the XML, but it does not automatically turn a nested ISO 20022 message into a clean relational schema.
This means that you or other downstream users will need to decide at some point:
- which XML blocks become tables,
- which elements become columns,
- how repeating groups are handled,
- how parent-child relationships are preserved,
- and how schema versions are managed over time.
In practice, the conversion usually happens in one of two places: either inside the database, managed by you and your team, or further downstream, when users access the data.
In the downstream approach, the XML is first loaded into the database in its original form. The schema and mapping are then applied only when the data is queried.
These are the steps to the process:

So yes, databases like Snowflake and Databricks can ingest ISO 20022 XML.
But loading raw XML is not the same as converting ISO 20022 XML to SQL tables.
Once the XML becomes deeply nested, the database parsing and handling functions become harder to use.
And when you start handling multiple ISO 20022 message types, your SQL can quickly become difficult to read, test, and maintain.
Pro tip
Native XML support in a database is useful when you want to inspect, validate, or query XML directly.
But if your real goal is analytics-ready relational tables, you still need a proper conversion and modelling layer.
Otherwise, you are mostly moving the XML hierarchy into semi-structured or relational storage and postponing the real modelling problem.
This approach is best when:
- The XML files are small or moderately simple,
- The structure is stable (very rare),
- The number of message types is limited,
- and your team has strong SQL and XML skills.
It is less suitable when you need to process ISO 20022 XML at scale across multiple message families, versions, and counterparties.
Option 2: Convert ISO 20022 XML with custom code
The second option is custom code.
This usually means Python, but it can also mean Java or C#, depending on your stack.
With Python, for example, you might use libraries such as lxml or ElementTree to parse the ISO 20022 XML, extract the fields you care about, and write the output into relational tables.
The basic flow looks like this:
- Step 1: Analyse your source XML and XSD files.
- Step 2: Define your target Database Target Schema.
- Step 3: Manually map your source XML to the target database rows and columns.
- Step 4: Write code to load the XML into the SQL tables according to the mapping from Step 3.
- Step 5: Run the code to insert data into the database (hopefully it succeeds and you won’t need to go back to steps 2, 3, and 4).
- Step 6: Query with SQL.

Of course, for each of the six steps I gave you above, there’s a ton of manual work underneath for you and your colleagues.
Pro tip
I’ve covered manual XML to database conversion approaches in more detail in a separate guide.
If you want to compare options such as native database XML functions, custom code, flattening, and automated conversion, start here:
The manual code approach gives you flexibility and control. But it also brings challenges.
Because once you build the logic yourself, you own it.
If you write a parser for pain.001.001.09, that parser is usually tied to that message type and that version.
Then someone sends you pain.001.001.03.
Or pacs.008.001.09. Or camt.053.
Or the same message type, but with different optional branches populated.
Now the code needs to change.
Again.
For a narrow project, this is manageable. For a production ISO 20022 ingestion pipeline, costs quickly become high.
The real cost is not writing the first parser. The real cost is maintaining it.
You need to maintain mappings, tests, schema assumptions, validation rules, error handling, table definitions, and version-specific logic.
And this is before your downstream users ask for a new field that was buried three levels deeper than the original mapping covered.
Pro tip
Custom parsing code usually starts as a shortcut.
Then it becomes the system of record for your XML interpretation.
That is fine if the scope is small and stable. It is not fine if your ISO 20022 feeds change, grow, or arrive from multiple counterparties.
Custom code is best when:
- You only need one or two message types,
- The ISO 20022 XML structure is stable,
- The target relational model is simple,
- and your team is comfortable maintaining the parser long term.
It is risky when:
- You process multiple ISO 20022 message families,
- You receive multiple schema versions,
- You need proper lineage and source-to-target mapping,
- or the pipeline is business-critical.
Option 3: Convert ISO 20022 XML automatically with Flexter
The third option is automated conversion with Flexter Enterprise.
This is the approach that makes sense when ISO 20022 XML conversion is not a one-off exercise.
Instead of manually writing parsing logic, Flexter Enterprise converts ISO 20022 XML to a relational database automatically for you.
That is the key difference.
Flexter does not just extract a few fields from XML.
It analyses the schema, understands the hierarchy, and creates a relational model with tables, columns, and relationships.
For the simplified pain.001.001.09 example earlier, that means the XML hierarchy can be converted into related tables, such as:
- message_header,
- payment_information,
- credit_transfer_transaction,
- party,
- account,
- Remittance_information.
In a real production project, the generated model can be much richer, as the full ISO 20022 XSD provides far more structure than the simplified example shown in this article.
The process with Flexter looks like this:
- Step 1: Provide the ISO 20022 XML and/or XSD file.
- Step 2: Flexter reads the ISO 20022 XML or XSD schema and generates the target relational schema without manual mapping.
- Step 3: Flexter automatically generates source-to-target mappings, entity-relationship diagrams, metadata and documentation.
- Step 4: Flexter processes the XML messages and loads the data into the generated tables.
- Step 5: You can then query your data with SQL.

That is the part that matters for data teams:
- You are not writing custom XPath logic for every branch.
- You are not manually designing tables for every repeating group.
- You are not rebuilding the pipeline every time a new schema version appears.
Flexter supports ISO 20022 loading to SQL Server, Snowflake, Databricks, Oracle, PostgreSQL, BigQuery, Redshift, and other JDBC-compatible databases.
So if your target is Snowflake or Databricks, you can still use them as the analytics platform.
The difference is that you load relational tables into your target database, rather than having every analyst query deeply nested XML directly.
Pro tip
Want to see what ISO 20022 XML to database conversion looks like before building anything yourself?
Try Flexter Online: The free XML to Snowflake converter!
You can upload an XML file and see how Flexter turns the hierarchy into relational tables without writing custom parsing code.
This approach is best when:
- You need to convert ISO 20022 XML to a relational database at scale,
- You process multiple message types such as pain, pacs, and camt,
- You receive different schema versions,
- You need repeatable conversion logic,
- and you want queryable SQL tables without building a custom parser for every message.
Which approach should you choose?
I know you’re busy, so here’s the main takeaway:
- If you only want to inspect a single type of ISO 20022 XML file, native database XML support may be sufficient.
- If you have one stable message type and a strong engineering team, custom code may be acceptable.
- If you need production-ready ISO 20022 XML to database conversion across multiple message types, versions, and target databases, automation is usually the safer approach.
|
Approach |
Best for |
Main limitation |
|---|---|---|
|
Fast ingestion and inspection of raw XML. |
Still requires manual flattening and table design. | |
|
Narrow, stable use cases with full control. |
High maintenance burden as schemas and message types change. | |
|
Automated ISO 20022 XML to relational database conversion. |
It is a commercial tool and has a license fee. |
Analytics Use Cases for ISO 20022 Data in a Relational Database
If converting from ISO 20022 to a database is so challenging, why go through all this effort?
Because once ISO 20022 XML is converted into relational tables, it stops being a pile of nested financial messages and starts becoming usable data.
That is the whole point.
Surely, nobody converts ISO 20022 XML because they enjoy turning payment headers and transaction details into database tables.
You do it because you want to answer questions with SQL.
Keep reading to see when ISO 20022 XML to SQL conversion stops being optional and starts becoming necessary.

Payment analytics
The first use case is payment analytics.
Once pain.001 and pacs.008 messages are in relational tables; you can connect customer payment initiations with interbank settlement messages.
That means you can track a payment from the original instruction to the later bank-to-bank message.
For example, you can join on EndToEndId and compare timestamps:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT p.end_to_end_id, p.instruction_id, p.requested_execution_date, x.interbank_settlement_date, x.settlement_amount, x.currency FROM pain_credit_transfer_transaction p JOIN pacs_credit_transfer_transaction x ON p.end_to_end_id = x.end_to_end_id; |
Now you can detect delays, failed payments, settlement gaps, and SLA breaches.
Try doing that cleanly across raw XML files with XPath expressions. Exactly. Painful.
Fraud detection
ISO 20022 data also becomes useful for fraud and anomaly detection.
Once camt.053 bank statement data is stored in tables, you can use standard SQL aggregations and window functions to identify unusual behaviour.
For example:
- unusually high transaction volumes,
- repeated payments to the same creditor,
- sudden changes in payment corridors,
- outlier amounts by account,
- or suspicious transaction timing.
The important bit is that the data is no longer trapped inside nested XML.
You can query it, aggregate it, compare it, and feed it into downstream fraud models.
Regulatory reporting
Regulatory reporting is another obvious use case.
For example, if you need all cross-border payments over EUR 100,000 in Q1, you do not want to parse XML files one by one.
Here’s what such a query looks like:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT end_to_end_id, debtor_name, creditor_name, amount, currency, settlement_date FROM iso20022_payments WHERE amount > 100000 AND currency = 'EUR' AND settlement_date BETWEEN DATE '2026-01-01' AND DATE '2026-03-31'; |
That is the difference between reporting and suffering.
Once the data sits in relational tables, audit, reconciliation, and compliance reporting become ordinary database workloads.
Treasury analytics
Treasury teams also benefit from relational ISO 20022 data.
With camt.053 statement data in tables, you can reconcile cash positions daily, monitor balances across accounts, identify idle cash, and compare expected versus actual account movements.
That is hard to do when every account statement is still sitting as a separate XML document.
It becomes much easier when entries, balances, accounts, currencies, and transactions are queryable.
SEPA analytics
If you process SEPA direct debits, relational ISO 20022 data can also help with operational analysis.
For example, pain.008 direct debit data can be used to identify unpaid mandates, returned payments, debtor behaviour, recurring payment failures, and rejection patterns.
That kind of analysis needs relationships between mandates, debtors, accounts, payments, returns, and status messages.
In other words, it needs tables.
Pro tip
Are you interested in learning more about conversions between XML and other formats, along with the best converters for each use case?
Then check out my recent blog post: Best XML Converters by Use Case (2026 Guide)
Frequently Asked Questions (FAQ)
ISO 20022 XML is a standard format for exchanging financial messages. It is used for payments, account reporting, securities, trade services, and other financial workflows. Each message type is defined by an XSD schema.
The main ISO 20022 message families are pain, pacs, camt, sese, acmt, and fxtr. Common examples include pain.001 for payment initiation, pacs.008 for interbank credit transfers, and camt.053 for bank statements.
An ISO 20022 XSD schema defines the structure of a specific message type.
It specifies the elements, data types, required fields, repeating groups, and validation rules. For example, pain.001.001.09 is a specific version of the customer credit transfer initiation schema.
You can load ISO 20022 XML as raw XML, but that does not make it relational. To query it properly, you need to convert the nested XML into tables, columns, and relationships.
Yes. ISO 20022 XML can be converted to SQL tables using native XML functions, custom parsing code, or an automated XML conversion tool. Flexter reads the ISO 20022 XSD and automatically generates the relational schema.
SWIFT MT is an older fixed-format message standard. ISO 20022 uses structured XML and formal schemas.
It carries richer data, but it also requires proper parsing and modelling before it can be analysed in a relational database.
Yes. Platforms such as Snowflake and SQL Server can store XML. But storing XML is not the same as converting it. For analytics, ISO 20022 XML still needs to be flattened or normalised into relational tables.
ISO 20022 XML is deeply nested, versioned, and full of repeating elements (related to business structures).
A single message can contain headers, parties, accounts, transactions, agents, amounts, references, and remittance data. These need to be preserved as related tables in the target database (not flattened blindly).
It should read the ISO 20022 XML and XSD, understand the message hierarchy, generate relational tables, preserve parent-child relationships, and load the XML into SQL-ready structures.
As I’ve shown in my other post, in practice, very few tools do this properly for complex XML messages.
Flexter is a well-tested solution to help you get there. It converts ISO 20022 XML to a relational database “automagically” by generating the schema, relationships, and source-to-target mappings from the XSD without manual mapping.
Flexter supports ISO 20022 conversion to Oracle, SQL Server, PostgreSQL, and Snowflake.
It can also convert XML and JSON from different sources, including files, cloud object storage, FTP/SFTP, network drives, and relational database columns such as BLOB, CLOB, or Snowflake VARIANT data.
You can read more about the Flexter’s capabilities in our Extended FAQ Guide.
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: