Re-use algorithms for converting XML and JSON to a relational format

In our previous post Optimisation algorithms for converting XML and JSON to a relational format, we explained that Flexter ships with two optimisation algorithms. These algorithms make the life of downstream consumers of the output of Flexter easier as they simplify the relational target schema that Flexter auto-generates.
In this post we will be showing you a second optimisation called Re-use.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Re-use optimisation
XML schemas (XSDs) can contain complex types. These can be reused multiple times inside an XML document. Flexter detects this behaviour and consolidates the information of different type instances in the same relational entity. Instead of creating multiple different tables in the target schema, it creates a single table for the same types.
The advantage for the XSD developer is that they just need to define the complex type once, and they can then re-use it for different instances, e.g. the complex type of address can be used as home address, shipping address, billing address etc. If a change is made to the complex type, it is applied to all instances inside the schema.
Let’s have a look at an example. In this XSD we have defined audiotrack as a complex type.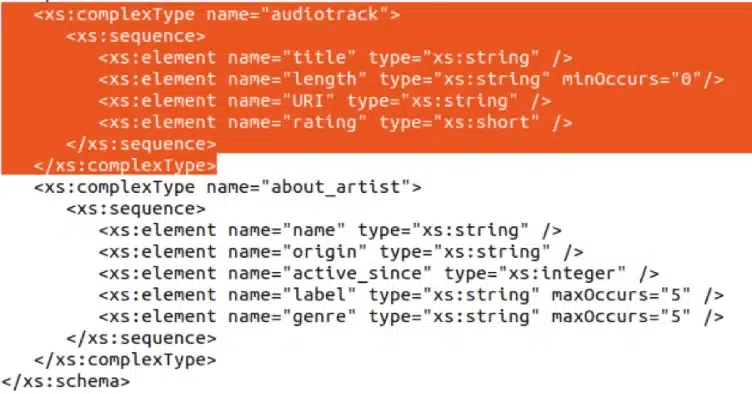
As you can see in the figure below, audiotrack is reused multiple times in album. Both as song and also as bonus_track.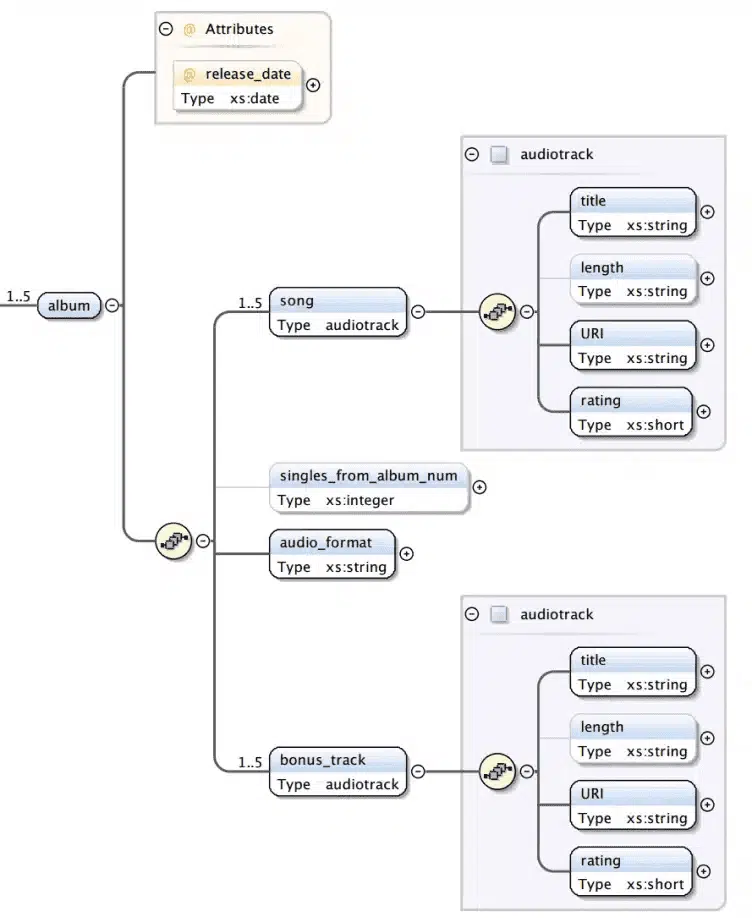
Flexter consolidates the data from multiple instances of a complex type in the same table in the target schema. The data for song and bonus_track will end up in the same target table.
Let’s go through an example.
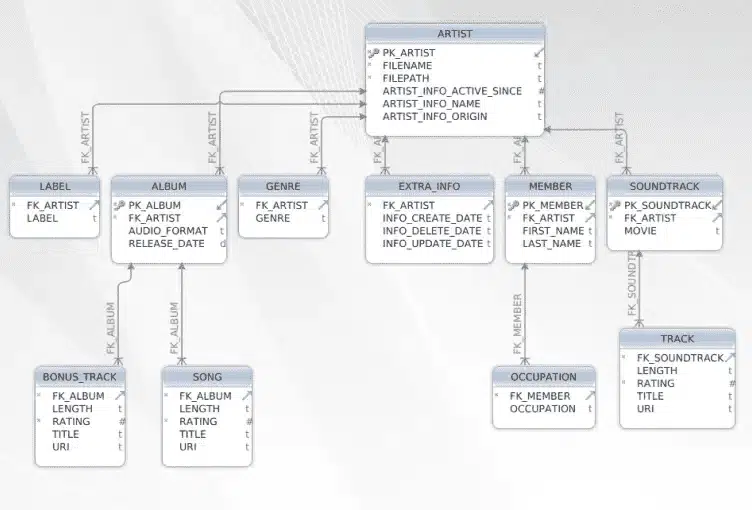
Target Schema without RE-use optimisation
Target Schema with Re-use optimisation
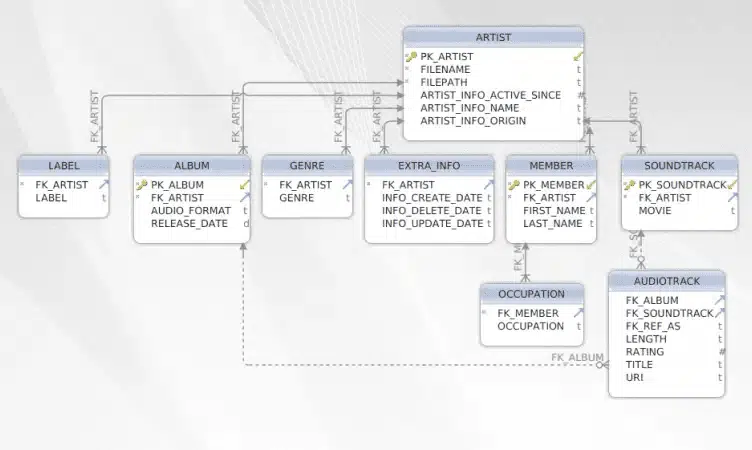
As we can see there are less tables. Tables ‘song’ , ‘bonus_track’ and ‘soundtrack’ are now grouped under one table called ‘audiotrack’.
Re-use with real world data
Let’s look at a real world data set from clincialtrials.gov. With the elevate only optimisation the target schema will result in 24 tables.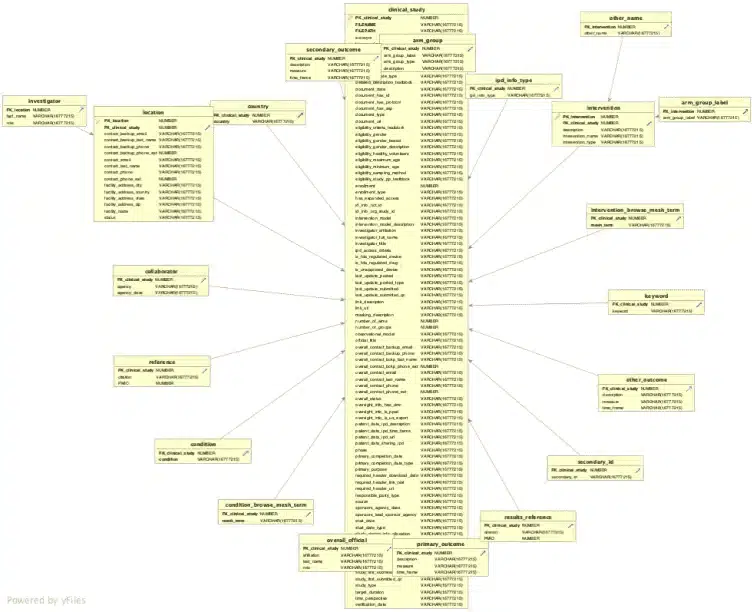
With the reuse optimisation we end up with just twelve tables in our target schema, which makes it significantly easier for downstream consumers to work with the data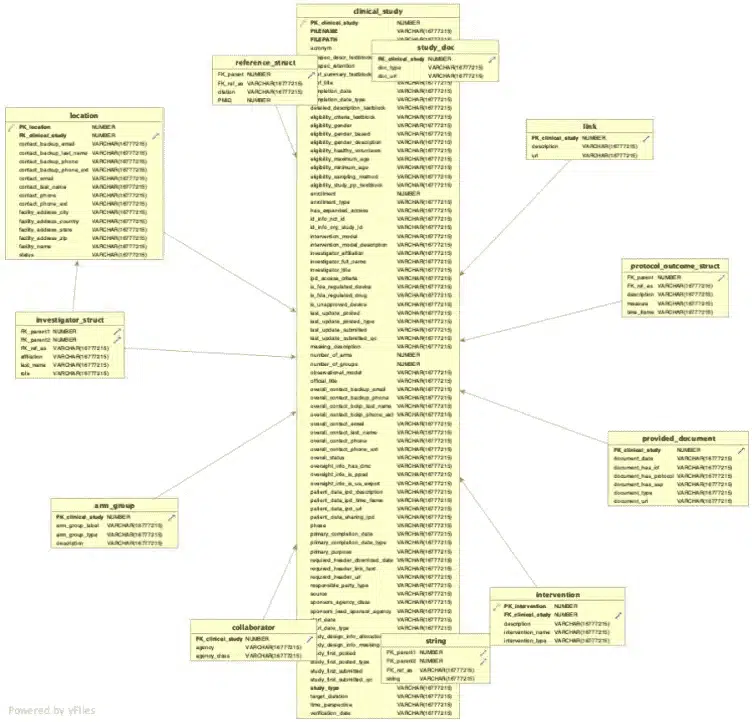
Converting XML data with Re-use
We will be using the Docker Version of Enterprise Flexter on our local Ubuntu. Converting XML/JSON data can be performed in a couple of simple steps.
Step 1 – Collecting Statistics (Information such as data type and relationships) and Data Flow (Mapping data points in the source to the data points in target schema)
Step 2 – Define Source Schema (XSD)
Step 3 – Converting data
Step 1 – Collecting statistics. Creating a data flow
We can process XML files without a Source Schema (XSD).
Instead we can use a sample of XML documents. We analyse the sample and collect statistics such as the data types or relationships inside the sample.
As part of this step we also create the data flow, which maps the source elements to the target table columns.
In the command below we will use the -g3 switch. This switch determines which optimisation we want to use while collecting statistics and creating the data flow. There are 4 levels:
– 0 : No optimized mapping
– 1 : Elevate optimisation (1 = 1)
– 2 : Reuse optimisation
– 3 : Elevate + Reuse optimisation
xml2er <INPUT PATH>
Example of output
… # schema origin: 4 logical: 2 job: 4 # statistics startup: 4107 ms parse: 6855 ms xpath stats: 436 ms doc stats: 4744 ms xpaths: 19 | map:0.0%/0 new:100.0%/19 documents: 1 | suc:100.0%/1 part:0.0%/0 fail:0.0%/0
This command collects Statistics (origin ID 4). At the same time it also creates a Data Flow (logical ID 2).
Note: Flexter collects so called Statistics from a sample of source XML documents.
If the sample of your Source Data is too big to be processed in one iteration, we can collect statistics in multiple steps. This is also useful if the structure of your XML files changes.
After we have collected statistics and created a data flow we can convert our data to a Target Connection. Target Connections are based on the URI standard. It means Flexter can access different locations and protocols defined by the path, e.g.
- file://
- ftp:// ftps://
- hdfs:// maprfs://
- jdbc:xyz://
- s3a://
Some of these protocols require you to provide a username and password. In all cases it’s possible to use the parameters or configuration files to define them. For some, you can specify the username and password directly in the URI path, e.g. for FTP.
Step 2 – Define Source Schema (XSD)
In the next step we will define Source Schema by uploading the XSD
xsd2er -k<Statistics ID (origin) -g3 INPUTPATH
Example of output
# schema origin: 7 logical: 3 job: 6 # statistics load: 1608 ms stats: 40 ms parse: 368 ms build: 121 ms write: 47 ms map: 128 ms xpaths: 16
Step 3 – Converting XML data with Re-use Optimization
In this example we will use Snowflake as our target connection. We will also use the -g3 switch.
xml2er -g3 -l3 (Data Flow ID (logical)) -o jdbc:snowflake://<account_name>.snowflakecomputing.com/?<connection_params> INPUTPATH
Example of output
17:16:24.110 INFO Finished successfully in 17701 milliseconds # schema origin: 7 logical: 4 job: 8 # statistics startup: 4107 ms load: 9416 ms parse: 6855 ms write: 2297 ms xpath stats: 436 ms doc stats: 4744 ms xpaths: 19 | map:0.0%/0 new:100.0%/19 documents: 1 | suc:100.0%/1 part:0.0%/0 fail:0.0%/0
Once the job has finished successfully, you can find the converted data in the Target Path.
Conclusion
Flexter ships with some powerful optimization algorithms that generate a simplified target schema for easy querying downstream. In this post we looked at the Re-use algorithm.
The re-use algorithm identifies the various instances of complex types in an XSD and consolidates these types in a single table in the target schema. What’s not to like about it.
Why did we create Flexter?
Flexter was born from our own frustration of converting XML and JSON documents into a data warehouse. We saw many projects fail or run over budget. Why waste weeks of converting XML/JSON and risking failure instead of focusing on delivering real value to your business users? We think that the time spent writing manual code to convert the data to It just takes too much time of converting the data
Our customers are delighted with Flexter. Hear what they say
“This will save us weeks”
“You did in one day what we could not achieve in 3 years”
And this is what Ralph Kimball, one of the fathers of data warehousing has to say about XML conversion:
“The construction of an XML parser is a project in itself – not to be attempted by the data warehouse team”. Ralph Kimball, ETL Toolkit
We provide Flexter in Enterprise Edition:
Our enterprise edition can be installed on a single node or for very large volumes of XML on a cluster of servers.
If you have any questions please refer to the Flexter FAQ section. You can also request a demo of Flexter or reach out to us directly.
Last but not least we have open sourced Paranoid, our solution to obfuscate data in XML and JSON documents
Who uses Flexter?
Companies in travel, finance, healthcare, automotive, finance, and insurance industry use Flexter.