Automatically detect bad SQL. Static and dynamic analysis of SQL code


Preventing Query Catastrophe with FlowHigh SQL Analyser
Does the following sound familiar?
As the wizard EsQuEl delved deep into the SQL code, he stumbled upon multiple instances where tables were listed in the FROM clause without any explicit JOIN conditions. This resulted in implicit cross joins, causing tables to be combined in every possible combination of rows. For sizable tables, the results were catastrophic. Queries that should’ve fetched a few rows were returning millions, leading to severe performance issues and system slowdowns. These implicit cross joins not only squandered resources but also created vast matrices of data that made no logical sense. It was a glaring testament to the dangers of overlooking SQL best practices and the profound impact such an oversight could have on the performance of a data platform.
If this sounds familiar, read on…
This blog post is a step by step guide on how you can detect and fix anti patterns like the ones our poor old friend EsQuEl ran into.
- In the first step we explain what an SQL anti pattern is.
- We then categorise anti patterns into types and degrees of severity and go through some common examples of bad SQL (another word for SQL anti pattern).
- Next we explain why you should care about SQL anti patterns and the impact on your data projects.
- We explain what SQL code analysis is and how it helps to detect bad SQL.
- We show you various options on how you can detect anti patterns, e.g. this could be a manual or fully automated process.
- Last but not least we show what approach you should take when fixing SQL anti patterns.
FlowForward.
All Things Data Engineering
Straight to Your Inbox!
What is an SQL anti pattern?
I say bad SQL. You say SQL anti pattern. Anti pattern is a commonly used term in software engineering. A pattern is a standard solution to a common problem. The term recipe has a similar meaning and you will find many cookbooks across all programming languages full of recipes to solve common problems. While design patterns describe the best practices to solve a problem anti patterns do the opposite. They are the worst practices that should be avoided at all costs.
Here are two examples of some common anti patterns in software development:
- Spaghetti Code: This occurs when code and control structures are convoluted and it becomes difficult to understand the program flow. It makes code hard to maintain and understand.
- God Object: A God Object is an object in object-oriented programming that knows too much or does too much. A similar concept in data modelling is a God Table. It is an informal term in database design that refers to a table which contains a wide variety of data, mixing concerns and responsibilities that would normally be separated into different tables. Such a table tries to capture too much information, often leading to issues with normalization, scalability, and maintainability.
Like any other programming language SQL also has common design patterns and anti patterns. An SQL anti pattern is an implementation of SQL code that solves a problem but does so at significant costs or with huge side effects such as bad performance or poor readability.
SQL Cookbook
is a good book to get started with SQL recipes. An oldie but goldie.
What type of SQL anti patterns exist?
Different SQL anti patterns exist across databases. We have databases for OLTP, distributed databases that scale out, databases that scale up, OLAP databases, different SQL dialects etc. One size does not fit all. However, there is still significant overlap. An unintended cross join is bad across all databases. Many SQL anti patterns are applicable across most SQL databases. In particular SQL anti patterns that deal with the SQL code itself rather than the physical database design (DDL, DML, indexes, data layout etc. etc.).
There are SQL anti patterns that address common issues around physical data model design, e.g. overuse or underuse of indexes. Other examples that fall into this category are normalisation versus denormalisation, use of materialised views to speed up queries etc. While important we will not look into these anti patterns in this blog post. This will have to wait for another time.
In this article we focus on the SQL code itself to identify anti patterns. This means we look at the way the SQL code is structured to detect issues.
We can group SQL anti patterns into three categories.
- SQL anti patterns that affect performance. Improving performance will directly decrease Snowflake costs. Fixing SQL performance issues is often referred to as SQL tuning.
- SQL anti patterns that impact readability. These anti-patterns impact productivity of data engineers and SQL developers. They have an indirect impact that is hard to measure.
- SQL anti patterns that may lead to incorrect or unexpected results. This is another indirect impact that may lead to bad decisions. It is hard to measure and quantify.
Some SQL anti patterns fall into more than one category, e.g. an anti pattern may affect both performance and readability or it may affect performance and the correctness of the result.
Sometimes fixing one type of anti pattern can only be achieved at the expense of introducing a different one, e.g. many people find it hard to read correlated subqueries such as when using WHERE EXISTS etc. However, in some databases WHERE EXISTS gives better performance than other options. In these scenarios you need to prioritise your preferences. Sometimes you need to override your default approach.
Why should you care about SQL anti patterns?
SQL anti patterns can have a direct impact on your bottom line. They can lead to increased compute costs by hampering performance directly, or they can ramp up costs in the form of overhead such as maintenance, readability, and correctness. At best, bad SQL will increase your compute costs to execute inefficient SQL scripts. At worst, it might result in outputs with errors, leading to bad decisions. Whether it’s a direct cost or an indirect one, the result is the same.
Consider this scenario: an unnoticed flawed SQL CROSS JOIN inadvertently exaggerates the monthly sales data in a management report. Consequently, the report suggests a rise in sales when they’re actually declining, leading to inaction.
Pay per use data platforms penalise poor practices, especially bad SQL code. Errors come with tangible consequences, while efficient SQL practices can translate into savings on your computing expenses.
The following quote comes to my mind:
“Pain is your best teacher. It tells you something is wrong and demands a change.” Maxime Lagacé
What are some common examples of SQL anti patterns?
There are dozens of SQL anti patterns.
In this blog post I will give you an example of an SQL anti pattern for each of the categories we identified earlier on.
Performance SQL anti pattern: SELECT *
Let’s take a look at one of the most common performance anti patterns. Use of SELECT *.
Whenever a developer uses SELECT *, they commonly pick more columns than they need.
Without any good reason, the database must free up system resources to select the extra columns. The use of this anti-pattern could cause performance problems, reduce concurrency, and increase costs.
- The anti pattern is particularly bad when used on columnar databases where the database only reads the columns specified in your SQL query. Using SELECT * negates this advantage. The same is true for row storage tables with indexes as SELECT * excludes index only scans.
- High deserialisation cost. Deserialisation converts raw bytes into data types. The Client also needs to deserialise the bytes it receives from the database. So you get hit twice
- Network cost of sending data across the network for no good reason.
- Data is cached on compute nodes but not needed. As a side effect it evicts data that is actually needed.
- The issue is worse for very wide tables with a lot of columns of non numeric data types in particular VARIANT or GEOGRAPHY
- Running SELECT * is expensive. Literally. Some databases such as Google BigQuery or AWS Athena, charge customers according to the volume of data accessed. It can cost you hundreds of dollars to run a query across a TB-sized table when we only need four or five.
Apart from posing a performance issue it can also affect readability or correctness, e.g. in ETL processes where mappings are done implicitly.
- When columns are renamed or dropped, downstream processes may break in your data engineering and BI workloads
Unfortunately, this anti pattern is quite common and hard to get rid of. Here are some suggestions on how to mitigate it.
- Monitor usage of the anti pattern, e.g. by scanning the query history using FlowHigh. Pay attention to very wide tables and large tables (data size).
- Snowflake has an SQL extension named EXCLUDE to exclude columns from the SELECT list. This is useful to exclude some expensive columns such as VARIANT or GEOGRAPHY and minimise the impact of using SELECT *.
- Another recommendation is to use an IDE with an autocomplete feature, e.g. Snowflake Snowsight.
- Use the LIMIT clause (without ORDER BY) in Snowflake to only return a small subset of the data, e.g. for some preliminary data exploration.
Legitimate use of pattern
As always there are exceptions to the rule. Here are some legitimate uses of SELECT *
Temporary Analysis: For one-time, quick analyses where a complete view of the data is necessary, SELECT * can be useful. It’s beneficial when the primary goal is to get a snapshot of the data without concern for performance or long-term implications. Ideally it should be used together with the LIMIT or TOP clause. LIMIT and TOP are database dependent. LIMIT and TOP may not improve performance for all queries and databases, e.g. if your result needs to be deterministic it will slow things down or if your query is very complex. In the context of temp analysis you typically run simple non-deterministic queries against a simple query and that should improve performance by an order of magnitude
Full Data Extraction: In situations where the intention is genuinely to extract or backup the entire table, SELECT * is not only legitimate but also the most direct method to achieve this.
Readability anti pattern: ANSI-89 join syntax
Probably the most common SQL anti pattern that affects readability and maintainability is the ANSI-89 JOIN syntax. Instead of using the INNER, LEFT, RIGHT, CROSS Join syntax developers join tables in the WHERE clause and use cryptic symbols such as (+) to specify the JOIN type.
Here is an example.
|
1 2 3 4 5 6 |
SELECT sc.customerid ,sc.customername ,sb.buyinggroupname FROM sales_customers sc ,sales_buyinggroups sb WHERE sc.buyinggroupid(+)=sb.buyinggroupid |
Instead you should use the ANSI join syntax:
|
1 2 3 4 5 6 7 |
SELECT sc.customerid ,sc.customername ,sb.buyinggroupname FROM sales_customers sc LEFT OUTER JOIN sales_buyinggroups sb ON sc.buyinggroupid=sb.buyinggroupid |
Correctness anti pattern: handling NULLs
Many anti patterns that fall into the category of correctness are caused by poor understanding of Three Valued Logic (3VL).
| What is 3VL? In classical logic, or two-valued logic (2VL), a statement can only be true or false. This works well for many situations, but there are circumstances, particularly in database systems, where it’s possible that the truth of a statement is unknown. This is especially the case when dealing with NULL values in databases. So in three-valued logic, a statement can be true, false, or unknown. The value “unknown” typically comes up in the evaluation of a statement containing a NULL (which is a special marker used in Structured Query Language (SQL) to indicate that a data value does not exist in the database). For example, if we have a NULL value in a database table for a person’s age, and we want to evaluate the statement “This person is older than 20”, we can’t say if this is true or false, because we don’t know the person’s age. So in the context of 3VL, the result would be “unknown”. |
Let’s go through an example.
Using arithmetic and string operations on NULLable columns could have side effects that you didn’t plan for.
Table with sample data:
|
customer_id |
first_name |
middle_name |
last_name |
age |
|---|---|---|---|---|
|
1 |
hans |
peter |
wurst |
NULL |
|
2 |
edgar |
NULL |
uelzenguelz |
18 |
We concatenate the first_name, middle_name and last_name to illustrate the anti pattern for string operations.
SQL query
|
1 2 3 4 5 |
SELECT customer_id ,CONCAT(first_name ,middle_name ,last_name) AS full_name FROM customer |
As the middle_name is unknown for customer_id 2 the concat string operation also results in an unknown value (NULL). We might have expected “edgar uelzenguelz” as the full name for that customer_id
Result
|
customer_id |
full_name |
|---|---|
|
1 |
hans peter wurst |
|
2 |
NULL |
Solution
We recommend using a defensive programming style when writing SQL queries. As a rule, you should always assume any column can be NULL at any point. It’s a good idea to provide a default value for that column. This way you make sure that even if your data becomes NULL the query will work.
For the string operation we can use the COALESCE function to achieve our objective
|
1 2 3 4 5 6 7 8 |
SELECT customer_id ,CONCAT(first_name ,' ' ,COALESCE(middle_name ,'') ,' ' ,last_name) AS full_name FROM customer |
If you want to be very careful, you can use COALESCE for all of the columns in the string concatenation, not just the ones that can be NULL. This will make sure that your code will still work even if the NULLability of a column changes.
|
1 2 3 4 5 6 7 8 |
SELECT customer_id ,CONCAT(first_name ,' ' ,COALESCE(middle_name ,'') ,' ' ,last_name) AS full_name FROM customer |
Legitimate case
The columns used in the expression are NOT NULLable.
What is SQL code analysis?
The purpose of SQL code analysis is to detect bad SQL and SQL anti patterns
Two different types of SQL code analysis exist. Static and dynamic analysis
Static SQL code analysis
Static SQL code analysis refers to the process of inspecting and analysing SQL code without actually executing it. The primary aim is to identify potential issues, vulnerabilities, and areas for improvement in the SQL code. This ensures that database interactions are efficient, secure, and maintainable.
The SQL code goes through a life cycle where it is deployed from lower to higher environments, e.g. from Development to Testing to Production. In this scenario the anti pattern can be detected before going live. A CD / CI test pipeline that runs static SQL code analysis before a deployment into Production can identify these issues. If you don’t have automation in place it could be done as a manual code review checklist by peers. We will go through some examples in a minute.
Here are some examples of static SQL code analysis and the types of checks you can perform.
- Code Quality: Identifying areas in the SQL code that may not adhere to best practices. This can include checking for inefficient queries, improper use of functions, or other elements that can affect performance.
- Consistency Checks: Ensuring that the SQL code adheres to a particular coding standard or style guide. This helps maintain consistency across the codebase.
- Dependency Analysis: Understanding and visualising dependencies between different database objects like tables, views, stored procedures, and more.
- Dead Code Detection: Identifying unused or obsolete SQL code, which can be removed to streamline the codebase.
- Syntax Verification: Checking SQL code for syntax errors, even before it gets executed.
- Data Flow Analysis: Reviewing the flow of data through SQL statements and procedures to ensure that data is correctly accessed and modified.
- Schema Change Impact: Analysing how changes to one part of the schema might impact other parts of the database or application.
Dynamic SQL code analysis
Dynamic SQL code analysis refers to the evaluation and analysis of SQL code while it is being executed or run, in contrast to static analysis which examines code without executing it. Dynamic analysis often focuses on understanding the behaviour of SQL queries in a production environment, under real or simulated conditions.
Data analysts and data scientists run ad hoc queries as part of data exploration. These are typically not part of a data pipeline. The code does not go through a DevOps process but is often run directly on the production environment. For this scenario you need to continuously monitor the history of SQL statements that are run. For very bad anti patterns such as implicit cross joins or anti patterns that return unintended results you should set up monitoring and notifications. This can be very beneficial as you will see in a moment when we go through some examples.
Analysing your SQL code for anti patterns is a recommended best practice. It is not bulletproof as code analysis is not always able to capture the intent of the programmer or has to work with partial information. This can result in false positives or false negatives.
How does SQL code analysis detect SQL anti patterns
Successful SQL code analysis is built on top of an SQL parser, e.g. the FlowHigh SQL parser. You need to be able to have a full understanding of the SQL code to detect anti patterns. Sometimes you can use a brute force approach, e.g. use a regular expression to detect SELECT * but this is not scalable and does not work for more complex anti patterns.
We have created the FlowHigh SQL Analyser module for static and dynamic analysis of SQL code. FlowHigh also includes a module to visualise complex and deeply nested SQL queries.
FlowHigh can be accessed through a web based UI, an SDK for programmatic access, and we have also created a Snowflake native app.
FlowHigh detects 30+ SQL anti patterns by inspecting and analysing SQL code in isolation.
Each anti pattern is categorised by type (performance, correctness, readability) and severity of the issue.
FlowHigh UI
You can use the FlowHigh UI to manually check individual statements for bad SQL. This is useful as part of a code review checklist. A peer reviews code before it is promoted to a higher environment. It is static code analysis before deploying into test or production environments.
Let’s go through an example of a query that contains 3 different antipatterns.
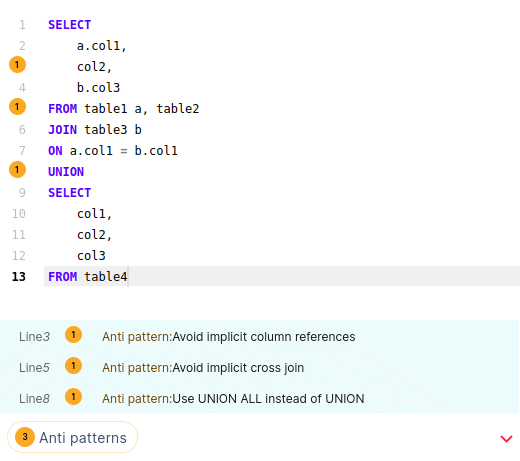
As we can see FlowHigh detects antipatterns and marks each line. Also at the bottom of the code editor we can see a list of all of the anti patterns inside the query. When you click on the yellow dot a description of the anti pattern pops up. It includes information such as the type, severity, explains the issue at hand, provides a recommendation and also lists scenarios where the pattern might be legitimate.
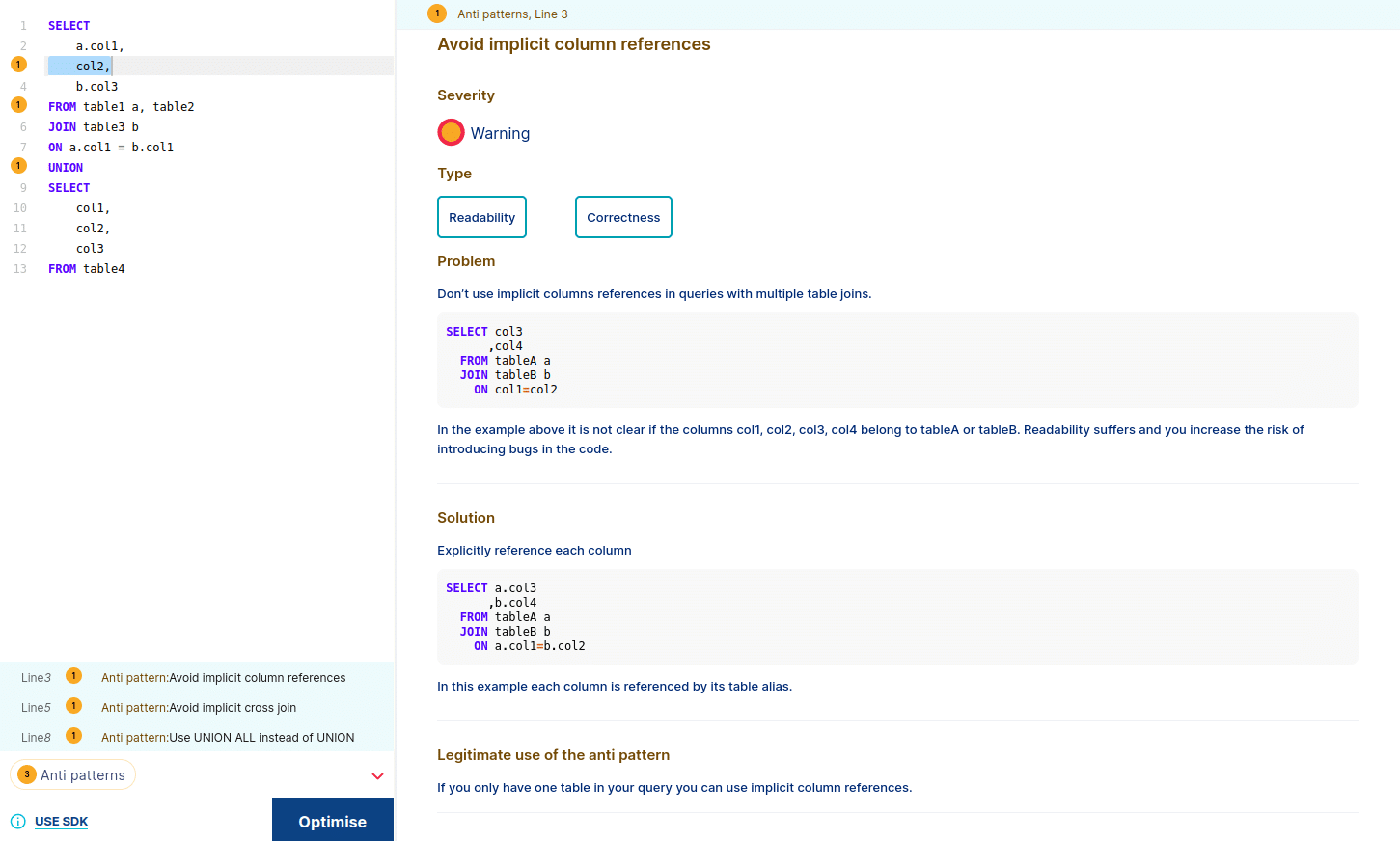
Implicit column reference anti pattern
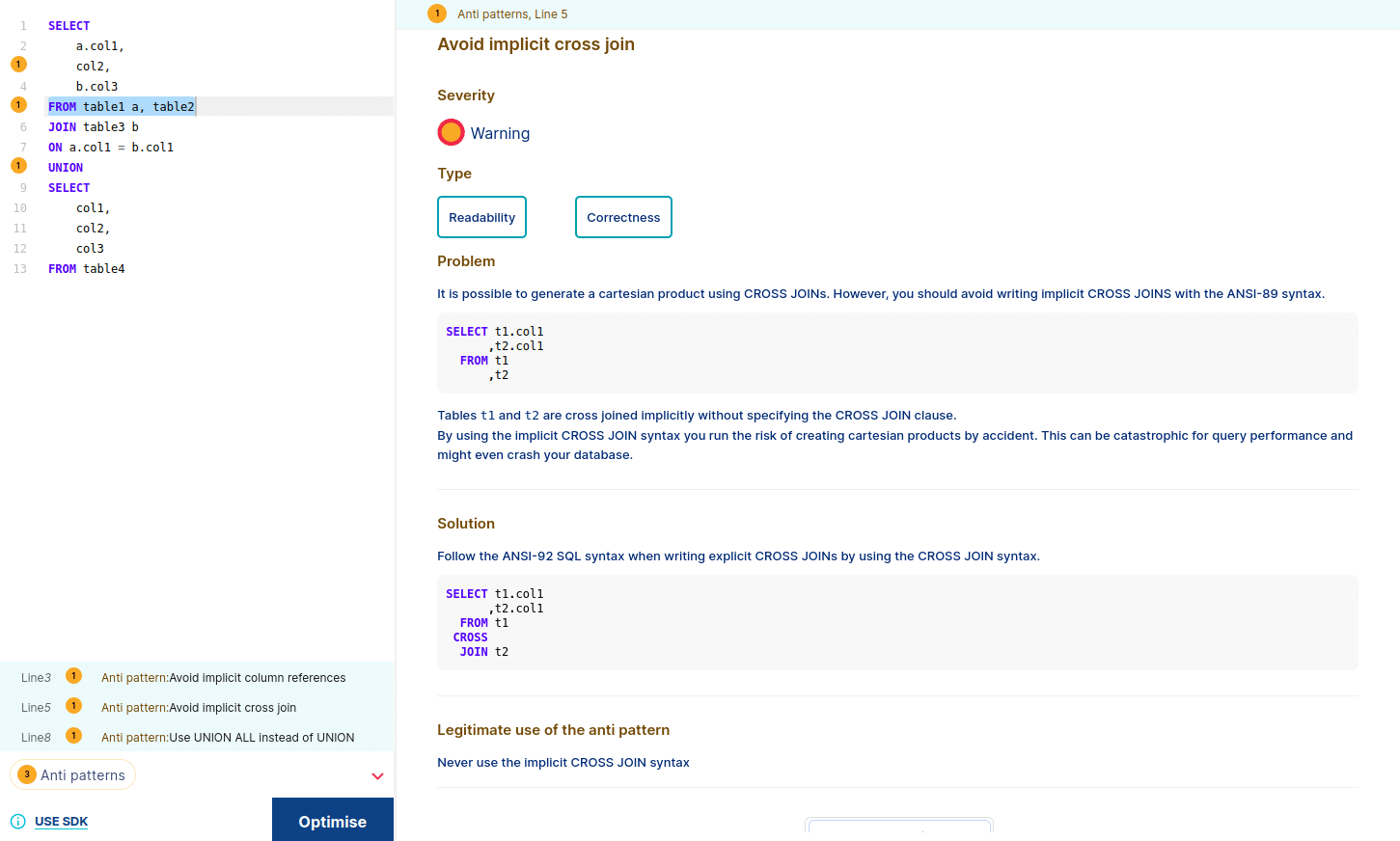
Implicit cross join anti pattern
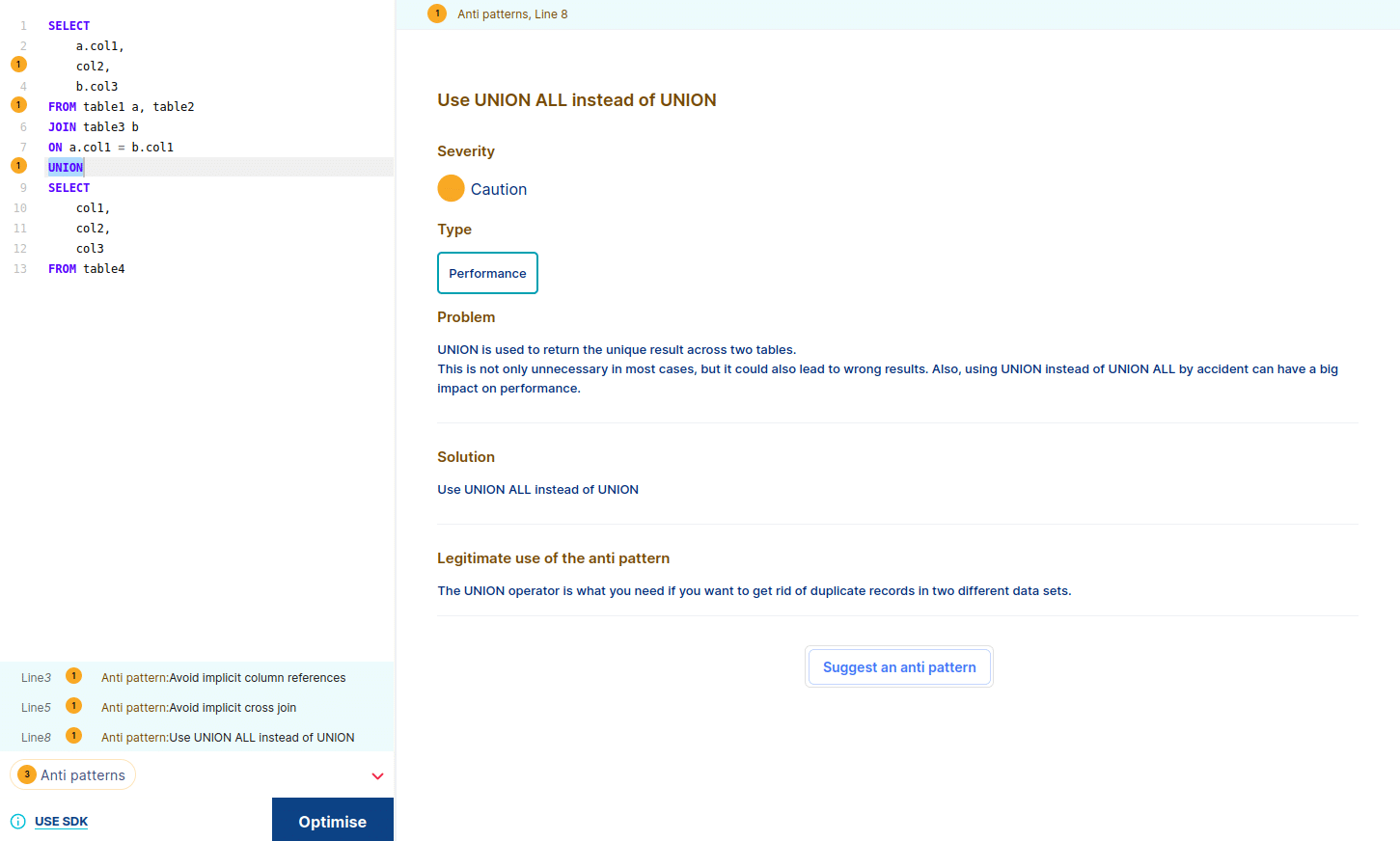
UNION instead of UNION ALL
As we can see, when we select one antipattern, FH shows us the explanation and solution. It also highlights the part of the query that is causing the antipattern.
Register to gain access to the FlowHigh SDK.
FlowHigh SDK
FlowHigh SDK for static SQL code analysis
Apart from the UI we also ship an SDK to automate the detection of bad SQL. This can be used as part of a CI / CD test pipeline for static code analysis.
With the FlowHigh SDK you can use a programmatic approach to automate SQL anti pattern detection. These are the steps to go through.
- Connect to source control
- Get SQL from source control
- Analyse SQL with FlowHigh SDK
- Store results and anti patterns
- Analyse, priorities and fix SQL issues
FlowHigh SDK for dynamic SQL code analysis
You can also use the FlowHigh SDK for dynamic SQL code analysis.
Using the SDK you can continuously scan the query history of your database for anti patterns and alert or notify an operator if bad SQL is detected.
We have written up blog posts elsewhere that go through examples of SQL parsing on different technologies:
- Parsing SQL and automatically detecting anti patterns on Snowflake
- Parsing SQL and automatically detecting anti patterns on Oracle
- Parsing SQL and automatically detecting anti patterns on MS SQL Server
We have also written a comprehensive post that covers all of the use cases for an SQL parser.
Register to gain access to the FlowHigh SDK.
Snowflake native app
For Snowflake we have created a native app. Currently, it is available as a private listing and not yet available on the Snowflake marketplace. You can request access for free. We will then share the FlowHigh native app directly with your account. Snowflake native apps are in public preview. As of the date of writing (August 2023) native apps are only available for Snowflake AWS accounts. If you are on Azure or GCP you can use the FlowHigh SDK
Register for FlowHigh to get access to the Snowflake native app
How can you fix SQL anti patterns?
What is SQL optimisation?
The remaining piece in the puzzle is to figure out how to fix bad SQL.
This process is known as SQL optimisation. It aims to address and fix SQL anti patterns. SQL optimisation should aim to address all SQL anti patterns including those affecting readability and most importantly correctness.
SQL optimisation is often reactive in nature. It looks at the problem only post the fact. We already have a mess that we need to tidy up. You can compare it to health issues such as high cholesterol. You can address the issue once you have a diagnosis. A much better approach however would be to eliminate the factors that lead to high cholesterol in the first place, e.g. a healthy diet, exercise etc. The same applies to SQL. It is much better to prevent problems from happening in the first place.
Here are some measures you can take to be proactive and to prevent SQL anti patterns from happening:
- Proper planning, e.g. understanding the requirements such as the number of users, the types of queries, the latency, data volumes etc.
- Defining SLAs, performance KPIs, and setting correct expectations
- Good design: You need to select the appropriate design for the requirement and problem you try to solve, e.g. denormailsation and columnar storage for OLAP workloads and normalisation and row storage for OLTP workloads
- People
- Training and foundational knowledge: Proper planning and good design skills are dependent on a good foundation knowledge of SQL, databases, and their design patterns.
- Use FlowHigh for static and dynamic SQL code analysis as part of CD / CI and as part of continuous monitoring.
Let’s return to our health analogy. Rather than addressing the root causes of high cholesterol you can use a class of drugs called statins. This also lowers your cholesterol. You can do the same in SQL optimisation. Instead of fixing the root cause of the issue you can throw money at the problem in the form of compute and hardware. Data engineering time to fix a problem may be more expensive than compute costs.
Snowflake gives you nice and simple options. You can easily increase the size of your virtual warehouse and even run virtual warehouses concurrently. Typically but not always this also improves performance. You need to know and understand the scenarios when additional compute power fixes the problem and when it doesn’t. This brings me back to one of the main points of this blog post: you need to have an understanding on how databases work internally to make the best decisions.
Using additional compute power may be a good strategy to get over a performance issue initially. You can then sort it out properly without the extra pressure and stress. Sometimes it even makes sense not to fix the issue at all. Engineering time may be more expensive than Snowflake compute costs.
Which SQL should be optimised and fixed first?
Any good consultant will answer this question with: ‘It depends’. It depends on the impact to your business. Impact is highly selective. What one business considers a significant impact is not relevant for another organisation.
It is also important to understand that SQL code analysis is not aware of the intent of the engineer. As we have seen things are not black and white and there are legitimate reasons for using what can be considered an anti pattern
I have tried to put together some rule of thumb guidelines. The ten commandments of prioritising SQL optimisation if you like:
- There are direct costs and indirect costs resulting from bad SQL. Indirect costs are typically less visible than direct costs but it can be more important to fix bad SQL code that results in indirect costs. An example of an indirect cost is SQL that is hard to read and maintain. This has an impact on productivity of data engineers.
- When it comes to fixing SQL anti patterns and optimising your SQL code you are making a trade off. There is always something that is not perfect. As the old saying goes: Perfection is the enemy of good. There is value in recognizing when something is good enough and avoiding the trap of unattainable perfection. SQL optimisation comes at a cost, the cost of engineering time. You should only optimise where the benefits significantly outweigh the costs.
- SQL that produces incorrect or unexpected results should be high on your priority list. This type of SQL may lead to bad business decisions. Handling of NULLs is a common source of bad SQL and may lead to incorrect data.
- SQL that performs badly is a source of both direct and indirect costs. The direct cost is directly visible on your Snowflake bill. The longer it takes for your SQL to run the more compute time you use and the more dollars you need to cough up. An indirect cost may be increased wait times for business users. This has an impact on productivity.
- There are two types of badly performing SQL that require your attention. These are typically badly written queries that have very long execution times ranging from minutes to even hours. However, do not forget about short running queries that are executed thousands or even millions of times. These might be more problematic than the badly performing ETL job that is run only once. So when identifying long running queries you need to check the cumulative execution time. The following formula applies: number of executions * elapsed query time.
- Not all badly performing SQL should be fixed. The pareto rule is a good guide for deciding which SQL to fix. 80% of problems are caused by 20% of queries. Based on the formula from the previous bullet point, create a list and take the top 20% of badly performing SQL. Ask a data engineer to go through the list to get an estimate to fix the issue. You can then make an informed decision if it is worthwhile to fix a query or not.
- The low hanging fruit on the bad SQL tree are those that have a big negative business impact but are quick to fix.
- Fixing one SQL anti pattern may introduce another one, e.g. using a correlated query such as WHERE EXISTS on some databases is more performant than WHERE IN but less readable.
- Remember: SQL optimisation is reactive. You should prevent bad SQL showing up in your Snowflake query history in the first place. Good design and training will help you get there.
- Last but not least some people think that optimising bad SQL is a challenge and fun (including the author). So go on. Knock yourself out. There is plenty of bad SQL to go around.
Once you have identified the bad SQL and determined if you should fix it you need to tackle the last hurdle. Turning bad SQL into good SQL. This requires a mix of skills:
- Very good understanding of SQL. Most importantly expertise in window functions and the ability to think in sets.
- To be successful with SQL you also need to know databases and related concepts inside out. If you want to master SQL you also need to know this:
- Indexes, cluster keys: Using these can vastly speed up retrieval times.
- Join algorithms (hash joins, sort merge joins etc.): Different algorithms are used to join tables, and the best one often depends on the data distribution and table size.
- Sort operations and sort algorithms: Understand how sorting works in databases, the algorithms behind them, and their time complexities.
- Concurrency: How databases handle multiple users and operations simultaneously without causing data conflicts.
- Parallel execution: This allows for tasks to be performed concurrently, leading to quicker execution times on multi-core processors.
- Memory structures: Understand the different types of memory (e.g., buffer cache for caching data) and their roles in a database environment.
- CPU cache levels: Knowledge of the hierarchy of CPU caching can help in optimising database performance.
- Database storage, e.g. row versus columnar: Different storage models have advantages depending on the use-case, like OLAP vs OLTP. On Snowfalke you need to understand how micropartitions work.
- Scaling up versus scaling out: Scaling up refers to adding resources to a single node, while scaling out involves adding more nodes and creating a cluster.
- SMP vs MPP: Single-Machine Processing (SMP) involves a single machine handling tasks, whereas Massively Parallel Processing (MPP) divides tasks across many machines.
- Explain plans: A tool to understand the strategy chosen by the database optimizer to execute a query, helping in performance tuning.
- Cost Based Optimisation: The database’s method of optimizing queries based on the cost (resources/time) associated with different strategies.
- Big O notation: A way to describe the performance or complexity of an algorithm in terms of its worst-case or average-case behaviour.
- Normalisation and denormalization: Normalisation is the process of minimising redundancy and dependency by organising data, while denormalization is the addition of redundant data to improve read performance.
- Data partitioning: The technique of dividing a large table into smaller, more manageable pieces, yet still being treated as a single table.
Contact us if you need a Sonra SQL expert to fix your bad SQL and SQL anti patterns.
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: