SQL Parser deep dive. Use cases, features, practical examples, and tools for SQL parsing

In this blog post we will cover all aspects of SQL parsing.
First we will explain what we mean by SQL parsing and look at the inner workings and mechanics of breaking down SQL code into its components.
We will then explain the differences of different types of SQL parsers, e.g. what is the difference between an online SQL parser and an SQL parser library.
The main part of this blog post will be about the use cases and benefits of SQL parsing. You will be surprised about the huge number of use cases that are underpinned by an SQL parser.
We will finish up the blog post with some practical examples of SQL parsing. We will showcase the capabilities of Sonra’s SQL parser, FlowHigh.
Here is a brief table of contents of what we will discuss with direct links to the relevant sections.
FlowForward.
All Things Data Engineering
Straight to Your Inbox!
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
What is an SQL Parser?
You are probably surprised to learn that SQL parsing underpins many data governance and data engineering use cases ranging from data lineage to performance tuning, data protection, productivity and many more.
An SQL parser analyses the structure of an SQL query. It takes the SQL statement and decomposes it into its elements, e.g. tables, columns, joins, filters, subqueries etc.
Once you have deconstructed your SQL queries you can apply analytics on SQL usage inside your organisation. Analysis can answer a lot of useful questions
- Which tables are frequently used in SQL queries?
- What are common join columns?
- What columns are used in filters?
- Which tables are frequently queried together?
- What columns are used to aggregate data?
These are just some of the questions you can answer with an SQL parser. We will discuss the benefits and use cases of SQL parsing in detail in a minute.
Let me walk you through a simple example.
SELECT cust.customer_id
,SUM(ord.order_amount) AS order_amt
FROM orders ord
JOIN customers cust
ON (ord.customer_id=cust.customer_id)
GROUP BYCust.customer_id
ORDER BYOrd.order_amount DESC
Running this query through our SQL Parser FlowHigh produces the following visualisation
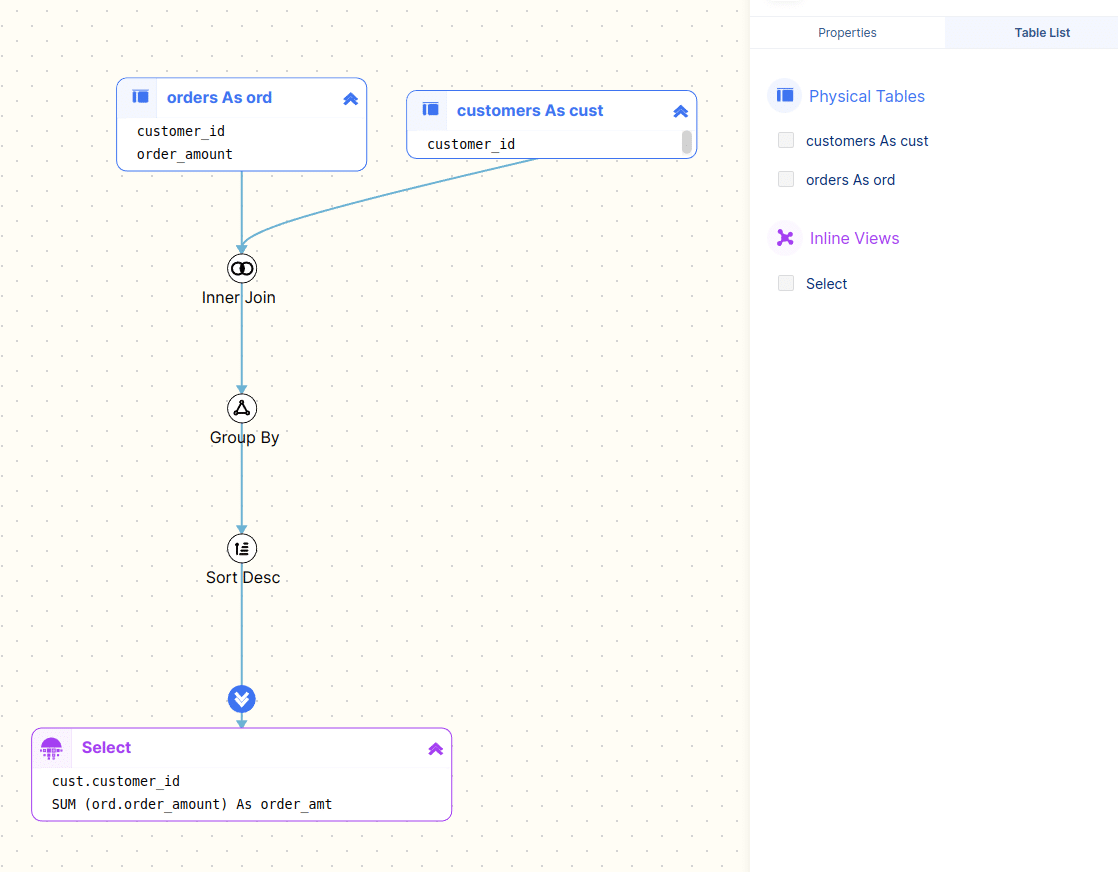
Looking at the parsed query tree that FlowHigh generated we can see the various elements of the SQL query
- The input columns: customer_id, order_amount
- The output columns: customer_id, order_amt
- The input tables: orders, customers
- The join columns: customer_id (customers) and customer_id (orders)
- The aggregation column: customer_id
- The sort column: order_amount
Instead of a visual representation of the parsed query we can also get a breakdown of each component in the SQL tree.
Using FlowHigh we can also get this information as a JSON or XML document.
Let’s get the XML document for the previous query

We will see later on in this blog post that we can meet a variety of different business requirements and use cases with all of this information.
How does an SQL Parser work?
Let’s get a bit more technical and look at how an SQL Parser works under the hood. You can skip this section if your main interest is in the use cases and business benefits of using an SQL Parser.
SQL parsing is similar to parsing any other programming language. The parser deconstructs the SQL query based on the SQL syntax, identifies each of the query components, and then creates an Abstract Syntax Tree (AST) in a hierarchical format.
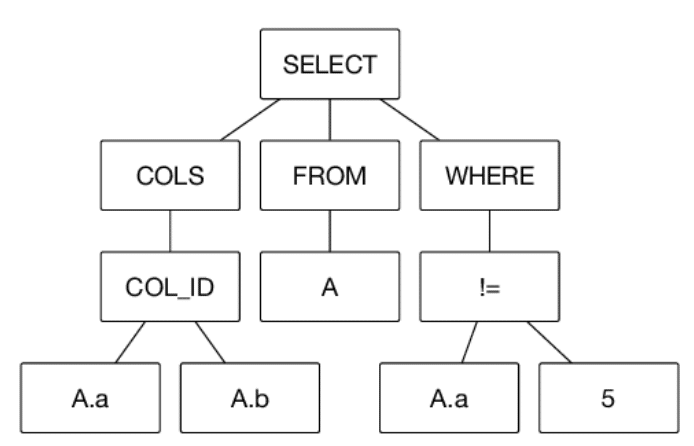
A simple example of an Abstract Syntax Tree for an SQL query
Getting from SQL query to AST is a three step process
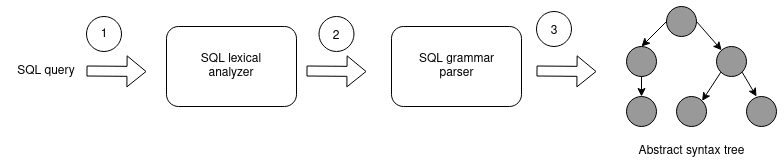
The first step is lexical analysis (also known as tokenization). The lexer attaches meaning to a set of characters and strings in our SQL query. These strings with identified meaning are referred to as tokens.
An example of SQL tokens
| Token name | Sample token values |
|---|---|
| keyword | SELECT, INSERT |
| separator | ( , ) ; |
| operator | < = != <> |
| literal | ‘order’ |
| comment | /* some comment about code */ |
Lexical analysis is relatively simple. It is typically followed by a parsing stage. Parsing is also known as syntactic analysis.
The parsing step takes the tokens as input and builds an Abstract Syntax Tree. It checks that the tokens form an allowable expression by recursively iterating and looping over them.
Types of SQL parsers
Online SQL parser vs SQL parsing library
An online SQL parser follows the Software as a Service (SaaS) model. Another word for online SQL parser is SaaS SQL parser. You don’t need to download and install any software locally on your laptop or PC. You just sign up for the service online and off you go. You access the software through your web browser or programmatically through an API or an SDK.
Traditionally SQL parsers had to be installed locally or on premise. The IT department typically provides a server, instals and maintains the SQL parser software or library. An online SQL parser on the other hand follows the Software as a Service (SaaS) model. It is hosted and managed by the vendor of the SaaS SQL parser.
Here are some of the advantages of an online SQL parser over the traditional way of parsing SQL.
- Accessibility: A SaaS SQL parser can be used from anywhere with an internet link, while locally installed software can only be used on the device where it was installed. This means that users can use SaaS apps on any device without having to run the software, making it easier and more flexible.
- Scalability: A SaaS SQL parser can be easily scaled up or down.
- Maintenance and updates: SaaS software companies take care of maintenance and updates, so users don’t have to spend time and money keeping their software up-to-date and in good shape.
At Sonra we have created FlowHigh a free online SQL parser to bring you the benefits of SQL parsing.
Related concepts to SQL parsing
You will come across similar or related terms and concepts for an SQL parser.
- SQL statement parser or SQL command parser are often used interchangeably with SQL parser. However, the emphasis of SQL statement or command parser is often on an individual SQL statement rather than entire scripts or stored procedures.
- SQL Parsing Tool and SQL Parsing Library refer to similar concepts as SQL parser. An SQL parsing library is a collection of pre-built functions, classes, or modules that can be integrated into other software applications. It provides a programmatic interface for developers to include SQL parsing functionality in their projects.
- SQL parser API is very similar to the terms online SQL parser or SaaS SQL parser. An SQL parser API is an Application Programming Interface (API) that offers access to SQL parsing functionality via a web service or a remote procedure call. This enables developers to use SQL parsing features in their applications without directly integrating a parsing library. Sonra’s FlowHigh is an online SQL parser.
- SQL Syntax Checker, SQL Formatter, SQL Linter, SQL Code Validator, SQL Optimization Tool, SQL Query Analyzer are useful applications that are built on top of an SQL parser. The SQL parser is the foundation for these tools.
Commercial versus open source SQL parsers
Various open source SQL Parsers exist, e.g. SQL Parse is an implementation of an SQL parser in Python.
sqlparse in Python – Installation and Basic Usage
If you want to try SQL parsing in Python without setting up a database, a server, or an enterprise platform, sqlparse is the quickest place to start.
It is lightweight, easy to install, and useful for inspecting, splitting, or formatting SQL statements.
That does not mean it will understand your entire data estate.
It means you can start pulling SQL text apart without turning the afternoon into a procurement exercise. Small victories.
Install it with pip in your Python environment:
|
1 |
pip install sqlparse |
And here’s a basic example:
|
1 2 3 4 |
import sqlparse sql = "SELECT id, name FROM customers WHERE status = 'active'"parsed = sqlparse.parse(sql)[0] # Get the statement typeprint(parsed.get_type()) # Output: SELECT # View the tokensfor token in parsed.tokens: print(token.ttype, repr(str(token))) |
The output shows you how sqlparse breaks the SQL statement into tokens.
For example, it can identify the statement type as SELECT, separate keywords from identifiers, and expose the query’s structure in a token-based representation.
That is useful for simple parsing tasks.
For example, you can use sqlparse when you need to:
- format SQL,
- split SQL scripts into separate statements,
- inspect tokens,
- build lightweight SQL utilities,
- prototype simple parser logic in Python.
But this is where the expectations need to stay realistic.
sqlparse is non-validating. It does not connect to your database. It does not check whether a table exists. It does not understand your schema, your dependencies, or your data lineage.
It gives you a token-based, tree-like representation of the SQL statement.
That is useful for formatting and simple inspection.
It is not enough for production-grade lineage, impact analysis, column-level dependency mapping, or multi-dialect SQL understanding.
For those use cases, you need a more robust SQL parser, which is where the commercial options below come into play.
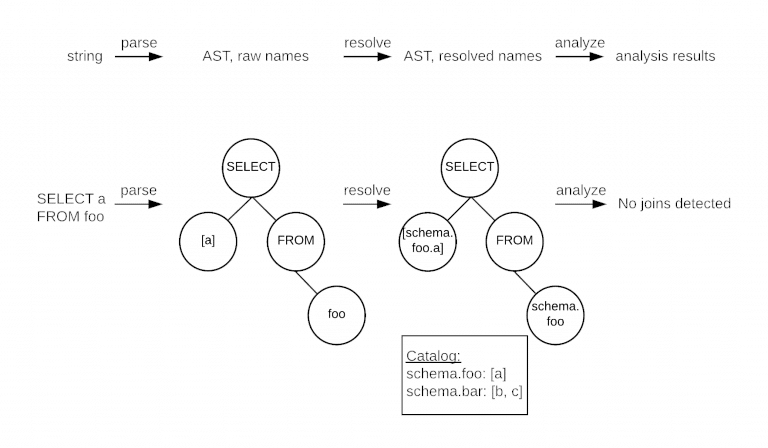
Another interesting open source SQL Parser has been developed by the Uber engineering team. It’s called Queryparser. The team needed to identify all of the table columns that are used in joins.
The Uber engineers also built a lookup phase into the parser that looks up information in the information schema such as the columns for SELECT b.* FROM tableb as b. This component resolves column names that are obscured in the SQL itself, e.g. looking at SELECT * in isolation will not tell you the column names that are part of the query. You can augment the parse tree by looking up this information from the database’s information schema.
The diagram from the website outlines the three step process they implemented.
The open source SQL Parsers work for some simple use cases. You can even build your own SQL Parser from scratch using ANTLR or other parser generators.
However, if you need something more robust you should look at a commercial SQL Parser. Some advantages of an SQL parser.
- You need broad support for SQL dialects
- You need support for the long tail of SQL features. These are features that are very specific to a particular dialect, e.g. CONNECT BY on Oracle
- You don’t need to host or administer the SQL Parser. Just access it online via an SDK or an API
- You need product support
- You need custom features or enhancements
Sonra’s FlowHigh SQL parser follows a freemium pay per use model. You will get a certain number of free credits each month. Once you have used up your credits you will be billed by usage.
Gain access to FlowHigh today.
Choosing an SQL parser
We have listed a couple of criteria you should take into consideration when selecting an SQL parser.
- Define your requirements. You will need to define your business objective and the type of SQL statements you need to parse, e.g. your SQL dialects and SQL operators. Do you need to parse DDL, DML, or both?
- Choose an SQL parser that is fast and efficient.
- Choose an SQL parser that gives you flexibility, e.g. choose a parser with an SDK for automating common tasks.
- Choose an SQL parser that is cost-effective and fits within your budget. Consider the long-term costs of using the parser, e.g. with an online SQL parser you can eliminate costs around maintenance and upgrades.
- Choose an SQL parser that is well documented and easy to use.
- Choose an SQL parser that provides additional functionality such as data lineage, impact analysis, SQL optimisation etc.
SQL parser use cases for data governance
You can categorise use cases for SQL parsing into data governance and data engineering use cases. Let’s start with some SQL Parser use cases for data governance.
Data catalogue
An SQL Parser can help you populate a data catalogue. Companies use data catalogues to make it easier for data analysts and data scientists to find and discover useful corporate data sets. A data catalogue typically contains a data dictionary with the descriptions, keywords and tags for tables and columns in a data warehouse, data management system, or database.
However, the data dictionary contains only very static information. Organisations can go a step further and enrich the data catalogue with real usage stats of how users actually consume corporate data. By using an SQL Parser we can deconstruct the queries that users issue against the database and identify the columns and tables that were queried, how tables are joined and filtered and much more.
Additional information such as the name of the user who submitted the query, the time when the query was run, what tool submitted the query etc can be extracted from the SQL queries that were executed. The history of SQL queries is typically stored in the query history in the information schema of a database. The SQL Parser can extract all of the useful information from those queries over time.
Here is a list of some common usage metrics that you can capture in a data catalogue for data set discoverability:
- Access counts for columns and tables
- Distinct access counts for columns and tables
- The most common queries that are run against a particular table. How is a table used in practice?
- Commonly joined tables
- Table usage by users or groups of users and teams
- Other query patterns
Having those metrics available you can answer questions such as:
- find popular datasets used widely across the company, e.g. what are the TOP 10 tables used at the company
- find datasets that are relevant to the work my team is doing
- find datasets that I might not be using, but I should know about
- Find related datasets
- Identify tables and columns that are rarely or never queried. They may be dropped.
You can read about the data catalogue at Spotify to find out more about how they are using metadata from SQL queries to enrich their data catalogue.
Business rule extraction and documentation
With an SQL Parser you can extract business rules and business transformation logic.
Here is a simple example:
SELECT ADD_MONTHS(date_column
,2)
,date_column AS RESULT
FROM TABLEX;
We apply business transformation logic to the date_column by using the function ADD_MONTHS to add two months to the column date_column.
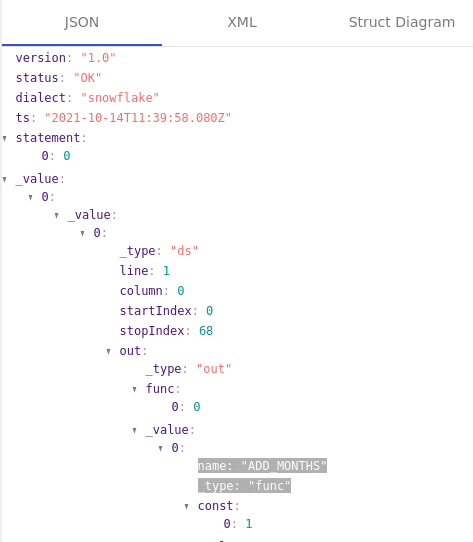
Using our SQL Parser, FlowHigh we can identify any columns where a function such as ADD_MONTHS has been applied. Based on this we can auto generate documentation for business transformation logic.
Data Lineage
A very common application for an SQL Parser is to detect the flow of data across and inside systems and databases of an enterprise.
Here is a very simple example of how data from the ORDERS table flows to the ORDER_AGG table.

Lineage can be a visual representation of data origins (creation, transformation, import) and will help answer questions such as Where did the data come from?
There are two types of data lineage.
Table level lineage
Table level lineage tells us about dependencies at table level.
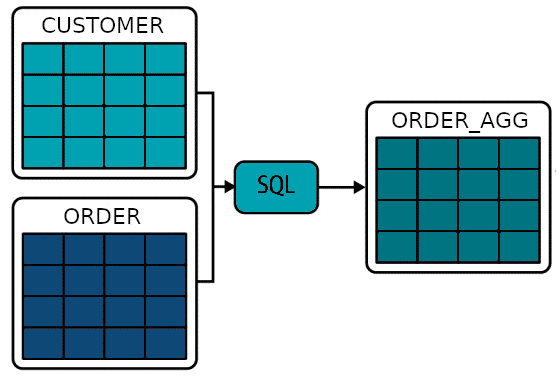
Table ORDER_AGG is the result of a join of Table CUSTOMER and ORDER
Column level lineage
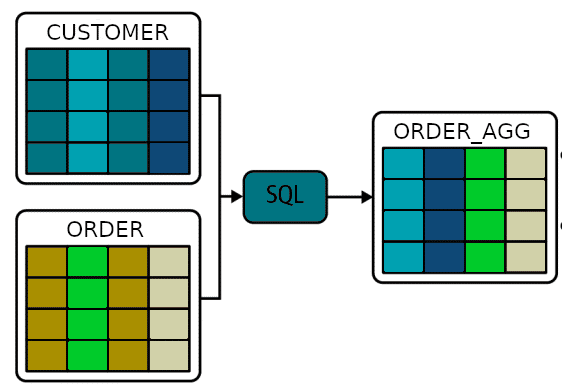
Having data lineage available at column level is a lot more useful as it allows you to trace the data at a more granular level, e.g. if you know that column CUSTOMER_NAME in table CUSTOMER contains PII and this column is used to populate column CUSTOMER_NAME in table ORDER_AGG then you can infer that column CUSTOMER_NAME also contains PII. As a result you can use this information to identify any tables that contain PII data or even use it to automatically mask PII data across all tables.
The importance of data lineage
Having the ability to trace data flows through systems is very useful for multiple use cases
- With data lineage and metadata you can automate the creation of column level access controls.
- Data lineage allows you to identify all of the sensitive data within your data warehouse and operational systems.
- You can perform impact analysis, e.g. which tables are affected downstream if the name of a table or column is changed.
- Regulations such as BCBS 239 require the finance industry to trace back data to the authoritative source.
- With data lineage you can identify records that need to be deleted throughout your systems e.g. as part of a GDPR requirement.
- Data lineage can be used to troubleshoot the root cause of issues, e.g. the failure of an ETL process (stepwise debugging).
- Data lineage provides a complete audit trail for a data point of interest from the source to its final destinations.
- One of the most important applications of data lineage is impact analysis. Impact analysis automatically detects changes to a data pipeline by comparing current version to previous versions of the pipeline. Furthermore it can detect the type of impact of this change on dependent objects downstream and upstream of where the change occurred.
Data security and data protection
Database activity monitoring with SQL audit logging
A SQL Parser can be used to address auditing requirements for compliance. Regulations such as Sarbanes Oxley or HIPAA have common auditing-related requirements.
With audit logging you can monitor and record selected user database actions such as access to tables and columns by extracting the table and column names from SQL queries that users run.
- Audit logging will help with detecting suspicious activity on a database.
- Enable accountability for actions. These include actions taken in a particular schema, table, or row, or affecting specific content.
- Notify an auditor of actions by an unauthorised user. For example, an unauthorised user could change or delete data,
- Detects problems with an authorization or access control implementation.
SQL Injection
Using an SQL Parser you can deconstruct queries submitted through websites to detect SQL injection attacks and prevent them. This research paper discusses the details of using an SQL Parser to detect SQL injection.
SQL parser use cases for data engineering
SQL visualisation
SQL is a very powerful language. It can be used to solve almost any type of data related problem or question. However, SQL can get quite verbose. Many beginners and intermediate users of the language tend to write unnecessarily complex SQL. An avalanche of subqueries, nesting and spaghetti code is the result.
SQL generators such as BI tools tend to generate poor SQL. This happens if the underlying model or semantic layer has been poorly designed. Some BI tools are just plain bad when it comes to generating good SQL.
Here are some visualisations from the FlowHigh SQL visualiser.
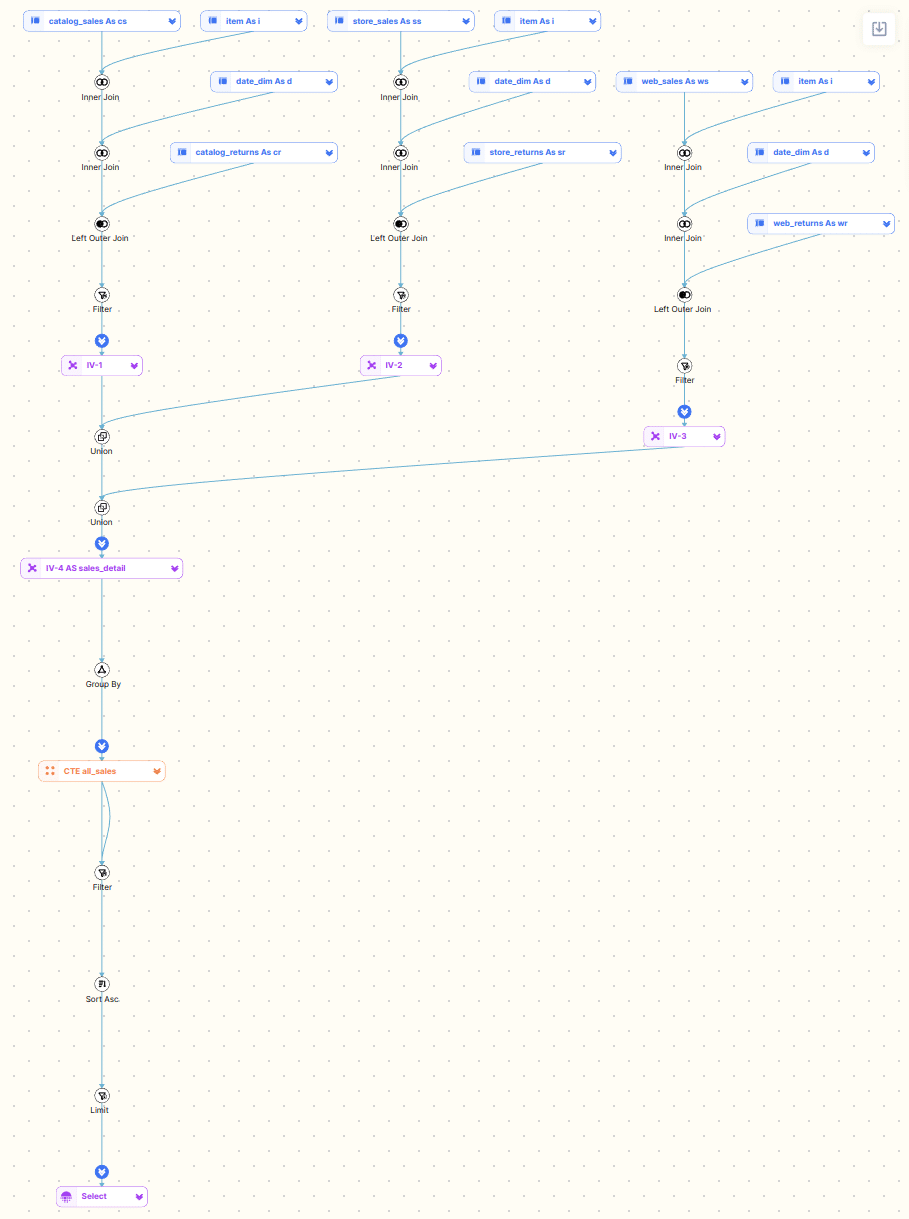
Debugging SQL becomes a breeze with an SQL visualisation tool.

500 lines of code at a glance in a diagram. A picture says more than a thousand words has never been more fitting.
Here is a summary of the use cases for SQL query visualisation.
- Quickly make sense of the query tree and query hierarchy, e.g. nested queries, CTEs, inline views
- Identify issues and query anti-patterns such as self-joins
- Get a list of all the physical tables and columns involved in a query
- Identify sub-queries, virtual tables, cross joins, and recursive queries at a quick glance
- Document important queries, e.g. document your ELT / ETL pipeline
SQL flow visualisation can also be done in reverse, i.e. creating a query through a visual tool and then generating the SQL code from it.
SQL formatting
A well known productivity use case for an SQL Parser is SQL formatting. Using an SQL Formatter you can beautify SQL code, e.g. apply proper indentation, apply styles, and format the SQL code according to good practices.
Before
After
Refactoring and impact analysis of ETL and data pipelines
Sometimes you need to make a change to a table. Using an SQL Parser you can determine the impact to upstream and downstream processes.
By analysing the SQL that is run against the changed table you will be able to determine what code needs to be refactored. You can make sure that nothing breaks if you go live with the change to your table.
Performance tuning
Another useful application for an SQL Parser is to detect performance issues or recommend performance improvements.
Detect SQL anti-patterns
Using an SQL Parser you can detect SQL anti-patterns. Anti-patterns are SQL queries that do not follow best practices.
I have listed some common anti-patterns below. Sometimes the anti-pattern is legitimate under certain circumstances. The list should be treated as a rule of thumb only.
- Using a self join instead of window functions
- Using the same table multiple times in a complex query may indicate that the query is not well written
- Using DISTINCT is often an indicator that something is wrong with the query or the underlying data quality
- Using UNION instead of UNION ALL
- Selecting all of the columns from a table SELECT * FROM
- Detecting unnecessary joins in a query, e.g. where the table is used in a join but then not used as part of the query.
While you can detect certain anti-patterns by just looking at a piece of SQL code you frequently require additional information, e.g. the way the data has been modeled physically, data distribution stats, information on data volumes, data access patterns etc.
Data layout and physical data model optimisations
Just looking at a query in isolation is not enough to propose performance tweaks. Frequently, you need to look at query patterns over time and the query history to make performance recommendations.
I have listed some examples where looking at the query history can be used to make recommendations to adapt the physical data model design.
- Looking at the table join columns you can determine an appropriate set of distribution keys
- Looking at frequently used column filters in the WHERE clause can determine recommendations for indexes or sort/cluster keys.
- Queries that frequently aggregate on columns make good candidates for Materialised Views
Data warehouse and database migration
SQL to SQL – Database to Database
Using an SQL Parser you can translate the SQL syntax from one SQL dialect to another SQL dialect by mapping the grammar between these.
This is useful for migration projects from one database vendor to another, e.g. you might want to migrate an on premise Oracle data warehouse to a cloud data warehouse such as Snowflake.
SQL to ETL – Database to ETL tool
You can take this one step further and migrate SQL code to an ETL tool. Many ETL tools have an SDK that can be used to programmatically generate transformation operators. Using an SQL Parser you could migrate SQL code to a visual representation in an ETL tool such as Oracle Data Integrator using the SDK of the tool.
The other direction is possible as well. Using the SDK you could generate SQL code from visual ETL transformations and operators.
Why do we need an SQL parser
We have seen that an SQL parser covers a huge number of use cases and applications. An SQL parser translates SQL code into human readable bits and pieces. This is the foundation to enable all of these use cases.
Here is a summary of the benefits and applications of an SQL parser
- Formatting and maintenance of code: SQL parsers make code easier to read and maintain by requiring uniform formatting and structure in queries. This makes it easier for the team to work together and simplifies the code.
- Query conversion: SQL parsers can be used to convert SQL queries into other query languages, ETL tools, or data integration tools. They can also translate SQL queries between different dialects. When moving applications to new database systems, this can be helpful.
- Visualisation and analysis of queries: Parsers can visualise and analyse SQL queries, helping developers understand the relationships between tables and columns.
- Query formatting: To make SQL code more readable and compliant with coding standards, a SQL parser can automatically format SQL code using predefined styles or rules.
- SQL parsers may extract metadata from queries, including the tables and columns used, which is useful for processes like schema validation, impact analysis, and documentation creation.
- Optimising and refactoring queries: Parsers can assist in refactoring SQL queries by spotting unnecessary or inefficient code and recommending alternatives to speed up query execution and boost performance.
- Data lineage analysis: By detecting dependencies between tables and columns in queries, SQL parsers can be used to track data lineage, allowing for a better understanding of data flows and linkages in complicated systems.
- Automated testing: By producing test cases, validating query outputs, and spotting any bugs in the SQL code, SQL parsers can help with automated testing of SQL queries. The SQL parser assists in identifying any anti-pattern mistakes or consistency problems in the SQL queries as part of a CI pipeline, giving developers thorough feedback about the problems detected. The queries can then be tested again to make sure they are functioning properly after developers have fixed the problems.
- Impact analysis involves assessing the prospective effects of system changes, such as adjustments to database architectures or data processing pipelines. Developers and database administrators may make wise decisions, prepare for essential changes, and reduce risks by identifying the affected components and evaluating the potential impact.
Examples of SQL parsing
Let’s go through some practical examples of parsing SQL.
We will use the FlowHigh to parse SQL.
Online SQL parser in browser
You can parse SQL with FlowHigh in two ways. Either through your browser or using the SDK.
Use the following simple query to test the parser in your browser
SELECT d.year
,i.brand_id
,cs.quantity-COALESCE(cr.return_quantity
,0) AS sales_cnt
FROM catalog_sales cs
JOIN item i
ON i.item_sk=cs.item_sk
WHERE i.category_id=10
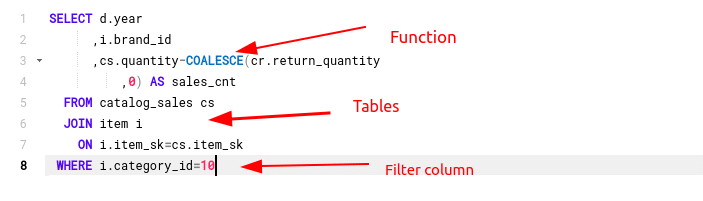
You can get the parsed output either as a JSON or XML message. The deconstructed SQL is returned as a tree.
Flexter generates a message as output from the SQL. The message can either be returned as XML or JSON. The message is based on a schema (XSD).
The XSD is structured hierarchically and made up of various complex types. At the root of this tree we have the complexType ParseQL. It contains various elements, e.g. Statements. You can view the XSD in the online documentation.
I have highlighted some of the SQL clauses and mapped them to the matching components in the XML output.
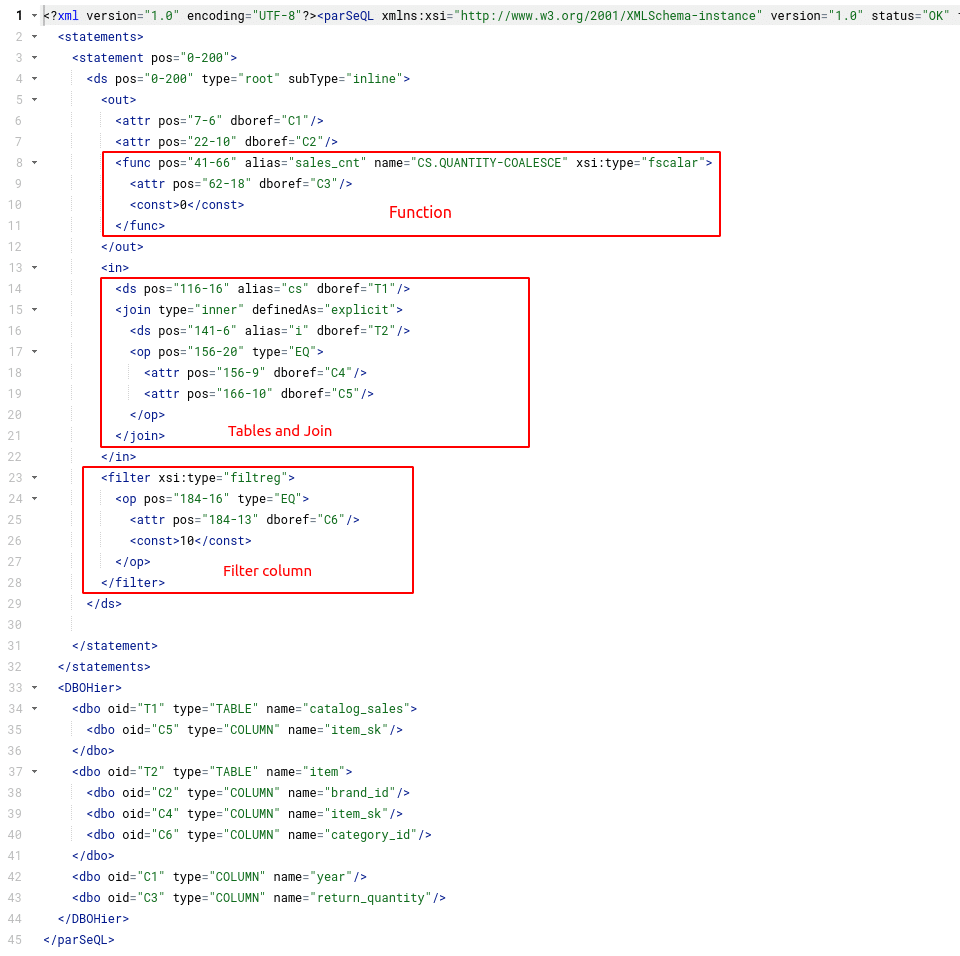
SQL parser SDK
FlowHigh ships a powerful Python SDK to automate SQL parsing tasks.
We have prepared a couple of SQL parser SDK snippets that you can view online. Those snippets have been built from the primitives of the FlowHigh SDK. The snippets cover some common use cases
- Get all of the tables and table types from an SQL query
- Get a list of all of the columns in the SELECT clause of an SQL query
- Get all of the columns that are used to filter a query
- Get all of the columns in the ORDER BY clause. This is useful to identify columns that are involved in expensive sort operations. These are candidates for clustered indexes or sort keys.
- Get all of the columns in the GROUP BY clause. These may be candidates for Materialised Views.
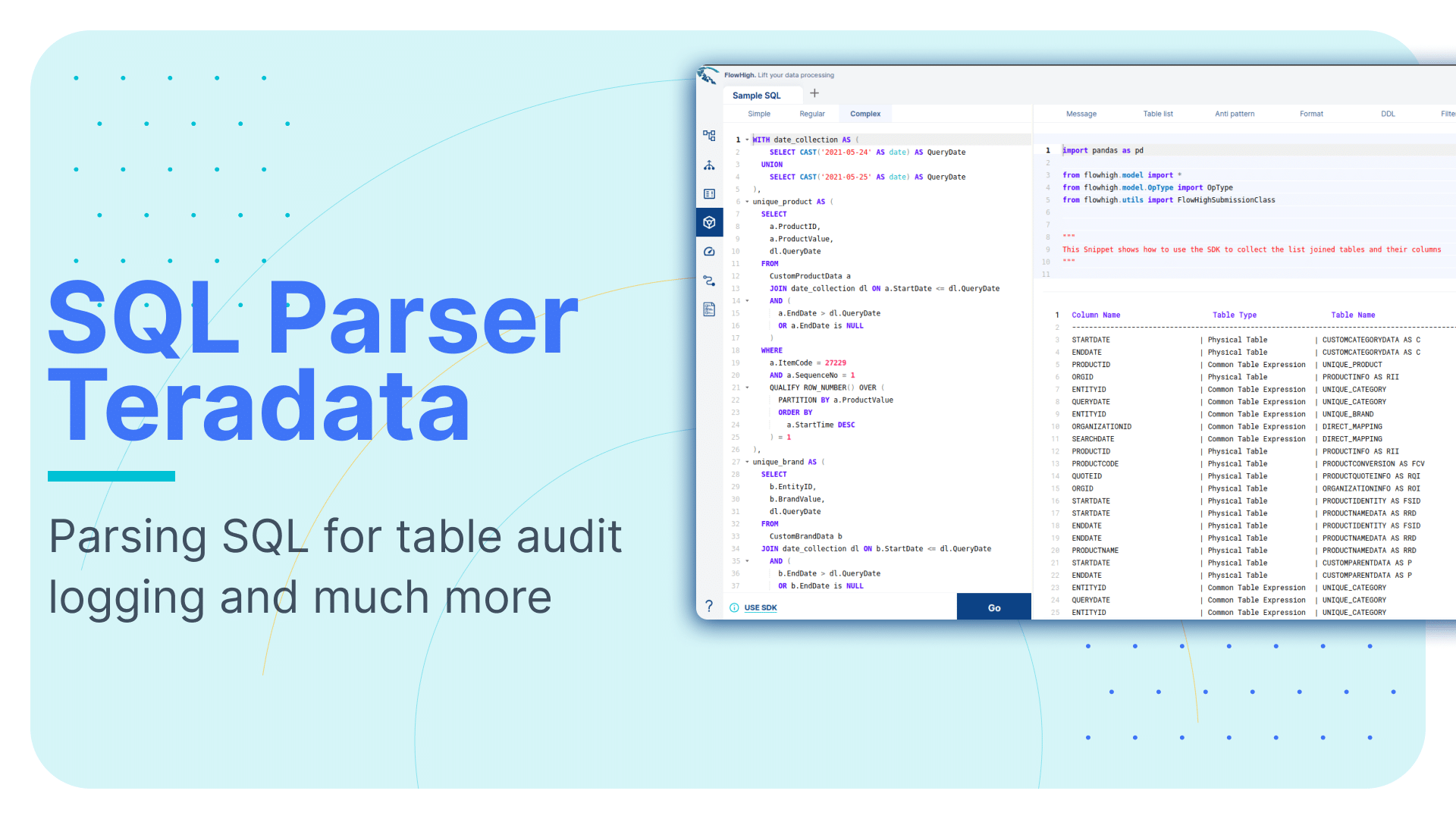
Here is a screenshot of the SDK snippet that deconstructs an SQL statement into its tables and table types
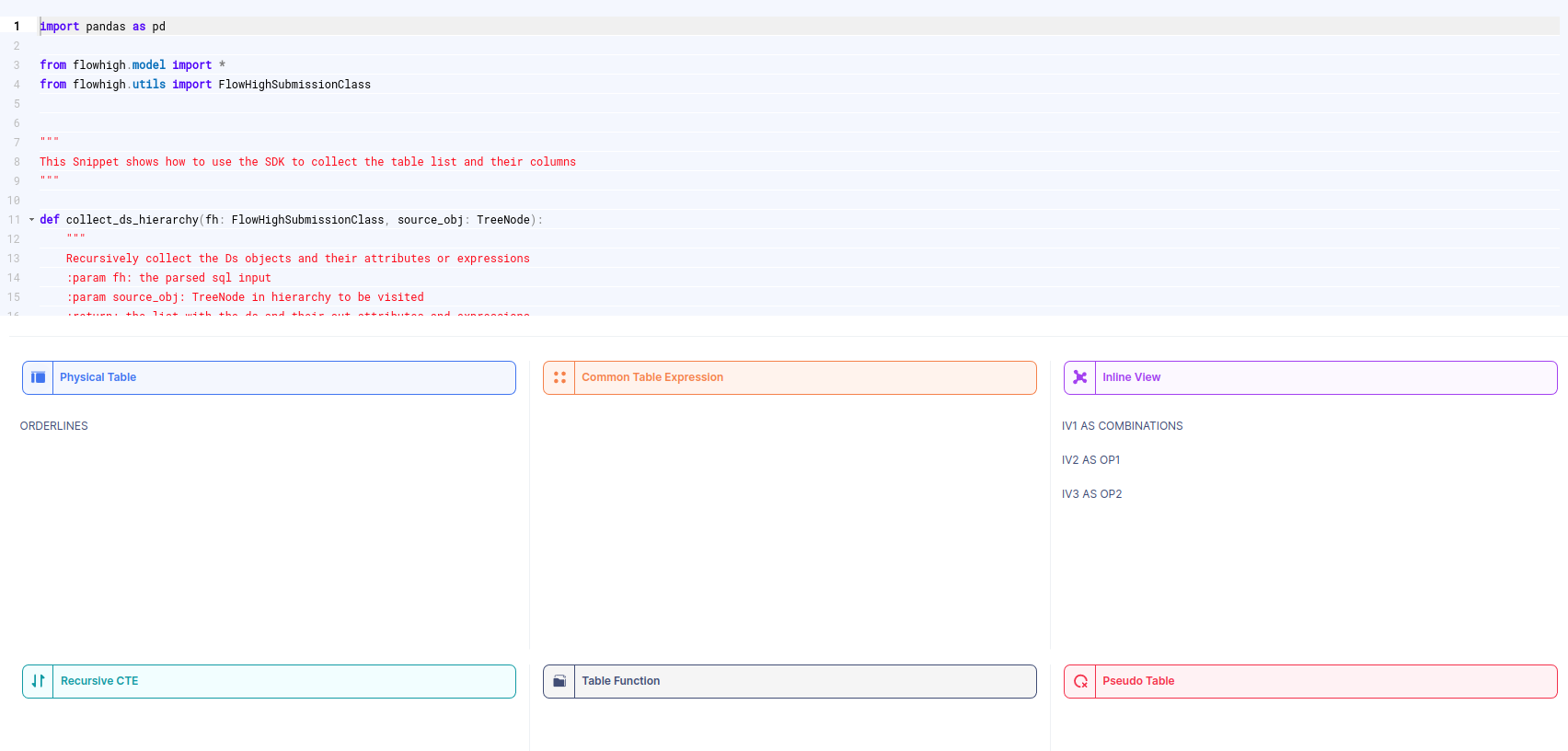
The online documentation contains many more examples on how the SQL parser SDK works to meet your specific needs.
The SDK ships with various abstractions for common use cases, e.g. to get all of the tables in an SQL statement you can run the following code
>>> from flowhigh.utils.converter import FlowHighSubmissionClass
>>> fh = FlowHighSubmissionClass.from_sql("SELECT id FROM TAB GROUP BY 1")
>>> [fh.get_tables(s) for s in fh.get_statements()]
Gain access to FlowHigh today.
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: