Endeca text tagging: Tagging unstructured IT jobs data against a whitelist of LinkedIn skills
A couple of days ago I have started to look at Endeca. So far it looks like a great tool and I believe we will see and hear a lot more from it over the next couple of months and years.
I am currently still learning a lot and in the next couple of weeks I will document my progress in a couple of blog posts. In this first post we will tag some unstructured data and then create a multi value attribute, which is one of the great features of Endeca.
In this example we look at some Irish IT job offerings data that has been extracted from the web. One of the fields of this data set is a description field. We will tag this unstructured data with a whitelist of skills that were extracted from LinkedIn. There are 30K skills right now on LinkedIn, which resulted in some performance issues when using the text tagger in Clover ETL. More on that later
Irish IT jobs data set (about 16K records collected over the last 3 months).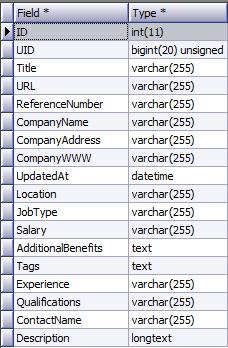
LinkedIn skills data set
The Irish jobs data sits on a MySQL server. The skills data set is in an Excel sheet. The end result of our ETL will look like this.
You need to name the input fields SearchTerm and TagValue respectively. Any other value will throw an error when loading via the Text Tagger component.

We first add a connection to the MySQL database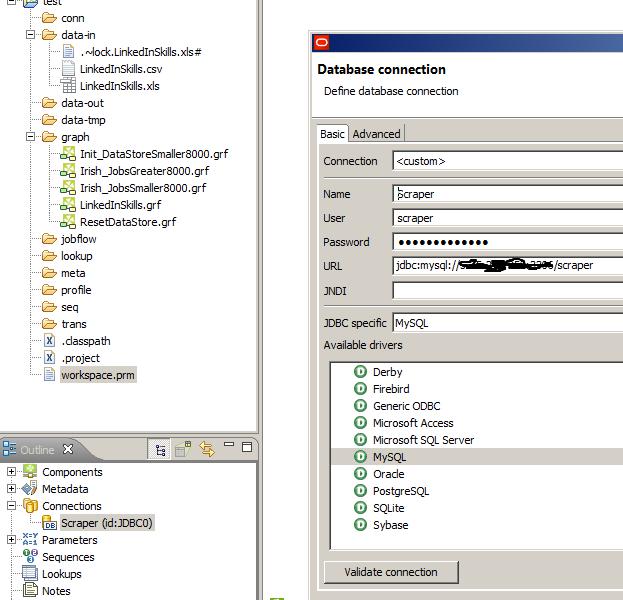
Next we create a graph and add the Irish Jobs and LinkedIn metadata to it.
A data flow/mapping in CloverETL is named graph.

And the LinkedIn metadata
Next we add a DB_INPUT_TABLE and an XLS_DataReader and configure them

Next we add the Text Tagger – Whitelist component from the Discovery palette and connect the Irishjobs_IE input table and the XLSDataReader for the LinkedInSkills to it. The Text Tagger takes two parameters as input. The unstructured text field that needs to be tagged and the name of the output field. In our case the Source Field Name is Description and the Target Field Name is DescriptionSkills. We still need to set up the latter as Metadata in the next step.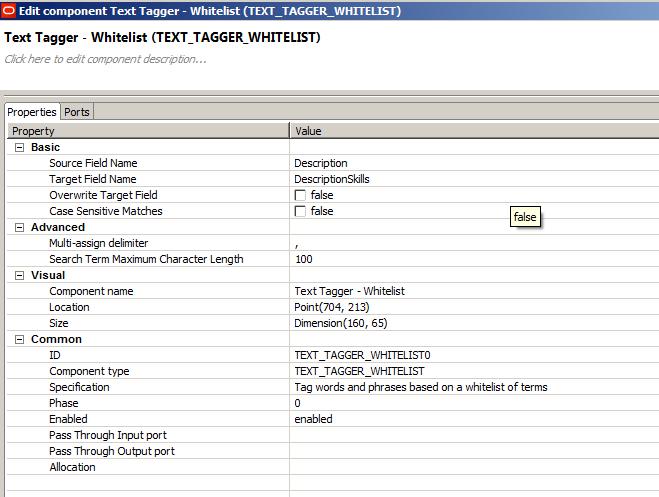
I have set the multi-assign delimiter to “,”. This will separate the tagged skills as a comma separated list. In the Endeca Server we can treat this then as a multi-value attribute.
Next we need to create the Metadata for the output from the Text Tagger and add the DescriptionSkills field to it. We do this duplicating the metadata from the irishjobs_ie input table and manually adding the field DescriptionSkills to it.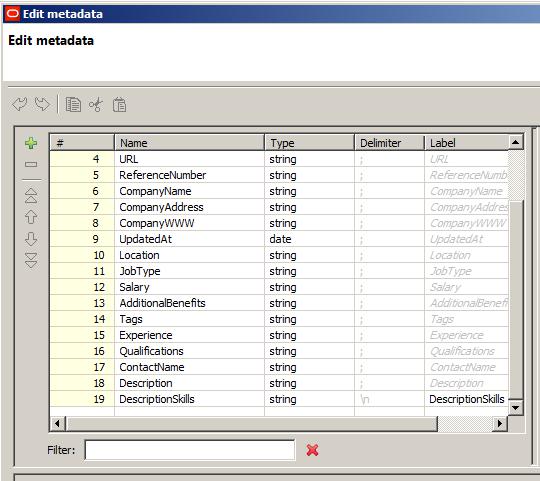
Next we add a Bulk Add/Replace Records component to the graph, connect the Text Tagger to it, and add the newly created metadata to it. In the properties of the Bulk Add/Replace Records component we specifiy the Spec Attribute (unique key) and the multi-assign delimiter. In our case that is a “,” (as specified earlier in the text tagger. The multi-assign delimiter is used to split the chain of comma separated values. What I find strange here is that you need to define a delimiter for all of your attributes. I would really expect to specify this at the attribute level rather than the dataset level.
ETL Performance problems
Once this is done we can run the ETL. When I first ran this with 30K records in the skills whitelist the whole thing was crawling. For the 16K records it took 12 hours. I noticed that Clover was only using one core of my quad-core CPU at a time (maxed out at 25% CPU usage). An indication to me that multi-threading is not implemented. Either in the Text Tagger component itself or in Clover. I had a look on the Clover website and it stated there that it is multi-threaded so my conclusion for the moment is that the Text Tagger component is not multi-threaded or that the Desktop version of Clover is not multi-threaded. Can anyone please shed some light on this?
I was then experimenting a bit. What I found was that splitting the whitelist file into multiple smaller ones and then sending the jobs data through the Text Tagger sausage machine improved performance significantly. What that means is that Text Tagger performance is not linear, i.e. doubling the number of whitelist records does more than double elapsed time for tagging.
Below you see how the split is implemented in Clover. This should give you an idea how this can be done. I am sure this can be implemented in a more elegant way using splitters and loops and stuff. The take away though is that in order to get the best performance you need to play around with your whitelist sizes.
The Reformat component is used to concatenate the resulting skills output fields from the Text Tagger components.
The result for 200 sample jobs for a subset of the skills (letters A-E) is as follows.