Flexter FAQ & Guide – Automate XML & JSON Conversions

Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Product Overview
Flexter – Automating XML & JSON Conversion for Enterprises
Flexter is an enterprise data integration tool specifically designed to automate the conversion of large volumes of complex XML and JSON files into a tabular structure or relational formats like SQL tables in a database.
If you’re also working with JSON workflows in Databricks and want step-by-step guidance on reading, parsing, querying and flattening JSON data, see our Databricks JSON Guide Read Parse Query and Flatten Data.
Flexter empowers organisations to focus on extracting value from their data instead of wrestling with the complexities of XML and JSON transformations. It solves the following problems:
- Simplifies and automates the transformation of complex XML/JSON data into relational formats.
- Eliminates manual coding and reduces errors in data preparation.
- By using various schema optimisation algorithms, Flexter makes the target schema more compact and easier to work with for downstream analytics.
- Provides schema discovery and evolution handling.
- Scales effectively for large and complex datasets.
- Bridges the gap between hierarchical data and relational/analytical systems.
- Reduces costs and time spent on custom development.
- Ensures compliance with regulatory requirements through accurate data processing.
Key Features of Flexter for Automated XML & JSON Conversion
Here is a list of high level Flexter features. For a full list refer to the Flexter Data Sheet in Appendix
Automated Target Model Creation:
- Supports the full XML Schema (XSD) specification, including advanced features like polymorphism and xsi:type construct.
- Automatically generates relational target schemas from XSDs or XML samples, simplifying complex hierarchies.
Automated Mappings:
- Automatically maps XML source elements to target table columns during schema generation.
- Reduces manual effort and ensures accuracy in the transformation process.
Automated Documentation:
- Generates data lineage, ER diagrams, source-to-target mappings, and data models automatically.
- Provides clear, comprehensive insights into data relationships and transformations.
Automated Foreign Key Generation:
- Creates parent-child relationships and foreign keys during conversion.
- Maintains referential integrity in the target schema.
- Employs automatic generation of surrogate key values which are guaranteed to be globally unique.
Connector Support:
- Supports cloud storage (S3, Azure Blob, Azure Data Lake) and modern data platforms (Snowflake, Google BigQuery, Databricks).
- Compatible with traditional RDBMS like Oracle and MS SQL Server, and open formats like Parquet and Delta Lake.
Optimized Target Schema:
- Simplifies target schemas to minimize the number of tables and joins for downstream consumption.
- Improves query performance and readability of the data model.
API / Programmatic Access:
- Provides APIs, SDKs, and CLI for seamless integration into data pipelines.
- Enables automation and programmatic control of the XML conversion process.
Metadata Catalog:
- Stores source-to-target mappings and keeps record of schema versions for easy management.
- Supports DDL generation and upgrade scripts for evolving schemas.
Error Handling and Logging:
- Logs runtime errors and provides robust error handling.
- Ensures stable, predictable conversion processes.
Pipeline and Workflow Integration:
- Integrates with broader data pipelines for archiving, error handling, and ETL processes.
- Supports alerting, restartability, and detection of unknown XPaths.
Scalability and Performance:
- Processes large XML files and scales to meet any data volume or SLA requirements.
- Delivers high-speed conversion for massive workloads.
Schema Evolution:
- Handles changes in XSDs through automated or semi-automated refactoring.
- Simplifies schema updates and ensures smooth transitions.
Full XSD and XML Support:
- Fully supports all XSD features and handles any XML data, regardless of complexity.
- Offers universal compatibility across industries and standards.
Inside Flexter – Architecture and Technical Design
How It Works:
Converting XML to a relational or tabular format is a simple two step process.
Here is a high level overview of how it works
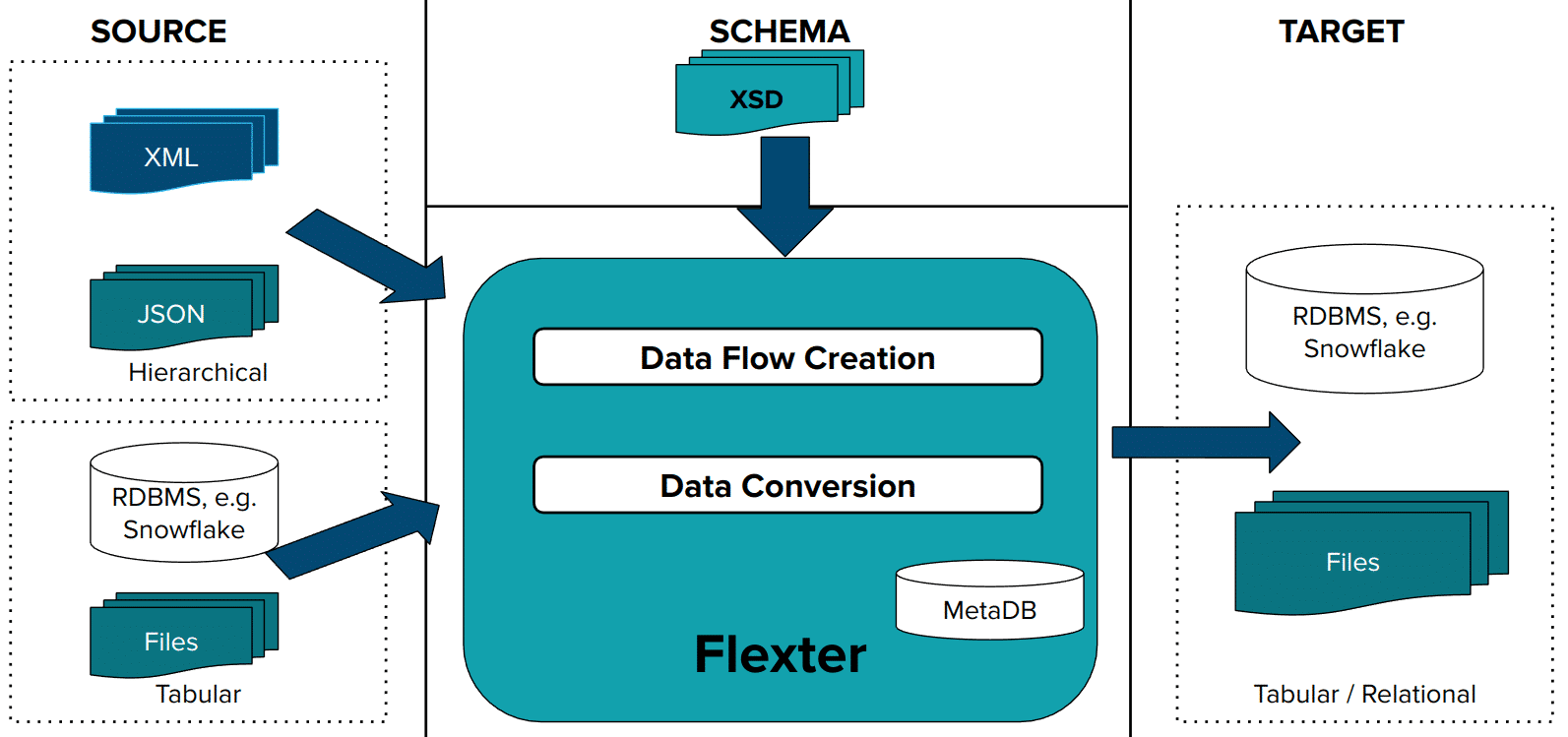
Step 1: Create Data Flow
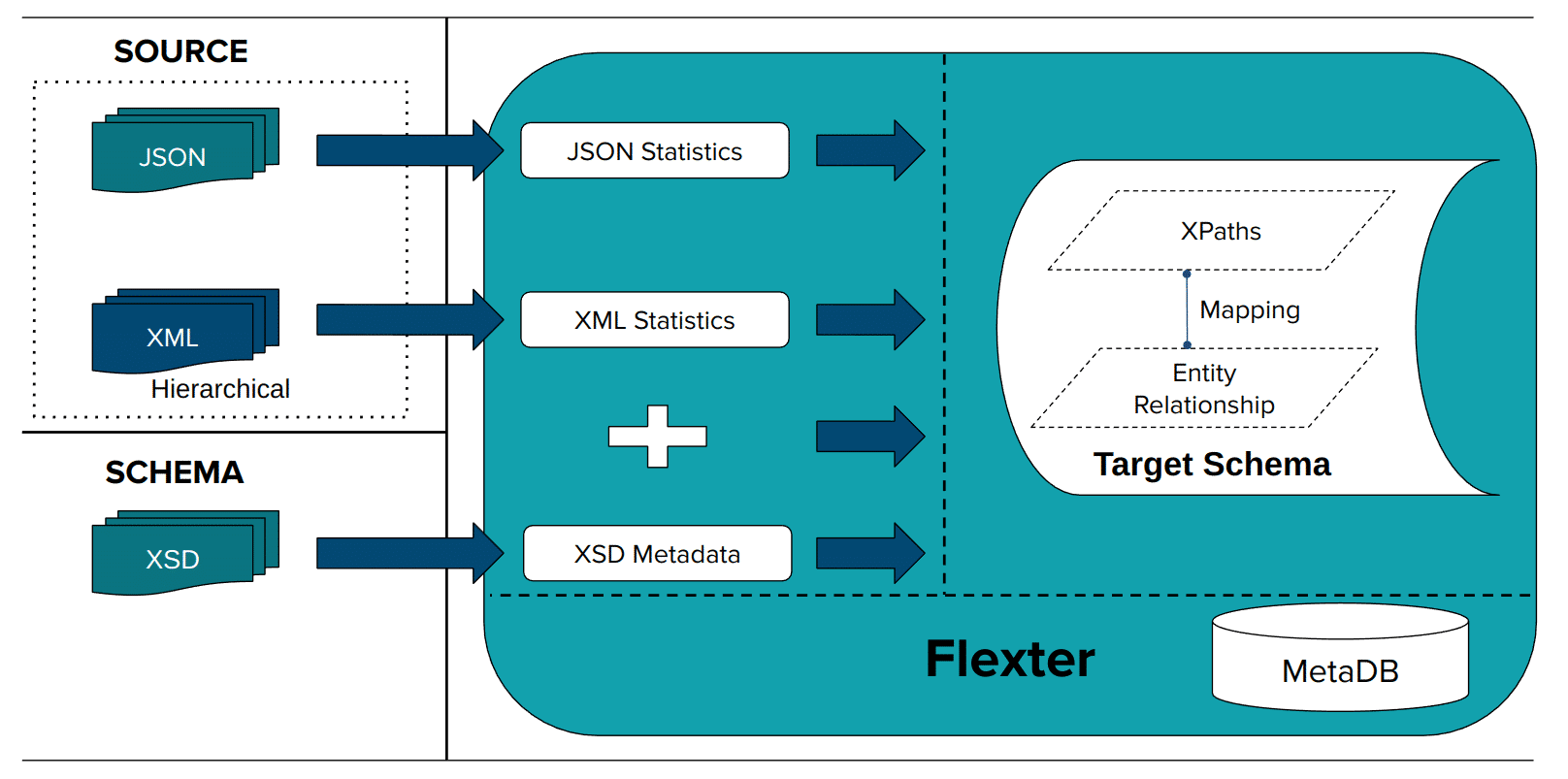
In the first step Flexter creates a Data Flow from an XSD, a sample of XML, or a combination of both. Flexter also works with JSON. The data flow generates the logical target schema and the mappings. This information is stored in the Flexter MetaDB. Data Flow creation is a one off process. It is only repeated to evolve the schema if the changes in the incoming date structure require it.
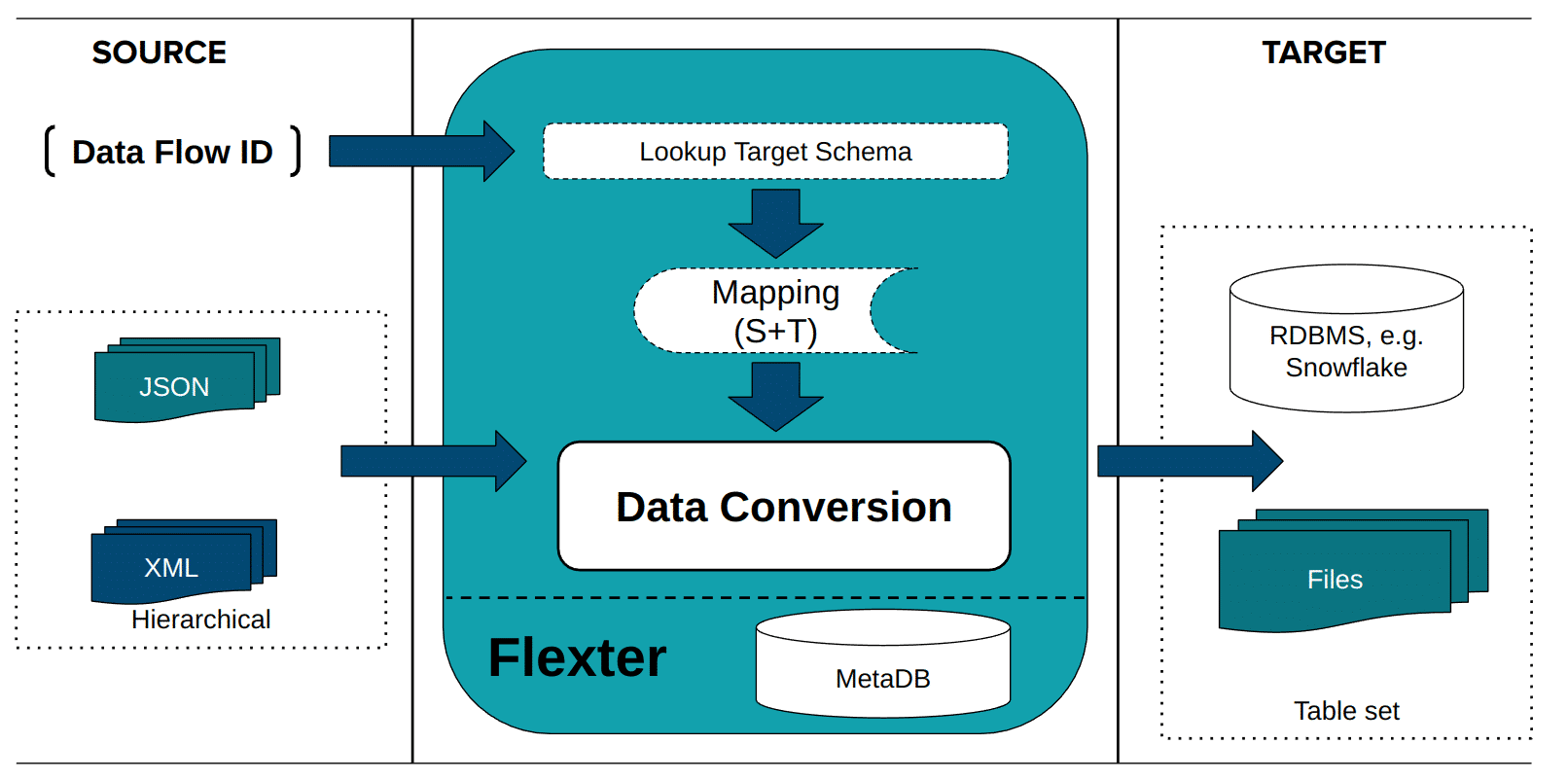
Step 2: Convert XML Data
In the second step Flexter converts XML to a supported target format
Optimisation target schema
What makes sense to a data warehouse manager or a data architect may not make a great deal of sense to a “downstream” user of the data.
Converting data from XML to a database is one thing. But for that data to be readable for a decision-maker or analyst, it needs to be optimised into a recognisable and highly readable format.
This is where the real beauty of Flexter comes in.
A powerful in-built optimisation algorithm works to greatly simplify the auto-generated target schema so that any downstream user can query and read the necessary data.
Core Technologies:
Flexter is a powerful enterprise XML conversion tool that leverages the distributed computing capabilities of Apache Spark to deliver exceptional performance and scalability. Its design ensures that organizations can handle large volumes of complex, hierarchical XML data efficiently, making it an ideal choice for enterprise-grade data processing needs.
Deployment Options:
Flexter runs on standard servers or VMs with appropriate compute and storage configurations, depending on the size and complexity of the XML/JSON data being processed.
Flexter offers versatile deployment options to cater to different organizational needs and infrastructure setups. It can run as a standalone application on a single server or virtual machine (VM) or as a distributed application on an Apache Spark cluster, providing flexibility, scalability, and performance optimization.
Flexter is designed to be deployed within the client’s own environment, providing flexibility and control over data processing and security. Clients can choose to install Flexter in their on-premises data center or within their private cloud environment, depending on their infrastructure and operational preferences.
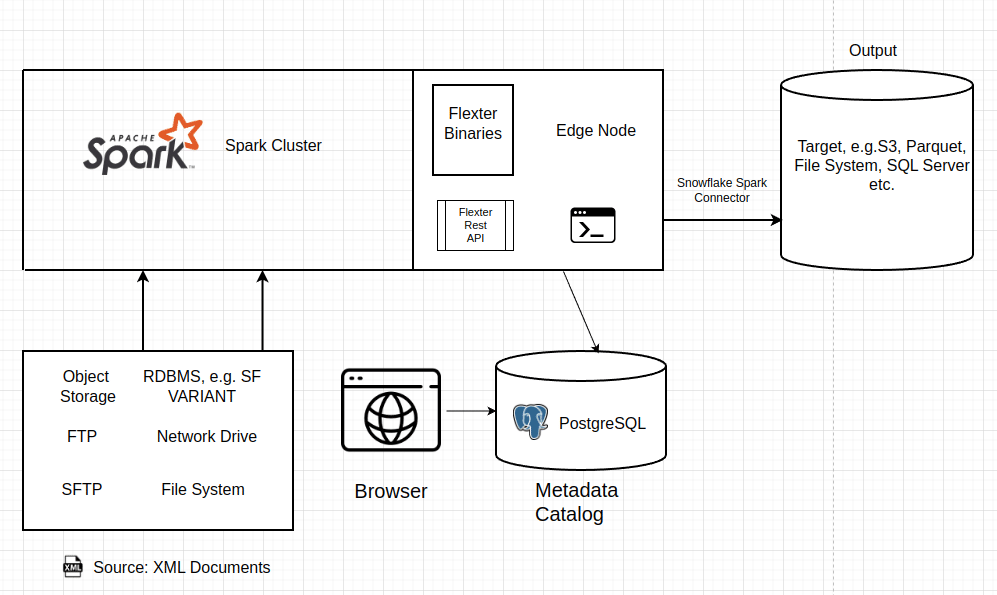
This diagram illustrates the Flexter architecture and its components, showing how XML/JSON data is processed, transformed, and integrated into downstream systems. Here’s a breakdown:
Input Sources
- Supported Input Types:
- Object Storage: Reads data from cloud storage like AWS S3, Azure Blob Storage, or Google Cloud Storage.
- RDBMS: Can process data stored in relational databases, including Snowflake’s VARIANT data type and other BLOB and CLOB data types.
- FTP/SFTP: Ingests data from FTP or SFTP servers for secure file transfers.
- Network Drive/File System: Supports local file systems or network drives for XML file input.
Processing Framework
- Apache Spark:
- Flexter leverages Apache Spark for distributed data processing, enabling high performance and scalability.
- Spark handles large datasets, splitting processing tasks across multiple nodes in a cluster.
- PostgreSQL Integration:
- Flexter uses PostgreSQL for storing metadata, such as schema mappings, data lineage, and registering detailed status of its own jobs.
- Acts as the metadata catalog, essential for managing transformations and schema evolution.
Edge Node
- Flexter Binaries:
- The core Flexter binaries handle the XML/JSON parsing, schema mapping, and data transformation processes.
- Flexter REST API:
- Provides programmatic access to Flexter’s capabilities for triggering, monitoring, and managing data transformations.
- Enables integration with other tools and automation frameworks.
- Command-Line Interface (CLI):
- Allows users to interact with Flexter via scripts for custom workflows and batch processing.
Metadata Catalog
- Browser-Based Access:
- Users can interact with the metadata catalog via a web browser for managing schemas, viewing logs, and configuring transformations.
- Metadata includes mappings, their version histories, lineage details and registered exceptions.
- PostgreSQL Storage:
- The metadata catalog is stored in a PostgreSQL database, ensuring centralized management of transformation rules and version tracking.
Output Targets
- Supported Targets:
- Cloud and Local Targets: Outputs can be written to cloud storage (e.g., S3), local file systems, or relational databases.
- Open Formats: Generates data in formats like Parquet, Delta Lake, or Avro for compatibility with modern analytics platforms.
- RDBMS Integration: Supports databases such as SQL Server, Oracle, or Snowflake, enabling direct integration with data warehouses.
- Snowflake Spark Connector: Specifically integrates with Snowflake using the Spark connector for seamless data ingestion.
Workflow and Data Pipeline
- Source-to-Target Transformation:
- XML/JSON files are ingested from the sources, parsed, and transformed into a relational format.
- Metadata catalogs track schema evolution, data lineage, and mappings for traceability.
- Scalability:
- Apache Spark ensures horizontal scalability, processing large and complex datasets efficiently.
Integration and Compatibility
Programmatic Access
- APIs:
- Flexter offers RESTful APIs for interacting with its conversion engine, allowing developers to trigger, monitor, and manage XML/JSON transformations programmatically.
- API endpoints support operations like uploading files, generating target schemas, retrieving logs, and accessing conversion results.
- Command-Line Interface (CLI):
- The CLI provides direct access to Flexter’s functionality, enabling batch processing and integration with automation scripts.
- Ideal for embedding Flexter in shell scripts or scheduling tools like cron jobs.
Integration with Other Tools
ETL and Orchestration Tools:
- Flexter integrates seamlessly with ETL platforms enabling automated data transformation workflows.
- Works with orchestration tools like Apache Airflow to manage multi-step data pipelines.
Cloud Storage and Object Stores:
- Reads from and writes to cloud object stores like Amazon S3, Azure Blob Storage, and Google Cloud Storage, enabling scalable cloud-native workflows.
Performance and Scalability
Flexter is designed to deliver exceptional performance and scalability, making it an ideal solution for processing large volumes of complex XML and JSON data. By leveraging modern computing frameworks and advanced optimization techniques, Flexter ensures fast and reliable data transformation, even under demanding workloads.
Efficient Parsing and Conversion
- In-Memory Processing: Flexter uses memory-efficient algorithms to process XML/JSON data, significantly reducing processing time compared to traditional file-based approaches.
Parallel Execution
- Multi-Core Processing: On standalone servers, Flexter takes advantage of multi-core CPUs to parallelize workloads, boosting single-machine performance.
- Distributed Workload Management: On Apache Spark, Flexter processes data in parallel across multiple nodes, accelerating execution for large datasets.
Reduced Query Complexity
- Optimized Target Schemas: Flexter simplifies relational schemas to minimize table joins, improving downstream query performance.
Compression Handling:
- Supports compressed input files (e.g., GZIP), saving preprocessing time and resources.
Horizontal Scaling
- Cluster Expansion: Flexter runs on Apache Spark clusters, allowing organizations to scale horizontally by adding more nodes to the cluster.
- Linear Performance Growth: As the cluster size increases, the system scales near-linearly for most types of workloads, maintaining consistent performance for increasing workloads.
Vertical Scaling
- Resource Augmentation: On standalone deployments, Flexter can scale vertically by adding more CPU cores, memory, or storage to the server.
Cloud Integration:
- Flexter integrates seamlessly with managed Spark services like AWS EMR and Azure Databricks.
Reliability
- Cluster Redundancy: In distributed environments, Flexter ensures high availability by balancing workloads across multiple nodes and automatically rerouting tasks if a node becomes unavailable.
Security and Compliance
Flexter is an on-premise solution, not a SaaS product, which ensures it is not constantly exposed to the internet or making external connections. This section highlights the built-in security features and connectivity requirements of Flexter, including its support for encryption, controlled access, and secure installation methods. These measures are designed to protect sensitive data and align with organisational security standards.
Connectivity:
- Flexter requires three types of connections to function:
- reading input file/object storage or input database
- writing to output files/object storage or output database
- reading from and writing to its metadata PostgreSQL database
No additional connections are made or required by Flexter beyond these.
Data Encryption:
- Flexter supports encryption, provided the access method used (e.g., JDBC driver options, HTTPS/ADFS protocol, or the Snowflake Spark connector) facilitates encryption.
OS user and privileges:
- Flexter’s regular job runs are performed under a standard, non-root, non-administrative OS user.
- Access to Flexter is restricted through the OS user, managed and controlled by an OS administrator (e.g., via SSH).
Password Management
- Passwords are stored in configuration files with access restricted by the operating system’s administrator
- Secure access keys are supported, eg. Snowflake key-pair authentication
Installation and upgrades:
- Performed directly from a remote binary (RPM) repository hosted by Sonra.
- Alternatively, installation packages can be securely shared by Sonra and manually deployed by an administrator on the target system.
Recommendations:
- Create and use a dedicated OS user for Flexter. Grant access to Flexter binaries for that OS user. Share access to that OS user with relevant developers or maintenance groups.
- Secure access to PostgreSQL Flexter metadata DB for that OS Flexter user
- Secure network access to input/output/metadata database by whitelisting the IP where Flexter binaries reside.
- Store passwords securely in configuration files accessible by Flexter OS user only.
Real-World Use Cases – How Flexter Solves Data Challenges
Target Use Cases
Conversion of XML Locked Away in Industry Data Standards:
- Flexter converts complex industry XML formats (e.g., HL7, FIX, ACORD) into SQL-ready tables, enabling actionable insights and integration with modern platforms like Snowflake.
- Supports compliance reporting and streamlines workflows for industries like finance (SWIFT/FIX) and healthcare (HL7 for EHRs).
IoT Sensor Data:
- Handles large volumes of IoT XML/JSON data by converting it into structured, relational tables for real-time analytics and anomaly detection.
- Ideal for smart factories (efficiency monitoring) and utilities (smart meter data analysis).
Insurance Platforms (Guidewire, Duck Creek etc.):
- Flexter automates XML data extraction from insurance platforms for compliance reporting, trend analysis, and unified operational views.
- Helps insurance companies analyse claims data, improve fraud detection, and enhance underwriting models.
Data Sharing:
- Automates XML-to-relational transformation for smooth data exchange between organizations, eliminating manual parsing and errors.
- Supports use cases like supply chain data sharing and financial transaction data exchange between banks and regulators.
XML Database Conversion:
- Migrates XML databases (e.g., MarkLogic, BaseX) into relational or analytical systems like Snowflake and Redshift with consistent and ready-to-use data.
- Useful for converting legacy databases and product catalogs for modern e-commerce platforms.
Government Systems:
- Transforms XML data for easier integration into analytical tools for public reporting, policy-making, and cross-agency collaboration.
- Supports use cases like IRS tax filings (Form 990) or benefits applications.
Why Choose Flexter – Customer Benefits and Advantages:
Scalability to Meet Your Needs and SLAs
- Handles Any Workload: Flexter scales both vertically and horizontally to meet your Service Level Agreements (SLAs) and performance benchmarks.
- Scale Vertically: Add more CPUs or vCores to boost performance.
- Scale Horizontally: Add servers or virtual machines to handle increasing workloads.
- Processes Large Datasets: Flexter can manage Terabytes of XML with ease.
Faster Time to Go Live
- Automated Conversion: Flexter fully automates XML conversion, eliminating the need for manual coding and lengthy development cycles.
- Accelerated Development: Shortens the development life cycle from weeks or months to just hours or days.
- Quicker Access to Data: Makes data immediately available for analysis and decision-making, enabling faster insights and better outcomes.
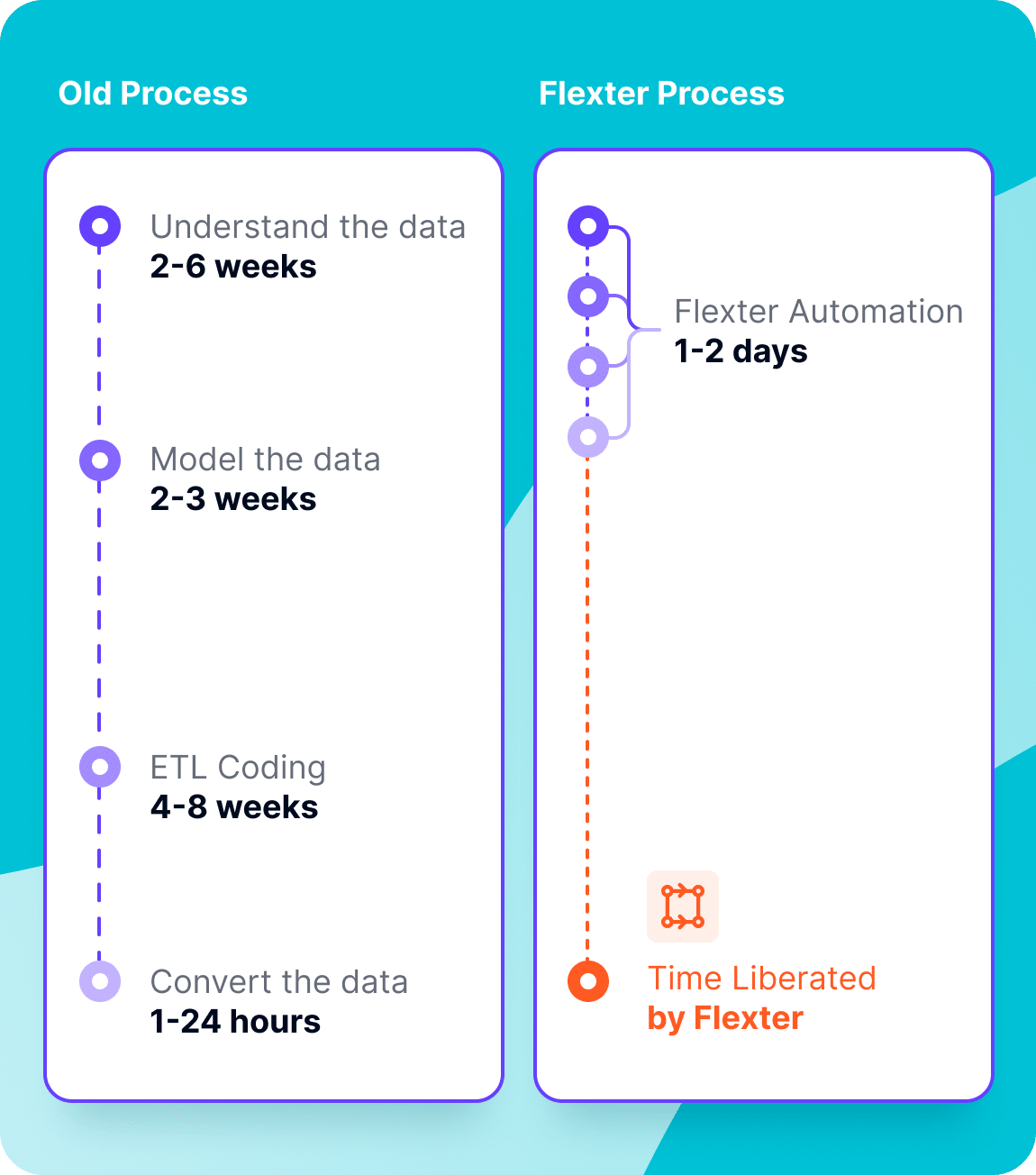
Eliminates Project Risks
- Proven Reliability: Manual XML conversion projects have a high failure rate—Flexter drastically reduces this risk.
- Based on industry experience, 50% of manual projects fail, and the rest often go over budget.
- Pilot or PoC Support: Flexter lets you run a quick pilot or proof of concept (PoC) in just a few days, demonstrating its reliability and minimizing project risks.
- Tested and Trusted: Years of testing and quality control ensure Flexter’s XML conversion process is robust and bug-free.
Boosts Productivity
- Frees Up Resources: Flexter automates repetitive data conversion tasks, allowing data engineers to focus on delivering insights and value to the business.
- Improves Morale: Simplifies the job for data engineers, reducing burnout and eliminating the need to learn outdated legacy skills.
- Enables Decision Making: By delivering data faster, Flexter supports critical business decisions with accurate and timely information.
Reduces Business Risk and Missed Opportunities
- Timely Data Access: Delays in accessing data can result in missed opportunities. Flexter ensures data is ready when you need it to make informed decisions.
- Supports Growth: By eliminating bottlenecks, Flexter helps you capitalize on opportunities and drive business growth.
Simplifies Refactoring and Schema Evolution
- Adapts to Change: Flexter semi-automates schema evolution, detecting changes during runtime or when new schema versions are released.
- Speeds Up Refactoring: Significantly reduces the time required to adapt to new data standards or modify implementations.
Customer quotes
“Prior to deploying Sonra Flexter, ecobee explored the possibility of coding a custom app that would allow them to parse the XML data. However, after several working sessions, it became clear that this route would be time-heavy and only serve to produce a temporary workaround – one that would likely delay the BigQuery migration.” – Monteil Lin , Director Business Intelligence, ecobee
“You did in one day what we could not do in 3 years”, VP Data Management, Aer Lingus
“This will save us weeks”, VP at a Bank
“To us, the sensor IoT data is a goldmine, and underpins any number of analytical use cases across a large number of functional areas. We very much look forward to exploring applications for this goldmine now that Flexter has unlocked it.” – Monteil Lin , Director Business Intelligence, ecobee
“Flexter is an amazing tool. It cut down my XML load from hours to minutes. It gets better. I didn’t even have to write a single line of code. I just fed Flexter my XML files, made some tea, and when I got back my data was ready to use in my analytics application”. Alexey Shchedrin, Enterprise Architect.
Differentiators
Flexter stands out among XML and JSON conversion tools by combining unparalleled automation, scalability, and versatility with robust features designed for modern data workflows. Unlike other solutions, Flexter fully automates complex tasks such as schema discovery, mapping, and documentation, significantly reducing manual effort and errors. Its integration with Apache Spark ensures exceptional scalability, allowing it to handle massive datasets and deeply nested structures without compromising performance. Additionally, Flexter supports a wide range of input and output formats, integrates seamlessly with modern data platforms like Snowflake and Databricks, and simplifies schema generation with advanced optimization algorithms. Flexter sets itself apart with its ability to automatically generate optimized, normalized schemas instead of simple flattened structures, a key differentiator from other XML and JSON conversion tools.
These differentiators make Flexter the go-to solution for organizations seeking to transform complex data into actionable insights efficiently.
Automation
- End-to-End Automation:
- Flexter fully automates the XML-to-relational conversion process, including schema discovery, mapping, and transformation, requiring minimal manual intervention.
- Dynamic Schema Handling:
- Flexter detects changes in XML schemas (XSDs) at runtime. Changes to schemas can be evolved semi-automatrically
- Auto-Generated Documentation:
- Automatically produces ER diagrams, source-to-target mappings, and data lineage reports, streamlining analysis and governance tasks.
Scalability
- Distributed Processing:
- Flexter leverages Apache Spark to process terabytes or even petabytes of XML data in a distributed manner, enabling high performance for enterprise-scale workloads.
- Horizontal and Vertical Scaling:
- Scales horizontally by adding nodes to the cluster or vertically by increasing compute resources on a single server.
Versatility
- Wide Data Compatibility:
- Handles any XML data, irrespective of the industry or data standard, without being tied to specific formats.
- Comprehensive Platform Support:
- Integrates with modern data platforms like Snowflake, Databricks, BigQuery, and traditional RDBMS (e.g., Oracle, SQL Server).
- Broad Output Formats:
- Supports open-source formats like Parquet, Delta Lake, Avro, and ORC for seamless compatibility with modern data ecosystems.
Normalized Schemas
- Relational Target Schema:
- Automatically generates normalized schemas with parent-child relationships, foreign keys, and referential integrity.
- Simplified and Optimised Schema Design:
- Optimizes the schema to reduce the number of tables and joins while retaining logical clarity, ensuring performance and usability.
- Dynamic Refactoring:
- Supports semi-automated schema evolution and refactoring, reducing the time and effort required to adjust to changes in data standards.
Optimisation Algorithms
- Performance-Tuned Parsing:
- Uses advanced algorithms to optimize the parsing and transformation of nested and hierarchical data structures.
- Minimized Query Complexity:
- Produces schemas that balance normalization and simplicity, reducing join complexity in downstream queries.
- Efficient Data Workflows:
- Ensures high-speed processing by leveraging in-memory computation and Spark’s distributed processing capabilities.
Metadata Management
- Centralized Metadata Catalog:
- Maintains source-to-target mappings, tracks schema versions, and auto-generates DDL and upgrade scripts for seamless change management.
- Version Comparison:
- Provides tools to identify and manage differences between schema versions, aiding in governance and impact analysis.
Integration and Workflow Support
- Pipeline Integration:
- Embeds into data pipelines using APIs, and CLI for automated workflows.
- Error Handling:
- Features robust error logging and handling, ensuring predictable and stable pipeline execution.
- Support for Data Governance:
- Automatically generates lineage reports and mappings, making it easy to integrate with governance frameworks.
Reliability and Business Continuity
- Proven in Production:
- Trusted by enterprises across finance, healthcare, travel, and insurance to handle mission-critical XML transformation tasks.
- Fault Tolerance:
- Built on Spark’s fault-tolerant architecture, ensuring reliable processing even under heavy workloads or node failures.
- Pilot-Ready:
- Supports quick pilots or proofs of concept, demonstrating reliability before full-scale deployment.
Comparing Flexter to ETL Tools
We often see companies using Flexter alongside general-purpose ETL tools, for example, where Flexter handles the conversion of XML and the ETL tool then manages downstream processing. The fundamental difference lies in their core design: a general ETL tool is a versatile toolkit for a wide array of data integration tasks, whereas Flexter is specifically engineered to automate the transformation of complex XML/JSON into tabular and relational formats.
For many companies grappling with complex XML/JSON, we’ve seen a significant shift by replacing traditional ETL tool processing with Flexter. The results can be dramatic. In one real-world example, processing time plummeted from a staggering 26 hours down to a mere 5 minutes. This kind of drastic improvement is a common outcome.
Another frequent challenge users face with ETL tools when dealing with intricate XML structures is outright failure. It’s not uncommon for these tools to simply crash when confronted with highly complex schemas.
Many ETL vendors advertise support for processing XML and JSON, but in reality, this is often little more than a checkbox feature. What they typically offer is a graphical interface that allows users to build mappings and transformations visually, rather than through code. While this may seem user-friendly, the process remains largely manual and can become cumbersome for complex data structures. In many cases, writing a few lines of code to handle the transformation is not only more flexible, but also significantly faster and more maintainable than clicking through a series of UI elements in an ETL tool. The visual approach may suit simple use cases, but it quickly falls short when dealing with deeply nested or irregular data formats like XML and JSON.
Here are the potential downsides of using a general ETL tool (like Talend) for XML conversion compared to Flexter:
Significant Manual Effort and Development Time:
- General ETL Tool: Frequently demands that developers manually define schemas, map XML/JSON elements and attributes to target structures (such as database tables or flat files), and visually construct the transformation logic. This process can be particularly time-consuming and labor-intensive for intricate XML/JSON with deep nesting, multiple hierarchies, or inconsistent structures.
- Flexter: Is designed to automate schema discovery and the generation of the target relational schema and the associated loading processes. This automation eliminates the manual development time typically required.
Difficulty Handling Complex and Evolving Schemas:
- General ETL Tool : While capable of processing simple XML/JSON, managing highly complex, deeply nested, or polymorphic structures (where elements can have varying structures) can become very complicated. Furthermore, when the XML/JSON schema evolves over time, manual updates to the ETL jobs are often necessary, which can be cumbersome and prone to errors.
- Flexter: Is specifically architected to automatically parse complex XML/JSON structures and is much better equipped to handle schema drift or variations without requiring extensive manual reconfiguration. It analyzes the data itself at runtime to check for changes, rather than solely relying on a predefined schema that might become outdated.
Performance Bottlenecks:
- General ETL Tool : Processing very large XML/JSON files or a high volume of documents within a general ETL framework is not as performant as using a tool purpose-built for XML/JSON parsing and conversion. Managing memory and ensuring processing efficiency for navigating complex node structures can present challenges.
- Flexter: Is optimized for high-speed parsing and processing of large and complex XML/JSON files, often surpassing the performance of general-purpose tools for this specific task. Flexter is designed to scale both vertically and horizontally, capable of processing terabytes of XML or JSON data.
Maintenance Overhead:
- General ETL Tool : Manually built XML/JSON processing jobs can become intricate and challenging to maintain, debug, or modify, especially if the original developer is no longer available. Understanding the detailed mappings and logic can be difficult.
- Flexter: By automating the conversion process, the resulting logic is generated consistently. While understanding the output schema is still necessary, maintaining the conversion process itself can be simpler as it requires less manual intervention for standard operations. Mapping documents are created automatically.
Steeper Learning Curve for Complex XML/JSON:
- General ETL Tool : While the graphical interface of many ETL tools is generally user-friendly, mastering the specific components for XML/JSON processing and effectively configuring them for non-trivial structures demands significant learning and specialized expertise.
- Flexter: The primary focus is on automation. The learning curve is more about understanding how Flexter interprets the XML/JSON and generates the output, rather than manually constructing the parsing logic from scratch.
Less Specialized XML/JSON Features:
- General ETL Tool : As a versatile tool, its XML/JSON capabilities are broad but might lack some of the highly specialized optimizations or algorithms found in a dedicated tool designed solely to maximize XML/JSON conversion efficiency and accuracy.
- Flexter: Its entire focus is on XML/JSON conversion, often outperforming general tools with specific features and performance optimizations tailored to these data formats.
Automated Documentation:
- Flexter: Automatically generates critical documentation as a direct result of its conversion process, including an Entity-Relationship (ER) diagram visualizing the relational target schema it creates and a detailed source-to-target mapping document illustrating precisely how source XML/JSON elements are mapped to target database columns.
- General ETL Tool : Typically does not automatically generate these specific artifacts in the same way. While mappings are often visually defined and job documentation can be exported, obtaining a distinct ER diagram of the resulting schema often necessitates external database tools or manual design, and producing a concise, standalone source-to-target mapping document usually requires manual documentation effort.
Optimization Algorithms:
- Flexter: Employs automated, built-in algorithms that analyze source XML/XSD structures to automatically simplify the target relational schema—flattening unnecessary nesting and consolidating re-used types into single tables with minimal user configuration.
- General ETL Tool : Achieving similar schema simplification typically requires significant manual effort: a developer must first manually identify these structural patterns, then manually design the optimized target schema, and finally implement potentially complex mapping logic to manually flatten the hierarchy or consolidate data from re-used types.
In Summary:
Using a general ETL tool for XML/JSON conversion is certainly feasible and suitable for simpler structures or when XML/JSON processing is just one component of a broader, diverse ETL workflow. However, when compared to a specialized tool like Flexter, the drawbacks for complex, large-scale, or rapidly evolving XML/JSON conversion tasks often include:
- Increased manual development time and effort.
- Greater difficulty and potential performance limitations with complex or large files.
- Higher maintenance overhead for manually constructed jobs.
- Challenges in automatically adapting to schema changes.
The optimal choice depends on the specific requirements: if you need a versatile tool for numerous different ETL tasks and your XML/JSON needs are relatively straightforward, a general ETL tool might suffice. If your primary challenge is efficiently and automatically converting large volumes of complex XML/JSON data, a specialized tool like Flexter is likely to provide significant advantages in speed, automation, and the ability to handle complexity.
FAQ
General Concepts & Overview
What is Sonra’s Flexter in simple terms?
Flexter is an automated software tool that reads complex semi-structured files (like XML or JSON) and converts them into simple, structured tables suitable for databases, data warehouses, and analytics tools, without needing manual coding.
What is the core problem Flexter is designed to solve?
It solves the slowness, high cost, complexity, and error-prone nature of manually writing code or using traditional ETL tools to parse and process deeply nested data structures from sources like XML, JSON, and industry-specific formats.
Who is the target audience for Flexter?
Primarily Data Engineers, ETL Developers, Data Architects, and Data Analysts/Scientists who need to ingest, process, and analyze complex data sources. It’s also relevant for IT Managers looking to improve data pipeline efficiency and reduce development costs.
What makes Flexter different from standard ETL/ELT tools?
While standard ETL tools often have basic XML/JSON capabilities, Flexter is purpose-built and highly optimized for the complexity and scale of semi-structured data. It automates schema detection, mapping, and parallel processing for these specific formats far more effectively and rapidly.
Is Flexter a No-Code or Low-Code solution?
Flexter is fundamentally a No-Code solution for the core task of parsing and transforming complex XML and JSON data. It automatically generates the required logic. While integration points might involve configuration or light scripting (e.g., orchestration), the central data conversion requires no coding.
What’s the “elevator pitch” for Flexter?
“Flexter automatically converts your complex XML, JSON, and industry-standard data into analysis-ready tables up to 100x faster than manual coding, saving significant time, cost, and effort while unlocking valuable insights.”
Technical Deep Dive – How Flexter Works
How does Flexter handle extremely large individual files (e.g., single XML/JSON files of many Gigabytes)?
Yes, Flexter is specifically architected to handle very large individual files that might overwhelm standard parsers or consume excessive memory. It achieves this through techniques such as:
Streaming Processing: Reading and processing the file in manageable chunks rather than loading the entire file into memory at once.
Optimized Memory Management: Efficiently handling the data structures generated during parsing.
How does Flexter handle processing massive data volumes (e.g., millions of smaller files)?
Flexter excels at processing large volumes of data, which might consist of millions or billions of smaller files.
Horizontal Scalability: Flexter can be deployed across multiple nodes or cores.
Distributed Workload: It automatically distributes the processing of individual files across the available resources, allowing many files to be parsed and transformed concurrently.
High Throughput: This parallel execution enables high data throughput, making it suitable for large batch processing scenarios or ingesting significant amounts of data regularly. So, whether it’s one massive file or millions of smaller ones constituting a large total volume, Flexter’s scalable design is built to handle the load efficiently.
How does Flexter handle schema detection? Does it require an XSD or schema file?
Flexter can work in multiple ways:
* It can infer the schema by sampling or reading the input data directly.
* It can utilize provided XSD (for XML), JSON Schema, or other schema definition files for a more precise understanding of the structure and data types. Using a schema is often recommended for highly complex or strictly defined formats.
How does Flexter handle schema evolution or drift (changes in source format)?
This is a key feature. Flexter can automatically detect and adapt to changes in the source schema between files or batches, preventing pipeline failures and reducing manual maintenance.
Can Flexter handle data type conversions automatically?
Yes, during the transformation process, Flexter intelligently converts data types from the source (e.g., strings, numbers in XML/JSON) into appropriate target data types suitable for relational databases or data lakes (e.g., VARCHAR, INTEGER, FLOAT, TIMESTAMP).
Does Flexter have a graphical user interface (UI)?
Flexter has a web based UI
Can the transformation logic be customized if needed?
While the core parsing is automated, Flexter often provides hooks or configuration options to customize certain aspects, such as renaming columns, handling specific data cleansing rules, or applying simple transformations post-parsing.
How does Flexter scale? (Horizontally/Vertically)
Flexter is typically designed to scale both vertically (using more resources on a single node) and horizontally (distributing the workload across multiple nodes in a cluster) to handle increasing data volumes and velocity.
What are the typical resource requirements (CPU, Memory, Disk)?
Resource requirements depend heavily on the data volume, complexity, desired throughput, and deployment model. Sonra provides guidance based on specific customer scenarios during evaluation or implementation.
How does Flexter handle errors or malformed data in source files?
Flexter usually provides robust error handling capabilities, allowing configuration of how to manage bad records or files (e.g., skip, quarantine, log errors) without halting the entire process.
Data Format & Processing Capabilities
What specific complex XML structures can Flexter handle (e.g., recursion, deeply nested elements)?
Flexter is designed to handle virtually any valid XML complexity, including deeply nested structures, recursive elements, namespaces, mixed content, and complex relationships.
What about complex JSON structures (nested arrays, objects)?
Similarly, Flexter efficiently processes complex JSON, including deeply nested objects, arrays of objects, arrays within arrays, and variations in structure between records.
Does Flexter support industry-specific standards like HL7 v2, FHIR, FpML, ISO 20022 out-of-the-box?
Yes, Flexter handles any XML or XSD as it fully supports the XSD specification.
Can Flexter process formats like Avro, Parquet, or ORC as input?
Yes, Flexter can typically ingest data from these common Big Data formats, especially when they contain embedded complex structures (like JSON strings within a Parquet field).
How does Flexter output relational data? Does it maintain relationships?
Flexter intelligently flattens the hierarchical structure into a set of normalised and related tables. It automatically generates primary keys and foreign keys to maintain the relationships present in the source data, making it easy to query using SQL.
Can Flexter selectively parse only certain elements or fields from a large file?
Yes, users can typically configure Flexter to target and process only specific sections or elements within complex files, ignoring others, which can improve performance and reduce noise in the output.
How does Flexter handle different character encodings (e.g., UTF-8, ISO-8859-1)?
Flexter is designed to detect or be configured for various character encodings to ensure accurate data interpretation and prevent data corruption during processing.
Can Flexter assist with data masking or anonymization during processing?
Sonra provides Paranoid. Paranoid is an open source data masking and obfuscation command line tool for XML and JSON file formats. Paranoid is best used in combination with Flexter.
Deployment, Integration, and Security
What are the requirements for an on-premise deployment?
On-premise deployment usually involves installing Flexter software on Linux servers meeting specified CPU, RAM, and disk requirements..
Does Flexter offer an API for programmatic control and integration?
Yes, Flexter provides APIs (often RESTful) allowing developers to start jobs, monitor progress, manage configurations, and integrate Flexter processing into larger automated workflows.
How can Flexter be integrated with workflow orchestration tools like Apache Airflow or Azure Data Factory?
Integration is usually achieved via Flexter’s API or CLI, allowing orchestrators to trigger Flexter jobs as a step within a larger data pipeline.
Does Flexter integrate with data catalog tools?
Integration involves Flexter writing metadata such as mappings and the processed source and target schemas, which data catalog tools can then ingest.
How is security handled? (Authentication, Data Encryption)
Flexter deployments incorporate security best practices. This typically includes:
* Secure authentication methods for accessing UI/APIs.
* Support for encrypted communication (SSL/TLS).
* Secure handling of credentials for connecting to source/target systems.
* Compatibility with data encryption at rest in target storage/databases.
Use Cases & Industries
What are some specific examples of Flexter use cases in Finance?
Processing FpML for derivatives trading, parsing ISO 20022 payment messages (pacs, camt), handling FIX protocol messages, onboarding client data in complex XML formats.
What are specific examples in Healthcare?
Parsing HL7 v2 messages (ADT, ORU, etc.), processing HL7 CDA documents, converting FHIR resources (JSON/XML) for analytics, integrating data from medical devices.
Can Flexter be used for data migration projects?
Absolutely. When migrating systems where data is archived or exported in complex XML/JSON formats, Flexter can be invaluable for transforming that data into a structure suitable for the new target system.
How does Flexter help with feeding data warehouses or data lakes?
It acts as a crucial “first mile” ETL component, taking raw, complex source data and transforming it into clean, structured formats (like Parquet in a data lake or relational tables for a warehouse staging area) that downstream processes can easily consume.
Can Flexter enable more real-time analytics?
By drastically reducing the time it takes to process complex data batches, Flexter enables faster data availability, moving organizations closer to near real-time insights compared to slow manual processes.
Licensing, Support, and Getting Started
How is Flexter typically licensed? (e.g., per core, data volume, subscription)
Flexter is an annual licensing model including support. Contact Sonra for specifics.
Are there different editions or tiers of Flexter?
Sonra offers different editions (Free online versions, Enterprise) with varying features, scalability, and support levels tailored to different organizational needs.
Is there a free trial or Proof of Concept (PoC) option available?
Sonra typically offers evaluation options, including personalized demos and Proof of Concept (PoC) engagements, allowing potential customers to test Flexter with their own data and use cases.
What kind of customer support and maintenance is available?
Sonra usually provides standard and premium support packages, offering technical assistance, software updates, and maintenance releases. Service Level Agreements (SLAs) often differ based on the support tier.
Is training available for users?
Yes, Sonra offers training resources, which include documentation, webinars, or dedicated training sessions to help users get the most out of Flexter.
What does a typical Flexter implementation project involve?
Implementation usually involves understanding the source data and target requirements, installing/configuring Flexter, running initial processing jobs, validating the output, and integrating Flexter into the broader data workflow. Sonra provides professional services to assist.
What’s the best way to get started with Flexter?
Contact Sonra directly through their website (https://www.sonra.io/ – Assumed link) to request a demo, discuss your specific use case, and explore evaluation options like a PoC.
Free Online Flexter Tools
Does Sonra offer completely free online versions of Flexter?
Yes, Sonra offers completely free online versions of Flexter. These are typically referred to as “Flexter Online” and include:
- Free Online XML to CSV/TSV Converter: This tool allows you to upload and convert XML files (up to 1MB in the free version) into CSV or TSV formats directly through your web browser. You can learn how to use it in our guide: Flexter XML to CSV/TSV Converter Online.
- Free Online XML to Database Converter: This tool enables you to convert and load XML data into a database. Similar to the CSV converter, this is a free online tool accessible via the Sonra website. You can find more details and guidance in our Flexter XML to SQL Guide.
What are the main limitations of the free online Flexter tools?
The file size is capped at 1MB maximum per upload (compressed ZIP files). This is 10-30MB uncompressed.
What tasks can I perform with the free online tools?
You can upload XML files (with optional XSD schema support) and convert them into normalized, related CSV/TSV files or load them directly into a database environment (Snowflake) for online querying). We also generate helpful metadata like Entity-Relationship (ER) diagrams and source-to-target mapping documentation.
How do I use the free online Flexter tools?
You typically navigate to the specific tool’s page on the Sonra website, upload your XML file (drag-and-drop or browse), optionally upload an accompanying XSD, accept the terms, and provide your email address. A secure link to access your converted data/results is then sent to your email.
Do the free tools just flatten XML into one big table?
No, a key feature is that Flexter Online performs normalization. It intelligently converts the hierarchical XML structure into multiple, related tables (whether in CSV/TSV or database format), maintaining relationships and avoiding the limitations of flattening everything into a single large table (OBT).
Can I process HL7, or other complex formats with the free tools?
Yes, as long as you stay below the upload limit..
How do these free tools differ from a Flexter Enterprise trial or PoC?
The free online tools offer limited, specific functionality (XML to CSV/Snowflake database up to 1MB) available perpetually online. A Flexter Enterprise trial or Proof of Concept (PoC) involves a time-limited evaluation of the full, scalable enterprise software with all its features, format support, deployment options, and support, typically arranged by contacting Sonra’s sales team.
What kind of support is available for the free online tools?
Free support via email or website chat is available. However, response times might be longer (up to 1-2 business days) compared to the dedicated support SLAs provided with commercial licenses of Flexter Enterprise.
Flexter Capability Sheet
|
Category |
Feature |
Free Flexter |
Enterprise Flexter |
|---|---|---|---|
|
Data |
Data volume |
Up to 1MB |
Any |
|
Overwrite |
– |
✓ | |
|
Append |
– |
✓ | |
|
Access |
API |
– |
✓ |
|
Command Line |
– |
✓ | |
|
WebUI |
✓ |
✓ | |
|
Formats (Input) |
XML |
✓ |
✓ |
|
JSON |
✓ |
✓ | |
|
TSV, CSV, PSV etc. |
– |
✓ | |
|
RDBMS |
– |
✓ | |
|
Databases (Output) |
Snowflake |
– |
✓ |
|
Oracle |
– |
✓ | |
|
MySQL |
– |
✓ | |
|
PostgreSQL |
– |
✓ | |
|
Teradata |
– |
✓ | |
|
Redshift |
– |
✓ | |
|
MS SQL Server |
– |
✓ | |
|
Azure SQL Data Warehouse |
– |
✓ | |
|
Yellowbrick |
– |
✓ | |
|
BigQuery |
– |
✓ | |
|
Databricks |
– |
✓ | |
|
AWS Athena |
– |
✓ | |
|
Query Engines (Output) |
Hive |
– |
✓ |
|
Impala |
– |
✓ | |
|
File Formats (Output) |
CSV, TSV, PSV etc. |
✓ |
✓ |
|
Excel |
– |
✓ | |
|
ORC |
– |
✓ | |
|
Parquet |
– |
✓ | |
|
Avro |
– |
✓ | |
|
Delta Tables |
– |
✓ | |
|
Automation |
Target schema |
– |
✓ |
|
Mappings |
– |
✓ | |
|
Parent-child relationships |
– |
✓ | |
|
Conversion |
– |
✓ | |
|
Documentation |
– |
✓ | |
|
Optimization Algorithms |
Elevate |
– |
✓ |
|
Reuse (XSD only) |
– |
✓ | |
|
Naming |
– |
✓ | |
|
Schema Generation |
JSON sample |
✓ |
✓ |
|
XML sample |
✓ |
✓ | |
|
XSD |
✓ |
✓ | |
|
XSD + XML sample |
– |
✓ | |
|
Database |
– |
✓ | |
|
Text |
– |
✓ | |
|
Sources |
FTP, SFTP |
– |
✓ |
|
Object storage (S3, ADLS, Azure Blob etc.) |
– |
✓ | |
|
HTTP(S) |
– |
✓ | |
|
HDFS |
– |
✓ | |
|
Network drive |
– |
✓ | |
|
Local file system |
✓ |
✓ | |
|
Upload |
✓ |
✓ | |
|
Change Intelligence and Management |
Metadata Catalog |
– |
✓ |
|
Schema version diff |
– |
✓ | |
|
Schema evolution |
– |
✓ | |
|
Data lineage |
– |
✓ | |
|
ER diagram |
– |
✓ | |
|
Platforms |
Virtual Machine / Server |
✓ |
✓ |
|
Kubernetes |
– |
✓ | |
|
Databricks |
– |
✓ | |
|
Spark |
– |
✓ | |
|
Location |
Google Cloud (GCP) |
– |
✓ |
|
AWS |
– |
✓ | |
|
Azure |
– |
✓ | |
|
On-premise |
✓ |
✓ | |
|
Support |
|
✓ |
✓ |
|
Phone |
– |
✓ | |
|
Requirements |
– |
✓ |




