Converting XML and JSON to a Data Lake

Data lakes are a popular design pattern in data analytics. A data lake is used to store a copy of data coming from operational source systems such as relational databases.
If you’re also working with JSON on modern data platforms and need step-by-step guidance on reading, parsing, querying and flattening it before landing it in a lake, see our Databricks JSON Guide Read Parse Query and Flatten Data.
You can choose from dozens of tools to populate a data lake from relational and structured data sources. However, it gets tricky when you want to store and query XML and JSON documents in the data lake. Often your only choice is to write your own XML / JSON parser. This is not a trivial exercise as this quote from Ralph Kimball shows:
“Because of such inherent complexity, never plan on writing your own XML processing interface to parse XML documents.
The structure of an XML document is quite involved, and the construction of an XML parser is a project in itself—not to be attempted by the data warehouse team.”
While this quote from the father of dimensional data warehousing was made in the context of the data warehouse, the same applies to the data lake.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
The trouble with XML / JSON conversion projects for data lakes
XML conversion projects are well known for their high failure rates. They either run over time and budget or fail completely. To a lesser extent this also applies to JSON as JSON documents tend to be less complex than XML.
We typically see a combination of the following issues:
- Lack of skills. Data analysts and data engineers are good at working with structured data in databases using SQL. They don’t have the niche skills such as XSLT, XSD, XQuery to unlock the data from XML or JSON.
- The lack of skills delays projects or even leads to a complete failure of the project as poorly designed and implemented solutions are developed.
- Projects need to go through a lengthy and complex development process taking weeks or months. We have seen some projects taking more than a year with several failed attempts. The result is that data is not available to decision makers.
- Using an ETL tool still requires a significant development effort. These tools can handle simple XML/JSON documents but fail when things get more complex.
- The lack of skills leads to solutions that don’t scale well. We have seen ETL processes running for 24+ hours to convert 50,000 XML documents.
- Once everything has been deployed after weeks, months, or years a new version of an XML or JSON Schema has been released and the whole process of refactoring and reengineering has to be applied.
Automated conversion of XML / JSON to data lakes
We have experienced all of these issues ourselves in dozens of data lake and data warehouse implementations. We thought to ourselves: “There must be a better way”. Hence we created Flexter. Flexter is an automation solution for converting XML and JSON documents to data lakes on AWS (S3), Azure (Data Lake Storage Gen2), and GCP (Cloud Storage).
Using Flexter you can automatically convert your XML / JSON documents on a data lake to Parquet, ORC, Avro, CSV, TSV, PSV on cloud object storage and then consume the data downstream, e.g. in a data warehouse such as Snowflake or a query engine such as Athena etc.
The best thing is, everything happens automagically. You don’t have to go through a lengthy conversion project and risk project delays and failures. Install and configure Flexter and instantly start converting XML and JSON to a relational format.
Flexter can handle any data volume or complexity. You can scale up or scale out to a cluster of nodes to distribute your workload for Terabytes or even Petabytes of XML/JSON documents.
With Flexter’s metadata catalog you can even semi-automate the upgrade process from different versions of your schema. Identify the changes and then auto generate scripts to upgrade your target schema.
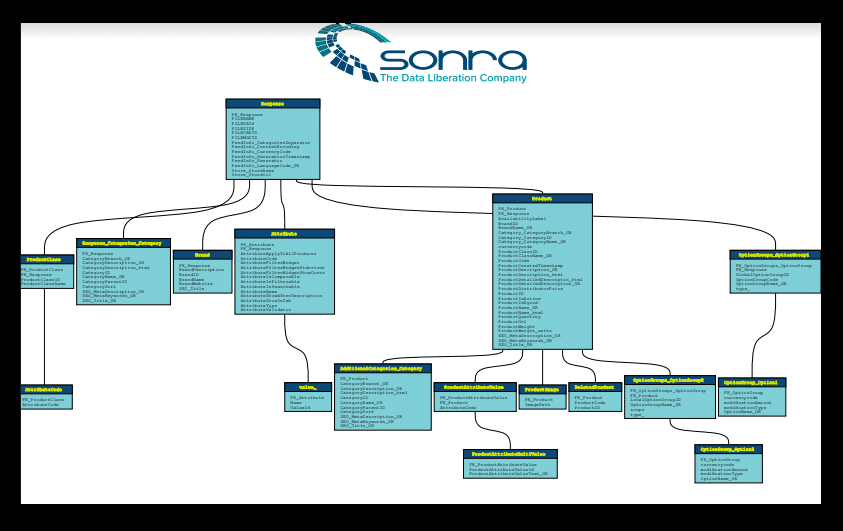
Convert any XML to a data lake on S3, Data Lake Gen2 or Google Cloud Storage
Flexter works with any volume of data using a simple three-step process:
| Image | Step |
|---|---|

|
In a rapid, one-time operation, we scan and traverse XML/JSON documents for information and intelligence. |
 | Step 2
We create a logical target schema and the mappings between XML/JSON elements and the database tables and columns. |
| |

|
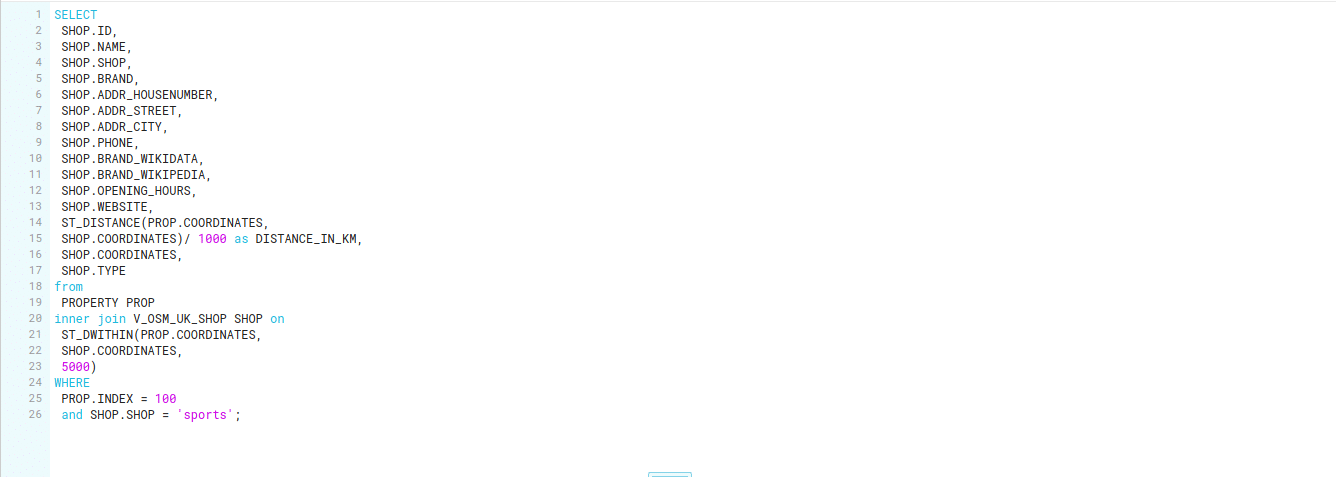
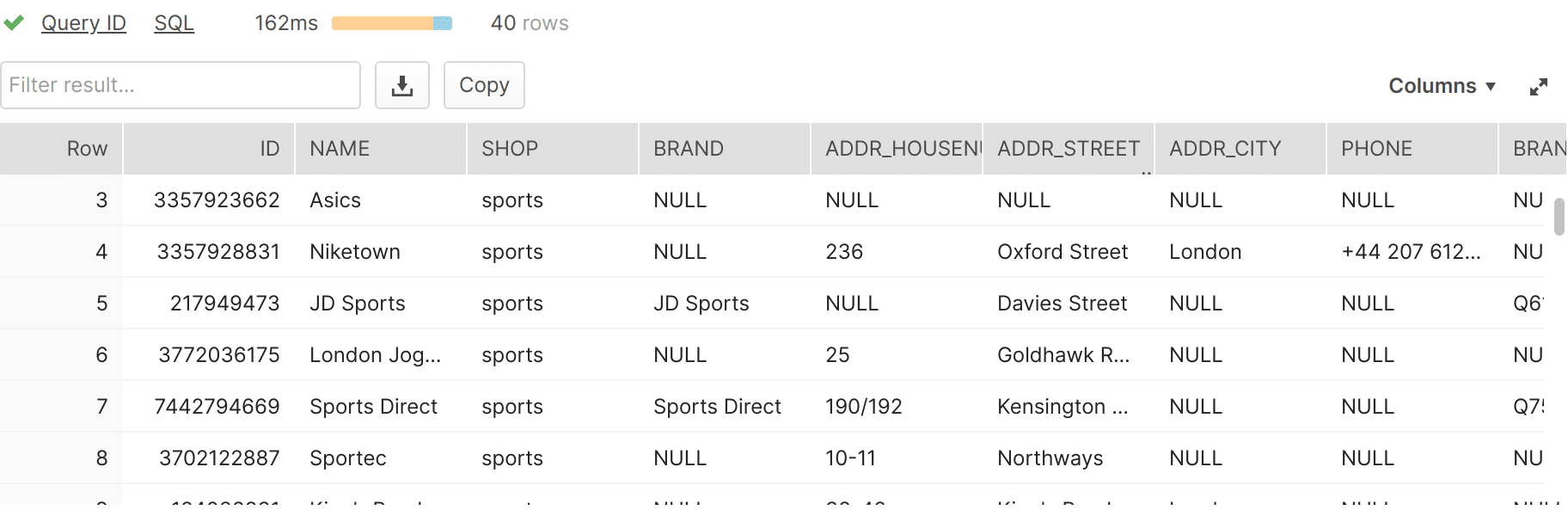
Step 3 We process and convert the XML/JSON documents each time new data arrives. |
| |
This produces guaranteed, high-quality results that remove the uncertainty and inaccuracy from laborious manual processes that may never provide the results you’re looking for.
Conclusion
Converting XML to a readable format is easy with Flexter. It is a fully automated and optimised process.
We would like to find out more about your use case. Contact us or book a demo and tell us about your challenges of working with XML and JSON.
You can find out more about Flexter by visiting the Flexter product page or the Flexter data sheet.
You can download our XML conversion checklist The 6 Factors You Need to Get Right to Make Your XML Conversion Project a Success
Read a case study how ecobee uses Flexter to convert XML to BigQuery
You can book a demo if you are interested in Flexter.
Last but not least we would like to find out more about your use case. Contact us and tell us about your challenges of working with XML.



