How to do full text search with Snowflake, Inverted Indexes and Snowpark

Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Inverted Index
An Inverted Index is a data structure used to support full text search over a set of documents.
An inverted index is very similar to an index at the end of a book. In the book index you get an alphabetically sorted list of the core keywords with a list of pages where the keyword occurs.
Some databases such as PostgreSQL ship with dedicated features to create an inverted index for full text search. Other databases such as Snowflake do not (yet) have such a feature (even though Snowflake recently improved string matching by a factor of 2x) . For those databases without full text search we can build our own inverted index and this blog post will show you how it is done in true DIY fashion.
We create our own inverted index by taking a table column with a lot of text and apply various text analytics techniques such as stop word removal, stemming etc.
The result is a new table with one entry per word/term for all the text documents processed, along with a list of the key pairs: document id and frequency of the term in the document (how many times does the term appear in the doc).
In this example we will use Snowpark. Snowpark ships with Snowflake to create custom UDFs in Python, Scala, or Java.
FlowForward.
All Things Data Engineering
Straight to Your Inbox!
LIKE ‘%phrase%’ anti pattern. When should you use an inverted index?
When would you use or create an inverted index? Like with most scenarios the answer is: It depends. For small data volumes and infrequent access you should use the LIKE operator or for more complex pattern matching scenarios the REGEX operator.
If you store large text data volumes and require concurrent access by many users an inverted index might be a good fit. In particular if you experience slow query performance and a general performance degradation of the database when users run full text searches with LIKE or REGEX.
It is important to understand your search requirements before building an inverted index, e.g. for defining the rules for data cleansing, stemming, stop word removal etc. as part of the build process of the inverted index.
You will also need to take into account that building and maintaining an inverted index comes at a cost, e.g. each time you add a new document you need to also update your index.
For complex requirements it is better to rely on a dedicated text search engine such as Apache Solr instead of building your own inverted index. Some database vendors also offer full text search as a feature. Under the hood these RDBMS build their own inverted index.
How is an inverted index constructed
Let’s imagine we have two documents with different texts:
- A car is a great automobile, I like cars.
- Cars are bad for the environment.
In order to create the Inverted Index, each text is sliced into different units or terms. The rule is to use whitespace as the natural separator between words, even though this can be changed.
Additionally, per each term there is a list of pairs (document id, frequency), showing the document’s ID where the term is found, and the number of times the term appears in the text.
Therefore, the Inverted Index after processing the previous two documents would be:
| Term | Appearances (DocId, Frequency) |
|---|---|
| automobile | (1,1) |
| bad | (2,1) |
| car | (1,2) (2,1) |
| environment | (2,1) |
| great | (1,1) |
| like | (1,1) |
How do you detect the anti pattern?
You will need to identify SQL statements that use the LIKE operator or Regular Expressions to apply free text search.
Most databases log the history of SQL statements that were run in an information schema. You can use our product FlowHigh to parse the SQL and identify those queries that use LIKE and REGEX operations and the tables and columns that they use for filtering and free text search. Those columns that are queried frequently and have performance problems become candidates for an inverted index.
With FlowHigh you can parse, visualise, optimise, and format SQL. You can also detect SQL anti patterns that violate SQL best practices such as self joins, implicit cross joins etc.
Performance of an inverted index
How does the performance of an inverted index compare to using a LIKE operator. Let’s return to our example about the book index. Using the LIKE operator is similar to reading / scanning the entire book end to end instead of looking up the index at the end of the book to find the pages for a keyword.
When you use the LIKE operator the database needs to read all of the records from the database table column that contains the free text (full table scan). Free text can be large, does not compress well and storage indexes or sort keys do not work either (there are some edge scenarios). So using the LIKE operator will require a lot of table scanning and network traffic. The LIKE operation is also very CPU intensive as it needs to match the string of the search term against the full text. There are various algorithms that help to do this but nevertheless this is an expensive operation.
Nothing in life is free and an inverted index also comes at a cost. It needs to be updated each time you add a new document. For scenarios where you don’t have a near real time requirement you can update the inverted index as part of a batch process.
Creating an inverted index on Snowflake
Let’s see how an inverted index can be built on Snowflake using Snowpark.
The starting point is to create a snowpark session.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from snowflake.snowpark import Session connection_parameters = { "account" : "******" ,"user": "******" ,"password": "******" ,"role": "******" ,"warehouse": "******" ,"database": "******" ,"schema": "******" } session = Session.builder.configs(connection_parameters).create() |
Now create the functions required for creating the inverted index. Firstly, the function for tokenizing text.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
def tokenize(text) -> list: from nltk.corpus import stopwords from nltk.stem import WordNetLemmatizer,SnowballStemmer import unicodedata2 import regex as re #https://godatadriven.com/blog/handling-encoding-issues-with-unicode-normalisation-in-python/ #Normalisation Form Compatibility Decomposition text = unicodedata2.normalize('NFKD', text).encode('ascii', 'ignore').decode('utf-8', 'ignore') text = text.lower() #Sustitute 's, email address, website address, html tags and new line with a space cleansed1 = re.sub(r"'s\b|\w+@\w+\.\w+|\w+://\S+|<[^<]+?>|'[\n\r]'", ' ', text) #Substitute all unwanted special characters with a space cleansed2 = re.sub("[^A-Za-z' ]+", ' ', cleansed1) #Substitute apostrophe at beginning and end of words, roman numerals and onewords with a space cleansed3 = re.sub(r"(?<=\s)\'+(?=\w*)|(?<=\S)\'+(?=\s+)|(?<=\s)[ivxlcdm]+(?=\s)|(?<=\s)\w(?=\s)|^\w(?=\s)|(?<=\s)\w$", ' ', cleansed2) #Remove all the remaining apostrophe cleansed4 = re.sub(r"\'",'',cleansed3) #Split the text into tokens words = list(cleansed4.split()) #Correction = [word.replace("'d","ed") if word[-2:] == "'d" else word for word in words] #Lemmatization using nltk WordNetLemmatizer # Create an instance WordnetLemmatizer which is used for lemmatizing words wordnet_lemmatizer = WordNetLemmatizer() lemmatized =[ wordnet_lemmatizer.lemmatize(word, pos = "n") if word != wordnet_lemmatizer.lemmatize(word, pos ="n") else wordnet_lemmatizer.lemmatize(word, pos ="a") if word != wordnet_lemmatizer.lemmatize(word, pos = "a") else wordnet_lemmatizer.lemmatize(word, pos ="v") if word != wordnet_lemmatizer.lemmatize(word, pos = "v") else wordnet_lemmatizer.lemmatize(word, pos ="r") if word != wordnet_lemmatizer.lemmatize(word, pos = "r") else wordnet_lemmatizer.lemmatize(word, pos ="s") if word != wordnet_lemmatizer.lemmatize(word, pos = "s") else wordnet_lemmatizer.lemmatize(word) for word in words ] #Stemming using nltk SnowballStemmer # Create a new instance of a English language specific subclass of SnowballStemmer which is used for stemming the words snowball_stemmer = SnowballStemmer('english', ignore_stopwords=True) stemmed = [snowball_stemmer.stem(word) for word in lemmatized] #Removing stopwords using nltk stopwords stopword = stopwords.words('english') normalized_tokens = [word for word in lemmatized if word not in stopword] return normalized_tokens |
Here a list of the terms built from the text field. These are known as tokens. The steps involved in constructing the text tokens are described below.
Normalise Data
Unicode Normalisation converts alphabetical Unicode glyphs to their nearest equivalent characters.
Few examples are as given below:
| 𝕔𝕠𝕞𝕡𝕝𝕖𝕥𝕖𝕝𝕪 𝕦𝕟𝕣𝕖𝕒𝕕𝕒𝕓𝕝𝕖 | → completely unreadable |
|---|---|
| Ç, é, Å | → C, e, A |
| ℌ | → H |
| Xⱼ | → x |
| ½ | → 12 |
|
1 2 3 |
import unicodedata2 text = unicodedata2.normalize('NFKD', text).encode('ascii', 'ignore').decode('utf-8', 'ignore') |
Cleansing
Cleanses the document by removing the following
- Apostrophe s (‘s)
- Email addresses
- Website addresses
- Html tags
- New lines
- Special characters
- Roman numerals
- One words
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import regex as re #Sustitute 's, email address, website address, html tags and new line with a space cleansed1 = re.sub(r"'s\b|\w+@\w+\.\w+|\w+://\S+|<[^<]+?>|'[\n\r]'", ' ', text) #Substitute all unwanted special characters with a space cleansed2 = re.sub("[^A-Za-z' ]+", ' ', cleansed1) #Substitute apostrophe at beginning and end of words, roman numerals and onewords with a space cleansed3 = re.sub(r"(?<=\s)\'+(?=\w*)|(?<=\S)\'+(?=\s+)|(?<=\s)[ivxlcdm]+(?=\s)|(?<=\s)\w(?=\s)|^\w(?=\s)|(?<=\s)\w$", ' ', cleansed2) #Remove all the remaining apostrophe cleansed4 = re.sub(r"\'",'',cleansed3) |
Splitting text into words
The document text is made into a list of words by using whitespace as the separator.
|
1 2 |
#Split the text into tokens words = list(cleansed4.split()) |
Lemmatization
Lemmatization is the process of grouping together the different inflected forms of a word so they can be analysed as a single item. Lemmatization is similar to stemming but it brings context to the words. So it links words with similar meanings to one word.
Examples of lemmatization:
|
1 2 3 |
-> rocks : rock -> corpora : corpus -> better : good |
One major difference with stemming is that lemmatize takes a part of speech parameter, “pos” If not supplied, the default is “noun.”
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from nltk.stem import WordNetLemmatizer,SnowballStemmer #Lemmatization using nltk WordNetLemmatizer # Create an instance WordnetLemmatizer which is used for lemmatizing words wordnet_lemmatizer = WordNetLemmatizer() lemmatized =[ wordnet_lemmatizer.lemmatize(word, pos = "n") if word != wordnet_lemmatizer.lemmatize(word, pos ="n") else wordnet_lemmatizer.lemmatize(word, pos ="a") if word != wordnet_lemmatizer.lemmatize(word, pos = "a") else wordnet_lemmatizer.lemmatize(word, pos ="v") if word != wordnet_lemmatizer.lemmatize(word, pos = "v") else wordnet_lemmatizer.lemmatize(word, pos ="r") if word != wordnet_lemmatizer.lemmatize(word, pos = "r") else wordnet_lemmatizer.lemmatize(word, pos ="s") if word != wordnet_lemmatizer.lemmatize(word, pos = "s") else wordnet_lemmatizer.lemmatize(word) for word in words ] |
Stemming
It is the process of reducing the word to its word stem that affixes to suffixes and prefixes or to roots of words known as a lemma. In simple words stemming is reducing a word to its base word or stem in such a way that the words of similar kind lie under a common stem. For example – The words care, cared and caring lie under the same stem ‘care’. Stemming is important in natural language processing(NLP). Porter’s Stemmer, Snowball stemmer, Lancaster Stemmer are the common stemmers available in NLTK library. We are using the Snowball stemmer in our codes. Please refer here for detailed information on the different stemmers.
Few common rules of Snowball stemming are:
|
1 2 3 4 5 |
ILY -----> ILI LY -----> Nill SS -----> SS S -----> Nill ED -----> E,Nill |
- Nill means the suffix is replaced with nothing and is just removed.
- There may be cases where these rules vary depending on the words. As in the case of the suffix ‘ed’ if the words are ‘cared’ and ‘bumped’ they will be stemmed as ‘care‘ and ‘bump‘. Hence, here in cared the suffix is considered as ‘d’ only and not ‘ed’. One more interesting thing is in the word ‘stemmed‘ it is replaced with the word ‘stem‘ and not ‘stemmed‘. Therefore, the suffix depends on the word.
Let’s see a few examples:
|
1 2 3 4 5 6 7 8 9 10 |
Word Stem cared care university univers fairly fair easily easili singing sing sings sing sung sung singer singer sportingly sport |
Drawbacks of Stemming:
- Issues of over stemming and under stemming may lead to not so meaningful or inappropriate stems.
- Stemming does not consider how the word is being used. For example – the word ‘saw‘ will be stemmed to ‘saw‘ itself but it won’t be considered whether the word is being used as a noun or a verb in the context. For this reason, Lemmatization is used as it keeps this fact in consideration and will return either ‘see’ or ‘saw’ depending on whether the word ‘saw’ was used as a verb or a noun.
|
1 2 3 4 5 6 |
from nltk.stem import WordNetLemmatizer,SnowballStemmer #Stemming using nltk SnowballStemmer # Create a new instance of a English language specific subclass of SnowballStemmer which is used for stemming the words snowball_stemmer = SnowballStemmer('english', ignore_stopwords=True) stemmed = [snowball_stemmer.stem(word) for word in lemmatized] |
Stopword Removal
One of the major forms of pre-processing is to filter out useless data. In natural language processing, useless words (data), are referred to as stop words.
A stop word is a commonly used word (such as “the”, “a”, “an”, “in”) which is removed from the list of words.
|
1 2 3 4 5 |
from nltk.corpus import stopwords #Removing stop words using nltk stopwords stopword = stopwords.words('english') normalized_tokens = [word for word in lemmatized if word not in stopword] |
Once the function for tokenizing words is done, the next step is to create the main snowpark udf for building the inverted index.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
@udf(packages=['nltk==3.7','unicodedata2'] ,imports=["/home/ryzen/nltk_data/corpora/stopwords.zip" ,"/home/ryzen/nltk_data/corpora/wordnet.zip" ,"/home/ryzen/nltk_data/corpora/omw-1.4.zip"] ,name = 'inverted_index' ,is_permanent = True ,stage_location="@T_STAGE" ,replace=True) def inverted_index(id : str,text : str) -> dict: import sys import os import zipfile import nltk from pathlib import Path IMPORT_DIRECTORY_NAME = "snowflake_import_directory" import_dir = sys._xoptions[IMPORT_DIRECTORY_NAME] if not Path("/tmp/nltk_data/corpora/stopwords").exists(): with zipfile.ZipFile(f'{import_dir}/stopwords.zip', 'r') as myzip: myzip.extractall('/tmp/nltk_data/corpora/') if not Path("/tmp/nltk_data/corpora/wordnet").exists(): with zipfile.ZipFile(f'{import_dir}/wordnet.zip', 'r') as myzip: myzip.extractall('/tmp/nltk_data/corpora/') if not Path("/tmp/nltk_data/corpora/omw-1.4").exists(): with zipfile.ZipFile(f'{import_dir}/omw-1.4.zip', 'r') as myzip: myzip.extractall('/tmp/nltk_data/corpora/') nltk.data.path.append('/tmp/nltk_data') if text: try: terms = tokenize(text) except: terms = [''] appearances_dict = dict() # Dictionary with each term and the frequency it appears in the text. for term in terms: term_frequency = appearances_dict[term]['frequency'] if term in appearances_dict else 0 appearances_dict[term] = {'doc_id' : id, 'frequency' : term_frequency + 1} return appearances_dict |
The packages to be installed on the snowflake warehouse such as nltk and unicodedata2 need to be specified when creating the UDF. There is also dependency on the nltk files namely stopwords,wordnet and omw-1.4, which should also be specified.
The import directory where the dependent files and packages are imported is specified as given below.
|
1 2 |
IMPORT_DIRECTORY_NAME = "snowflake_import_directory" import_dir = sys._xoptions[IMPORT_DIRECTORY_NAME] |
The imported nltk files should be unzipped to a directory with write privilege and the NLTK_PATH(nltk.data.path) needs to be modified to add this path as well.
|
1 2 3 4 5 6 7 8 9 10 11 |
if not Path("/tmp/nltk_data/corpora/stopwords").exists(): with zipfile.ZipFile(f'{import_dir}/stopwords.zip', 'r') as myzip: myzip.extractall('/tmp/nltk_data/corpora/') if not Path("/tmp/nltk_data/corpora/wordnet").exists(): with zipfile.ZipFile(f'{import_dir}/wordnet.zip', 'r') as myzip: myzip.extractall('/tmp/nltk_data/corpora/') if not Path("/tmp/nltk_data/corpora/omw-1.4").exists(): with zipfile.ZipFile(f'{import_dir}/omw-1.4.zip', 'r') as myzip: myzip.extractall('/tmp/nltk_data/corpora/') nltk.data.path.append('/tmp/nltk_data') |
The logic for building the inverted dictionary is then added to the udf.
Now a dataframe needs to be created selecting only the primary key and text fields from the table required. The udf inverted_index is then applied on these columns and the output which is the id (the primary key), text and the inverted index for the text would be written to a snowflake table.
|
1 2 3 4 5 |
#write all rows to table df = session.table(table).select(column_list).to_df(["id","text"]) \ .filter("text is not NULL") df.select("id","text",inverted_index("id","text").alias('APPEARANCE')) \ .write.saveAsTable(f"TERESA_SANDBOX_DB.INVERTED_INDEX.AGGIE_INVERTED_INDEX_INITIAL_{table.split('.')[-1]}", mode="overwrite") |
The output table is as shown below.
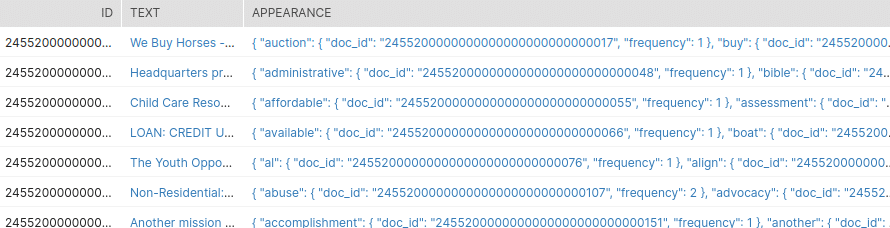
Now as the last step, a single inverted index for all the rows of text will be created using the snowflake sql as given below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
session.sql(f"""CREATE OR REPLACE TABLE INVERTED_INDEX_FINAL_{table.split('.')[-1]} AS WITH SET1 AS ( SELECT KEY,VALUE FROM INVERTED_INDEX_INITIAL_IRS990, LATERAL FLATTEN("APPEARANCE") ) SELECT KEY AS TERM,LISTAGG(VALUE,',') WITHIN GROUP (ORDER BY VALUE) AS APPEARENCE FROM SET1 GROUP BY TERM ; """).collect() |
The output of this is as given below.

The final inverted index thus has each of the terms along with the id of the text it appears on and its frequency in each of the text fields.
Thus we just need to pass the table name and the column names for the primary key and the text fields in order to create an inverted index for that.
This blog post was co-authored by Teresa Rosemary and Uli Bethke
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: