Iceberg Ahead! All you need to know about Snowflake’s Polaris Catalog

Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
What is the Polaris Catalog?
At the Snowflake Summit 2024 Snowflake’s CEO Sridhar Ramaswamy announced the Polaris Catalog during the main keynote speech. The announcement around the Polaris Catalog has triggered a lot of excitement but also some confusion. Unless you are deeply involved and knowledgeable about open table formats It is not obvious what problem the Polaris Catalog solves.
Just like other data management related terms such as Model, the term Catalog is overloaded with different meanings.
In this post we bring some clarity and recommendations to the announcement. We first look at the Polaris Catalog in the context of open table formats (Apache Iceberg) and the problems it solves around data sprawl, interoperability, and vendor lock-in. We then outline some of the gotchas of using Iceberg on Snowflake. We also describe some common use cases and make recommendations of when to use Iceberg and the Polaris Catalog in your Snowflake implementation.
If you are in a hurry I have compiled the key takeaways from this post.
Key takeaways
- The Polaris Catalog is not a Data Catalog. The native Data Catalog in Snowflake is called Horizon.
- The Polaris Catalog is a technical catalog that needs to be understood in the context of Apache Iceberg.
- Apache Iceberg is an open table format. The original open table format is Hive and the Hive Metastore. Iceberg addresses a lot of the limitations of Hive.
- Open table formats make interoperability between different compute and data processing engines possible. Store your data in the same format (Iceberg). Process it with different engines, e.g. Snowflake, Dremio, Spark etc.
- Open table formats address the underlying problem of data sprawl and multiplication of data copies. They also address vendor lock-in to proprietary storage formats.
- Snowflake added support for Apache Iceberg a while ago with the option of using a proprietary Snowflake catalog or an external catalog. But there was a catch. Using the external catalog, Snowflake could not write to Iceberg. Using the Snowflake Catalog external engines could not write to Iceberg and reads were limited to Spark via a separate SDK.
- The Polaris Catalog lifts that limitation. Snowflake and external engines can now read from and write to Iceberg.
- By announcing the Polaris Catalog, Snowflake has made clear that they support open standards in general and open table formats and the advantages of interoperability between different tools.
- While the Polaris Catalog addresses the multiplication of the data itself it does not seem to address the multiplication of the security layer. You can set security and access policies like RBAC within Snowflake for Iceberg tables created by Snowflake or other compute engines. However, this security only works within Snowflake and doesn’t extend to other engines.
- There is no feature parity between Snowflake native tables and Iceberg tables. A lot of features such as Dynamic Tables, Cloning etc. are not supported (yet?).
- Some use cases for Polaris Catalog
- Data sharing between organisations will be much easier. Imagine data in the Snowflake Data Marketplace accessible to organisations that use Spark, Dremio, Trino etc.
- Offloading workloads to other engines for cost, performance, skillset reasons, e.g. run ETL on Snowflake and data science on AWS Sagemaker.
- You need to support multiple tools and compute engines inside your organisation, e.g. one business unit uses AWS Athena another Snowflake
- For now do not go all in on Iceberg. Wait until there is more clarity on the support for all features on both native and Iceberg tables.
- For now use Iceberg for the use cases I have outlined and make sure to check if you are impacted by the feature limitations. Don’t be the Titanic. Cautiously navigate the Iceberg.
The Polaris Catalog is not a data catalog
Let’s start by looking at what the Polaris Catalog is not.
The Polaris Catalog should not be confused with a (meta)data catalog for data lineage, search, data inventories, glossaries etc. For this purpose we have Snowflake Horizon and third party products such as Collibra.
The Polaris Catalog is a technical catalog. This type of catalog is a component of open table formats such as Apache Iceberg. Another example of such a catalog is the well known Hive Metastore.
In order to understand what this technical catalog is about we need to understand how open table formats and in particular the Apache Iceberg format work under the hood and what the advantages of open table formats are.
What is an open table format? What is Apache Iceberg?
Apache Iceberg is an open table format which originated at Netflix.
Open table formats such as Apache Iceberg address two common problems.
- Open table formats increase interoperability and prevent vendor lock in around data storage. You are not locked into a proprietary storage format for your data. Data stored as Iceberg tables can be queried and written by other query engines and not only Snowflake.
- Making data available outside Snowflake to consumers with other tools and compute engines is now easier. You can avoid duplication of data and possibly streamline your data pipelines if you plan things properly. Other tools that have support for Iceberg such as Athena, Spark, Databricks, Dremio etc. can now also access your data if it is stored as Iceberg.
Apache Iceberg builds on a history of other open table formats. The original open table format was Hive. Hive lets you build tables for SQL querying on top of CSV, Parquet, or ORC files.
Apart from being an open table format Hive also ships with a compute engine. This is different from Iceberg, which is purely focused on storage. With Hive you could use other compute engines such as Spark, Presto etc. to query the data inside Hive. Hive also requires a catalog which is called the Hive metastore. It is still widely used and you can also use it as your catalog for the Iceberg table format.
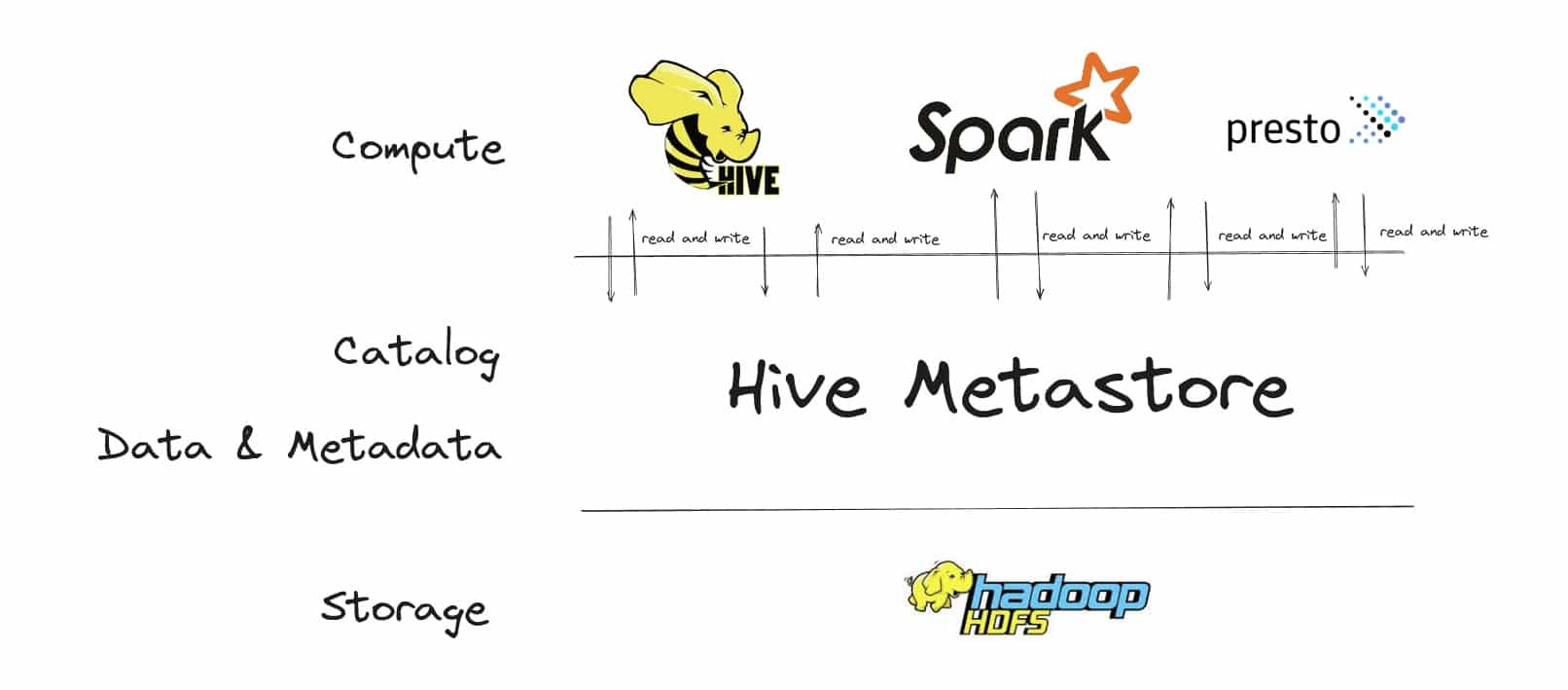
Hive had various issues in particular around partitioning, ACID, performance, schema evolution, storage etc.
Apache Iceberg is based on the same ideas and concepts of data interoperability as Hive but fixes all of the technical issues in Hive, e.g. ACID, schema evolution, partitions at directory rather than file level etc.
Other popular open table formats are Hudi and Delta Lake. Hudi, despite being around for a long time never gained much traction. While Delta Lake is an open source project it is primarily managed, resourced and controlled by Databricks. Because of this and because some nice features around partitioning and schema evolution Iceberg has gained a lot of traction over the last few years and now claims the #1 spot amongst open table formats in terms of committers and companies supporting it.
Let’s go through the components of the Apache Iceberg table format.
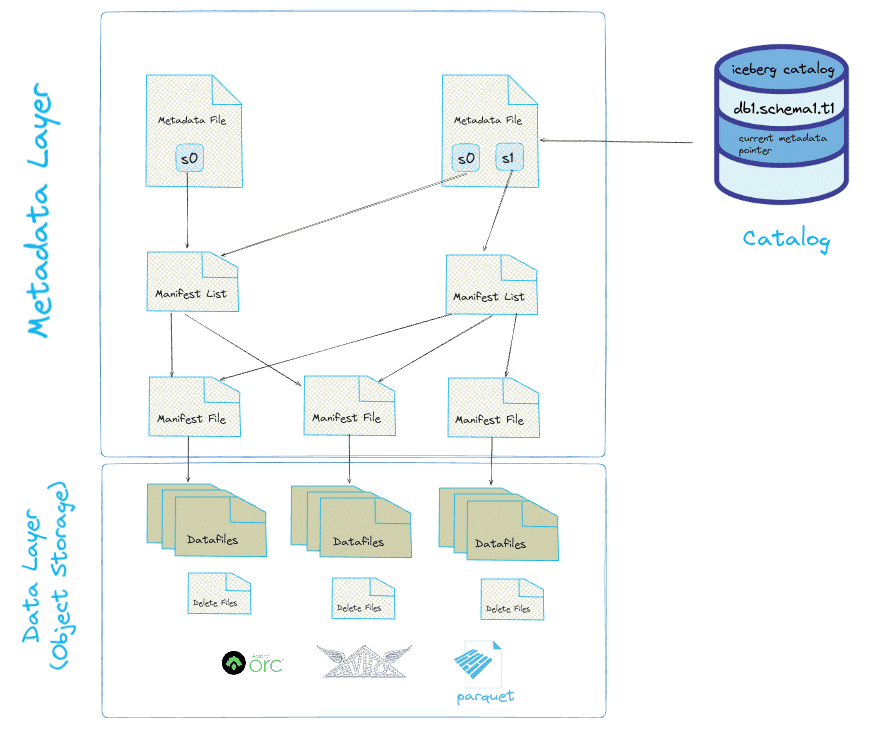
Figure based on the excellent book Iceberg the Definitive Guide.
Data Storage
Let’s start with the data files at the lowest level. Data files store the data itself. Data files also include delete files. These are used for updates and deletes and are used to calculate the current state of the data. Apache Iceberg currently supports Apache Parquet, Apache ORC, and Apache Avro. The most commonly used data format is Parquet.
Parquet is columnar storage and internally organises the data in row groups, columns and pages.
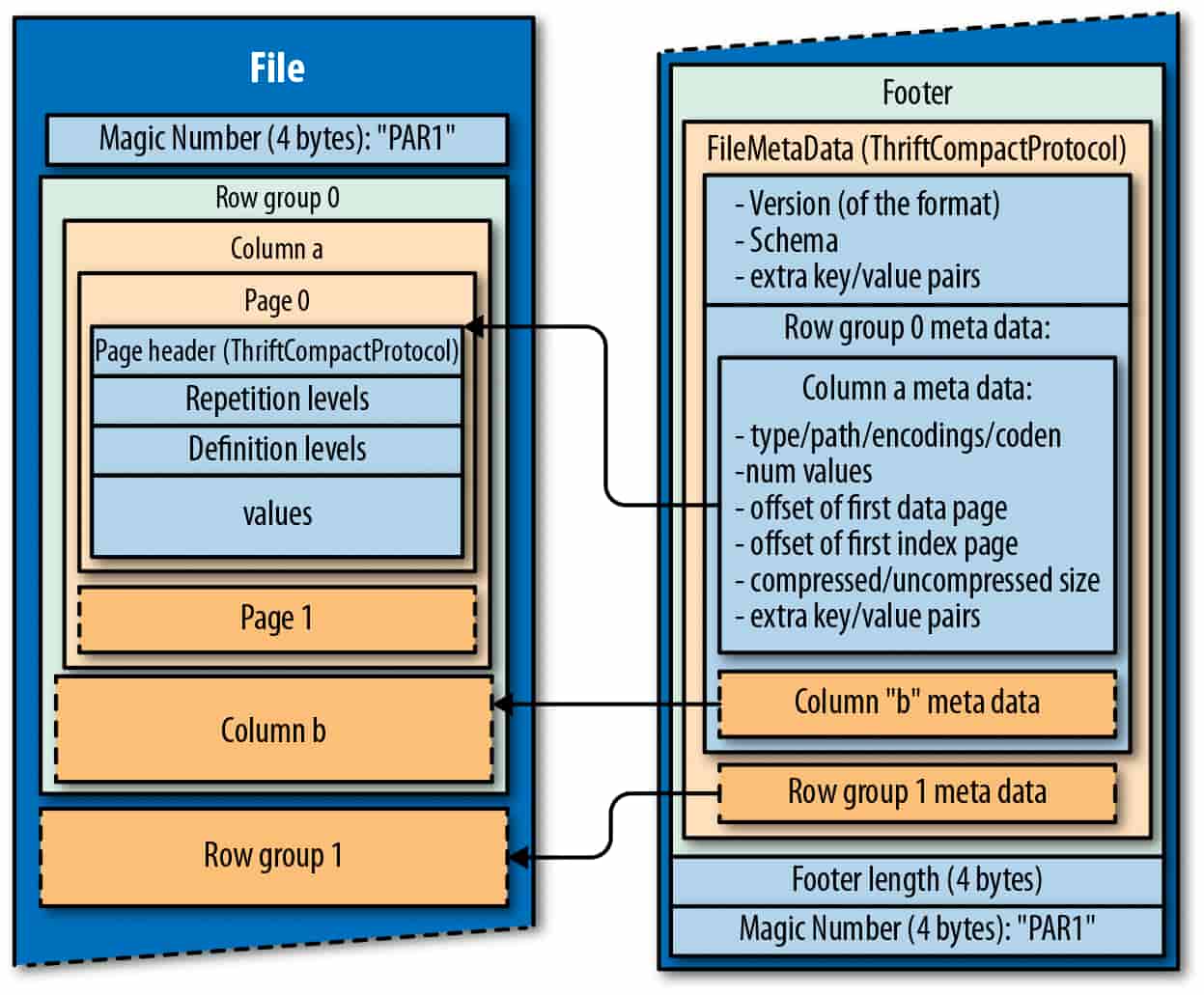
While Iceberg supports ORC and Avro, Snowflake only supports Parquet for Iceberg.
Metadata
The metadata layer is made up of various files. In the metadata layer Iceberg stores aggregated column statistics such as the MIN and MAX values from the data files. This information is used for partition pruning to skip reading data files where not needed and is a huge performance boost. While the data files also store this information it generates overhead to peek into each of the data files. The query engine instead first has a look at the aggregated stats and if possible skips scanning the data files themselves.
The metadata layer also is responsible for tracking the state of the data files in the form of metadata files. Each time a change is made to the data files a new metadata file is created with pointers to the various data files. These serve as snapshots of the data as a point in time.
Catalog
The Catalog is the component inside the Iceberg spec where the Polaris Catalog got its name from. It is an entry point for compute engines such as Snowflake or Spark into the data managed by Iceberg.
It serves two purposes:
- Database abstraction. Iceberg is a specification for technical metadata at the table level, and Iceberg metadata files are stored next to your data files. The metadata layer is unaware of concepts such as table names, schemas, and databases. The catalog creates a database abstraction on top of your collection of tables by introducing hierarchy and storing a map of table names onto prefixes.
- Pointer to the current table version. When you make changes to an Iceberg table, new data and metadata files are added and stored next to the old ones. The catalog keeps track of the metadata files which represent current state and point in time states of your data. The Catalog tells you which table version is current.
A great deep dive on the internal mechanics of the Iceberg table format can be found in the excellent book Apache Iceberg the Definitive Guide
Now that we have some high-level understanding of how Iceberg works, let’s look at how it can be used today inside Snowflake, how it compares to other table formats supported by Snowflake and how the Polaris Catalog lifts some limitations that currently exist.
Table formats and Iceberg on Snowflake
When Snowflake first started out your only option for storing your data was Snowflake’s native data format. If you wanted to give access to other tools and consumers such as AWS Sagemaker, Spark etc. you typically first had to unload the data from the Snowflake proprietary table to a file format such as CSV, Parquet etc. This leads to compute overhead and a multiplication of data, which in turn brings governance problems to manage all of these data copies.
Snowflake tackled this problem in multiple ways.
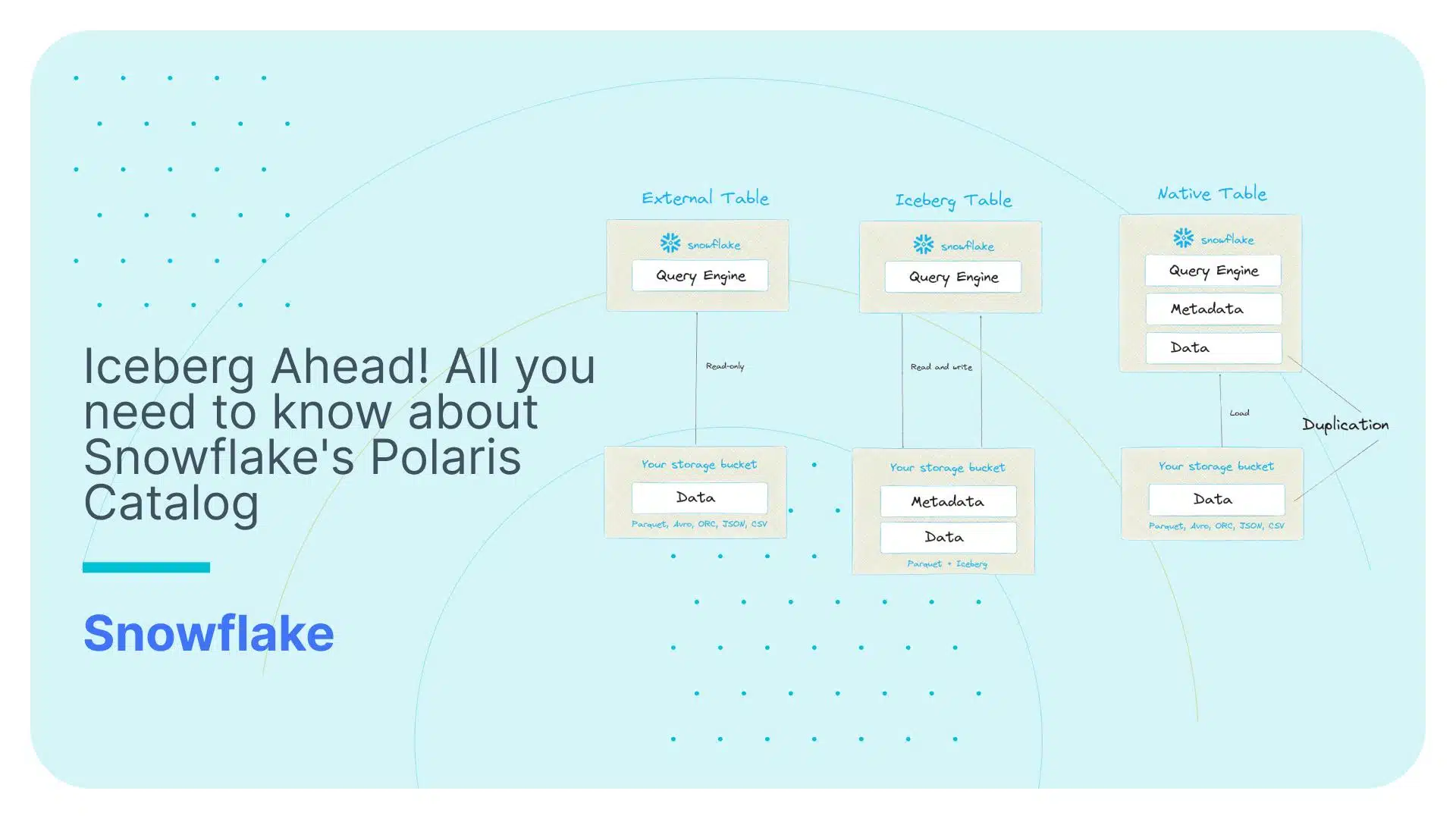
As a first step, Snowflake added support to query data in external tables. This way customers can query data that is stored on object storage such as S3 or ADLS from inside Snowflake and other tools and compute engines. External tables support file formats such as CSV, JSON, Parquet and a few other formats. External tables do not have support for XML. There are also a few other downsides of using external tables in Snowflake
- They don’t match native Snowflake tables in terms of performance
- You had to define your own metadata and table spec
- Only a small subset of the features you will find with Snowflake native tables is available for external tables
- You can’t write directly to an external table the way you can write to a native table
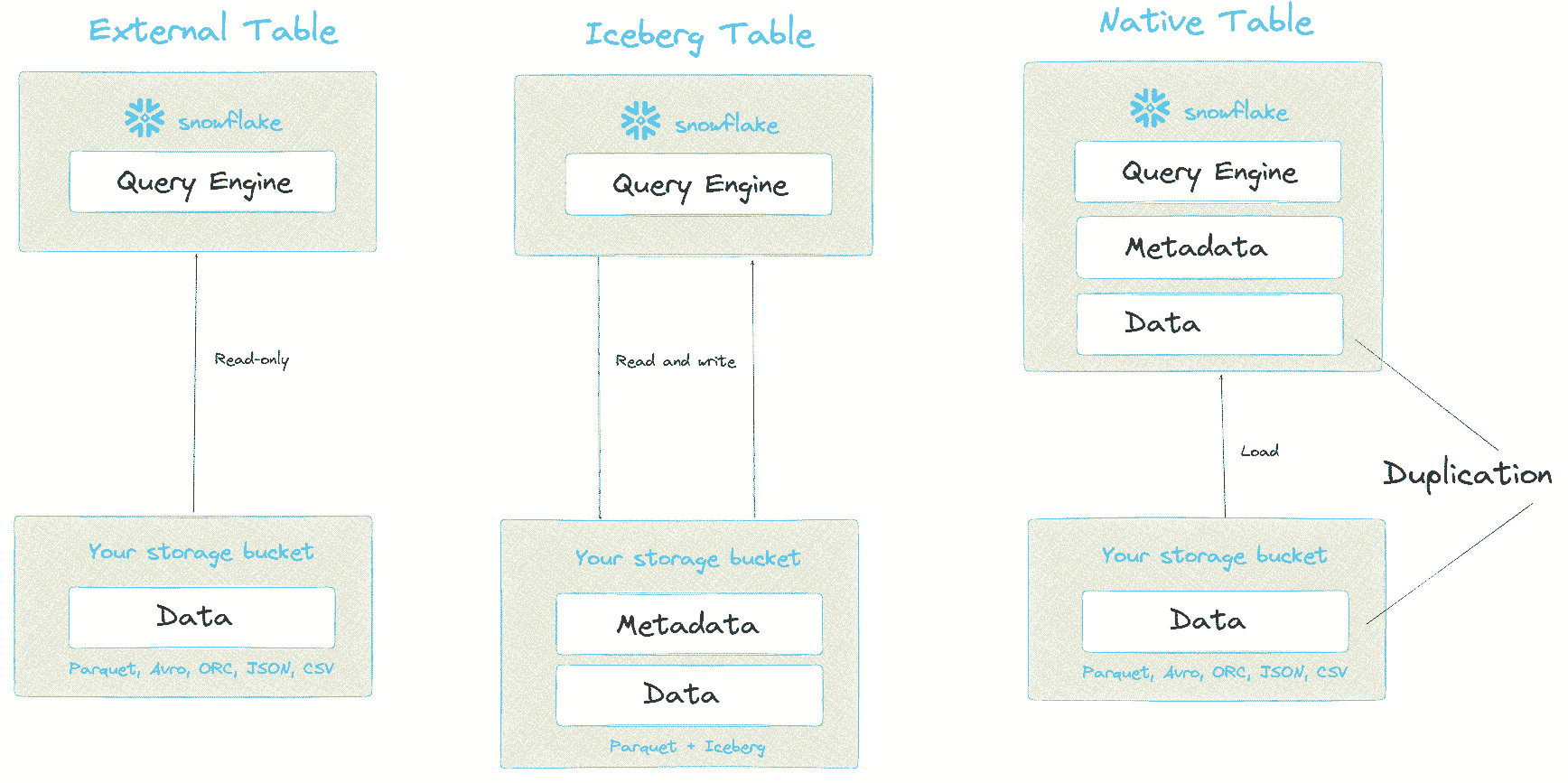
More recently, Snowflake added support for Iceberg, which is an open table format.
Iceberg addresses the limitations of Snowflake external tables.
- You can write to Iceberg tables
- It has metadata
- It supports more features than external tables but still has many limitations in comparison to native tables which we will cover at the end of this post.
- Iceberg tables almost match the performance of Snowflake native tables. This probably means that the implementation of Snowflake native tables is very similar to Iceberg.
The Polaris announcement addresses one big limitation in Snowflake Iceberg. The Catalog. As we learned earlier on, Iceberg requires a Catalog to store technical information about your data such as schema and table names.
Prior to Polaris Catalog you could either use a proprietary Snowflake Catalog for Iceberg or an external Catalog such as AWS Glue. Using the native Snowflake Catalog you were able to write to Iceberg from Snowflake but other engines were not able to write to Iceberg. Furthermore only some engines were able to read data written to Iceberg this way via a separate SDK.
With the Polaris Catalog these restrictions will be lifted. Snowflake and other compute engines can now both read and write to Iceberg.

The announcement around Polaris Catalog also sends a message to Snowflake clients and prospects: We embrace open data standards. We support open access to your data from different compute engines and tools. We don’t limit access to your data to Snowflake only. We don’t lock you into Snowflake’s data standard.
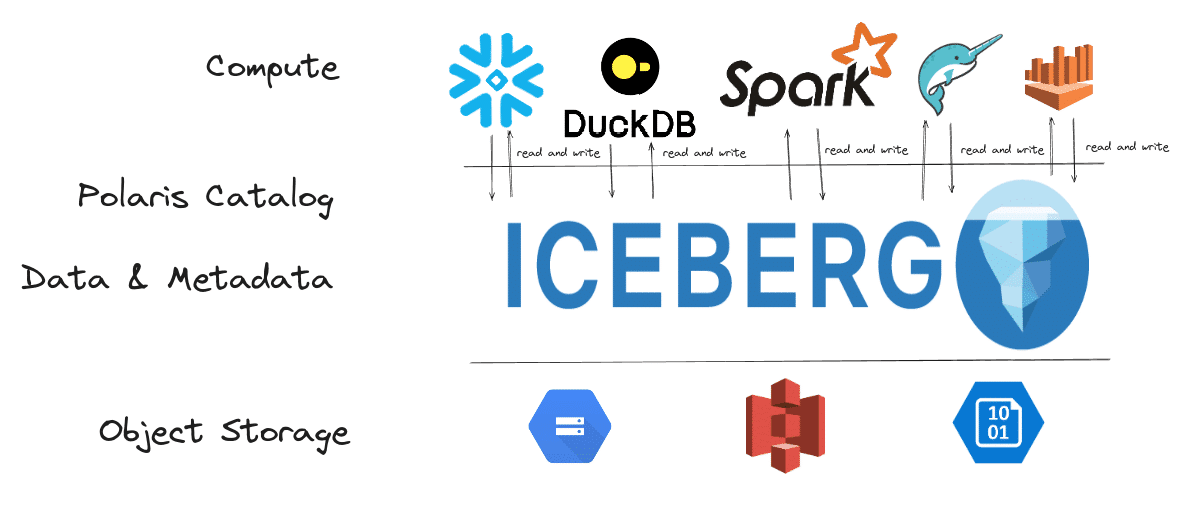
Here is a good overview from Snowflake about the Polaris Catalog, which reveals some inner workings of it
Are there any gotchas?
You can bet there are.
Data format support
Let’s start with a minor one. The Snowflake implementation of Iceberg only supports Parquet but not Avro or ORC.
Query performance
Another minor issue is that as a rule of thumb query performance against Snowflake native tables tends to be slightly better than against Iceberg tables
Missing Snowflake features
A bigger issue is that a lot of great Snowflake features are only supported for native tables but not supported for Iceberg tables. .
Here are some popular features that are not supported
- Cloning
- Dynamic Tables
- Fail-safe
- Query Acceleration
- Replication
- Hybrid Tables
- Various drivers
- Transient tables
Authorisation and security
At this point in time it is a bit unclear on how authorisation and security will work for Iceberg tables in the Polaris Catalog.
While the Snowflake announcement states that you will be able to define security such as RBAC, masking, object and row access through Snowfalke it is unclear if the security model defined inside Snowflake also extends to other compute engines, e.g. via a sync to the Polaris Catalog.
In the worst case scenario you would have to define the security model separately for each compute engine.
The best case scenario would be the option to define the security model inside the Polaris Catalog itself. Reading between the lines It is unlikely that this will happen though
Where will you define RBAC, object access, row and column level access, data masking, tagging? Do you need to define it once or multiple times for each compute engine that accesses the data?
While the Polaris Catalog solves the problem of data multiplication it is unclear if and how it will solve the problem of multiplication of metadata such as security models and access policies.
Use cases for Polaris Catalog and Iceberg
What are some use cases of the Polaris Catalog?
Personally I can think of the following scenarios where Iceberg tables could be useful on Snowflake
- Data sharing, e.g. you are a SaaS vendor and want to make data available to your clients and let them use their own internal engines to query the data. Think of the Snowflake Data Marketplace available for non Snowflake customers.
- You have a company policy to use open standards and open source where possible.
- You want to use a compute engine other than Snowflake for parts of your workload. Why would you want to do this? Another engine offers better performance and is more cost effective, offers additional features not currently in Snowflake or your skills are on other tools.
Some examples
- Spark for ETL
- DuckDB for testing
- AWS Sagemaker for data science
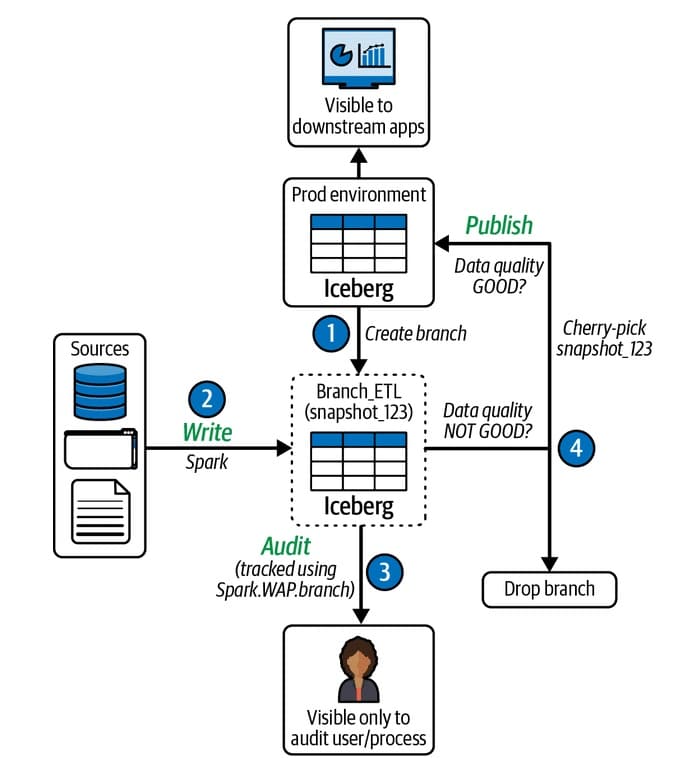
Figure taken from the excellent book Iceberg the Definitive Guide
Avoiding the fate of Titanic
At the moment there are still some significant discrepancies in terms of features between Iceberg and Snowflake native tables.
As long as there is no feature parity between native Snowflake and Iceberg tables I would not go all in on Iceberg.
For now I would recommend being selective when it comes to Iceberg on Snowflake. You don’t want to be the Titanic of data. Use it for the use cases I have outlined above and where you will not need to rely on features that are currently not supported for Iceberg tables.
While you are here also make sure to check out our free tool for visualising and debugging complex and nested SQL code
Recommended reading
Some Dremio executives and employees have published an excellent book on Iceberg. It is highly recommended reading not only for Iceberg enthusiasts but for data engineers in general as it explains the internal mechanisms of data storage very well. Iceberg the definitive guide
While you are here. Did you know that you can visualise SQL with FlowHigh SQL Visualise
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: