XML/JSON to CSV Converter

Convert complex XML/JSON hierarchies into human-readable CSVs. Perfect for rapid ad-hoc analysis in Excel or Python/Pandas without setting up a database.
CONVERT
Automated SQL Tables from XSD, XML & JSON
Don't let complex schemas slow you down. Flexter automatically transforms XSDs, XML, and JSON into a high-performance relational database. No XPaths, no manual mapping—just automated data delivery in minutes.
Book a Demo Try Free
“You did in one day what we could not achieve in three years!”
Stop fighting with complex schemas. Flexter automatically transforms deep XSD, XML & JSON structures into an optimized, SQL-ready relational database (3NF). No manual mapping, no “flattening” errors, and zero coding required.

Manual Engineering: Hand-coding thousands of XPaths and manual table modeling.
Data "Explosion": Flattening XML into messy tables, creating "Granularity Mismatch" and data loss.
Scaling Limits: Scripts crash on large volumes or deep files; cannot distribute the processing load.
Brittle Pipelines: Code breaks whenever XML versions or XSD structures change (e.g., FpML 4.0 to 5.0).
Delayed Access: Stakeholders wait weeks or months for the full development lifecycle to complete.
Unpredictable Risk: High risk of project overrun and months of engineering cost.
Zero Coding: 100% automated mapping and schema generation from XSD, XML & JSON.
Intelligent 3NF: Preserves complex parent-child relationships with automated Primary & Foreign Keys.
Proven Scale: Processed 20M files in 11 mins. Built on Apache Spark to scale for any data volume.
Self-Healing: Automatically detects Schema Drift and evolves the target database without manual updates.
Immediate Value: Decision-makers query usable SQL data on Day 1, enabling analysis instantly.
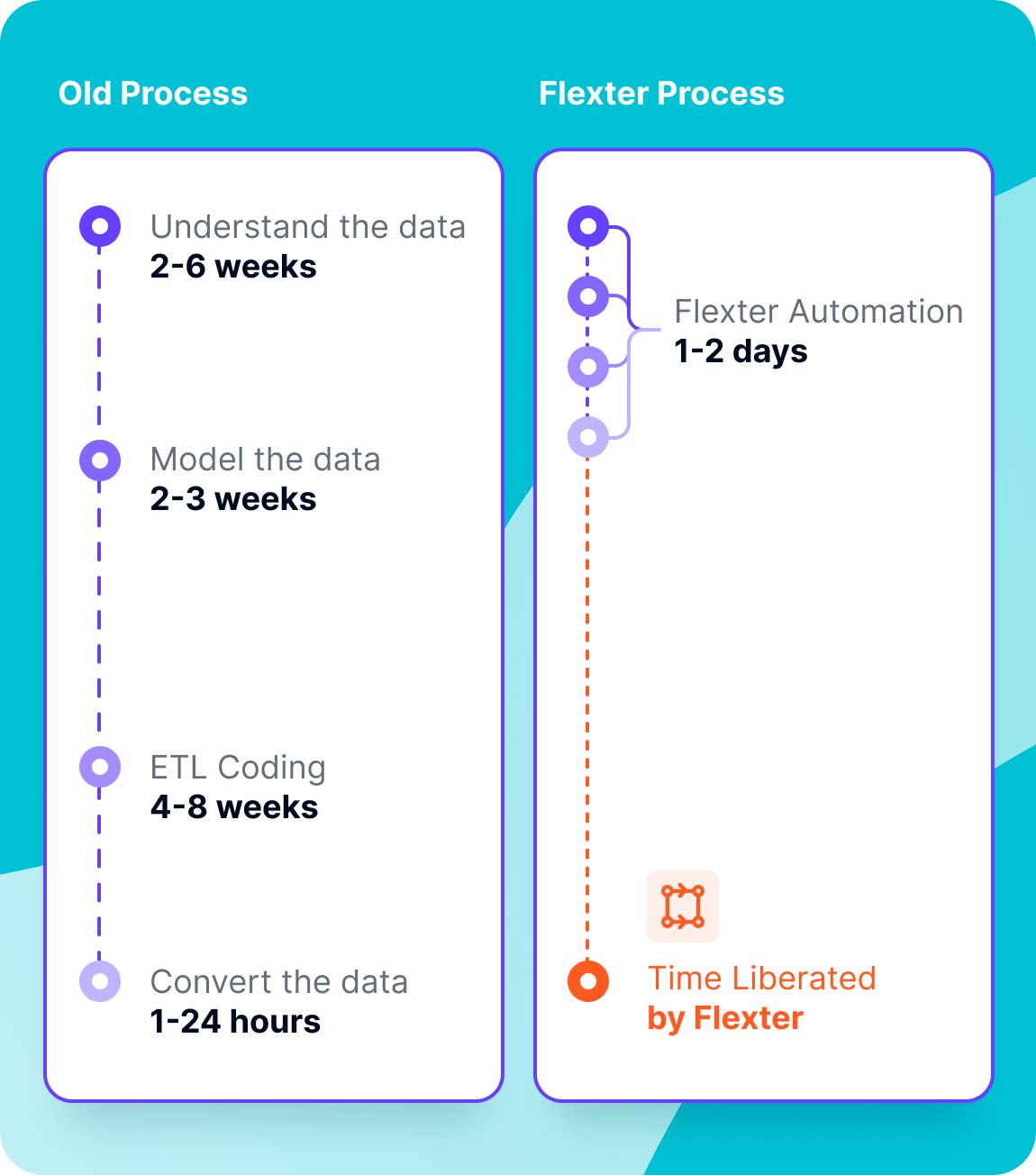
Predictable Delivery: Move from months to minutes. Case Study: Aer Lingus (1 Day setup).
Supports any XSD, XML, or JSON standard (FHIR, HL7, FpML, SEPA etc.) without the need for manual pre-processing.
Analyzes XSD, XML, and JSON structures to intelligently map complex relationships and hierarchies, rather than just extracting flat data points.
Instantly transforms XSD, XML, and JSON into optimized Target Schemas (DDL). Algorithms generate the database structure automatically—no manual data modeling required.
Built to scale up and out, processing terabytes of XSD, XML, and JSON data in parallel using a high-performance Apache Spark-based engine.
Complete transparency for compliance. Automatically generate documentation and mapping logic showing exactly how every XSD, XML, and JSON element maps to your target database.
Push your optimized XSD, XML, and JSON data directly into enterprise targets like Snowflake, Databricks, BigQuery, MS Fabric, Oracle, SQL Server, Iceberg, Parquet, ADLS, or S3.
Flexter has been purposefully designed and expertly engineered to stand as the #1 premier XML conversion solution for Snowflake environments. Here’s six reasons we’re the top choice for the world's leading corporations:
Cultivate insights and drive growth with three simple steps
Step 1: Intelligent Analysis

Step 2: Algorithmic Simplification
Step 3: Automated Execution
For a detailed overview of Flexter’s specifications, see a full technical breakdown below.


| Flexter Capabilities | |
|---|---|
| Data | |
| Data volume i Effortlessly process any volume of XML and JSON data, from small files to terabytes, ensuring high performance and scalability for enterprise workloads. Built on Apache Spark for big-data scale. | Handles any volume of data |
| Data size i Process multi-GB XML/JSON files on a single machine without memory failures. Streaming architecture reliably handles very large and complex files. | Handles very large files |
| Overwrite i Overwrite existing datasets in your target store to refresh analytics with the latest data. | Available |
| Append i Append new data to existing tables/files—ideal for incremental loads and maintaining history. | ✓ |
| Access & Interfaces | |
| API i Programmatic access via a robust REST API to integrate conversion in apps and data pipelines. | ✓ |
| Command line (CLI) i Script, automate, and schedule conversions—perfect for batch jobs and CI/CD. | ✓ |
| Web UI i Intuitive, web-based UI to manage XML/JSON conversion end-to-end—no coding required. | ✓ |
| Supported Input Formats | |
| XML i Parse and convert complex, nested, or large XML files into structured, queryable formats. | ✓ |
| JSON i Flatten and normalize hierarchical JSON for analytics and warehousing. | ✓ |
| TSV, CSV, PSV (delimited) i Handle common delimited files alongside semi-structured data for unified ingestion. | ✓ |
| RDBMS sources i Extract from relational databases and blend with XML/JSON streams. | ✓ |
| Supported Output Databases | |
| Snowflake i Convert and load XML/JSON directly into Snowflake with auto-optimized schemas for fast queries. | ✓ |
| Oracle i Load complex XML/JSON into Oracle, transformed into a relational format for enterprise apps. | ✓ |
| MySQL i Convert XML/JSON to MySQL tables so semi-structured data is ready for web apps and analytics. | ✓ |
| PostgreSQL i Transform XML/JSON into PostgreSQL for powerful relational analysis. | ✓ |
| Teradata i Integrate complex XML/JSON with Teradata for large-scale analytics and BI. | ✓ |
| Amazon Redshift i Quickly convert massive XML/JSON volumes for high-speed Redshift cloud analytics. | ✓ |
| Microsoft SQL Server i Modernize workflows by converting legacy XML/JSON for SQL Server use. | ✓ |
| Azure SQL Data Warehouse (Synapse) i Seamlessly load XML/JSON into Azure Synapse Analytics for cloud-scale analytics. | ✓ |
| Yellowbrick i Feed Yellowbrick with query-optimized XML/JSON conversions for fast analytics. | ✓ |
| Google BigQuery i Convert XML/JSON at scale for direct BigQuery analysis. | ✓ |
| Databricks (Delta) i Transform XML/JSON into Delta Lake tables for unified analytics and AI in Databricks. | ✓ |
| AWS Athena i Convert XML/JSON to Parquet on S3 for instant Athena querying. | ✓ |
| Supported Output Query Engines | |
| Apache Hive i Convert XML/JSON into structured data for Hadoop queries with Hive. | ✓ |
| Apache Impala i Optimize XML/JSON for high-performance, real-time Impala queries. | ✓ |
| Supported Output File Formats | |
| CSV i Convert complex XML/JSON into universal CSV or TSV for spreadsheets and reporting. | ✓ |
| TSV i Convert complex XML/JSON into universal CSV or TSV for spreadsheets and reporting. | ✓ |
| Microsoft Excel (XLSX) i Create well-structured Excel files from XML/JSON for business analysis. | ✓ |
| ORC i Generate compact ORC files to cut storage costs and speed Hadoop queries. | ✓ |
| Delta Lake Table i Build ACID-compliant data lakes by converting XML/JSON to Delta tables. | ✓ |
| Iceberg Table | ✓ |
| Apache Parquet i Produce efficient columnar Parquet files from XML/JSON for big-data analytics. | ✓ |
| Apache Avro i Convert XML/JSON into schema-based Avro for serialization and Kafka/Spark pipelines. | ✓ |
| Automation Capabilities | |
| Automated generation of target schema i Instantly generate an optimized relational schema from source data. | ✓ |
| Automated creation of data mappings i Automatically map XML/JSON to the target schema with full accuracy. | ✓ |
| Automated detection of parent–child relationships i Detect and preserve parent-child relationships with primary/foreign keys. | ✓ |
| Automated data conversion i Automate ingestion, parsing, transformation, and loading end-to-end. | ✓ |
| Automated generation of documentation i Auto-create ER models and documentation for governance and onboarding. | ✓ |
| Schema Optimization Algorithms | |
| Elevate algorithm i Simplify complex structures for a more intuitive, query-friendly schema. | ✓ |
| Reuse (XSD-based) i Optimise XSD-based schemas for a normalized, efficient data model. | ✓ |
| Automated naming conventions i Enforce automated, consistent naming for tables and columns. | ✓ |
| Schema Generation Sources | |
| From JSON sample i Generate a precise schema directly from JSON samples. | ✓ |
| From XML sample i Generate a precise schema directly from XML samples. | ✓ |
| From XSD i Create accurate target schemas from existing XSDs. | ✓ |
| XSD + XML sample i Combine XSD with sample XML for the most refined structure. | ✓ |
| From database schema i Build schemas from a database structure or simple text file. | ✓ |
| From text files | ✓ |
| Supported Data Sources | |
| FTP / SFTP i Securely ingest XML/JSON from FTP or SFTP servers. | ✓ |
| Object storage (S3, ADLS, GCS, Azure Blob) i Pull data from S3, Azure Data Lake, or Google Cloud Storage. | ✓ |
| HTTP(S) i Fetch and convert online data from web sources or APIs. | ✓ |
| HDFS i Process files stored in HDFS for Hadoop workflows. | ✓ |
| Network drives i Access files on shared drives or local systems. | ✓ |
| Local files and folders i Upload XML/JSON through the browser for instant conversion. | ✓ |
| Direct upload (Web UI) | ✓ |
| Change Intelligence & Management | |
| Centralized metadata catalog i Centralize schemas and mappings for governance and discovery. | ✓ |
| Schema version diff i Instantly compare schema versions to track changes. | ✓ |
| Automated schema evolution handling i Detect and adapt to source-schema changes to avoid breakages. | ✓ |
| Data lineage tracking i Track data flow from source to target for compliance. | ✓ |
| Automated ER diagrams i Auto-generate ER diagrams for clear documentation. | ✓ |
| Deployment Platforms | |
| Virtual machine / server i Run Flexter on your own VMs or physical servers. | ✓ |
| Kubernetes i Deploy as a scalable containerized app on any Kubernetes cluster. | ✓ |
| Snowpark Container Services i Execute directly inside Snowflake with Snowpark Container Services. | ✓ |
| Databricks i Run Flexter natively within Databricks for lakehouse integration. | ✓ |
| Apache Spark environments i Use any Spark environment for massive-scale data conversion. | ✓ |
| Deployment Locations | |
| Google Cloud Platform (GCP) i Process data from GCS and load into BigQuery on GCP. | ✓ |
| Amazon Web Services (AWS) i Convert S3 data and load into Redshift, Athena, or other AWS services. | ✓ |
| Microsoft Azure i Process ADLS/Blob data and load into Azure Synapse or other Azure databases. | ✓ |
| On-premise data centers i Deploy in your own data center for maximum control and security. | ✓ |
| Support | |
| ✓ | |
| Phone | ✓ |
✓ Available X Not available
Upload your complex XML/JSON. We will generate the optimized Relational Schema and load it directly into a live database environment (Snowflake) for you to query immediately.
Convert complex XML/JSON hierarchies into human-readable CSVs. Perfect for rapid ad-hoc analysis in Excel or Python/Pandas without setting up a database.

Experience the full engine. Flexter will process your file and populate a secure Snowflake database. Log in to inspect the optimized 3NF tables, run actual SQL queries, and export the DDL.
No. Flexter is deployed entirely within your private environment (AWS VPC, Azure VNet, Google Cloud, or On-Premise). The processing engine runs locally next to your data; no sensitive information is ever sent to our servers or third parties.
Yes. Unlike standard DOM parsers that load files into RAM. We routinely process individual XML files larger than 10GB and daily batches of millions of small files without bottlenecks.
Flexter is “API-first” and built for automation. You can trigger jobs via our CLI (Command Line Interface) or REST API, making it easy to orchestrate Flexter steps directly from Airflow, dbt, Azure Data Factory, Control-M, or any enterprise scheduler.
Flexter does not strictly require an XSD. Our Heuristic Scanner can analyze a sample of your XML/JSON files to reverse-engineer the schema, automatically detecting data types, relationships, and constraints to generate the target model.
Yes. You can start a Self-Service POC immediately on our website to process your complex XML/JSON files, generate the Target DDL, and inspect the data in Snowflake. For strictly on-premise requirements or large-scale evaluations, we offer a Supported Enterprise Pilot for free where a Data Architect and Data Engineer guides you through the installation and testing in your environment.
Yes, Flexter supports any industry standard because it is built on the full W3C XSD specification. Unlike niche tools built for just one format, Flexter is a universal XML/JSON engine. It automatically handles the complex features found in any standard—such as polymorphism, substitution groups, and deep nesting—without requiring custom coding.
Flexter pushes clean, optimized data directly to all major platforms.
Cloud Data Warehouses: Snowflake, Databricks, Google BigQuery, Azure Fabric, Redshift.
Relational Databases: Oracle, SQL Server, PostgreSQL, MySQL, MariaDB etc.
Lakehouse Formats: Delta Lake and Apache Iceberg.
File Formats: Parquet, Avro, ORC, and CSV.
Our licensing model has two simple components:
Compute Edition: Choose between Single Node (for standard workloads) or Cluster (for distributed, high-scale processing).
Schema Sources: Licenses are issued per distinct data source or standard (e.g., separate licenses are required for FpML, HL7, or internal XSDs). All Enterprise plans include a dedicated Data Architect to assist with installation, configuration, and your first production deployment.
If you have more Flexter related questions or want to know how it works, check out our detailed Flexter FAQ and Guide here.