Best Practices for implementing a Data Lake on Snowflake


Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Data lakes. An introduction
Data lakes are a common and useful design pattern in modern data architecture. Contrary to a widespread belief, data lakes have been around for a long time. The designs by Ralph Kimball and Bill Inmon included the design pattern of a staging and landing area. These are the parents of the data lake. The core feature of a data lake as a container of raw source data from operational systems for downstream consumers was already present. Over the last few years the early design pattern has been upgraded with some additional features:
- The only consumer of the staging area was the data warehouse / data marts layer. Only data engineers accessed the staging area to create ETL code and build data pipelines. The staging area was off limits for any other consumers such as data analysts or data scientists. In contrast to a traditional staging area, other stakeholders in the enterprise get direct access to the data in the data lake for their use cases. This access needs to be governed and managed.
- Data in the staging area was typically not audited, i.e. we did not record changes such as updates or deletes to the operational source data. Audit trails were typically kept downstream, e.g. in Slowly Changing Dimensions 2. Similarly schema evolution aka schema drift was not typically implemented in the staging area. Schema evolution keeps track of structural changes to a table over time, e.g. adding or removing a column.
In this blog post we will look at the data lake design pattern in more detail, e.g. the ingestion process and the consumers of a data lake. We first look at the pattern itself before we dive into the implementation of the data lake design pattern in the real world. For this purpose we will look at some best practices and anti-patterns of implementing a data lake on Snowflake.
You also might have heard of the term data lakehouse. It is another design pattern in enterprise architecture. It combines a data lake with a data warehouse on the same platform. Snowflake is a perfect fit for this architectural pattern.
FlowForward.
All Things Data Engineering
Straight to Your Inbox!
A deep dive into the data lake design pattern
At Sonra we have developed a reference enterprise data architecture over the years. It is bullet proof for the vast majority of data management use cases. If you are interested in our data architecture and data advisory services please contact us.
The reference data architecture also covers the data lake design pattern. I have highlighted the landing and staging areas with a red box. These two layers make up the data lake. The data lake receives its data from the data sources.
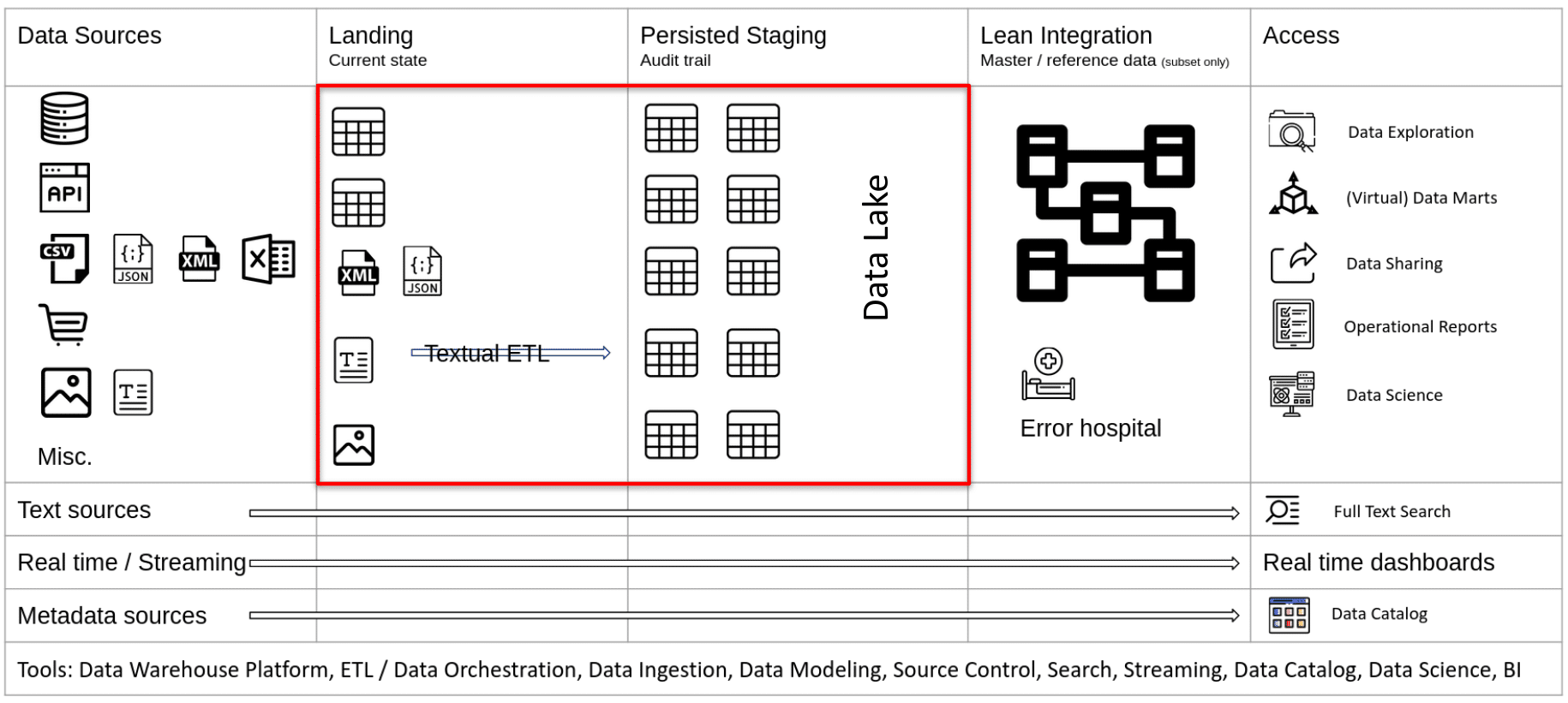
The data sources are the operational systems of an organisation. They represent and store data that is generated through the business processes. 10-15 years ago most data sources for data analytics were relational databases and text files (usually exports from relational databases). This has changed significantly over the last few years and we need to cater for a variety of different data source types. We will look at these in more detail in a minute.
Let’s first zoom in on the landing, and persisted staging layers as these are closely related. You can refer to them as the Raw layer in data architecture. We store the raw and unmodified data from the data sources.
Some people refer to this part of the data architecture as the data lake. The term data lake has a lot of negative connotations. It goes hand in hand with the term data swamp. I don’t think it is a good term to describe data architecture but it is now widely used and we will also use it in this blog post.
Landing
The Landing area is a copy of the data structures in your source systems. You should not apply transformations that contain business or integration logic between your sources and landing. You may apply some soft transformations such as mapping of data types or adding of control columns such as processing timestamps, or column hashes. However, do not apply business transformation logic or table joins as part of data ingestion from source to Landing.
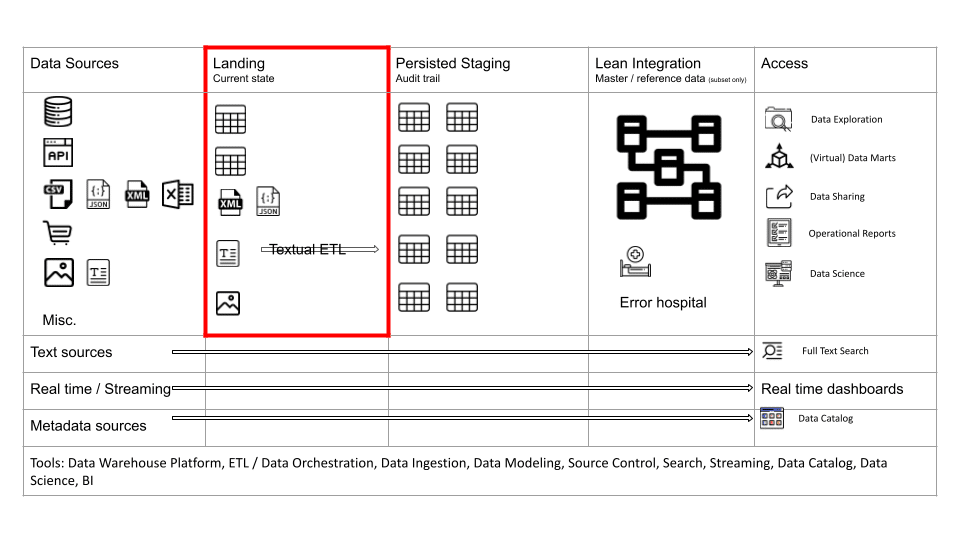
As a rule of thumb, it is better to ingest all the source data rather than just a subset, e.g. if you need to ingest a table to meet a requirement then ingest all the columns and not just a few columns. Reprocessing data and refactoring your data pipeline is expensive. Data storage on the other hand is cheap.
The landing area loosely couples your data sources to your staging area. It insulates the consumers of the Staging area from load failures.
The landing area typically contains the current state of your source system. It typically does not store the history of changes aka data audit trail.
The landing area is used to store all types of data. Structured, semi-structured, unstructured. Semi-structured and unstructured data is converted to structured data on the way from landing to staging.
You can use the landing area to perform Change Data Capture (CDC) against staging. CDC detects changes to source data, e.g. newly inserted, updated or deleted records. Various techniques exist to perform CDC.
- Reading the transaction log of a database.
- Using timestamps. We do not recommend this approach as it is not very reliable. It also requires a separate technique to detect deleted records. It may be useful under certain circumstances for very large transaction or event tables.
- Full extract and comparison between current state and previous state (as of last time the comparison took place)
CDC techniques depend on the type of source data, e.g. you will need to use a different technique for a text document or binary file than you would use for records in a relational database.
Persisted staging
In early data warehouse implementations the staging area was overwritten for each data load. Data was only stored permanently in the Integration and Data Mart layers. However, the Staging area has evolved over the last few years into the Persisted Staging area. Data is not overwritten. Quite the opposite. We store a full audit trail of historic changes to source data.
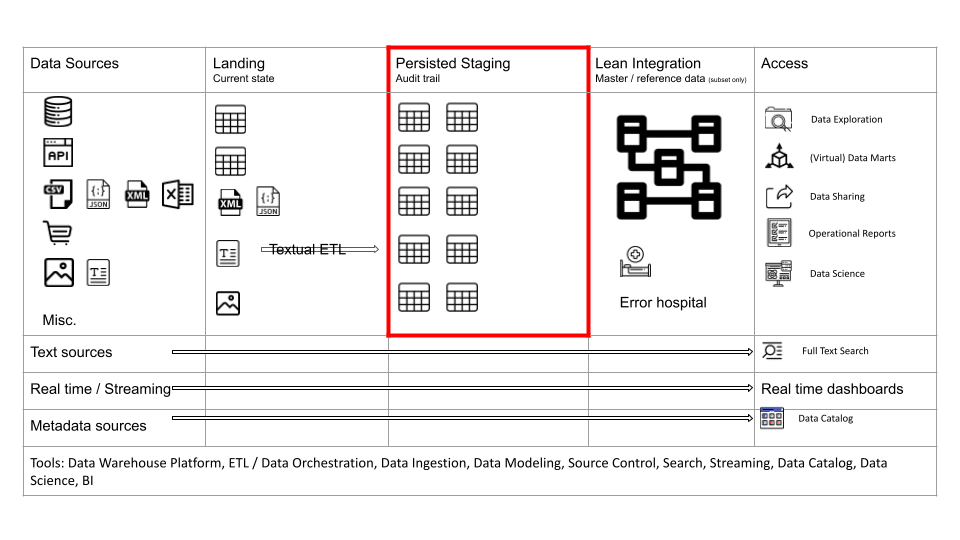
Furthermore, we can also keep any historic changes to the data structure itself, e.g. when a column is renamed you can keep both the original name and the new name. This is known as schema evolution or schema drift.
Storing a full audit trail and schema drift has significant benefits. You can run Point in Time queries that will tell you what your data looked like at any point in the past. You don’t have to take snapshots. Snapshots can be created dynamically from Persisted Staging. Using Persisted Staging you can rebuild, recreate or backfill your downstream models and layers.
In the early days of data analytics, only data engineers and downstream processes accessed Staging. However, the Staging area has evolved significantly. Other consumers and processes now can access the Staging area. I will talk more about the various consumers of Staging when we talk about the Access layer.
Using metadata and configuration files, we can fully automate the process of loading the Landing and Staging layer. Using metadata, we can also fully automate audit trail and schema drift.
This is what an audit trail might look like in Persisted Staging for a Person table
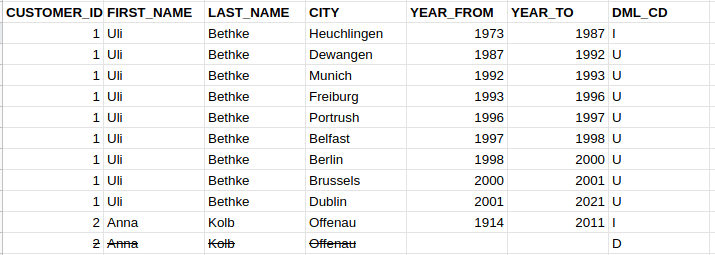
This is what the current state of the table would look like in the source system and Landing.

Implementing a data lake on Snowflake
Snowflake data lake anti patterns
Before we look into best practices of building a data lake on Snowflake, let’s discuss some anti-patterns that I come across frequently.
Implement the data lake on S3 or Azure Data Lake Storage
As we have seen in previous parts of this blog post, the data lake design pattern is a concept. It is separate from a tool or technology.
Some people immediately think AWS S3, Azure Data Lake Storage or Google Cloud Storage when they hear the word data lake. Building a data lake on object storage is a good idea. It is very well suited for implementing a data lake. It is cheap, scalable and you can store all types of data.
Snowflake stores data in an optimised format on object storage. When you load and ingest data into Snowflake it is converted to its internal storage format and put to cloud storage. I will cover this process in some more detail in a minute.
There is no good reason to build out a separate data lake layer outside Snowflake. Snowflake comes with all the ingredients to build a proper data lake. Rather than creating yet another layer on yet another technology let Snowflake do all of the hard work.
- If you separate your data lake layer from Snowflake you need to implement all the aspects of data governance multiple times.
- Separate implementations for security
- Separate implementations for data access
- Separate implementations for managing roles and users
- Separate implementations for handling
- Separate implementations for metadata management and data lineage
- … and you need to make all of these components talk to each other. Very painful. A real nightmare
- Increased complexity
- Increased number of failure points
- Increased risk of things going wrong
- Significant increase in the implementation effort
- Running queries against data on object storage outside Snowflake, e.g. through external tables is significantly slower than running them against data stored in Snowflake’s internal format.
Don’t do this
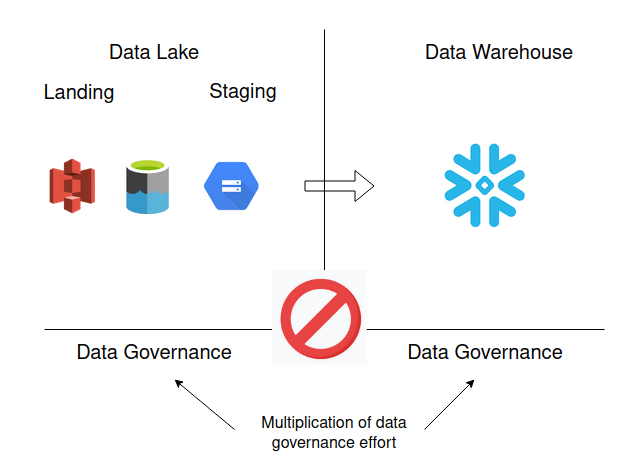
- Don’t implement a data lake as a standalone solution without consideration of the specific needs of downstream consumers.
- Keep it simple. Don’t use different technologies for your data lake and for your data warehouse. Build it on the same platform. Build it all on Snowflake.
- Snowflake has a huge number of native connectors for fast access to external data lake consumers. The Snowflake partner ecosystem is huge and it is highly likely that your tool of choice to consume data in the Snowflake data lake is supported.
Not differentiating between data lake consumers
In the section on data lake consumers I mentioned that access to the data lake is not restricted to the data warehouse. However, while the downstream processes of the data warehouse by default access the data lake other consumers have different access requirements.
Don’t do this
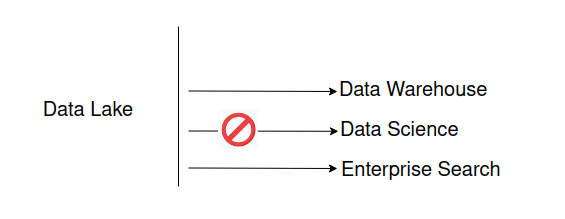
The type of access is determined by the use case.
Data science
Rather than accessing the raw source data, data science use cases should access cleansed and integrated data wherever possible. This means that they should access the integration layer or the data marts layer. Sometimes data is only available in the data lake layer. For those scenarios, data scientists can access the data lake layer directly. Any learnings such as key relationships, findings, or data quality issues from exploring the lake data should be documented and reused for other downstream use cases.
Enterprise search
Another use case is enterprise search. For this use case we need to build an inverted index for a textual search engine such as Apache Solr. You can refer to my blog post on enterprise data architecture for more details on this use case. For enterprise search we access the data lake directly.
Do this
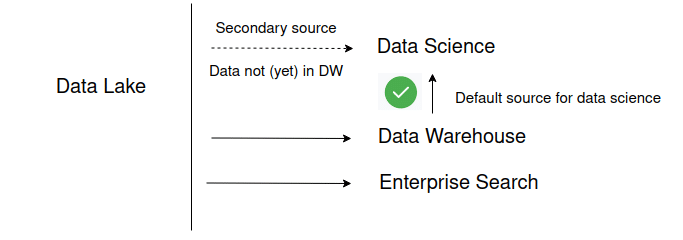
Implementing a data lake on Snowflake
Data ingestion
Structured data
When it comes to data ingestion to landing and staging you can use a mix of native Snowflake and third party tools.
For ingesting structured data from databases in near real time we use Qlik Replicate to read transaction logs of a database. Qlik is a very robust solution. It is also available as a managed service and white labelled as AWS Database Migration Services.
For ingesting structured data from SaaS APIs we can recommend Airbyte. It is an open source tool for ingesting data from common SaaS APIs. There are a lot of things to like about Airbyte, e.g. an SDK for developing connectors that can in turn be monetised.
For Excel files you can use Snowflake Excelerator. It is an open source plugin for Excel developed by Snowflake. You can use it to load Excel files or you can connect it to Snowflake to view data and create dashboards.
For ingesting data in near real time from object storage you can use Snowpipe. Snowflake also ships with a connector to Kafka.
You can use the Snowflake copy tool to load text files (CSV, TSV) directly to Snowflake. Snowflake has a new feature that automatically infers the schema and data types when ingesting text data.
Semi-structured data
You can store XML or JSON directly in Snowflake in a Variant data type. The Variant data type is optimised for storing and querying JSON and XML documents using SQL.
Converting JSON and XML to a relational format still requires a lot of manual effort on Snowflake. That is why we have created Flexter. Flexter converts any XML or JSON to a relational format on Snowflake. It handles any type, volume and complexity.
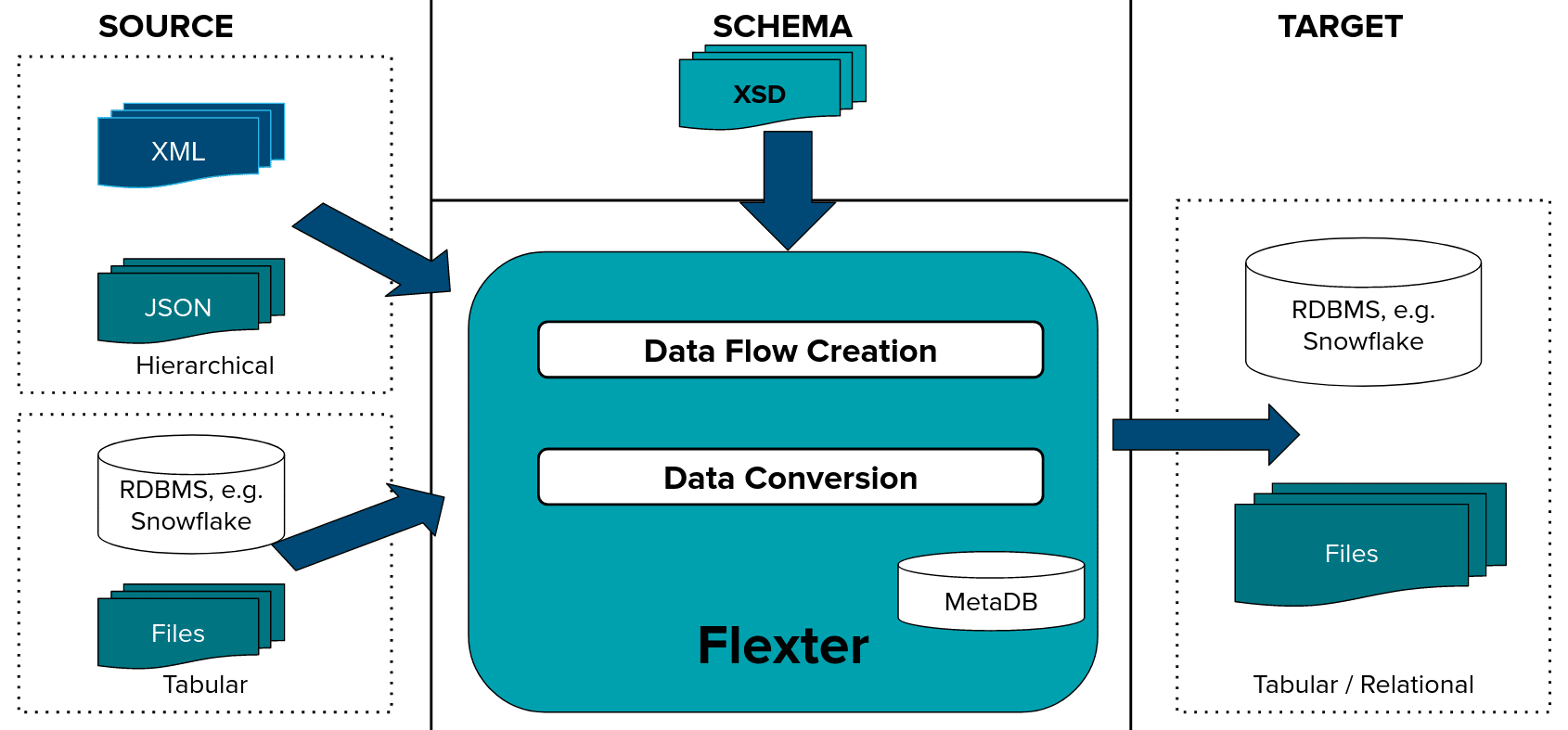
Converting semi-structured data to Snowflake is a two step process.
Step 1: The data flow creates the logical and physical target schema and maps the source elements in XML / JSON to target table columns.
Step: The data conversion converts XML or JSON documents to the relational and optimised target schema.
Unstructured data
Unstructured data includes a range of diverse types, e.g. free text, images, audio and video. I have extensively written about these formats in my blog post about reference data architecture.
The term unstructured data is misleading. This type of data has structure. However, structure needs to be imposed on this type of data. There are a lot of different techniques to detect structure inside unstructured data, e.g. entity resolution, summarisation etc. I have covered all of these in the aforementioned article.
We land unstructured data on object storage and then impose structure using Snowpark or other third party tools such as AWS Comprehend.
Snowflake offers many great features of working with unstructured data:
- You can store files in a Snowflake internal stage (or less desirable as outlined above in an external stage on S3, ADLS etc.)
- You can define access control on files and implement data management and governance directly inside Snowflake against your documents and files. Data governance is a first class citizen for file management in Snowflake.
- You can create scoped, and pre signed URLs for download of files through applications.
- You can use Snowflake’s data sharing feature to share unstructured data
- You can process unstructured data using external functions, e.g. for text analytics purposes
- You can process unstructured data and files using Snowpark
Looking under the hood of data ingestion
Let’s have a look at some technical aspects of ingesting data to Snowflake and see how it compares to Databricks
Both Snowflake and Databricks separate compute from storage and you can scale the layers independently of each other. Both Snowflake and Databricks store data on object storage, e.g. S3 on AWS or Blob Storage on Azure.
Both Snowflake and Databricks can read different types of data such as text, JSON, Avro, ORC, Parquet etc. directly from object storage through external tables. However, both platforms work and perform best when you convert the data to an internal storage format. In the case of Databricks this is called delta format or delta lake. For Snowflake the format is called Flocon De Neige (the French word for Snowflake) or FDN for short.
Before you can convert your data to an optimised storage format you need to put your data to object storage in the cloud. In the case of AWS this is S3. Once you have the data on S3 you can convert it to the optimised storage format respectively.
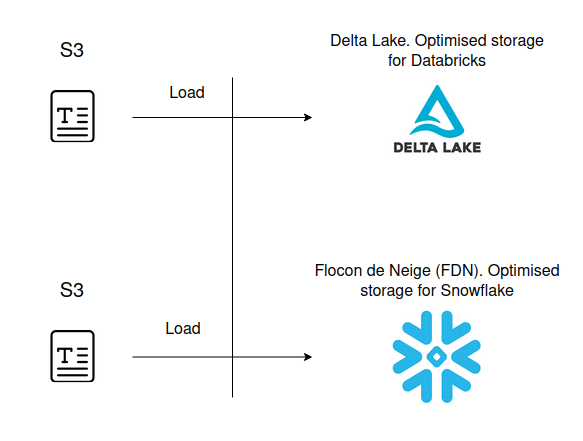
Apart from the conversion to the delta format we also need to optimise / compact the data on Databricks for most use cases. Compaction addresses the small files problem and consolidates many small files into larger files to improve performance. You can either optimise your tables manually or let Databricks apply auto-optimisation. Databricks also recommends to collect table and column statistics to improve the quality of the execution plans of the Cost Based Optimiser. On Databricks this is a separate step. On Snowflake this is done automatically when loading the data.
As you can see the whole process of converting data to a suitable storage format is very simple on Snowflake and more or less fully automated. On Databricks the process is more involved, more complex and less automated. There are various scenarios you have to take into account such as streaming, merging etc. when making decisions.
We loaded some large tables to Snowflake and Databricks (from TPC benchmark). Conversion comparison
| Table name | Raw (size) | S3 gzipped (size) | Snowflake 4XL | Databricks 128 nodes (core and memory equivalent to 4XL) | ||
|---|---|---|---|---|---|---|
| Size | Conversion time | Size | Conversion time | |||
| product_reviews | 123 GB | 56.5 GB | 48.2 GB | 22.3s | 81.6 GB | 22s |
| date_dim | 15 MB | 3.7 MB | 2.8 MB | 1.7s | 3.5 MB | 48s |
| item | 2 GB | 900.8 MB | 725.1 MB | 13.8s | 1.0 GB | 46s |
| store | 1 MB | 370.8 KB | 365 KB | 691ms | 406.0 KB | 27s |
| store_sales | 20 TB | 6.7 TB | 5.7 TB | 21min 58s | 6.6 TB | 31m 18s |
| store_returns | 958 GB | 349.7 GB | 309.8 GB | 1min 23s | 383.3 GB | 1m 40s |
| web_sales | 28 TB | 9.3 TB | 7.9 TB | 31min 46s | 9.4 TB | 44m 23s |
| web_returns | 1 TB | 386.4 GB | 372.5 GB | 1min 46s | 443.9 GB | 2m 7s |
As you can see the conversion process on Snowflake is both faster and more efficient. Snowflake more efficiently compresses the data than Databricks. This will reduce your storage costs. However, more significantly it will reduce the amount of time the database engine has to spend scanning your data. The less data to scan the faster the query performance and the less $$$ you spend on compute.
For both platforms you can apply additional optimisation techniques. In the case of Snowflake you can apply clustering, search optimisation (secondary indexes), and materialised views. In the case of Databricks you can apply zorder (the equivalent of clustering) and table partitioning. Databricks does not support secondary indexes or materialised views.
We have come across other data ingestion limitations on Databricks.
Databricks does not ship with a proper information schema for querying metadata. You need to write awkward code to get to this information. This should be a showstopper for implementing a data lake for most organisations in my opinion.
Snowflake has a nice feature to handle errors when loading files. I am not aware of a similar feature on Databricks.
The partner ecosystem on Snowflake is significantly bigger than on Databricks giving you more choice and options to implement a data lake.
Data governance
If you don’t build proper processes and governance around the data lake it turns into a swamp. Early data lake implementations frequently suffered from this problem.
Snowflake has all the data governance ingredients to prevent your data lake turning into a data swamp. I have listed a few of those features
- Role based access control
- Dynamic data masking
- Information schema for metadata management
- Error logging
- Data classification
- Object dependencies
- Encryption
- Authentication
- Authorisation, e.g. column and row level security
- Auditing access control
- Logging
Consuming data downstream
Sometimes you need to consume data outside Snowflake, e.g. rather than using Snowpark for data science you might already use an existing data science platform such as AWS Sagemaker.
Snowflake has very rich connectivity and a huge ecosystem of partner companies.
Beyond connectors and drivers, the Snowflake ecosystem also includes Snowflake Marketplace, where organizations can access trusted third-party datasets for analytics and data enrichment. For example, Sonra publishes a Canadian postal code dataset on Snowflake Marketplace that can be queried directly for geographic enrichment without the effort of sourcing and maintaining reference data internally.
- Snowflake Connector for Python
- Snowflake Connector for Spark
- Snowflake Connector for Kafka
- Node.js Driver
- Go Snowflake Driver
- .NET Driver
- JDBC Driver
- ODBC Driver
- PHP PDO Driver for Snowflake
- Snowflake SQL API
You can find out more about the connectors from the connectors and drivers page in the docs.
Conclusion
The data lake is a design pattern that has been around since the beginning of data warehousing. However, there have been some recent upgrades and you could call a data lake a staging area 2.0.
- A data lake stores the raw data from the operational source systems. No transformations are applied to the data during the ingestion to the data lake.
- A full audit trail of source data is kept in the data lake. We can query the state of the data at any point in time.
- Schema evolution is applied to the data lake, e.g. a process for handling a dropped column is implemented.
- The implementation of a data lake can be automated using metadata and configuration files.
- Data in the lake is consumed by users with different needs. Access is not limited to data engineers and downstream ETL processes for the data warehouse.
- Access, authentication and authorisation to the data lake needs to be actively governed and managed. It requires the design and implementation of various policies and processes.
The data lake design pattern can be implemented on a variety of tools and technologies. Snowflake is a great fit for implementing a data lake. The Snowflake data cloud stores data on object storage which is a perfect fit for a data lake as storage is cheap and scalable. Storing a Terabyte of data is just $20 per month.
- When implementing your data analytics use cases on Snowflake don’t make the mistake of implementing your data lake on unmanaged object storage outside Snowflake. You will create a lot of headaches for yourself:
- You will need to implement data governance and data access multiple times across different technologies.
- Data management and access is disjointed
- You will increase the risk of data management issues such as data breaches
- Don’t treat all downstream consumers of the data lake the same. Some consumers need default access to the data lake, e.g. ETL engineers. Other consumers such as data scientists should access the data warehouse by default. Only for scenarios where data has not (yet) made it to the data warehouse should data scientists be provided with access to the data lake.
Designing an enterprise data lake requires careful planning across storage tiers, governance layers, and ingestion paths. If you need strategic architectural oversight to lay out your environments, our Snowflake data architecture and advisory solutions team is available to help design your deployment roadmap.
This brings me to the end of this blog post. If you need to implement a data lake on Snowflake make sure to reach out to us. Sonra has been working with Snowflake for the last five years. We were one of the first partners in EMEA. Our consultants are Snowflake certified and I am a Snowflake Data Superhero. We also sit on the Snowflake Partner Advisory Council.
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: