XML to Redshift – Parsing, Loading, & Schema Tips (Guide)


Working with XML data in Amazon Redshift feels like running a marathon in flip-flops—clunky, frustrating, and unsupported at every turn. Unlike its cousin, PostgreSQL, which offers an XML data type, Redshift leaves developers scrambling for creative workarounds to store, query, or parse XML data.
If you’ve ever attempted to load XML to Amazon Redshift, you’ve likely felt the pain of:
- Manually mapping your source XML’s tags and elements to the Redshift’s rows and columns,
- Dealing with Redshift’s VARCHAR column limit of 64 KB for XML data, forcing you to chop and squeeze your data into place,
- Writing manual ETL scripts to handle nested structures and varied content types,
- Updating your manual code and parsing functions every time the source XML changes,
- Resorting to parsing XML with Regex and string manipulation, only to find that it’s like fixing a leaking boat with duct tape,
- Struggling with performance bottlenecks caused by these manual makeshift solutions, making processing painfully slow,
- Not being able to utilise your XSD to create a schema in Redshift,
- Performing multiple nerve-wracking SQL test queries to ensure your data makes it to Redshift uncorrupted and error-free.
If you’re like me, coming from platforms like PostgreSQL, SQL Server, Oracle, or Snowflake—where XML handling is easier—you’ve probably found all these challenges frustrating and unexpected.
But don’t worry—there’s a way forward.
To help you navigate XML to Amazon Redshift without losing your mind, I’ve compiled this blog post to share insights from recent large-scale XML to Redshift projects I recently tackled. I tested and evaluated various options for parsing, loading, and querying XML in Redshift, uncovering which solutions are dead ends and which are practical, efficient, and worth your time.
In a hurry? Here’s a TLDR:
Key Takeaways
- Loading XML into Redshift is fraught with challenges, as Redshift treats XML as a second-class citizen,
- Loading XML to Amazon Redshift can take place according to two ways:
- Breaking your XML into smaller chunks and loading them directly into Redshift’s VARCHAR columns,
- Or, what would make more sense would be to either flatten or normalise your data into tabular format that can be written to Redshift according to a schema,
- Several options can be found online and claim to be able to deal with Redshift XML parsing and converting deeply nested XML to tabular format that can be loaded to Redshift (spoiler alert: not all deliver on their promises):
- Using only Redshift and parsing XML with regular expressions and string manipulation functions,
- Using AWS Glue and its Crawlers feature to infer schema from your XML source files,
- Using AWS Lambda or Elastic MapReduce (EMR).
- Using Flexter, the all-in-one, automated solution to convert to Redshift.
- Based on my testing, you may be surprised that only one solid option exists for automated XML to Redshift. It can help you:
- Use state-of-the-art normalisation algorithms to store your source XML data in tabular format in Redshift,
- Optimise the schema in Redshift by analysing and simplifying parent-child relationships in the source XML,
- Utilise XML Schema (XSD) as input to directly extract constraints on data types and values and include them in the target schema,
- Get automated documentation generation (ER diagrams, Source-to-Target maps, schema diff) that will help you with schema evolution in the long term.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Setting the stage – XML to Redshift basics
Redshift is built on PostgreSQL, but while PostgreSQL provides a native XML data type, Redshift lacks direct support for XML storage and manipulation. This means it lacks XML support in terms of both format and function.
Handling XML with Redshift is tricky from start to finish. While other databases let you follow a standard set of steps, Redshift throws a wrench in the works, making the process far more challenging.
This is why I’ve been searching for an automated XML to Redshift solution, which simplifies things and allows me to focus on important parts of my projects.
Before exploring alternative approaches and an automated solution to simplify your life, let’s first review the two traditional methods for XML to Redshift.
Loading XML directly to Redshift’s columns
Redshift, an Online Analytical Processing (OLAP) database, excels at handling large-scale structured data. It also supports semi-structured formats like JSON and Parquet via SUPER columns.
The SUPER data type enables schema-on-read for these formats, but can you load XML directly into SUPER? No, you can’t—SUPER doesn’t support XML.
Your only option is VARCHAR columns, which can store XML in chunks of up to 64kB. This means splitting your XML into smaller pieces and loading them as text to Redshift columns. Here’s how schema-on-read for Redshift looks on a conceptual level:
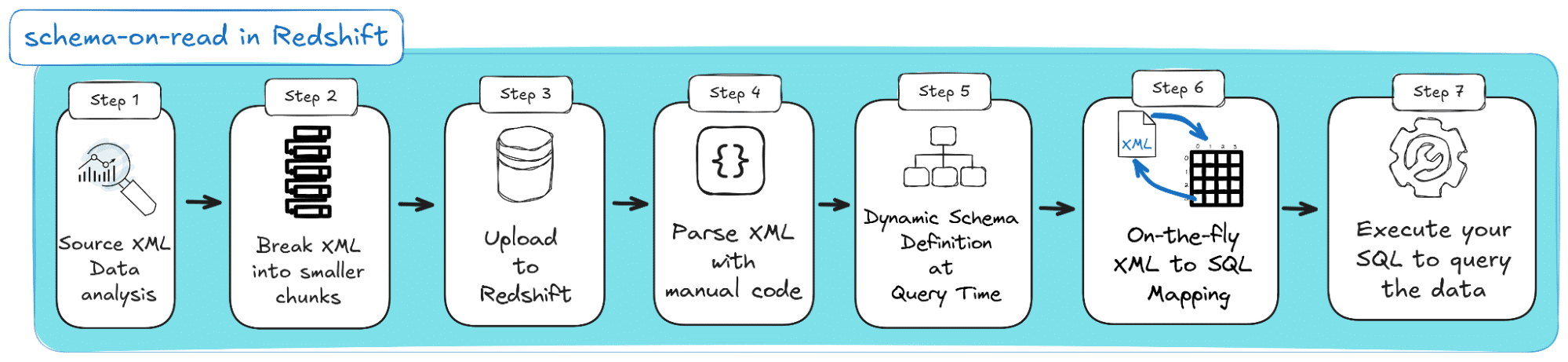
The steps begin with analysing source XML data in Step 1 and dividing it into smaller chunks in Step 2. Then, you must upload it to Redshift’s columns in Step 3. Each time you query Redshift for your data, you must follow three more steps: Parse the XML data with manual code (Step 4), dynamically assign it to your desired schema (Step 5), and map XML elements to rows and columns in Step 6. In Step 7, you can finally push forward your queries and consume the data.
Sounds tedious? That’s because it is. This approach is impractical and inefficient for larger-scale projects requiring frequent queries on massive datasets.
The Schema-on-read vs Schema-on-write debate
Deciding between schema-on-read and schema-on-write is a key step in any XML to database project—a topic I’ve explored in depth elsewhere on this blog.
At first glance, loading XML data into Redshift might seem like schema-on-read. But here’s the catch: unlike databases with native XML support, Redshift requires you to manually parse the XML after loading. This adds complexity to your setup and drains significant computational resources during queries.
Schema-on-read works well in data lakes, where queries are rare or not time-sensitive. But Redshift, built for structured, high-performance analytics, thrives on schema-on-write.
If you’re eyeing XML to Redshift, you’re likely building a data warehouse for large-scale analytics. In this case, schema-on-write is your best bet—transforming and structuring data upfront unleashes Redshift’s full potential for fast, efficient querying.
Parsing and converting to tabular format in Redshift
The smartest strategy for XML to Redshift is to parse and convert your XML into a tabular format before loading it. Trust me, your future self (and AWS bill) will thank you.
A schema-on-write approach is like giving your source XML data a makeover—analysing its structure, organising its content, and mapping it to a Redshift-friendly relational schema. It’s all about doing the hard work upfront so Redshift can focus on what it’s good at delivering blazing-fast analytics.
Choosing the schema-on-write path puts you on the right track, but be prepared—there’s still a significant amount of manual effort between planning and successful implementation!
Here are the steps that are required to realise the schema-on-write approach:
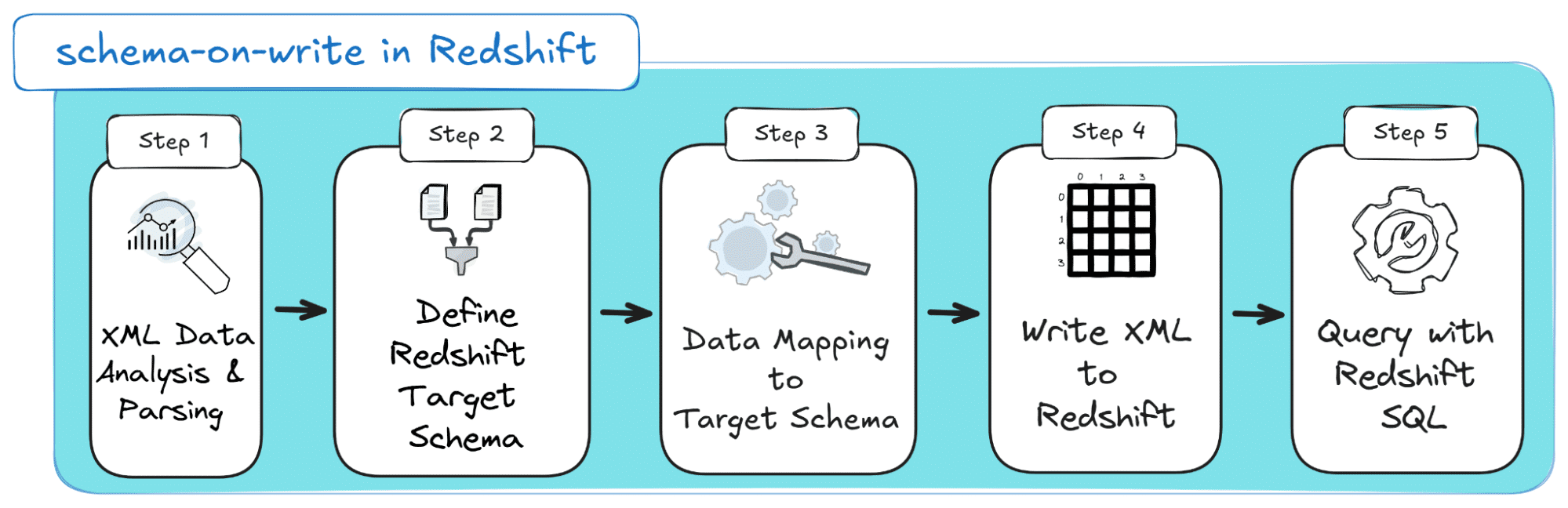
The schema-on-write process for Redshift kicks off with analysing and parsing your XML in Step 1. Step 2 is where the challenge begins—crafting a Redshift-compatible schema, requiring sharp planning to map XML elements to relational tables. Then comes Step 3, the heavy lifting: manually transforming XML data to fit your schema, which demands time and attention before loading it into Redshift (Step 4). Step 5 involves querying your data when you need it.
The Pain Points of XML to Redshift
The schema-on-write approach might appear seamless when outlined conceptually. However, beneath the surface lie many challenges that aren’t revealed until you’re deeply involved in the implementation.
Having tackled multiple XML to Redshift projects firsthand, I’ve faced countless obstacles that make progress feel like an uphill battle.
Just to give you an idea of the pitfalls I’ve faced, I’ve compiled a list of the most significant Pain Points you’re likely to encounter when writing XML to Redshift:
- In Step 1, XML data analysis demands a deep understanding of both content and structure. To build a manual approach with a robust XML parser on your own, you need years of specialised XML knowledge and a small team only to build this parser.
- Suppose you don’t try to make your parser robust enough for different XML test cases and overfit it to your specific XML structure and content. In that case, any small change to the source XML necessitates refactoring the manual code to accommodate the updated XML source.
- ETL tools can be used for XML to Amazon Redshift, which may offer some libraries for XML handling, but none of these tools can automate the steps without you writing manual code. You still need to go hands-on to load XML data to Redshift.
- Most teams that decide to go hands-on for XML to Redshift will, at some point, resort to Regex and/or string manipulation to parse edge cases of XML files. This does not only complicate the process but also makes it resource-intensive and expensive.
- Depending on your project needs, defining the target schema can be particularly challenging. Usually, here, you need to understand the difference between flattening and normalisation and be able to apply it to your project:
- On the one hand, for smaller-scale projects, you may decide to proceed with flattening your XML,
- But for a larger, long-term project, you must consider normalising your XML since flattening has been proven to have some restrictions.
- On the one hand, for smaller-scale projects, you may decide to proceed with flattening your XML,
- If this is your first or second XML to Redshift project, it’s common for those without much experience to assume that flattening the XML is sufficient, only to discover later that normalisation is needed to continue working on the project.
- Even if you develop a target database schema based on normalisation principles, how do you know it is optimal for your application? What if, based on some database design decision, the target database schema can lead to more efficient storage and querying, leading to savings in your AWS bill?
- You will need to manually create all the Redshift DDL commands to re-enter the constraints in Redshift. This is an overhead effort if you already have an XSD for your XML.
- Now, consider this: What happens when you need to make even minor changes to the XML or XSD? You’re forced to update the target database schema as well. Imagine the convenience of a tool that seamlessly takes the XSD as input and handles this for you.
- Mapping XML to Redshift columns adds to the workload. And how do you keep track of this mapping as your project evolves? You need to produce your own Source-To-Target maps and update it accordingly while keeping track of the versions.
- Even if you belong to the small user group interested in the schema-on-read approach, it isn’t a real option due to Redshift’s 64kB column limit and the lack of XML support for the SUPER datatype.
- One way to use the SUPER datatype options would be to convert your XML to JSON, and then write the JSON file to Redshift in a SUPER datatype column. But then again, you would have to get your hands dirty with XML to JSON, except if you use an automated XML to JSON converter.
- Writing JSON to Redshift also has its limitations, so schema-on-read with JSON to Redshift is not an ideal option.
- If XML to Redshift is hard enough for simple XML files, what happens if you need to handle large XML or large volumes of XML files?
- Your manual approach would need to have scaling features for high volumes of XML files: scaling up (using a more powerful CPU, more memory, and storage) and scaling out, which would mean having parallel processing capabilities.
- Streaming features for handling large XML files would require your approach to break the source XML into smaller chunks.
- Your manual approach would need to have scaling features for high volumes of XML files: scaling up (using a more powerful CPU, more memory, and storage) and scaling out, which would mean having parallel processing capabilities.
- I mentioned before that you need to create your own Source-To-Target maps, but the truth is that there are other elements to have a successfully documented XML to Redshift project: schema diffs, Entity-Relationship (ER) diagrams for the target schema, and potentially DDL commands for setting up the schema in Redshift.
- Finally, you should factor in the cost for both the building of a manual approach and what this would mean for your AWS bill for the duration of your project:
- Parsing the XML with non-native commands (or string manipulation and regex) can lead to consuming more resources,
- Flattening the XML into One Big Table (OBT) can lead to cartesian products, with you writing redundant information to Redshift, making querying more resource-intensive and expensive.
- Parsing the XML with non-native commands (or string manipulation and regex) can lead to consuming more resources,
- If this is one of your first XML to Redshift projects, how do you estimate your AWS bills for a manual or ETL script-based approach? How can you ensure the cost is justified compared to a one-time upfront fee in the long run? You’ll likely need to consult or hire an experienced AWS professional.
Are you surprised by the long list of pain points? Trust me, it is better to read about them than to face them in your day-to-day.
But don’t worry—that’s exactly why I’ve put this article together.
The solution? Work smarter, not harder. Automation is your best friend! Modern tools can handle the heavy lifting, effortlessly transforming XML into Redshift-ready tables. Let’s go over your options in the next section.
Options to parse XML and write to Redshift
Option 1: Manual Parsing in Redshift with String manipulation functions and Regular expressions.
If you don’t already have PTSD from your first few assignments when taking “Data Structures and Algorithms 101” in college, an option that you may want to examine is loading XML to Redshift and, from then on, using its string manipulation and regular expressions (i.e. regex) to parse and then query the XML content.
As discussed above, this would be a schema-on-read approach: loading your XML would be relatively “easy” by chunking down the source XML into 64kB parts and writing them to Redshift columns.
Then, to extract data from XML in Redshift, you’d rely on built-in options like REGEXP_SUBSTR and REGEXP_REPLACE. This involves manually building logic to parse XML elements, attributes, and tags across its branches.
The worst part? You’re still in Step 4 of the schema-on-read for Redshift approach, then you would also need to follow the steps to create the DML commands for applying the schema to the data you want to query and map the data from XML to your target rows and columns.
If the details shared up to now didn’t make you just scroll to the next option for Redshift XML parsing, I’ve put together a list of disadvantages for Option 1 (well, it wasn’t that hard):
- While Parsing XML using String Manipulation and Regular Expressions is technically possible, these commands are not built to parse/analyse XML, so the manual work needed to implement such an approach is extensive.
- To implement this approach, you must have specialised knowledge in XML and XML to database concepts. I’ve written elsewhere about a few basic concepts you must master just to get started.
- String manipulation and regular expressions can be surprisingly demanding on your CPU. Regex, in particular, tends to make multiple passes over the same XML data, and if you’re using it repeatedly to pull out different parts—like element values—it starts to add up. As your data grows or your XML gets more complex, this can quickly lead to performance bottlenecks and scaling headaches. Regex is not exactly gentle when it comes to heavy lifting!
- Extra manual work on the parsing and SQL logic is needed whenever the source XML changes. This makes the maintenance of the codebase under this option very expensive in terms of manhours/person-months in the long term.
- If your project involves more than one type of XML, it is hard to imagine how all possible edge cases can be covered with this approach.
- This approach is the definition of ‘reinventing the wheel’ and seems more like a research problem/puzzle than an approach that would be followed in a commercial project.
Option 2: AWS Lambda
Let’s talk about realistic solutions: what if you paired Redshift with another AWS service? AWS services are designed to work well together, often providing straightforward solutions to optimise your data workflows within the ecosystem.
How about trying AWS Lambda to support your XML to Amazon Redshift workflow?
AWS Lambda lets you run code (i.e. Lambda functions) without the hassle of managing servers. It’s event-driven, so your Lambda functions spring into action whenever specific triggers or events occur.
But can it automate your XML to Redshift workflow? Maybe when combined with S3 event notifications?
Unfortunately, Lambda won’t help you implement an automated schema-on-write approach for XML to Redshift. Not only that, but I’m afraid that if you decide to use manual Python to achieve the XML conversion, it will only add extra technical constraints:
- A Lambda function memory can be configured between 128 MB and 10 GB. The amount of memory allocated also determines the proportion of CPU power available to the function.
- This means that in an XML to Redshift scenario, the manual code developed would have to be adjusted never to require more memory than that, which would make it even harder than just running the code on-premises or some other cloud service.
- Regarding data handling:
- The maximum payload size for synchronous invocations is 6 MB for both request and response. For asynchronous invocations, the limit is 256 KB.
- In an XML to Redshift scenario, large files will fail if you send XML data directly as the input payload to the Lambda function. So, you need to consider streaming your XML files.
- The maximum payload size for synchronous invocations is 6 MB for both request and response. For asynchronous invocations, the limit is 256 KB.
- The maximum timeout value is 15 minutes.
And here’s the kicker—if you’re not well-versed in AWS, how do you even begin to estimate the costs of this setup? Honestly, the minor automation perks Lambda offers might not justify the effort compared to a fully manual approach without Lambda.
If I were in your shoes, I’d keep exploring other options—or better yet, just keep reading!
Pro tip
Over the years, I’ve tackled countless XML conversion projects—XML to CSV, SQL, JSON—you name it.
Here’s the deal: don’t waste time reinventing the wheel by manually converting XML. These projects are easily underestimated when planning, especially with less- or non-technical team members involved.
My advice? Don’t let overconfidence shape early decisions. Manual approaches have long and steep learning curves and require way more attention and effort than automated tools. Most of the time, they also end up straining the project budget.
Especially if you’re using XML Data Standards, like ACORD, FpML or HL7, pick an automated tool that uses XSD to generate the target database schema.
Still unsure? Check out my previous post on choosing between Python coding and automated XML conversion and decide for yourself!
Option 3: AWS Elastic Map Reduce
What about AWS Elastic MapReduce (EMR)? Maybe Lambda didn’t bring much for an XML to Redshift workflow, but EMR might just be the heavy-hitter you’re looking for.
Amazon EMR helps you process and analyse large datasets using tools like Apache Hadoop and Apache Spark. In an XML to Redshift workflow, EMR provides a manageable environment for leveraging Hadoop or Spark capabilities.
So does EMR’s focus on large-scale data processing make it a better fit for writing XML to Amazon Redshift?
I’ve analysed a blog post by AWS and cross-checked with the necessary steps to a successful XML to Redshift approach with schema-on-write, and found the following positive points:
- It can let you run a Spark job based on an Amazon EMR notebook that can be easily integrated with S3 and Redshift,
- Amazon EMR notebooks are Jupyter-based notebooks,
- It lets you use spark-xml and Spark DataFrames, which can help you parse simple XML files.
So these points are something. Slightly better than Options 1 and 2. But does it really automate the schema-on-write workflow and alleviate the Pain Points of XML to Redshift?
Not quite. AWS EMR still requires you to get hands-on with manual code for every step of the XML to Redshift workflow. The only “upgrade” is that you write the code in a Python notebook instead of a traditional script.
And the pain points? Yep, they’re still there, waiting for you and your team to tackle. This is because the spark-xml library has its own limitations:
- It won’t help you normalise XML or derive an optimised target schema,
- It has problems with really large and deeply nested XML files,
- XML nodes that contain both text and nested elements (mixed content) are difficult to parse correctly,
- No XSD support,
- The library doesn’t offer robust error handling for malformed or inconsistent XML. If you encounter parsing issues, it could lead to job failures or skipped rows,
- You still have to write all the manual code to handle changes in the XML source files.
These problems of handling XML in Spark are not new. I’ve previously dug deep into why automated XML conversion tools are essential in Spark itself.
With AWS EMR, it’s the same story—you’re stuck reinventing the wheel. When will we see a truly no-code solution for automating XML to Redshift workflows?
Option 4: AWS Glue and the Crawlers feature
While searching the AWS console, I found that AWS Glue was one of my last hopes for automated XML to Amazon Redshift.
Specifically designed to simplify the creation of manual or visual ETL workflows, Glue must have been the automated solution I was looking for.
My hopes were only raised when I found their blog post, which promised to guide me through Redshift XML parsing and analysing highly nested and large XML files.
Especially with Glue’s Crawler features, which can infer the schema and a mapping from my input XML, I can easily automate Steps 1, 2 and 3 of the schema-on-write approach and then just use an ETL job for Steps 4 & 5. Right?
I couldn’t resist giving it a shot. So, I rolled up my sleeves and went hands-on, putting AWS Glue and its Crawlers feature to the test with my XML conversion test cases.
XML to Amazon Redshift with Glue
Below are the steps I followed, which you can easily replicate to achieve similar results (well, there’s a plot twist at the end):
In the first preparatory step, you must sign up with AWS, access the S3 service and create a bucket.
You may want to create an “xml-source” bucket and an “xml-intermediary” bucket. One will store the initial XML file, and the other will temporarily store the crawler result.
If all is completed correctly, your S3 Buckets page should look like this:
Then, you can upload your XML to the “source-XML” bucket by selecting the bucket and “Add files”, as shown in the next screenshot.
One critical step to getting things right in AWS is setting up proper access for services that need to interact with other AWS services.
In AWS, this is done through IAM roles. Don’t worry; it’s simpler than it sounds. You’ll just need to create a role, stick with the default settings, and assign the right permissions—like read and write access to S3 and Redshift.
One positive thing about AWS Console is the search bar at the top, which allows you to access all services. In this step, you just need to search and access “IAM” and then “Roles” from the left side panel, where you can “Create role”.
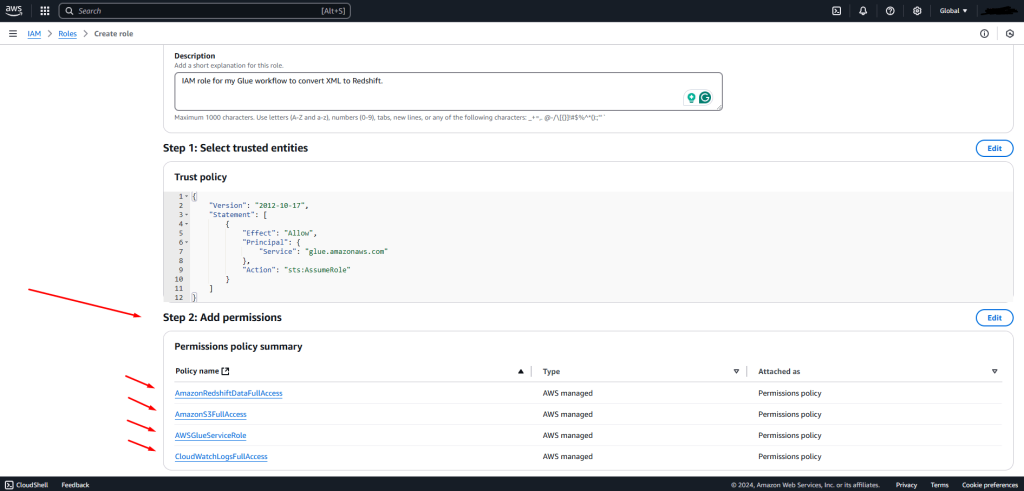
Once you’ve followed the steps after the Create role wizard, AWS will show you a summary of all the configuration options before you hit ‘Create.’ It’ll look like this:
Then, a highly anticipated moment came when I was about to test the AWS Crawlers.
Crawlers are a vital component of AWS Glue, streamlining the automation of ETL jobs, whether visual or script-based. They help you parse your input files (JSON, XML, Parquet, etc.) and derive a schema and mapping from the initial file structure and content to a tabular one.
Here are a few things that you should know about the crawlers feature and Glue, based on their documentation:
- The crawler’s output should first be written to a table in the AWS Data Catalog, rather than directly to S3 or Redshift.
- The AWS Data Catalog is a central repository that stores metadata about data source locations, schemas, and mapping to tabular format. Practically, a database closely integrated with Glue.
- Crawlers can run with default settings or be customised using the “Custom classifiers” feature. When creating a custom classifier, you specify the input file type (e.g., XML, JSON, GROK, PARQUET) and other parameters. For XML, the only extra parameter is the “Row tag” (details later).
- As per their documentation, step 2 of the workflow states: “If no custom classifier matches your data’s schema, built-in classifiers try to recognise your data’s schema.” This means the system will attempt to identify a schema even if you choose a “wrong” classifier. This also means that if the crawler returns an empty table, it has failed to detect any schema.
- The role of AWS Athena in the process: Before diving into the problems, it is important to mention that the AWS Glue and its Data Catalog are already integrated with AWS Athena so that the results in the Data Catalog (e.g. tables) can be quickly viewed in Athena (well, it seems for all other files except for XML).
It’s worth noting that Glue doesn’t normalise XML, which is a significant pain point when working with XML to AWS Redshift workflows. However, it could still prove valuable if it successfully flattens my simple XML test cases.
In that case, Glue could be applied to some straightforward XML to Redshift projects, with less-technical or non-technical developers who would be OK with flattening their XML and the limitations that come with it.
I’ve followed three more steps to set up the crawler to infer a schema for my test cases.
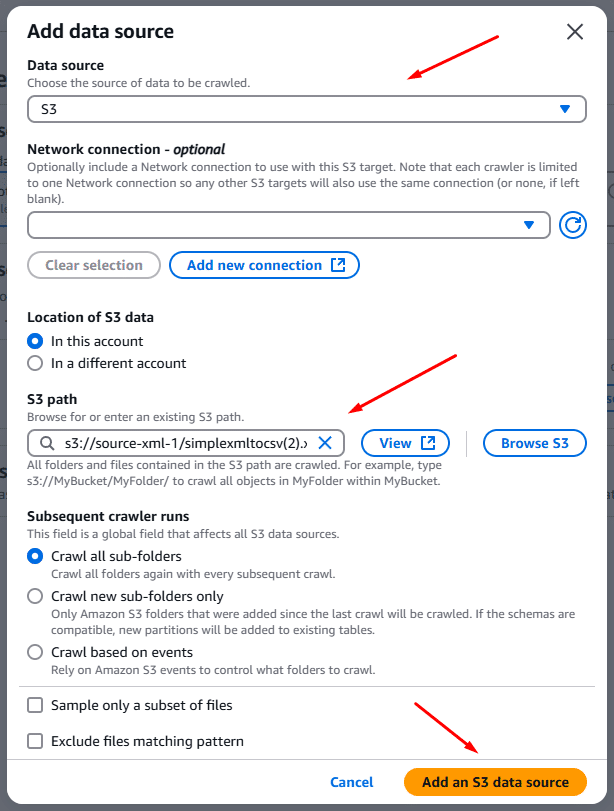
First, I added a data source, which is the source XML bucket from S3, as seen in the picture below:
Then, I added a custom classifier and also indicated a Row tag. According to their documentation, the Row tags guide the crawler and “specifies the XML tag in the file to treat as a row”.
So, based on this definition, the resulting table schema has the columns necessary to represent the XML in One Big Table (OBT), where each row/data record of the OBT was extracted based on XML elements equal to the Row tag.
That would mean I should add “Subtask” as the Row tag for my simple XML test case, as seen below.
After setting up the custom classifier, I also needed to assign IAM roles and create/select the target database in the AWS Data Catalog (to write the crawler’s result).
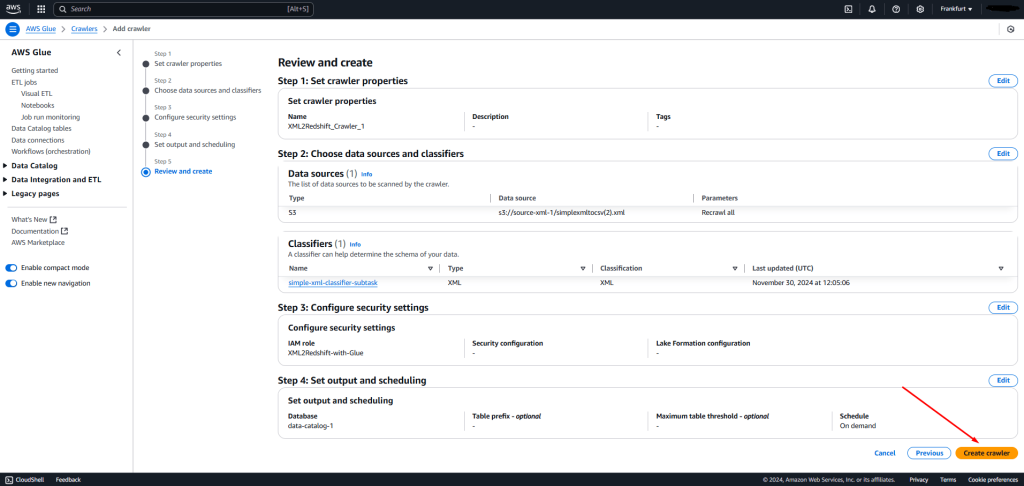
Before you hit the “Create crawler” button, AWS gives you a final opportunity to review all configuration settings, which should look like this:
When the crawler is set up, you have to select it on the Crawlers page to run it. It should look like this:
You can use the “Run crawler” button on the upper right side, and on the lower side of your screen, you can view your past Crawler runs and some metadata.
With all the crawler runs completed, we are ready to move to the final step of writing XML for Redshift!
With our crawler runs completed, we can use the inferred schema and mapping and write our XML to Redshift, right? Glue is just perfect for creating a script-based or visual ETL job to write the data to Redshift, so this should be easy.
Unfortunately, that’s not how it works. This is where the real hardships started: Just because the crawler run completes doesn’t mean it successfully produces the expected results (schema + mapping).
To be exact, Glue didn’t produce the correct schema for any of the XML test cases I tried. Please note that these XML test cases have been tested with a series of online tools, as discussed in my XML to SQL, XML to CSV and other resources on our blog.
Following these links, you’ll find that several online XML to SQL and XML to CSV tools can convert my XML test cases.
Unfortunately, AWS Glue joins a category of tools that underdeliver on their promises regarding handling and converting XML.
This is not a new issue; it is well-known that Glue is a general-purpose tool. According to a publication by the AWS Glue team, it is clearly stated that the ETL process with Glue is viewed as a long-tail problem where each use case requires substantial customisation.
Fortunately, not all tools share this limitation. Some are specifically designed to handle XML conversions to other file formats. Keep reading to discover them.
The failing Crawlers, along with a series of other issues summarised below, led me to abandon my efforts to convert XML to Redshift using Glue in Step 5.
AWS Glue testing results
I’ve tried to run the crawler for some of my simpler test cases, summarised in the table below:
| Test case | Input | Classifier and Row tag | Result |
|---|---|---|---|
| Test case 1: Simple XML test case | Input XML | Tested with a custom classifier and multiple Row tags: “Subtask”, “Task”, “Project”, “Team”, “Department”, and “Company.” | No schema returned (empty table in AWS Data Catalog). |
| Test case 2: XML with multiple branches | Tested without a custom classifier (due to structure with two potential row tags). | No schema returned (empty table in AWS Data Catalog). | |
| Test case 3: Normalised XML to CSV conversion test case | Input XML | Used a custom classifier and row tags “Manager” and “Employee”. | Schema returned but was wrong. Results queried in Athena were also incorrect (tags and elements from source XML were missing). |
Let’s dive deeper into the conversion of Test case 3, called “Normalised XML to CSV conversion test case”, which provided a result for a crawler run but was wrong.
If you download, you’ll notice that this XML file includes simple nesting with <Manager> and <Employees> elements at the same nesting level, while <Employees> has several child nodes with the <Employee> tag. Each <Manager> and <Employee> element, although at different nesting levels, include <EmployeeID>, <FirstName>, <LastName>, and <Position> elements as child nodes.
For this test case, I tried different crawler and custom classifier configurations which all resulted in the following schema:
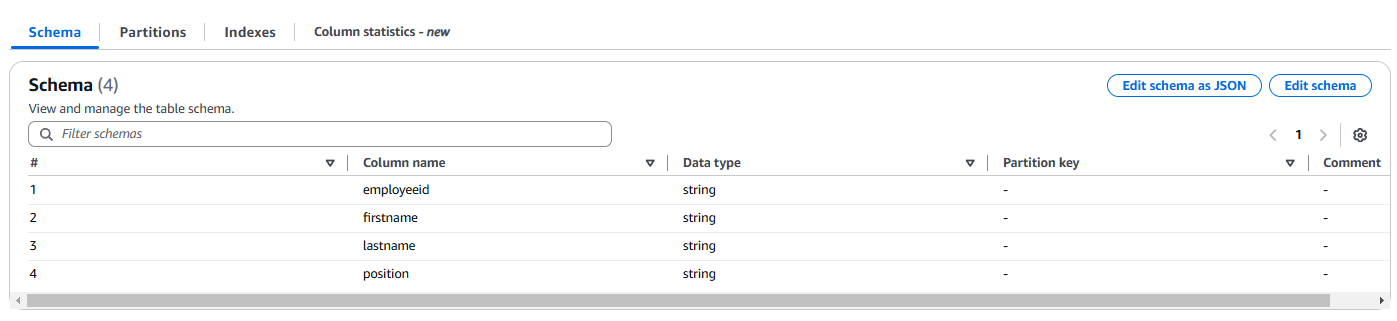
This schema looks correct, but it’s not. This is because while these columns can describe all Manager and Employee elements, the information about which Department each employee belongs to is missing.
So, if the crawler was to infer a flattened schema, it should include the Department ID and the Department name as columns to the flattened table.
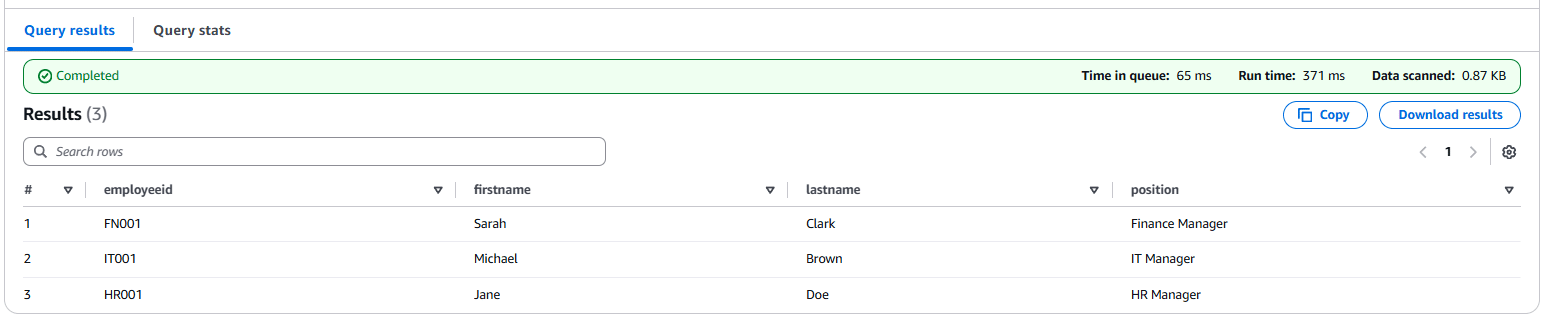
Suppose we follow the extra Athena workflow inside the XML to Amazon Redshift workflow to the Parquet process (as described in the AWS blog post). In that case, the following picture includes the query results:
As you may have noticed, only managers appear in the screenshot, indicating inaccurate mapping in the crawler’s result. The <Employee> elements are clearly missing.
So, it is overall a bit disappointing that I couldn’t get the crawlers to work after testing them with three very simple test cases. And this is not all since crawlers have other “de-facto” limitations that I discovered in their documentation. Here’s a list.
List of problems with AWS Glue workflow
The XML to Redshift process hit an early roadblock when a key feature—promised to automate Redshift XML parsing, schema derivation, and metadata extraction—failed to deliver. Here’s a breakdown of the issues:
Problem 1: I ran into an unexpected issue when I couldn’t even infer the schema for my simple XML test case. Honestly, I was a bit stunned—this was supposed to be the easiest one.
After some digging, I discovered a crucial detail in the classifiers’ documentation: AWS Glue crawlers and classifiers don’t support self-closing tags. That’s when it clicked.
In my test case, the ‘Subtask’ tag was self-closing, which made even this basic XML scenario unworkable for AWS Glue. What started as a small test quickly revealed a big limitation.
Problem 2: To only add to the limitation of the crawlers, as stated in their blog article, the crawlers can’t parse XML files bigger than 1 MB.
Problem 3: Although I read this process in the AWS blog post, I couldn’t believe it would be so exhausting: viewing crawler results in AWS Glue is far more complicated than it looks.
Glue Studio’s AWS Data Catalog acts like a database, storing a table for every crawler run and respective result. It’s tightly integrated with Athena, which is great for fast querying—but here’s the catch: Athena doesn’t support direct querying of the XML schema extracted by the crawler.
Here’s the error you get:
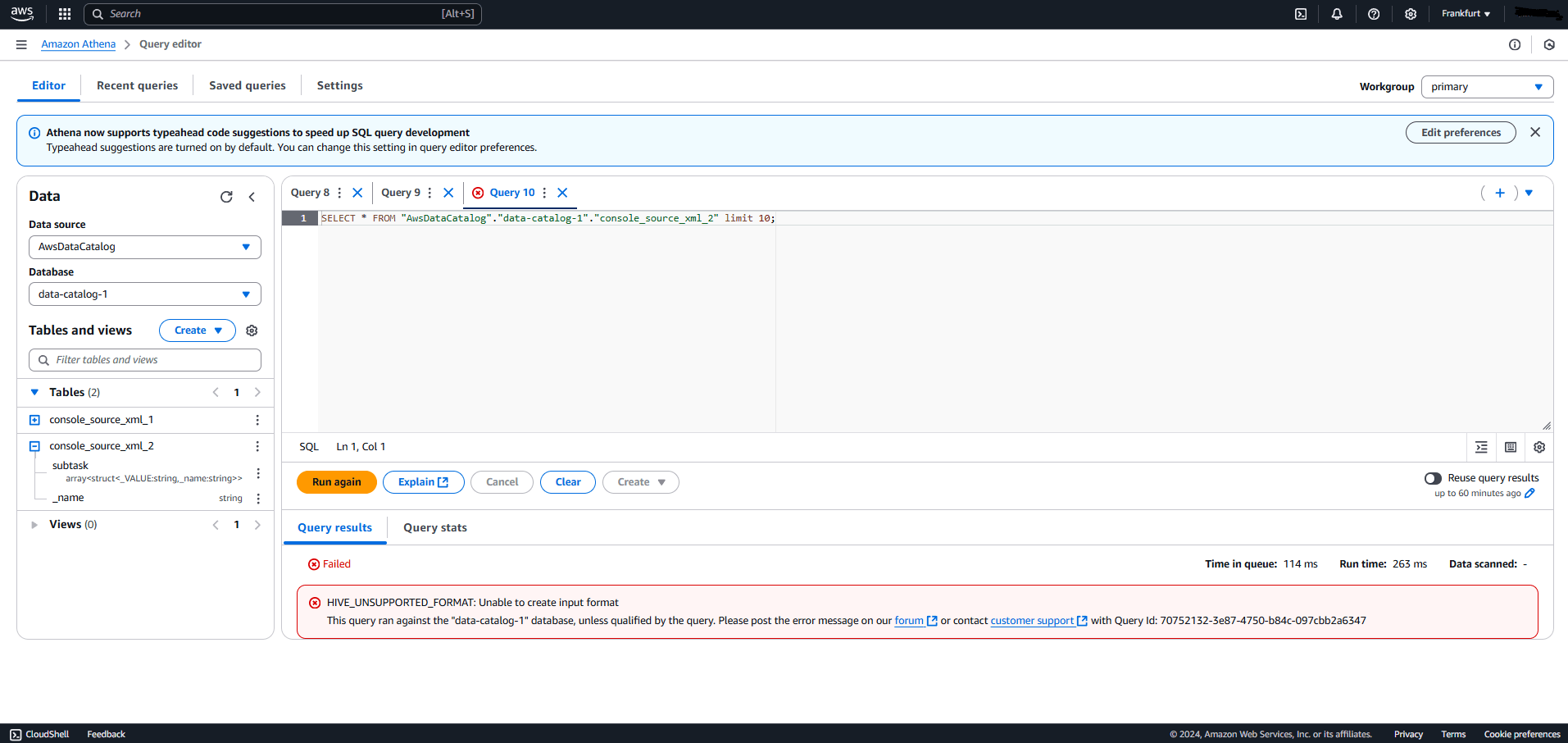
As AWS suggests in their blog post, you must convert it to Parquet by establishing a separate workflow inside the XML to Redshift workflow.
Now, imagine trying to learn the tool or test your crawler outputs. This extra step adds a ton of complexity and turns what should be a straightforward process into something slow and downright tedious. Trust me, it’s not automated at all.
Problem 4: If you haven’t noticed yet, AWS Glue crawlers struggle with even simple XML files, let alone more complex cases like XML with multiple branches (as I showed you with the example with Managers and Employees). This is alarming if you consider that more complex XML cases that usually show up in XML to Amazon Redshift projects.
For example, my deeply nested XML—with 701 unique branches—would be far too complex to manage effectively. Testing it here felt impractical, and the same applied to other edge cases, such as XML with mixed content or namespaces (that I have used to test other conversion tools).
Problem 5: When it comes to Redshift XML parsing, AWS Glue crawlers fall short in inferring data types for your elements. Worse, they don’t support XSD as input, leaving you to define most of the constraints manually.
Problem 6: Despite all these problems, even if your crawlers feature worked perfectly, the schema you end up with will almost always be a flattened table.
Based on my testing and the sources I’ve found online on Glue, no one seems to talk about normalising the XML schema or using branching and other optimisation algorithms that could improve the target schema.
Problem 7: And just a heads up: AWS doesn’t give you a free trial. The moment you perform an action—no matter how small—AWS consumes a minimum DPU, and you’re billed for it.
I learned this the hard way while testing small XML cases to see if the tools worked for me. You can’t experiment for free, and those charges add up quickly. If you’re new to this pricing model or need to justify every dollar to management, it’s a tricky lesson you’ll want to learn before diving in.
Verdict: If these challenges haven’t convinced you yet, let me spell it out: sometimes, the best solution isn’t within the AWS environment—it’s outside of it.
And if you’d rather not lose sleep scrolling through Reddit for answers, keep reading!
Option 5: No-code Redshift XML parsing with Flexter
After slogging through manual scripts, fighting with libraries, and trying out convoluted ETL tools, you’re probably wondering: Is there an easier way to deal with XML and load it into Amazon Redshift? The answer is a resounding yes, and its name is Flexter.
Flexter isn’t just another tool in the sea of potential workarounds for coping with the lack of XML datatype in Redshift —it’s the hero you and I always wanted.

Packed with all the necessary features, Flexter is now the most important part of my toolchain, taking away all of the Pain Points of XML to Redshift in my new projects.
Here’s how Flexter saves the day:
- With Flexter, you don’t have to write a single line of code. It is as simple as downloading the tool, configuring the connection to Redshift, and pointing it towards your XML file or folder containing multiple XML files.
- From then on, Flexter’s state-of-the-art normalisation and optimisation algorithms take over the process and create a target Redshift schema and mapping for your XML.
- Flexter normalises your XML, meaning it can analyse its content and structure and break it into several interconnected tables that can then be written to Redshift in a relational schema.
- Not only that, but its powerful optimisation algorithms can identify artificial hierarchies within the XML file (one-to-many parent-child relationships) and transform them into simpler ones (one-to-one relationships), reducing the complexity of the target Redshift schema. This makes it easier for data analysts and data engineers to work with the converted data.
- With Flexter, you just point the tool towards the file path where the XML are, and the tool handles the conversion no matter the size or volume. It can be configured to scale up or down according to your needs.
- Flexter can be downloaded and used from CLI, called through an API, or deployed to a server (on-premises or cloud).
- It can align with your team’s tech stack, as it can run on multiple operating systems, supports different data sourcing methods (FTP/SFTP, database LOB, object storage, HTTPs, or queues), and can support other file formats conversions such as XML to CSV or now also XML to Iceberg.
- Are you working with an established industry standard that comes with an XSD? Flexter can take the XSD as input and create the target database schema for you.
- Flexter provides you with all the documentation you need to deal with schema evolution in the long term.
- While you just focus on running the Flexter from CLI, once the conversion is completed it will provide you with a Metadata Catalogue. Some resources you will get with it are an ER Diagram for your target schema, a Source-to-Target mapping for the values of your XML to the target schema, and the schema diff every time a change is triggered to the Redshift schema.
- Flexter provides its own monitoring and error logging features on the XML conversion process, which are dedicated to XML handling.
- Don’t forget about the professional services. Flexter’s team is committed to answering any of your phone calls, emails, and support ticket requests, as well as explaining the tool’s detailed documentation.
- 📢 Flexter also supports converting XML to Apache Iceberg and integrates with the AWS Glue Catalog. Together with the recent announcement of S3 Tables support, this gives you yet another option for converting XML to Amazon Redshift. Just use Flexter to convert XML to Apache Iceberg and S3 tables and query the S3 tables using Redshift. What is not to like about it?
And here’s the cherry on top: you can book a free call with the Sonra team, who will guide you through the process and help you convert XML to Redshift in just a few days.
Conclusion
In this post, I’ve presented you with a series of options I’ve been experimenting with in my XML to Redshift projects over the last few years.
Although some of these options may seem appealing initially, they are not the automation you are looking for in an XML to Redshift project. This is mainly because of the following reasons:
- They required too much manual intervention, leaving you buried in scripts and parsers that do not really work,
- They struggled to handle the complexity of real-world XML data (as I showed you with just a few test cases).
- Moreover, accurately estimating the costs of a manual approach—including in-house labour hours and expenses for online resources—can be extremely challenging.
If you don’t want any more scripting nightmares and endless research on tools that are not dedicated to handling and converting XML, there is one way forward: Flexter.
Here’s my advice: stop wasting time trying to fix workflows that weren’t built specifically for XML to Redshift. Trust me, I’ve been there—lost so many hours debugging and troubleshooting—and I wouldn’t wish that frustration on anyone.
Instead, explore the resources below to see how we streamline conversions and migrations to Redshift with Flexter. Once you’re ready, schedule a call with us, and let’s get your project moving!
Further reading
Resources for Efficient Data Loading and Management in Redshift
- Working with JSON in Redshift. Options, limitations, and alternatives
- Converting Trello JSON to Redshift
- Flexter, Informatica, and Redshift work Hand in Hand to convert ESMA XML
- Parsing SQL queries in Redshift for table and column audit logging
- Introduction to Window Functions on Redshift
- Using Apache Airflow to build reusable ETL on AWS Redshift
- The evolution of Amazon Redshift
- Snowflake vs. Redshift – Support for Handling JSON
Guides on converting XML & XSD
- XML to Database Converter – Tools, Tips, & XML to SQL Guide
- Best XML to CSV Converters – Compared by Data Expert
- How to convert XML to Spark Delta Tables and Parquet
- XML Conversion Using Python in 2026
- Complete Oracle XSD Guide – Register XSD & Validate XML
- XML Converters & Conversion – Ultimate Guide (2026)
- XSD to Database Schema Guide – Create SQL Tables Easily
- Converting XML and JSON to a Data Lake
Interesting reads & resources on AWS Services and Glue
- The Story of AWS Glue
- Comparing Snowflake cloud data warehouse to AWS Athena query service
- Process and analyze highly nested and large XML files using AWS Glue and Amazon Athena
- Convert Oracle XML BLOB data using Amazon EMR and load to Amazon Redshift
- Data Warehousing in the Cloud: Amazon Redshift vs Microsoft Azure SQL
- AWS Athena SQL parser for table and column audit logging



