In-memory analytics with Tableau, SparkSQL, and MapR
Last week Tableau released version 9.0 of their data visualisation tool. From a Big Data point of view the nicest new feature was support for querying cached (in-memory) SchemaRDDs (Data Frames as of Spark 1.3).
[big_data_promotion]
In this tutorial I will show you how to connect to Spark 1.2.1 on the MapR 4.1 sandbox with Tableau 9.0.
Pre-requisites:
– Download the MapR 4.1 sandbox
– Install Spark standalone 1.2.1 and configure Hive on the sandbox
– Install Tableau Desktop. A free trial is available from Tableau
– Install the SparkSQL ODBC Driver from Databricks
Adjust Spark default memory
|
1 2 |
cd /opt/mapr/spark/spark-1.2.1/conf vi spark-env.sh |
Change
|
1 2 |
export SPARK_DAEMON_MEMORY=1g export SPARK_WORKER_MEMORY=2g |
Start Spark Slaves
|
1 |
/opt/mapr/spark/spark-1.2.1/sbin/start-slaves.sh |
Have a look at the Spark UI at http://maprdemo:8080/
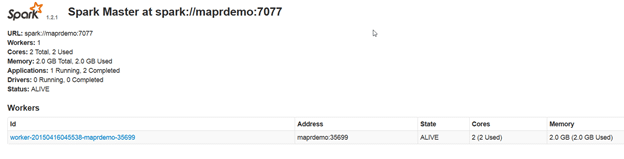
Start Spark Thrift Server on port 10001
|
1 |
/opt/mapr/spark/spark-1.2.1/sbin/start-thriftserver.sh --master spark://maprdemo:7077 --hiveconf hive.server2.thrift.bind.host maprdemo --hiveconf hive.server2.thrift.port 10001 |
Connect with Beeline to Spark Thriftserver
/opt/mapr/spark/spark-1.2.1/bin/beeline
!connect jdbc:hive2://maprdemo:10001
Use username to log on, e.g. mapr.
Leave Password blank
|
1 2 3 4 |
Connected to: Spark SQL (version 1.2.1) Driver: null (version null) Transaction isolation: TRANSACTION_REPEATABLE_READ 1: jdbc:hive2://maprdemo:10001> |
We will now load a JSON file as a temporary table into Spark
Copy file /opt/mapr/spark/spark-1.2.1/examples/src/main/resources/people.json onto the MapR-FS and create a temp table from it.
|
1 2 3 |
create temporary table people using org.apache.spark.sql.json options (path 'maprfs://maprdemo/apps/spark/people.json'); |
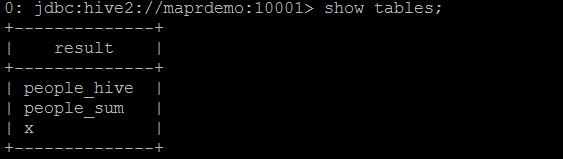
A temporary table persists for the lifetime of the Thrift Server.
It does not register with the Hive metastore and as a result won’t be listed when issuing show tables.
We can view execution details of create table statement at http://maprdemo:4040/jobs/
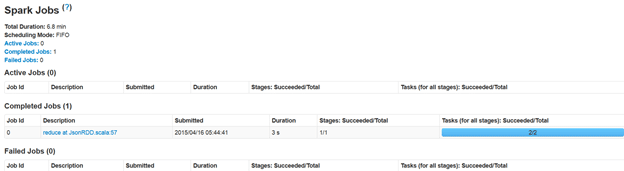
Next we cache the table in memory.
|
1 |
cache table people |
You can get confirmation at http://maprdemo:4040/storage/

If we want to register the table with the Hive metastore and want it to be accessible via Hive we need to create a permanent table.
|
1 |
create table people_hive as select * from people; |
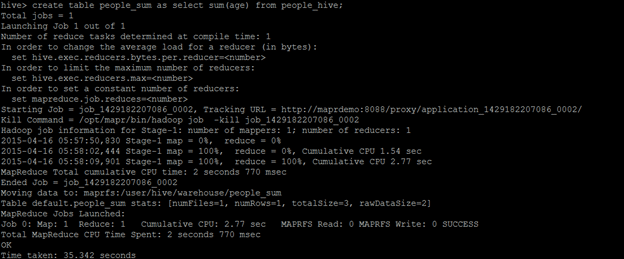
Next we launch the Hive CLI and create a new table
|
1 |
create table people_sum as select sum(age) from people_hive; |
We go back to beeline and cache tables people_hive and people_sum in memory:
cache table people_hive;
cache table people_sum;

Query in-memory tables in Tableau
We have three tables cached in memory. Now we can query them using Tableau. Select Spark SQL as your connection.
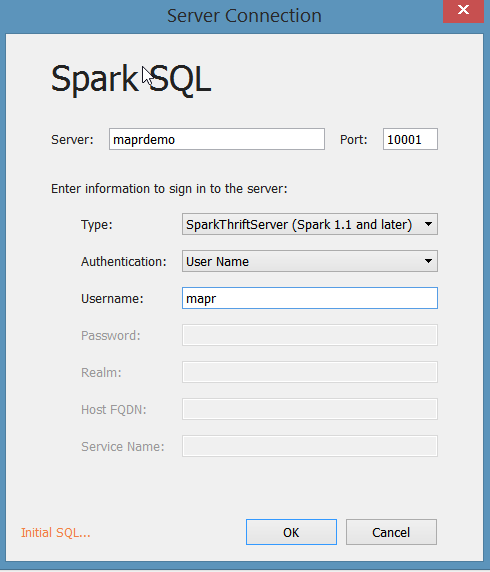
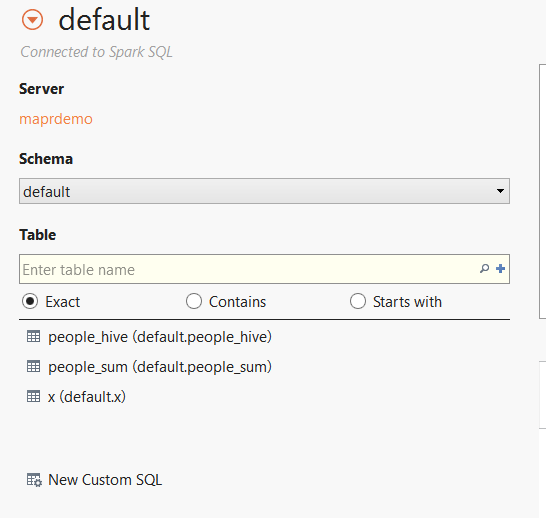
As expected we only see two of the three tables. Remember that table people is a temp table and has not been registered with Hive metastore. As a result Tableau does not know about it when retrieving metadata through the Spark thrift server. We could query it using the Initial SQL functionality in Tableau.
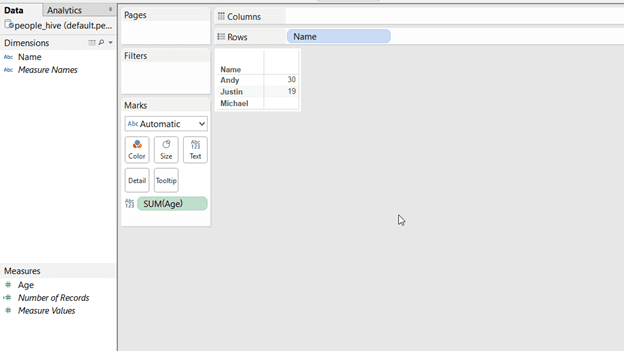
In a last step we create a Tableau worksheet and run some analysis.
What else is there?
You can remove a table from memory by using the uncache table command.
For tuning performance you can set various parameters such as applying in memory columnar compression to cached data.
In beeline or Initial SQL in Tableau use the following command:
|
1 2 3 4 |
set spark.sql.inMemoryColumnarStorage.compressed=true; <strong>Also Important</strong> Sonra are based in Dublin and provide services and hardware around Big Data and Hadoop. Make sure to come to our next <a href="http://www.meetup.com/hadoop-user-group-ireland/events/221077659/">Hadoop User Group Ireland meetup</a>. We will talk about data lakes, puddle, and swamps. |
[big_data_promotion]