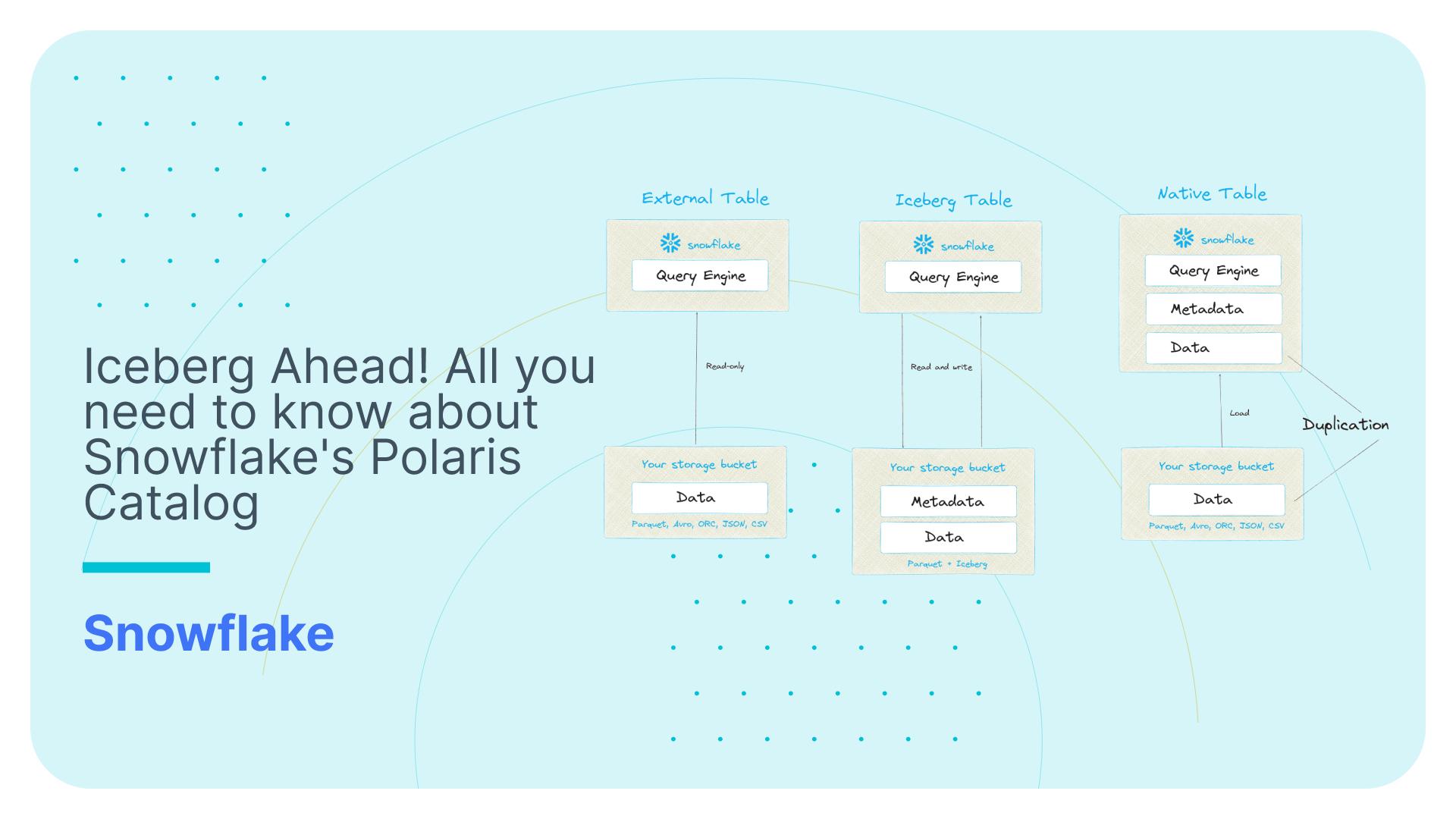
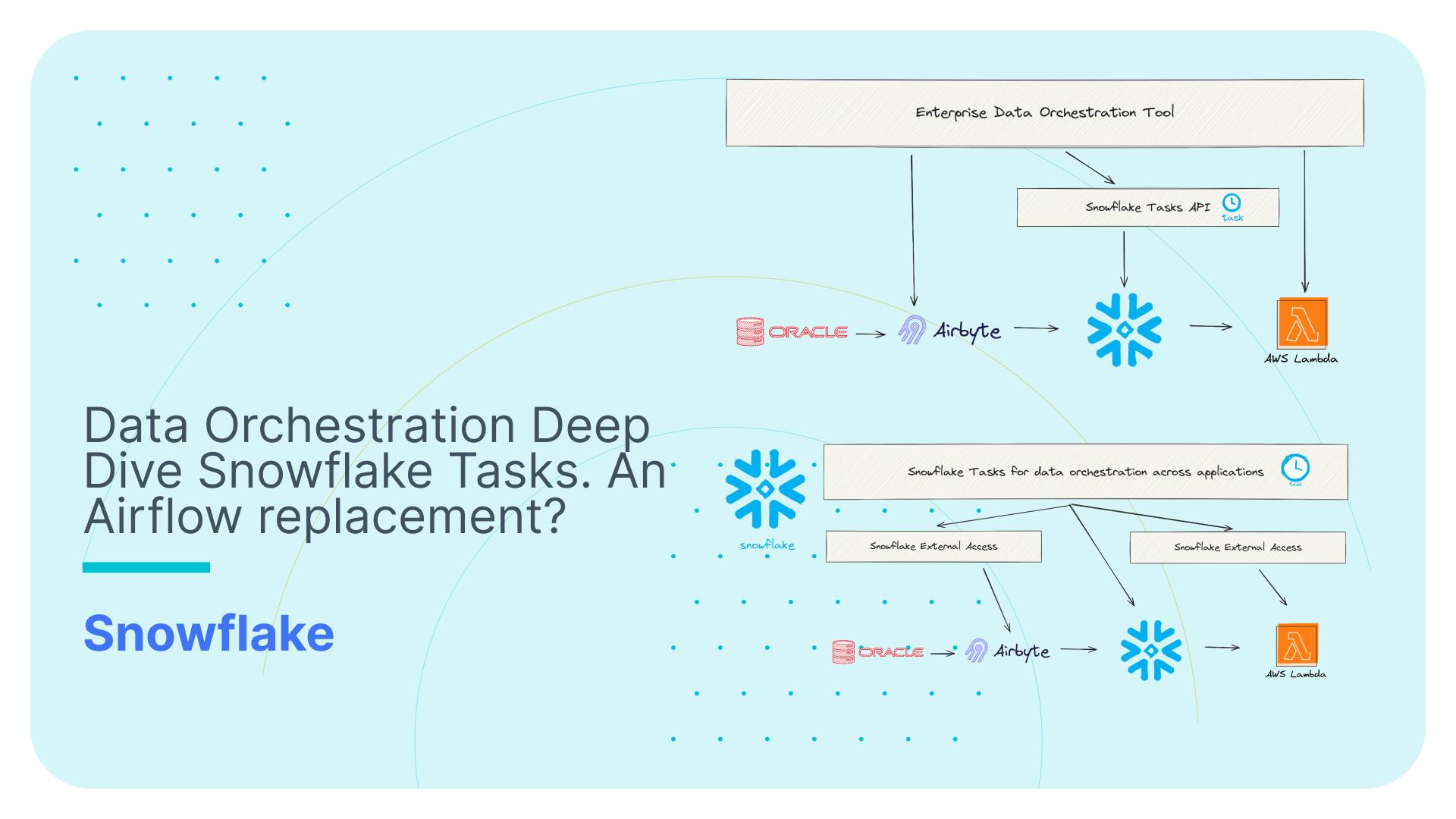
Using Virtual Data Marts the right way
Virtual data marts can be a useful design pattern but there are a few things you should know before you use them.
Virtual data marts are logical views dimensionally modelled on top of an integration layer or a persisted staging area.
Don’t confuse them with data virtualisation or data federation. Virtual data marts are built against a single data store (data warehouse platform). Data virtualisation is a data federation technique across multiple data stores that can be useful in certain edge cases (a topic for another day).
You can mix virtual marts with physical marts, i.e. you can set down the data physically for some fact or dimension tables but not for others.
The advantage of virtual data marts is that they will save you in development time and also when making changes (not Database Change Management).
The main downside is that they tend to perform less well than physical tables in particular for larger data volumes or complex logic.
In certain cases such as snapshots your only option may be to set down the data physically.
There are some other disadvantages of virtual data marts.
- You need to create OUTER JOINS from your virtual facts to the virtual dimension tables. You can’t use surrogate keys. Also hashes are prohibitive due to the huge overhead in compute costs.
- People find it hard to get used to virtual data marts. Don’t underestimate that factor.
- BI tools often require a surrogate key to work well with dimensional models.
I recommend using virtual data marts as the default approach in particular for the first iteration of your dimensional model. You need to have an approach that allows you to quickly turn a virtual data mart into a physical table. Data warehouse automation works well and it just takes minutes to swap out the virtual mart for a physical table, e.g. we have developed such automation on top of Airflow.