How to Parse XML Data in SQL Server


Are you still using fragile OPENXML and messy SQL to wrestle nested XML into relational tables on SQL Server?
You know the drill: It starts as a simple script, but the minute your XML file grows, adds a new attribute, or introduces a layer of nesting, your entire pipeline explodes into a late-night maintenance nightmare.
You’re stuck in a loop of manually adjusting the target database schema, mapping XML values for SQL tables repeatedly, and struggling with a workflow that was never designed for this level of complexity.
There is a better way.
Forget the painful choice between Schema on Read (flexible but slow at the query phase) and Schema on Write (faster, but a manual coding black hole).
It’s time to trade the exhaustion of endless scripting for the ease of an automated XML to SQL Server conversion that handles the heavy lifting for you.
Ready to ditch the debugging and reclaim your time? Let’s dive in.
Here’s the TL;DR breakdown before we dive deeper:
- First, we’ll go over the XML parsing fundamentals,
- Then, I’ll go over the several options for loading XML to SQL Server,
- Next are my dedicated sections on Querying and Shredding XML data in SQL Server,
- In the final section, I’ll give you my ultimate tool for Automated XML Parsing on SQL Server.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Quick Answers / Cheat Sheet:
If you’re looking for a quick win, here’s a Cheat Sheet with Quick Answers to your problems.
Problem 1: What is the Fastest way to handle XML in SQL Server (manual approach)
Answer: Store XML in an XML data type and use XQuery (nodes(), value(), query()).
Problem 2: How to extract a single XML value with manual code?
Answer: Use the .value() method on your XML column. Example based on the SalesOrder XML shown in the XQuery section.
|
1 |
SELECT XmlCol.value('(/SalesOrder/Customers/@CustomerName)[1]', 'nvarchar(100)'); |
Problem 3: How to Shred XML into relational rows manually?
Answer: Use .nodes() with CROSS APPLY.
Here’s an example based on the University / Faculty / Department XML used in the shredding section:
|
1 2 3 4 5 |
SELECT dp.value('@id','nvarchar(max)') AS DepartmentId, cr.value('.','nvarchar(max)') AS CourseName FROM XmlCol.nodes('/University/Faculty/Department') AS d(dp) CROSS APPLY dp.nodes('Course') AS c(cr); |
Problem 4: I want to write my own manual code to load XML to SQL Server. What are my options?
Answer: If you’re OK with all the pain points of manual approaches, then your options are:
- BCP or BULK INSERT for bulk/large XML,
- INSERT INTO… for small / dev XML,
- OPENROWSET for basic file reads.
Problem 5: Wait, is OPENXML a legacy approach?
Answer: Yes, OPENXML is a legacy approach. It is still supported but outdated, memory-heavy, and based on COM. You should use it only for old systems.
Problem 5: Can I use XML indexing for manual performance tuning?
Answer: Yes, if your XQuery is slow, manually create:
- A Primary XML index,
- An optional PATH, VALUE, or PROPERTY secondary index.
You can read more about this in my respective sub-section.
Problem 6: How to choose Schema on Read or Schema on Write?
Answer: Here’s a simple explanation:
- Schema on Read: Query directly from XML column using XQuery,
- Schema on Write: Shred XML into relational tables.
Problem 7: I’ve tried my luck with manual approaches and am looking for a solution that will give my team and me peace of mind. Where to look?
Answer: If you’re tired of searching for workarounds and bug fixes for manual approaches, then look no further.
Just go straight to my section on “Automating XML Parsing on SQL Server”, where I’ll show you how to use Flexter for automated parsing of XML on SQL Server.
Pro tip: If you don’t want to deep-dive into my individual sub-sections, you may as well check out my FAQ section on this topic.
XML parsing process on SQL Server
XML parsing refers to the process of interpreting and converting XML data using the features offered by SQL Server.
It involves one or more of the following steps:
- Loading and Storing XML Data: SQL Server allows storing XML data in its databases. You can store XML data in columns specifically designated as the XML data type. This will enable you to store structured data in a way that’s both human-readable and machine-processable. SQL Server includes a special XML data type for loading XML documents.
- Querying and reading XML Data: SQL Server provides useful tools for reading and querying XML data without the need to store it in a relational format. This approach is known as Schema on Read. For performance optimisation, SQL Server allows indexing XML data through a special type of XML index. This is particularly useful when dealing with large volumes of XML data, as it can significantly speed up query performance.
- Shredding XML Data: SQL Server provides the ability to ‘shred’ XML data; that is, to convert it into relational data. You can extract elements from the XML and represent them as relational rows and columns. This approach of parsing XML is known as Schema on Write and requires an ETL or data transformation process and pipeline. We have written extensively about the limitations of the schema on read approach for hierarchical data.
Constructing XML Data: SQL Server can also generate XML data from relational data.
This is done using functions like FOR XML or XQuery, which can output query results in an XML format.
Generating XML from a relational format is not covered in this article.
Loading XML to SQL Server
Loading XML documents into SQL Server is a prerequisite for organisations that need to query and shred this data using the SQL Server XML tools. By importing XML into SQL Server, businesses can leverage SQL Server’s powerful querying capabilities to extract valuable insights from XML data, transform it as needed, and integrate it seamlessly with other data types.
In this section, we discuss the diverse and often confusing options available to bulk import XML files into SQL Server. We begin by providing an overview of the XML data type in SQL Server, which is the preferred and optimised method for importing and storing XML data for downstream querying and XML conversion.
While you can map XML files to a relational format during the load phase to SQL Server, we recommend storing the XML document inside an XML data type before shredding the XML to relational tables. This way, you preserve the original structure.
You also have the option to query the original XML document, e.g. for debugging purposes.
What is the XML data type in SQL Server?
The XML data type, introduced in SQL Server 2005, represents a fully integrated and premier data type, specifically designed for the manipulation, storage, and querying of XML data.
SQL Server doesn’t store the precise, character-by-character string of the XML data in an XML data type. Rather, it transforms the given literal XML into an internal format akin to XDM (XML Data Model). This format is more abstract and logical, focusing on a hierarchical structure that captures the essential details about XML nodes. However, during this conversion process, some of the metadata associated with the original XML data may be lost.
The XML data type offers numerous benefits compared to the older functions and procedures that were used for managing XML on the server side before the advent of SQL Server 2005.
It offers the following benefits:
- Standardised Data Storage: The XML data type provides a standardised way to store XML data in SQL Server databases. This ensures that the data is stored in a well-structured and easily accessible format.
- Schema Support: SQL Server’s XML data type supports XML schema collections. This means you can define a schema for your XML data and ensure that the data stored in an XML column adheres to this schema, promoting data integrity and consistency.
- Integration with Other Data Types: The XML data type allows for seamless integration with other data types in SQL Server. This makes it easier to combine XML data with traditional relational data, facilitating complex data modelling and analysis.
- Performance Optimisation: The XML data type in SQL Server is optimised for performance. It includes features like XML indexing, which can significantly improve query performance on large XML data sets.
When importing XML data into an SQL Server table, ensure that the data type is set to XML.
Creating a table with XML data type (column University_Data) for loading XML documents to SQL Server.
|
1 2 3 4 |
CREATE TABLE [dbo].[University_Details]( [Id] [int] NULL, [University_Data] [xml] NULL ) |
Option 1: OPENROWSET XML Loading
OPENROWSET is a function in SQL Server that allows you to access data from a remote data source that is not defined as a linked server.
This function can also be used to read data from a file, such as an XML file, directly into SQL Server. When using OPENROWSET for loading XML data, you typically specify the BULK option, which is used for reading the content of a file.
When you use OPENROWSET, it treats the file’s contents as a set of rows, similar to how data is structured in a table. Depending on the type of data you are importing, you can specify options like SINGLE_BLOB, SINGLE_CLOB, or SINGLE_NCLOB.
These options determine how the file’s contents are returned: as a Binary Large Object (BLOB), Character Large Object (CLOB), or National Character Large Object (NCLOB), all in a single column.
|
1 2 3 4 |
DECLARE @x xml; SELECT @x = xCol.BulkColumn FROM OPENROWSET (BULK 'c:\sample.xml', SINGLE_BLOB) AS xCol; SELECT @x; |
When to use OPENROWSET to load XML data
If you are dealing with large volumes of XML files, OPENROWSET is not the most efficient in terms of performance. Tools like BCP or BULK INSERT are optimised for handling large volumes of data more efficiently.
Option 2: BCP for Loading XML to SQL Server
The Bulk Copy Program, or BCP for short, is SQL Server’s command-line tool for bulk loading files into SQL Server tables. BCP can also be used for importing XML files.
Using BCP, you can directly load an XML file to a table with an XML data type.
You can use an XML format file together with BCP to specify the format, data types, and XML document to database column mappings. BCP can auto-generate an XML format file, or you can also create it manually.
Example of an XML format file for loading XML with BCP:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<?xml version="1.0"?> <BCPFORMAT xmlns="http://schemas.microsoft.com/sqlserver/2004/bulkload/format" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <RECORD> <FIELD ID="1" xsi:type="CharTerm" TERMINATOR="," MAX_LENGTH="7"/> <FIELD ID="2" xsi:type="CharTerm" TERMINATOR="," MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS"/> <FIELD ID="3" xsi:type="CharTerm" TERMINATOR="," MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS"/> <FIELD ID="4" xsi:type="CharTerm" TERMINATOR="\r\n" MAX_LENGTH="24"/> </RECORD> <ROW> <COLUMN SOURCE="1" NAME="DepartmentID" xsi:type="SQLSMALLINT"/> <COLUMN SOURCE="2" NAME="Name" xsi:type="SQLNVARCHAR"/> <COLUMN SOURCE="3" NAME="GroupName" xsi:type="SQLNVARCHAR"/> <COLUMN SOURCE="4" NAME="ModifiedDate" xsi:type="SQLDATETIME"/> </ROW> </BCPFORMAT> |
Command using BCP for loading an XML file (GEO.xml) with an XML format file (GEO.fmt).
|
1 2 |
bcp AdventureWorks.Sales.CustomerGeography in c:\GEO.xml -f c:\GEO.fmt -T |
XML format files also work with the T-SQL BULK INSERT statement, which we cover in one of the next sections.
When should you use BCP for importing XML?
- Large XML Files: If you’re dealing with very large XML files, BCP is often the best choice. It’s specifically optimised to handle large volumes of XML data efficiently, so you can load bulk data faster.
- Automated and Scheduled Data Loads: BCP, being a command-line tool, is ideal for integrating into automated scripts or scheduled tasks. If your data loading process needs to be automated or regularly scheduled, BCP’s ease of integration with batch files or shell scripts makes it a great option.
When should you not use BCP for importing XML?
Transactional Control Needed: If you require transactional control over the data loading process (e.g., rollback capabilities), BULK INSERT or OPENROWSET within a transactional SQL script are more suitable for loading XML.
BCP does not check for the validity of an XML file. You would need to preprocess your XML to check that it is well-formed, or have failure handling processes in place.
BCP is not effective at handling granular errors.
Option 3: SQLXML Bulk Load
SQLXML added functionality in support of SQL Server’s original implementation of XML support circa SQL Server 2000. SQLXML allows developers to perform a variety of tasks, including converting relational data to XML format on the client, querying and updating relational data using XPath and XML, and bulk loading XML data into relational tables.
Although SQLXML was originally designed to work in unmanaged code through OLEDB (Object Linking and Embedding Database), the .NET Framework provides managed wrapper classes for SQLXML.
Before SQL Server 2008 (10.0.x), SQLXML 4.0 was released with SQL Server and was part of the default installation of all SQL Server versions except for SQL Server Express.
Starting with SQL Server 2008 (10.0.x), the latest version of SQLXML (SQLXML 4.0 SP1) is no longer included in SQL Server.
A useful feature of SQLXML is the Bulk Load feature. This feature is implemented by a stand-alone COM object, which is implemented separately from the other SQLXML functionality.
Accessing this functionality from .NET requires you to add a reference to the Microsoft SQLXML BulkLoad 4.0 Type Library COM object.
The SQLXML Bulk Load feature is a handy utility for loading XML data into your relational database fairly quickly. Because it’s COM-based, however, you may find it to be less efficient than a native .NET solution.
Option 4: Bulk Insert XML to SQL Server
Bulk Insert is a T-SQL command that can be used within SQL Server Management Studio (SSMS) or in SQL scripts. It’s executed as a SQL command and is often integrated into SQL scripts or procedures.
BULK INSERT loads data from an XML document into a table. This functionality is similar to that provided by the in option of the bcp command.
Like BCP, BULK INSERT is widely used for importing large volumes of data quickly into SQL Server databases, but they have distinct features and are suited to different scenarios.
When to use Bulk Insert over BCP:
- Transactional Control: BULK INSERT can be incorporated into transactions in T-SQL. This is useful if you need the ability to roll back the import in case of errors.
- Error Handling: BULK INSERT allows for more sophisticated error handling within T-SQL. You can capture errors and handle them in your scripts, offering better control over the import process.
- Simplicity in SQL Scripts: For users who are more comfortable with SQL than command-line tools, BULK INSERT offers a simpler and more straightforward approach within a familiar environment.
Option 5: INSERT INTO statement
Using the INSERT INTO statement to load XML data into SQL Server is useful in specific scenarios, particularly when you have small amounts of XML data.
It is perfect for loading individual XML files for development and testing purposes.
Example
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE XmlDataTable ( XmlColumn XML ); DECLARE @xmlData XML; SET @xmlData = '<root><element>Example Data</element></root>'; INSERT INTO XmlDataTable (XmlColumn) VALUES (@xmlData); |
Querying XML data in SQL Server
After loading XML data into a table that contains a column of the XML data type, you can begin querying and analysing this data.
SQL Server provides extensions like XQuery, which allow for the on-the-fly transformation of XML data into a relational format, eliminating the need to store the data separately in relational tables.
This method is commonly known as ‘schema on read’, where the schema is dynamically defined at the time of reading the XML data.
Option 1: XQuery
XQuery is a language designed for querying XML. It extends XPath, offering enhanced capabilities for iteration, sorting, and even constructing XML.
The XQuery standard is developed by the W3C (World Wide Web Consortium), with contributions from Microsoft and other leading RDBMS vendors.
SQL Server ships with XQuery since version 2005. It is an extension to T-SQL for XML parsing and can be used inside T-SQL.
In T-SQL, XQuery interacts with the XML data type through five methods. XQuery also supports XSD schemas for working with complex documents and employs FLWOR (pronounced “flower”) statements. FLWOR stands for ‘for’, ‘let’, ‘where’, ‘order by’, and ‘return’, which are constructs for iterating through nodes, variable binding, filtering with Boolean expressions, ordering nodes, and specifying return values.
Overview of the XQuery functions in SQL Server:
exist(): Checks if an XML document contains a node with a specified value, returning one if it exists and zero if not.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
DECLARE @SalesOrders XML SET @SalesOrders = '<SalesOrder OrderDate="2016-05-27" OrderID="73356"> <Customers CustomerName="Agrita Abele"> <Product StockItemName="Chocolate sharks 250g"> <LineItem Quantity="192" UnitPrice="8.55" /> </Product> </Customers> </SalesOrder>' ; SELECT @SalesOrders.exist('SalesOrder/Customers/Product[ (@StockItemName) eq "Chocolate sharks 250g"]') ; |
The SELECT query returns the value 1 (true).
modify(): Allows data modification in an XML document, supporting insert, delete, and replace value operations.
nodes(): Produces a row set from XML instances, useful for shredding XML into relational formats. We will cover this in the next section on XML shredding.
query(): Retrieves a subset of an XML document in XML format.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
DECLARE @SalesOrders XML ; SET @SalesOrders = '<SalesOrder OrderDate="2016-05-27" OrderID="73356"> <Customers CustomerName="Agrita Abele"> <Product StockItemName="Chocolate sharks 250g"> <LineItem Quantity="192" UnitPrice="8.55" /> </Product> </Customers> </SalesOrder>' ; SELECT @SalesOrders.query('/SalesOrder/Customers/Product') AS ProductDetails ; |
The SELECT query returns <Product StockItemName=”Chocolate sharks 250g”> <LineItem Quantity=”192″ UnitPrice=”8.55″ /> </Product>
value(): Using this SQL Server XML extraction technique gets a single scalar value from an XML document, converting it to an SQL Server data type.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
DECLARE @SalesOrders XML ; SET @SalesOrders = '<SalesOrder OrderDate="2016-05-27" OrderID="73356"> <Customers CustomerName="Agrita Abele"> <Product StockItemName="Chocolate sharks 250g"> <LineItem Quantity="192" UnitPrice="8.55" /> </Product> </Customers> </SalesOrder>' ; SELECT @SalesOrders.value('(/SalesOrder/Customers/ @CustomerName)[1]', 'nvarchar(100)') AS CustomerName ; |
The query returns the value Agrita Abele.
The examples have been taken from the highly recommended book SQL Server Advanced Data Types. JSON, XML and beyond.
Using XQuery is the recommended approach for querying XML data stored inside an SQL Server XML data type.
Using XPath queries in SQLXML can be a useful tool for remote querying of relational data, although SQL Server’s xml data type and XQuery functionality provide a much more powerful alternative to this particular SQLXML functionality.
Option 2: XML Index
XQuery can be used to query XML stored in an XML data type. The queries can be rather inefficient, however, unless you create XML indexes.
SQL Server offers support for primary XML indexes and three types of secondary XML indexes: PATH, VALUE, and PROPERTY.
XML indexes will outperform full-text indexes for most queries against XML columns.
A clustered index must exist on the table before you can create an XML index.
A primary XML index is a multicolumn clustered index on an internal system table called the Node table.
This table stores a shredded representation of the XML objects within an XML column, along with the clustered index key of the base table.
Secondary XML indexes can be established only on XML columns that already have a primary XML index.
Internally, these secondary indexes are essentially nonclustered indexes created on the Node table used by SQL Server to store XML data. They are particularly useful in enhancing the performance of queries that rely on specific XQuery processing techniques.
Three types of secondary XML indexes exist:
- PATH Index: This index is constructed on the Node ID and VALUE columns of the Node table. It is beneficial for queries involving path expressions, like those using the exists() XQuery method. A PATH index speeds up queries that navigate specific paths within the XML structure.
- VALUE Index: This index is structured in the opposite manner, focusing on the VALUE and Node ID columns. It’s advantageous for queries that search for specific values without specifying the XML element or attribute names. This index type is particularly useful for queries that need to find a value regardless of where it appears in the XML document.
- PROPERTY Index: Built on the clustered index key of the base table, the Node ID, and the VALUE columns, a PROPERTY index is effective when queries require the retrieval of nodes across multiple tuples of the column. It’s optimal for queries that need to access various parts of the XML data in relation to the overall database structure.

OPENXML vs. XQuery for Shredding XML in SQL Server
XML shredding shreds XML documents into components that can be stored in a relational format on SQL Server. Unlike XML querying, XML shredding uses a schema on write approach.
The schema on write paradigm requires a defined schema for the stored data, thereby ensuring consistency, efficient querying, and data integrity.
SQL Server supports XML shredding using OPENXML and XQuery. Let’s look at the advantages and disadvantages of each.
Option 1: OPENXML for Parsing XML in SQL Server
OPENXML was the original method for shredding XML in SQL Server, introduced back in SQL Server 2000.
It allows you to query XML documents in a table-like manner and project them into a relational structure.
However, as you’ll see in a moment, it is significantly more complex, resource-intensive, and less flexible than the XQuery-based nodes() method that SQL Server currently offers.
To keep things consistent across this guide, let’s apply OPENXML to the same University → Faculty → Department → Course XML used later in the XQuery example.
You can also use the Online SQL Server Compiler by SQL Fiddle to reproduce the example.
Here is our sample XML:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<University id="TUD"> <Faculty id="Engineering"> <Department id="ComputerScience"> <Course>Introduction to Programming</Course> <Course>Algorithms and Data Structures</Course> </Department> <Department id="ElectricalEngineering"> <Course>Circuit Analysis</Course> <Course>Electromagnetics</Course> <Course>Control Systems</Course> </Department> </Faculty> </University> |
Shredding XML with OPENXML
Before you can query the XML, SQL Server requires that you parse it using:
- sp_xml_preparedocument: loads the XML into an internal DOM representation,
- OPENXML: exposes XML nodes as a rowset,
- sp_xml_removedocument: frees memory afterwards.
Here’s the full example using our university XML:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
DECLARE @xmlDoc NVARCHAR(MAX) = N' <University id="TUD"> <Faculty id="Engineering"> <Department id="ComputerScience"> <Course>Introduction to Programming</Course> <Course>Algorithms and Data Structures</Course> </Department> <Department id="ElectricalEngineering"> <Course>Circuit Analysis</Course> <Course>Electromagnetics</Course> <Course>Control Systems</Course> </Department> </Faculty> </University>'; DECLARE @hDoc INT; EXEC sp_xml_preparedocument @hDoc OUTPUT, @xmlDoc; SELECT UniversityId = U.value, FacultyId = F.value, DepartmentId = D.value, CourseName = C.value FROM OPENXML(@hDoc, '/University', 2) WITH (value NVARCHAR(200) '@id') AS U CROSS APPLY OPENXML(@hDoc, '/University/Faculty', 2) WITH (value NVARCHAR(200) '@id') AS F CROSS APPLY OPENXML(@hDoc, '/University/Faculty/Department', 2) WITH (value NVARCHAR(200) '@id') AS D CROSS APPLY OPENXML(@hDoc, '/University/Faculty/Department/Course', 2) WITH (value NVARCHAR(MAX) '.') AS C; EXEC sp_xml_removedocument @hDoc; |
When you run it on SQL Fiddle, it’ll output:
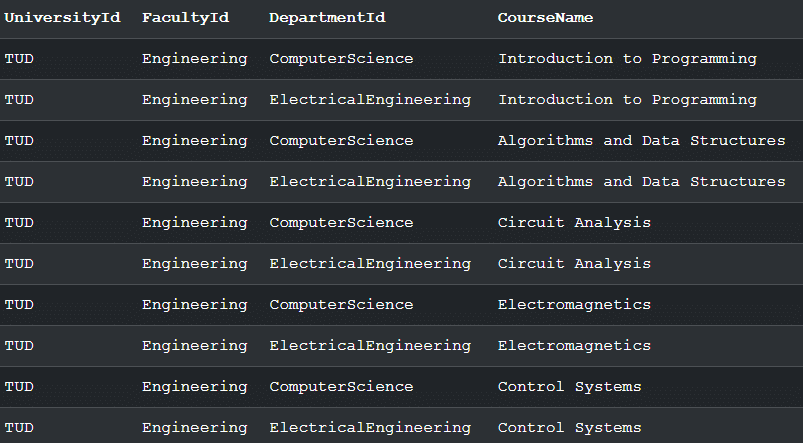
This result contains one row for every <Course> element in the XML. Since each course belongs to a specific department under the Engineering faculty, SQL Server repeats the higher-level values (UniversityId, FacultyId, DepartmentId) for each course.
This is expected: shredding hierarchical XML into a relational structure naturally produces repeated parent values because SQL Server flattens the tree into a two-dimensional table.
This repetitive structure is one of the reasons why XML flattening must be designed carefully, especially when dealing with multiple nested branches.
Why OPENXML is a Legacy Method
Although it still works, there are several reasons why OPENXML has fallen out of favour compared to SQL Server’s modern XML methods (as I’ll show you in the next section):
- OPENXML is based on the old COM model: OPENXML relies on Microsoft XML Core Services (MSXML) under the hood. Because it uses the COM-based DOM parser, it must load and maintain the entire XML document in memory.
- It consumes a significant portion of SQL Server’s memory: When you call sp_xml_preparedocument, SQL Server allocates up to 1/8th of the server’s total memory for XML processing, even if your XML document is tiny.
- The method is verbose and brittle: Each call requires explicit XPath expressions, manual mapping of elements and attributes, repeating paths for every rowset, and manually reconstructing parent-child relationships, followed by explicit cleanup of the document handle. As the XML structure grows, this quickly becomes difficult to maintain.
- The modern XQuery nodes() method is more efficient and more flexible: It isn’t based on COM, uses SQL Server’s native XML data type, avoids allocating large memory blocks, and streams only the XML fragments it needs instead of loading the full DOM.
Option 2: Shredding XML with XQuery
To shred data directly from a column, the XQUERY nodes() function is particularly useful for this purpose. It helps in pinpointing the specific nodes in the XML that map to relational columns.
You can pair this with the value() method, which is effective in extracting the actual data from these identified nodes. This combination allows for an efficient transformation of XML data into a relational format.
The primary advantage of using the nodes() method compared to OPENXML() lies in its simplicity when applied to a table.
You can use the SQL CROSS APPLY operator to efficiently implement the nodes() method across multiple rows within a table.
This makes it easy to flatten and denormalise a branch inside an XML.
An example
(To reproduce this example, you’ll need an SQL Server instance.)
Create a table in SQL Server with an XML data type.
|
1 2 3 4 |
CREATE TABLE [dbo].[University_Details]( [Id] [int] NULL, [University_Data] [xml] NULL ) |
A multi-branched XML is loaded into the table using INSERT INTO…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
INSERT INTO [dbo].[University_Details] (Id, University_Data) VALUES (1, '<University id="TUD"> <Faculty id="Engineering"> <Department id="ComputerScience"> <Course>Introduction to Programming</Course> <Course>Algorithms and Data Structures</Course> </Department> <Department id="ElectricalEngineering"> <Course>Circuit Analysis</Course> <Course>Electromagnetics</Course> <Course>Control Systems</Course> </Department> <ResearchGroup id="ArtificialIntelligence"> <Project>Machine Learning Advances</Project> <Project>Neural Network Optimization</Project> <Project>AI Ethics and Society</Project> </ResearchGroup> <ResearchGroup id="Nanotechnology"> <Project>Nano-materials Engineering</Project> <Project>Quantum Computing</Project> </ResearchGroup> </Faculty> <AdministrativeUnit id="Library"> <Service>Book Lending</Service> <Service>Research Assistance</Service> </AdministrativeUnit> <AdministrativeUnit id="IT"> <Service>Campus Network</Service> <Service>Helpdesk</Service> </AdministrativeUnit> </University>') |
To validate that the XML was inserted:
|
1 |
SELECT * FROM University_Details where id = 1 |

We flatten the Department branch: The query and result set below show the data flattened by department and project.
|
1 2 3 4 5 6 7 8 9 10 11 |
DECLARE @XMLToParse XML = (select University_Data from University_Details where id = 1) SELECT UniversityName = uni.value('@id', 'nvarchar(max)'), FacultyId = fac.value('@id', 'nvarchar(max)'), DepartmentId = dp.value('@id', 'nvarchar(max)'), CourseName = cr.value('.', 'nvarchar(max)') FROM @XMLToParse.nodes('/University') AS t1(uni) OUTER APPLY uni.nodes('Faculty') AS t2(fac) OUTER APPLY fac.nodes('Department') AS t3(dp) OUTER APPLY dp.nodes('Course') AS t4(cr); |
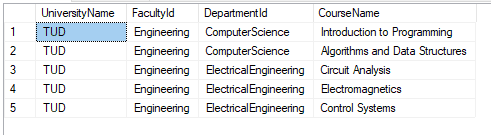
The query below and the result set flatten ResearchGroup and Project:
|
1 2 3 4 5 6 7 8 9 10 11 |
DECLARE @XMLToParse XML = (select University_Data from University_Details where id = 1) SELECT UniversityId = uni.value('@id', 'nvarchar(max)'), FacultyId = fac.value('@id', 'nvarchar(max)'), ResearchGroupId = rg.value('@id', 'nvarchar(max)'), Project = proj.value('.', 'nvarchar(max)') FROM @XMLToParse.nodes('/University') AS t1(uni) OUTER APPLY uni.nodes('Faculty') AS t2(fac) OUTER APPLY fac.nodes('ResearchGroup') AS t3(rg) OUTER APPLY rg.nodes('Project') AS t4(proj); |
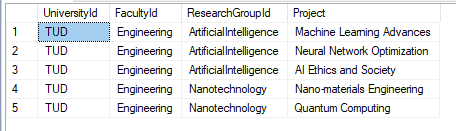
The query below and result set flatten out AdministrativeUnit and Service:
|
1 2 3 4 5 6 7 8 9 |
DECLARE @XMLToParse XML = (select University_Data from University_Details where id = 1) SELECT UniversityId = uni.value('@id', 'nvarchar(max)'), AdministrativeUnit = adm.value('@id', 'nvarchar(max)'), Service = ser.value('.', 'nvarchar(max)') FROM @XMLToParse.nodes('/University') AS t1(uni) OUTER APPLY uni.nodes('AdministrativeUnit') AS t2(adm) OUTER APPLY adm.nodes('Service') AS t3(ser); |
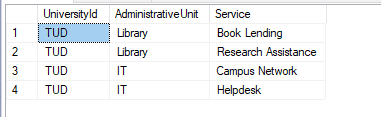
A note of caution on flattening and denormalising XML data into a relational format.
In relational databases, we aim to normalise data. Normalisation is a systematic approach to organising data to reduce redundancy and improve data integrity.
The primary goal of normalisation is to separate data into different tables in a way that each table represents one entity type, and then define relationships between these tables.
OPENXML vs. XQuery in SQL Server: which should you use?
If you compare Option 1 and Option 2 that I provided in this section, you’ll notice how the second approach is both simpler and more comprehensive.
In real-world production pipelines with highly nested XML, these differences become only more evident between the two options. Plus, XQuery performs better as your project scales.
For that reason, the nodes() method in XQuery is the preferred way to manually shred XML data in SQL Server.
However, it’s important to exercise caution when fully flattening XML structures, as this can lead to redundancies and potential errors in your data.
Additionally, be mindful when dealing with XML documents that have multiple branches.
Fully flattening such documents may not be feasible due to the complexity of their hierarchical structure.
Our enterprise XML converter Flexter ships with optimisation algorithms to find the perfect balance between a normalised and denormalised target model. Try Flexter to convert XML to a relational format.
For an extensive discussion of XQuery, refer to the excellent book Pro SQL Server 2008 XML.
Automating XML Parsing on SQL Server
The life cycle for manually converting XML to a relational database, such as SQL Server, covers a well-defined set of steps.
I’ve shared those steps in one of my previous posts.
In this section, I’ll show you exactly how you can automate and simplify those generic steps with Flexter.
If you’re looking for a side-by-side comparison of manual versus automated XML conversion, you may also check this downloadable resource.
The four magic steps to convert XML to SQL Server
Here’s the magic recipe to parse XML in SQL Server with minimal effort:
Step 1: Download and Install Flexter
To get started, you’ll need to download and install the Flexter binaries from the YUM/DNF repository.
Since this is an enterprise-grade solution, your first move is to contact Sonra directly for access to the repository.
Once you have access, installing the latest version is a straightforward process you can handle from the command line:
|
1 |
$ sudo yum --enablerepo=sonra-flexter install xml2er xsd2er json2er merge2er flexchma flexter-ui |
This command gives you all the basic Flexter Modules you’ll need for your XML to SQL project.
Step 2: Create an SQL Server database and configure the metadata catalogue
Next, as with any XML to SQL project, you’ll have to create your target database in SQL Server.
But to unlock Flexter’s true power, you need one crucial preparatory step: setting up a metadata database (MetaDB).
This MetaDB is a central location where Flexter stores all critical information about your conversions.
It’s a straightforward setup, and the payoff is massive: your Metadata Catalogue includes automatically generated resources, such as ER diagrams, Source-to-Target mappings, schema diffs, and DML/DDL scripts.
Do you still need to build the target schema manually when using an automated tool like Flexter?
The short answer is a resounding NO; not at all!
That’s one of the biggest advantages of using an automated XML to SQL platform like Flexter.
Instead of hand-crafting schemas, wrestling with complex hierarchies, or maintaining brittle mapping logic, Flexter handles the entire process for you.
In the next steps, you’ll see how Flexter eliminates the manual workload entirely: run a few simple commands, and Flexter automatically generates an optimised target schema along with all required mappings, ready for immediate use.
Step 3: Create data flow
This is where the magic happens, and you skip all the manual schema definition.
You have three powerful ways to tell Flexter how to build your relational target:
- Option 1: Use an XSD specification file alone.
- Option 2: Use an XML file (or a folder of files) as a sample.
- Option 3: The Gold Standard, a combination of both XSD and XML for maximum precision.
No matter which option you choose, Flexter automatically generates an optimised target database schema and the necessary conversion mappings, storing all this critical information in your metaDB.
This is a one-time setup. It won’t need any tweaks, except in the case that the source XML changes entirely.
For our test case, we run the following command to kick off the process:
|
1 |
xml2er -g1 test_case_file.xml |
Once executed, you immediately receive a Data Flow ID.
This ID is more than just a number; it’s the unique fingerprint of the automatically created target database schema and the mapping of XML elements to table attributes that Flexter will use for conversion.
Pro Tip: Did you catch the -g1 flag?
If you take away just one core feature of Flexter, make it this: the optimisation flag (like -g1).
Why is this a game-changer? This simple flag commands Flexter to deploy its advanced optimisation algorithms to craft an incredibly efficient target database schema. This optimised structure is immediately associated with the Data Flow ID from the xml2er command.
These algorithms are the behind-the-scenes horsepower for long-term, large-scale projects, eliminating artificial hierarchies and minimising redundancy.
Ready to see the true impact of this feature? Then you find more about it in my other posts:
Step 4: Convert XML to SQL Server
With your Data Flow ID ready, converting the XML is ridiculously simple—just one command is all it takes:
|
1 |
xml2er -x<Data Flow ID> -o jdbc:sqlserver://yourServerAddress;databaseName=yourDatabase -u yourUsername -p yourPassword pathTo/multibranchxml2(2).xml |
And voilà! The XML data is instantly converted and written directly to your SQL database. To confirm everything landed perfectly, just run a few final SELECT queries to verify the result.
Here’s how the XML to SQL Server process looks as a diagram:
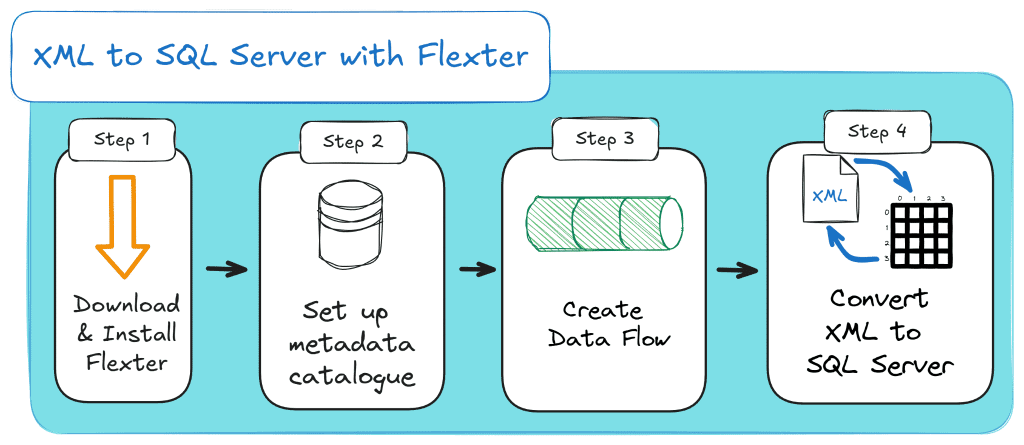
🎥 Video Tutorial: Automated Parsing and Converting XML to SQL
Are you a visual learner who still wants to see how Flexter can convert your source XML to a normalised SQL schema?
Here’s my video on how to convert any XML file into SQL tables with our Free Online Tool.
Pro tip
While this video tutorial focuses on XML to Snowflake conversion, rest assured that Flexter can convert your XML to SQL Server in exactly the same way.
Flexter can actually convert from XML to various other formats and systems, such as Oracle, MySQL, and PostgreSQL.
If you’re interested in the full list of Flexter’s output formats, I’d suggest you take a look at the full Flexter Capability Sheet.

Manual vs. Automated XML to SQL Server
The decision on manual versus automated conversion is a classic decision of buy versus build.
Here is a summary of the benefits of an automated approach:
- Complexity: An automated approach can handle any XML and XSD complexity quickly and instantly.
- Faster go-live: Automated XML parsing automates all of the steps in the XML conversion life cycle, e.g. analysis, schema generation, and mappings. Data ends up quickly in the hands of decision makers
- Reduces risk: Automation of XML parsing reduces the risk of project failure or budget overruns in complex conversion projects based on industry data standards.
- Consistency and accuracy: Automation ensures that XML parsing processes are carried out in a consistent and accurate manner, significantly reducing the risk of human error
- Performance: An XML automation tool can scale up and out to handle any SLA and XML data volume.
- Ease of Use: User-friendly interfaces in automated tools can make the process more accessible. This reduces dependency on niche XML skills, such as XPath, XQuery, and XSLT, which can be hard to find and can be a point of vulnerability for a project.
The advantages of using an automated conversion process have to be weighed against the additional licence costs for a tool such as Flexter.
For simple requirements or ad-hoc queries, an XML automation tool is not required. Here’s a simple decision table to help you decide:
|
Scenario |
Recommended Option |
Why? |
|---|---|---|
|
One-off or small XML during development/testing |
INSERT INTO with an XML variable |
Easiest option for small samples; fast to prototype, |
|
You need flexible querying without defining a schema upfront. Query-phase performance is not important for you. |
Store in XML data type and query with XQuery (nodes(), value(), query()). You may use BCP or BULK INSERT to insert XML into the column. |
This is a schema on read approach, where you can load the data to SQL Server with relative ease. Your target schema is not relational or optimised, though, so querying is more intensive. |
|
Complex, nested, or industry-standard XML at scale. |
Flexter (automated XML to SQL Server conversion) | Automatically generates an optimised relational schema and all mappings. Eliminates manual shredding, handles huge files, and is ideal for highly nested or XSD-based XML. |
Automated XML conversion software is a good fit if one or more of the following checks apply to you:
- Is your XML very complex? Does it use an XSD? Is it based on an industry data standard such as HL7 or FpML?
- Do you have conversion requirements for many different types of XML?
- Are your XML files huge?
- Are you parsing vast volumes of XML data with tight SLAs?
- Does your team lack in-house expertise in XML technologies, including XQuery, XSLT, and XPath?
- Do you have tight deadlines for your XML conversion project?
If you answered ‘Yes’ to one or more of these questions, why not give the free online version of our XML converter Flexter a try?
See for yourself what XML conversion software can do for you. Alternatively, talk directly to one of our XML conversion experts to discuss your use case in detail.
FAQ: Parsing XML in SQL Server
What is the best way to parse XML in SQL Server?
For most modern workloads, the best way to parse XML in SQL Server is to store your data in the XML data type and then use XQuery methods, particularly nodes() for shredding and value() for scalar extraction. This approach is simpler, performs better, and is far more flexible than older XML parsing techniques like OPENXML.
Is OPENXML still recommended in SQL Server?
No, OPENXML is considered a legacy method. It relies on a COM-based DOM parser, consumes a significant amount of memory, and is verbose and fragile as XML becomes more complex. SQL Server’s XQuery-based XML data type provides a more efficient and maintainable alternative for both querying and shredding XML.
How do I query an XML column in T-SQL?
You can query XML stored in an XML column using SQL Server’s built-in XQuery methods:
- nodes() to shred XML into relational rows,
- value() to extract scalar values,
- query() to return XML fragments,
- exist() to test for the presence of nodes.
For large XML datasets, SQL Server also supports primary and secondary XML indexes to improve performance.
What’s the difference between querying XML and shredding XML?
- Querying XML (Schema on Read): You read XML directly from the XML column using XQuery without converting it into relational tables.
- Shredding XML (Schema on Write): You flatten the XML into relational tables using nodes() or (formerly) OPENXML.
Shredding is useful for downstream SQL analytics, but flattening deeply-nested XML requires careful design to avoid data redundancy.
When should I use an automated XML conversion tool instead of custom SQL?
An automated XML conversion tool like Flexter is ideal when:
- Your XML is highly complex or XSD-based,
- You handle large XML files or very high data volumes,
- You have strict SLAs or limited in-house XML expertise,
- You need to support many different XML types,
- You want to avoid maintaining brittle manual mappings.
Automation reduces risk, speeds up delivery, and eliminates the need to hand-craft schemas or shred logic. Here’s a full list of advantages that automated software provides.
What’s the fastest way to bulk load XML files into SQL Server?
For large files, BCP or BULK INSERT are generally the fastest options:
- BCP is ideal for highly automated or scheduled bulk loads.
- BULK INSERT is better when you want transactional control or T-SQL-based error handling.
- OPENROWSET works, but is not optimal for large volumes.
Should I load XML into SQL Server as text or as XML data type?
You should load XML into the XML data type whenever possible. SQL Server transforms the XML into an internal structure, enabling indexing, XQuery, and shredding. It also preserves the hierarchical nature and avoids the limitations of storing raw text.
Can SQL Server automatically generate a relational schema from XML?
Not natively. SQL Server requires manual schema design for shredding XML into tables. However, Flexter can automatically generate an optimised target schema and all mappings, from XML (and optional XSD) to SQL Server, with a single command.
How does Flexter reduce the time and cost of XML to SQL Server projects?
Flexter eliminates the most time-consuming steps of any XML to SQL project, as I have described in detail in another blog post.
Instead of spending weeks analysing complex XML structures, Flexter automatically generates an optimised relational schema and all source-to-target mappings in seconds. These are just some of its features.
This dramatically shortens project timelines, reduces engineering costs, and removes the risk of human error that often leads to delays or budget overruns.
Can Flexter handle complex, real-world XML better than hand-written XQuery?
Yes. Flexter’s optimisation algorithms (including Elevate and Reuse) are specifically engineered to handle deeply nested, multi-branch XML and XSDs; something that quickly becomes brittle and unmanageable with hand-written SQL and XQuery.
Flexter produces a clean, normalised schema, avoids unnecessary redundancy, and scales effortlessly across massive XML volumes. This makes it ideal for enterprise XML such as HL7, FpML, FIXML, ACORD, and similar industry standards.
Further reading for XML to SQL Server Conversions
XML conversion
Deep dive on XML converters, XML conversion tools and XML conversion projects
Converting XML and JSON to a Data Lake
How to Insert XML Data into SQL Table?
The Ultimate Guide to XML Mapping in 2024
Optimisation algorithms for converting XML and JSON to a relational format
Re-use algorithms for converting XML and JSON to a relational format
Converting Financial Information eXchange XML (FIXML) to MS SQL Server
Should you Use Outsourced XML Conversion Services?
Flexter
Flexter FAQ & Guide – Automate XML & JSON Conversions
Free online version of Flexter
SQL Server and XML Parsing
Examples of bulk import and export of XML documents
Examples of Using XPath Queries
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: