Automating XML Conversion with Oracle's ETL Tool ODI

Get our e-books Discover the Oracle Data Integrator 11g Repository Data Model and Oracle Data Integrator Snippets and Recipes
In the previous posts we demonstrated how Flexter liberates data from complex XML files (Converting complex XML to CSV and Bulk loading XML files to Oracle with Flexter), we also presented the challenges when using ODI for the same purpose (Tips for Reverse Engineering complex XSDs such as SEPA and NDC in ODI and Tips for Parsing and Loading complex NDC XML files in ODI). We then did a side by side comparison where we showed how Flexter addresses various limitations in ODI for loading XML files.
In this post we will show how Flexter and ODI work hand in hand to load XML data into the staging area of a data warehouse. For this purpose we have written a Reverse Knowledge Module that creates an optimized relational schema from an XSD and generates the corresponding ODI model.
This seamless integration will allow developers to skip all the steps described in our previous posts
- Reverse engineer XSD into an ODI model
- Create Mappings to load XML
- Orchestrating a data flow for XML in ODI
and also
Flexter completely automates the processing of XML files. ODI developers can focus on activities that deliver real value to the business instead of performing boring and repetitive tasks.
Let’s go back to the SEPA pain.001 schema one last time.
Get our e-books Discover the Oracle Data Integrator 11g Repository Data Model and Oracle Data Integrator Snippets and Recipes
[flexter_banner]
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Analysing the schema
As outlined in our previous post Bulk loading XML files to Oracle with Flexter, Flexter can generate an optimized and simplified target schema for us. Once this is done we just need to reverse engineer it into an ODI model.
We have written a dedicated Flexter Reverse Knowledge Module (RKM) for this purpose.
Let’s create a new Model in ODI.
We go to properties and pick “RKM XML to Oracle (Flexter)” Knowledge Module from the Reverse Engineer tab.
This gives us two extra options to specify:
FLEXTER_XSD_PATH – this is the path to our XSD schema file(s)
FLEXTER_OPTIMIZATION_LEVEL – we can pick which optimizations should be applied by Flexter during target model generation. We will leave default value which will generate the most compact layout.
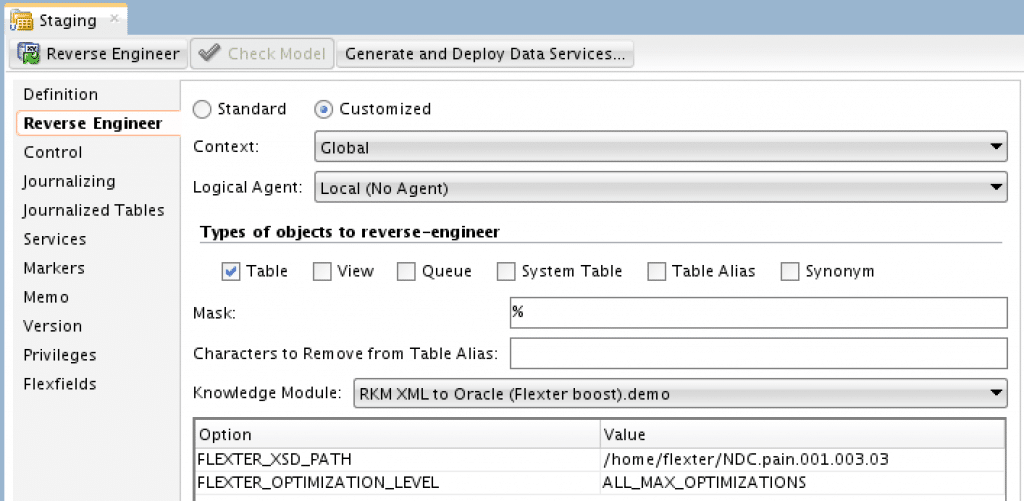
Next Save and click the ‘Reverse Engineer‘ button.
The dedicated RKM will call the Flexter RESTful API to do a few things:
- It first analyses the input schema and creates an optimized target schema (we have seen those steps in previous posts)
- Next it will create the target datastores in the ODI model:
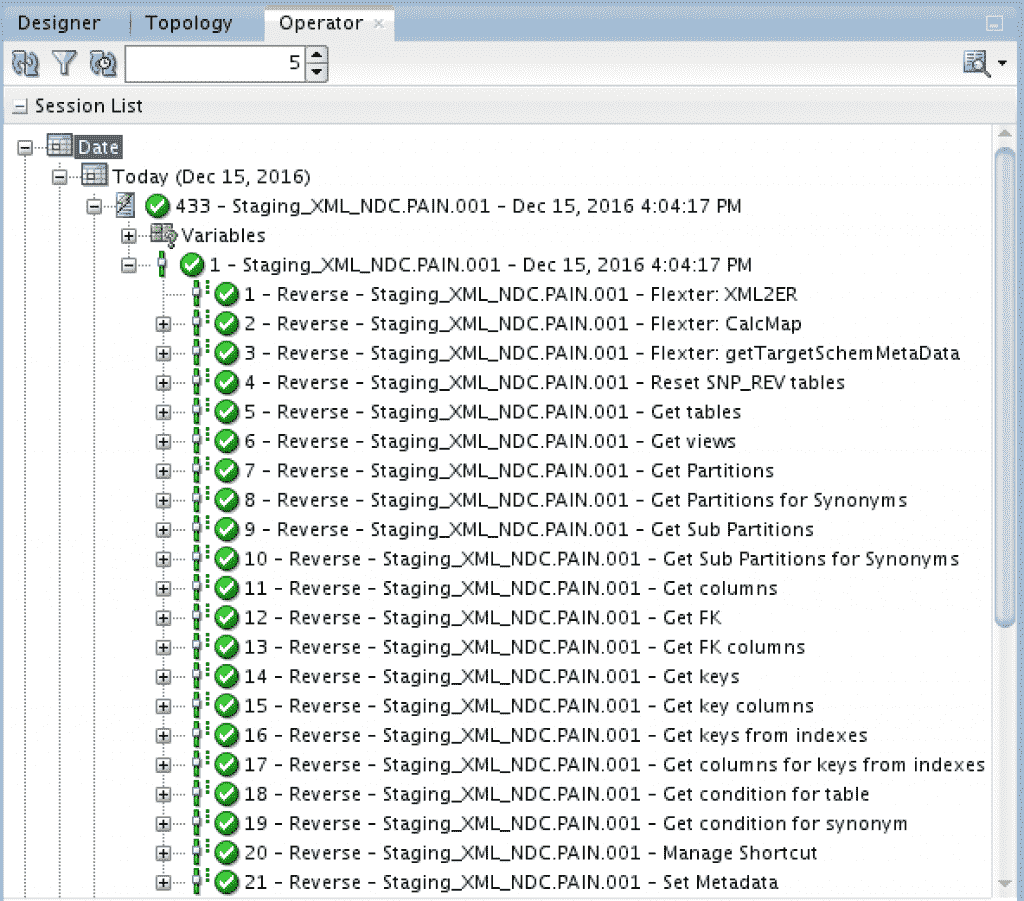
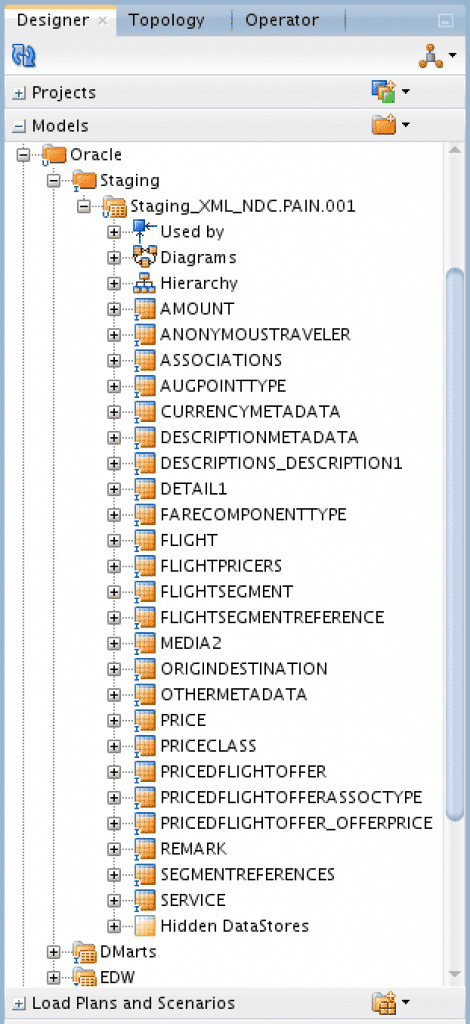
In addition, Flexter will produce the following documentation:
- A data lineage document that shows mappings from source to target:
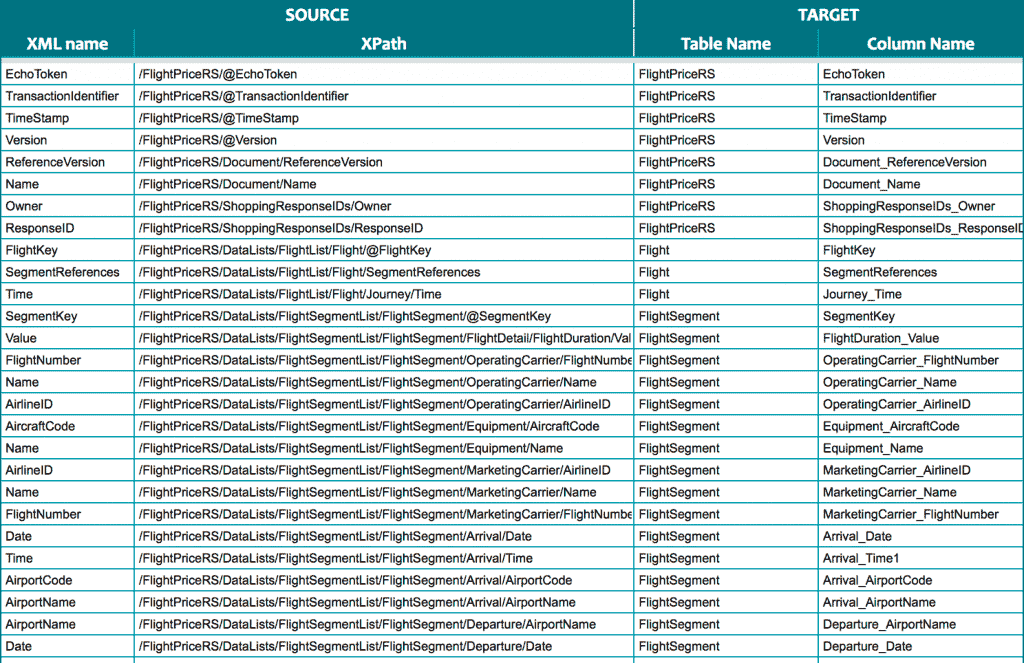
- A graph showing the layout/model of the target schema:
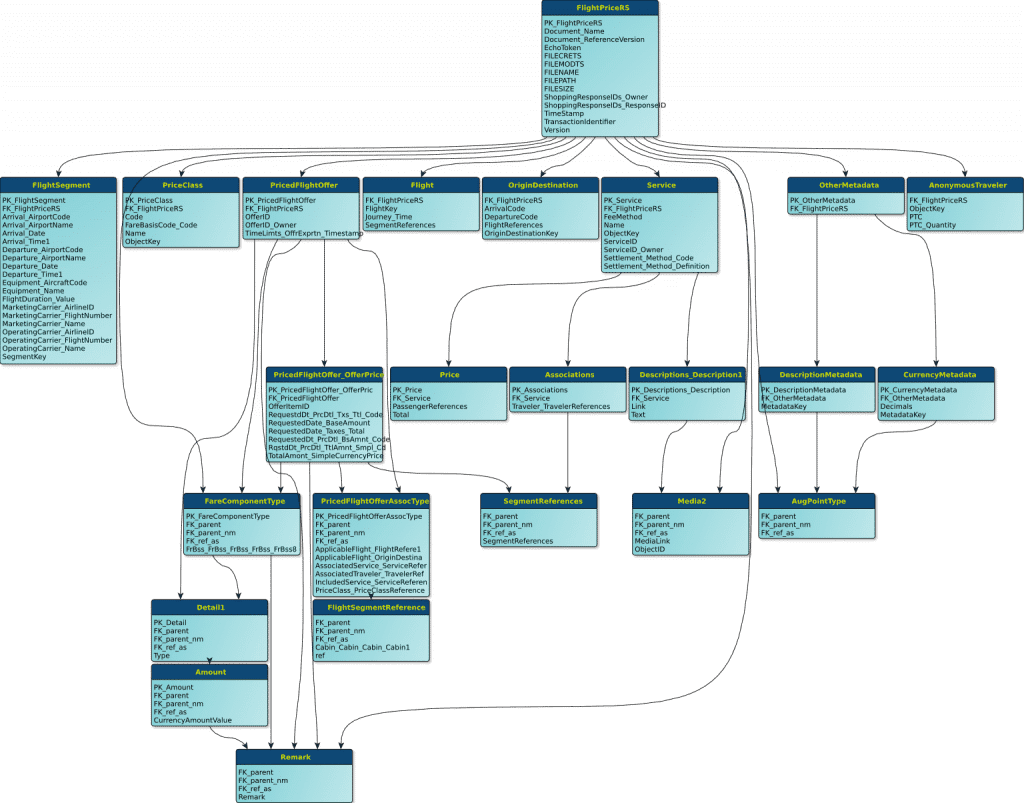
Populating the Target Schema
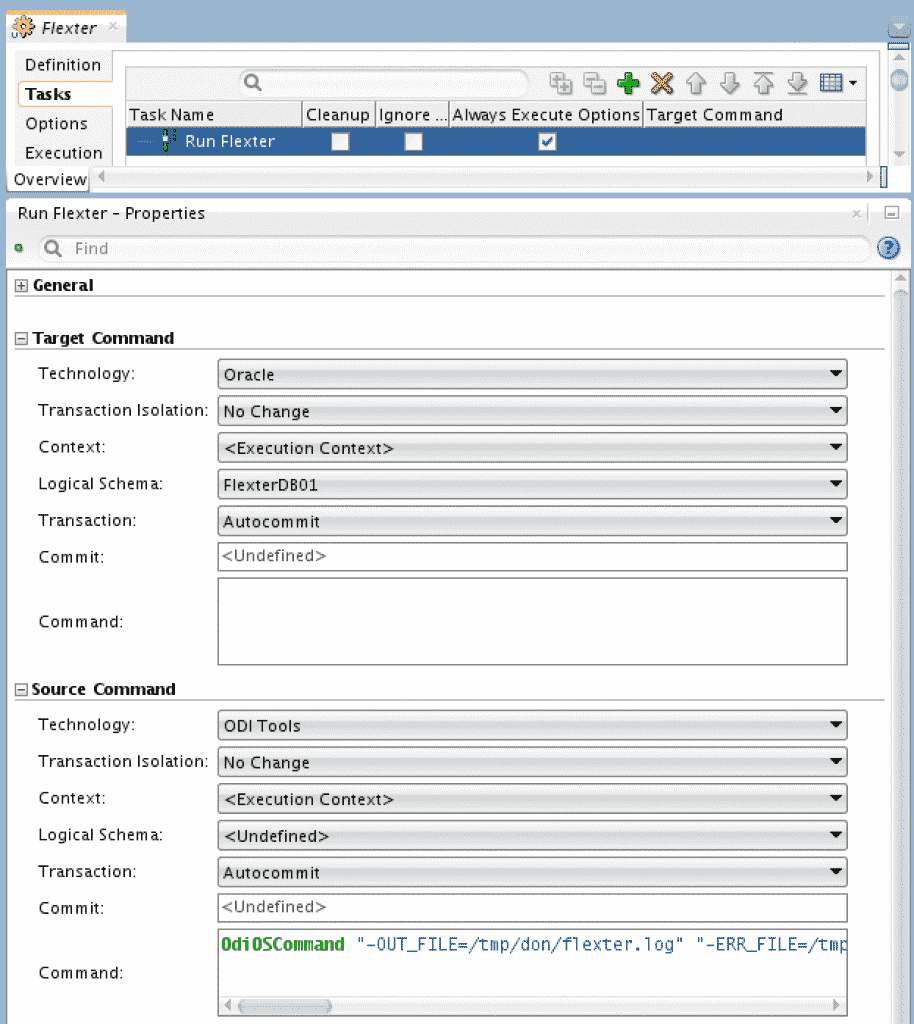
All that is left to do now is tell ODI to run Flexter. We have prepared an ODI Procedure to do this.
It just consists of a single task:
OdiOSCommand “-OUT_FILE=/tmp/don/flexter.log” “-ERR_FILE=/tmp/don/flexter.err” “-FILE_APPEND=yes” “-WORKING_DIR=/tmp/don” “-COMMAND=HADOOP_CONF_DIR= && xml2er -l <%=odiRef.getOption(“FLEXTER_XSD_SCHEMA_ID“)%> -f jdbc -S o -o <%=odiRef.getInfo(“DEST_JAVA_URL“)%> -u <%=odiRef.getInfo(“DEST_USER_NAME“)%> -p <%=odiRef.getInfo(“DEST_PASS“)%> <%=odiRef.getOption(“FLEXTER_XML_PATH“)%>”
The Procedure has two Options:
FLEXTER_XSD_SCHEMA_ID – This is the ID of the analysed XML schema
FLEXTER_XML_PATH – path to input XML file(s)
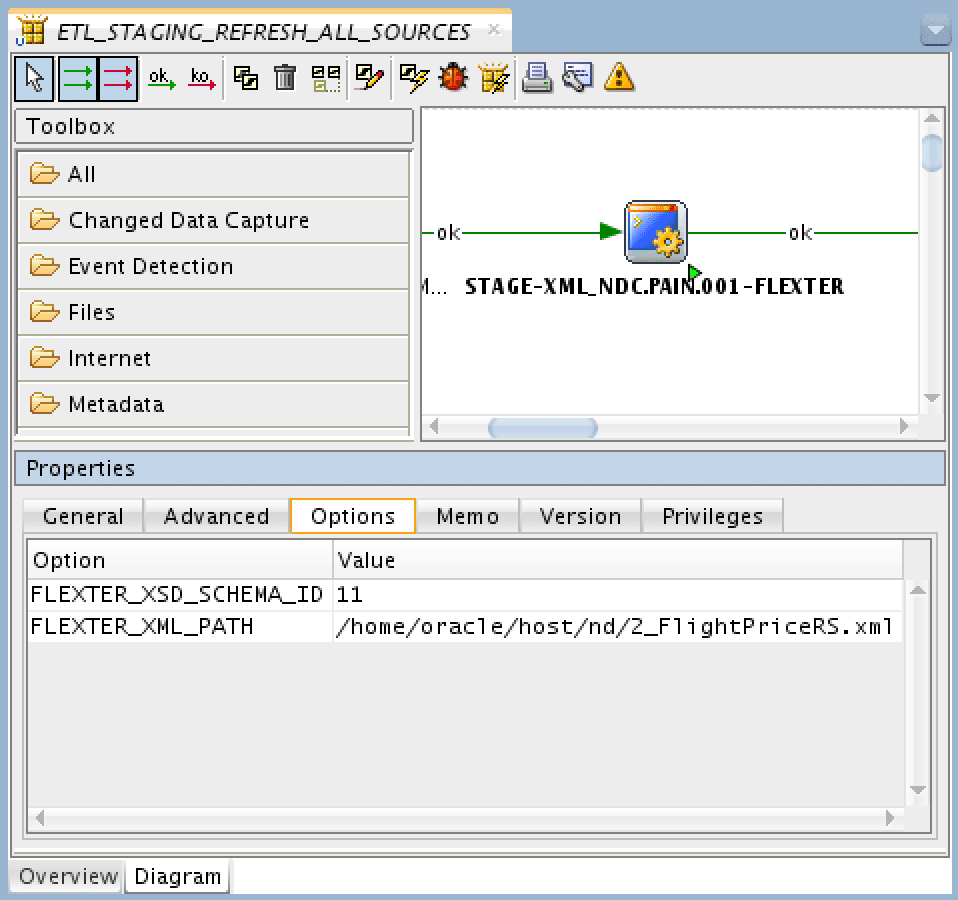
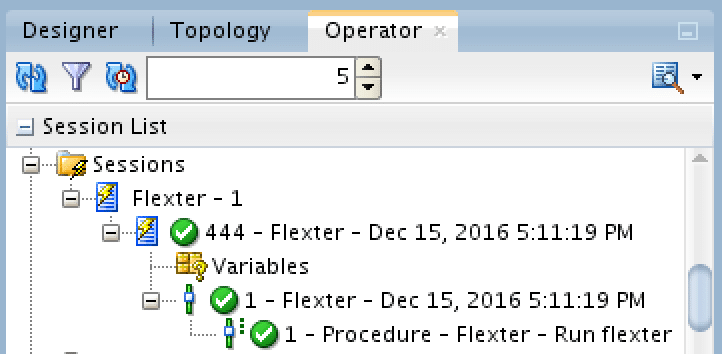
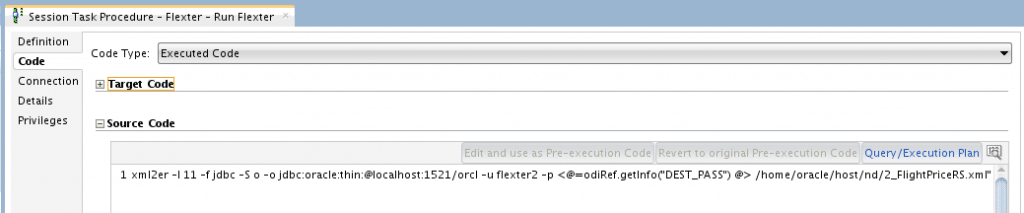
Once executed, ODI runs Flexter
Once finished (it just took 25 seconds to execute), the XML data is available in our target tables on the Oracle database.
That’s it. No variables, no file looping, just one simple (and very fast) procedure call.
[flexter_button]
Which data formats apart from XML also give you the heebie jeebies and need to be liberated? Please leave a comment below or reach out to us.
Uli Bethke
Uli has been rocking the data world since 2001. As the Co-founder of Sonra, the data liberation company, he’s on a mission to set data free. Uli doesn’t just talk the talk—he writes the books, leads the communities, and takes the stage as a conference speaker.
Any questions or comments for Uli? Connect with him on LinkedIn.
Follow Uli Bethke: 


