XML Converters & Conversion – Ultimate Guide (2026)

“Urgent XML Conversion Project – Need by End of Week”. “Just Convert this XML to SQL Tables. Should be Simple!” Sound familiar?
From my experience, XML conversion projects follow the classic Pareto principle: 80% of these projects are smooth sailing, with minimal effort and hassle. But it’s the other 20% that can really test your patience
- XML schemas are nested so deeply they resemble a set of Russian dolls, each layer hiding another, and another, and another. The data fields you need are buried somewhere at the tenth or twelfth level. You feel like an archaeologist, unearthing ruins 😀.
- The “generously” provided documentation for the XML based industry data standard runs hundreds of pages long. The jargon, the endless acronyms, the dry explanations. Every page adds more layers to the puzzle, more ways for things to go wrong. 😱
- “We need this for 100,000 XML files,” the client said and casually added. “Each minute”. After an endless development life cycle of manual Python coding you realise that parsing them takes hours, and your system creaks under the strain, threatening to crash with every step.
- XML files appear without any schema at all. You spent hours trying to reverse-engineer the structure across thousands of files. Every time you think you cracked it, a new set of tags appears. it is like playing a game of cards where the rules keep changing 🤪.
These are just some of the many issues when working with complex and deeply nested XML. I will cover these challenges in detail in this article and more importantly show you can solve your XML conversion headaches.
In this blog post I’m referring specifically to converting XML into tabular or relational formats, such as CSV, Excel, databases, SQL, or modern data formats like Parquet. These types of conversions are typically for data analysis use cases, where the goal is to make XML data more accessible for deeper insights.
For the purpose of this blog post, I won’t be covering other XML conversions, like transforming XML into HTML or PDF, which are more relevant to the publishing industry. Nor will I discuss scenarios where the conversion goes the other way—from databases or SQL tables into XML. My focus here is strictly on XML-to-table conversions that support data analysis needs.
I start with the basics you need to know about XML for a successful conversion project.
- What do we actually mean by XML conversion?
- What do we convert XML to?
Next I cover enterprise use cases for XML conversion such as data analysis and operational data integration.
I also outline why XML conversion is hard. Why do so many XML conversion projects run over budget or fail altogether?
Finally we go through the various options of converting XML. We cover manual coding approaches and automated approaches for converting XML. We outline when to use a manual approach and when to automate the process using XML conversion software such as Flexter.
First things first though.
Introduction to XML
What is XML?
XML (eXtensible Markup Language) is a markup language. Markup languages are made up of tags and attributes. They follow a hierarchical structure. Unlike HTML (another markup language), XML defines its own tags, making XML versatile for a wide range of applications, from configuration files to data interchange.
- XML defines structure, semantics, and meaning for data via tags.
- XML is self descriptive. As we will see later XML is often used in combination with an XSD, a schema definition.
- XML is text based and human readable (at least in theory). Unlike a database file you can open an XML document in a text editor and view and edit its content.
- XML has a hierarchical structure. This is useful for cases where nested data structures are required. Relationships between elements inside the XML are defined implicitly through the hierarchical structure. This is different from a database where relationships are defined explicitly via foreign key constraints
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
You can easily derive the structure, relationships and meaning from the XML tags, the hierarchy, and the content.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<?xml version="1.0"?> <books xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="BookSchema.xsd"> <book> <title>Harry Potter and the Sorcerer's Stone</title> <author>J.K. Rowling</author> <year>1997</year> </book> <book> <title>The Hobbit</title> <author>J.R.R. Tolkien</author> <year>1937</year> </book> </books> |
What is an XML schema?
While XML provides a way to represent structured data in a flexible manner, XML schemas (XSDs) apply governance and rules around XML documents. XML gives you unlimited flexibility in defining a structure. Often this is not a good idea as you want to apply standards and predictability. This is the purpose of an XSD (XML Schema Definition). It is very similar to the concept of a schema in a relational database.
XSDs allow you to validate XML documents. You can use them to check that the XML conforms to the rules set out in the schema. By defining what elements and attributes are allowed, in what order, and with what data types and structures, an XSD provides a blueprint against which XML documents can be checked for compliance.
With an XSD in place, you can ensure that all XML documents adhere to the same structure and format. This consistency is crucial, especially when XML documents are being exchanged between different systems or parties.
An XSD serves as a form of metadata and documentation. You can refer to the XSD to understand the structure, elements, attributes, and types expected in the XML documents.
Data Type Specification: Unlike XML, which doesn’t differentiate between data types (everything is text), XSD allows you to define specific data types for elements and attributes, such as strings, integers, dates, etc.
Beyond simple structure and data types, XSDs can also define constraints, such as:
- Specifying an element or attribute as mandatory (minOccurs) or optional (maxOccurs).
- Defining patterns that a text string must match (useful for things like phone numbers or email addresses).
- Enumerating the allowed values for an element or attribute
XSD example
Below is a simple example of an XSD
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
<?xml version="1.0"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <!-- Definition of a book --> <xs:complexType name="BookType"> <xs:sequence> <xs:element name="title" type="xs:string"/> <xs:element name="author" type="xs:string"/> <xs:element name="year" type="xs:int"/> </xs:sequence> </xs:complexType> <!-- Definition of books element which is a list of book --> <xs:element name="books"> <xs:complexType> <xs:sequence> <xs:element name="book" type="BookType" maxOccurs="unbounded"/> </xs:sequence> </xs:complexType> </xs:element> </xs:schema> |
Let’s go through some of the elements
- Comments such as <!– Definition of a book –> are used as documentation inside the XSD
- BookType is a complex type. Complex types can contain other elements and attributes, allowing for the definition of structured data objects.
- xs:sequence tells us that the child elements should appear in the exact order as defined in the sequence.
- The books element is of type BookType. It introduces the constraint maxOccurs
What is DTD and how is it different from XSD?
DTD stands for Before we had XSDs we had DTDs. They were the first attempt to define rules and structure around XML. As a matter of fact, DTDs existed before XML. DTDs in the context of XML can be considered as legacy and obsolete. They have been superseded by XSDs.
XSDs have various advantages over DTDs.
- DTDs don’t support data types
- DTDs don’t support namespaces
- DTDs have their own syntax whereas XSDs themselves are based on the XML markup language
Why is an XSD useful for XML conversion?
An XSD provides a clear definition of the structure, constraints, definitions and data types expected in the XML document. When we convert from XML to a database structure we have a blueprint to work from. We can translate the information such as constraints, relationships, data types in the XSD to equivalent objects in the database schema.
| XSD | The equivalent DDL in a database |
|---|---|
| <?xml version=”1.0″?> <xs:schema xmlns:xs=”http://www.w3.org/2001/XMLSchema”> <xs:element name=”book”> <xs:complexType> <xs:sequence> <xs:element name=”title” type=”xs:string” /> <xs:element name=”author” type=”xs:string” /> <xs:element name=”year” type=”xs:int” /> <xs:element name=”isbn” type=”xs:string” /> </xs:sequence> <xs:assert test=”year <= year-from-date(current-date())”/> </xs:complexType> </xs:element> </xs:schema> | CREATE TABLE Book ( title VARCHAR(255) NOT NULL, author VARCHAR(255) NOT NULL, year INT CHECK (year <= EXTRACT(YEAR FROM CURRENT_DATE)), isbn VARCHAR(13) NOT NULL UNIQUE PRIMARY KEY ); |

Why did XML fall out of favour?
XML was officially released in 1998 by the WWC. At the time it was considered as the ultimate data serialisation and exchange format.
As the years went by, XML fell out of favour. There are many reasons for it.
While XML gives users a lot of flexibility it is considered complex and verbose.
Unlike JSON it requires closing tags, which adds overhead both in creating and processing XML (performance and CPU penalty). Namespaces in XML and XSD are not intuitive and add complexity.
With the rise of Web 2.0 and JavaScript, XML was sidelined. JavaScript has native support for JSON, which made it a natural choice for web developers.
Simple Object Access Protocol typically uses XML for exchanging data between web services. SOAP was gradually replaced by RESTful APIs, which use JSON.
What are some common applications and use cases for XML?
While the use cases for XML diminished over time, XML is not dead. It has carved out a few niches for itself.
Enterprises use XML for exchanging data between each other. Unlike say databases, XML is a non proprietary and non binary format that is both human and machine readable (at least in theory). This makes it a great serialisation format for exchanging data as it is agnostic to the tools used in each company. XML and XSD are widely used as part of industry data standards such as HL7, FIXML, ACORD etc. In my opinion this is the most important niche for XML. We will discuss industry data standards in more detail further down.
XML is used as a foundation for expressing RDF data and building ontologies. These are critical for the Semantic Web and artificial intelligence applications.
Web services often use SOAP (Simple Object Access Protocol), which is XML-based, to communicate between the client and server. Having said that SOAP is not used widely anymore and has been replaced by REST in many environments.
XML is widely used in the publishing industry and documents in general. Office suites like Microsoft Office (OOXML format), Google, and OpenOffice/LibreOffice (ODF format) use XML-based formats for their documents, spreadsheets, and presentations. Other examples include the popular ebook format ePub.
These are the most common use cases for XML in an enterprise environment. XML is also used for other scenarios such as configuration files, vector graphics (SVG), user interface markup in Android and various others. However, these use cases are not relevant in the context of XML conversion.
XML, XSD, and industry data standards
XML and XSD are widely used in industry data standards.
What are industry data standards?
An industry data standard refers to a set of guidelines, specifications, or best practices established by industry groups, standards organisations, or consortiums to ensure that data is consistently defined, captured, and exchanged in a particular way within that industry.
Industry data standards typically contain both business and technical specifications.
Business specifications: business concepts and business rules
Central to any data standard is the precise definition and disambiguation of concepts. This ensures that all participants in the ecosystem have a common understanding of what specific terms and data elements mean.
Business rules define or constrain some aspect of the business. They assert business structure or control/influence behaviour. In the context of industry data standards, business rules might detail how certain data is validated, processed, or interpreted. Here is an example of a business rule in a healthcare standard: A patient’s primary diagnosis code cannot be left blank.
Technical specifications
The core part of the technical specification is the data model and schema. It defines the structure of data, including entities, attributes, data types, and their relationships. XML-based standards typically provide an XML Schema Definition (XSD) to specify what the structure of an XML message should look like to conform to the standard.
Other items that are part of the technical specification are data quality rules (often derived from the business rules), encoding standards, documentation, usage samples, message patterns and sequencing, and versioning.
Why are industry data standards so complex?
There are many reasons why industry data standards can be quite complex.
- Industries have varied processes, terminologies, and workflows. A data standard needs to accurately capture all these aspects to be useful and widely adopted. Many stakeholders contribute to the development of industry standards—vendors, end-users, regulators, and more. Accommodating the needs and concerns of these diverse groups can be tricky and add layers of complexity. Often the standard also needs to cater for a global audience which adds further layers of complexity.
- Industries evolve, and their needs change. Data standards must be flexible to accommodate current requirements and extensible for future needs. This often means building in structures or features that may not be immediately necessary but are important for long-term viability.
- Many industries, especially those like finance, healthcare, and insurance, have stringent regulatory requirements. Data standards in these sectors need to cater to these regulatory demands, adding to their complexity.
- To ensure data quality and consistency, standards often define intricate validation rules, dependencies, and constraints.
- Standards often incorporate advanced features like versioning, security mechanisms, transaction support, and more. While these are necessary for robust implementations, they also add complexity.
- Historical Baggage: Over time, as industries and technologies evolve, standards can accumulate legacy features or structures that are retained for the sake of existing implementations, even if they might seem redundant or sub-optimal in a modern context.
- Political and Organisational Factors: The development of standards often involves negotiations, compromises, and consensus-building among various entities. The final product can sometimes be a result of these dynamics rather than just technical or industry needs.
Complexity in industry data standards is both a challenge and a necessity. While it poses implementation and comprehension challenges, it’s also a testament to the standards’ robustness in addressing the multifaceted requirements of modern industries.
All these complexities of defining a standard and agreeing on its core areas are also reflected in the schema definition and XSDs of the standard. Complex standards result in complex XSDs. This is one of the reasons why it can be hard and difficult to convert XML based on a data standard to a tabular or relational format. We will cover this topic in detail in a moment.
Why is XML so popular with industry data standards
XML and XML schemas are very versatile and support advanced features such as inheritance, polymorphism, and complex types. This makes it a perfect fit for dealing with the complexities we encounter in industry data standards that we have discussed earlier on.
Inheritance is a concept that enables a standard to define a new data type based on an existing data type by adding new elements (extension). This concept of inheritance in XSD is primarily realised through the use of “complex types”.
Here is an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
<?xml version="1.0"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <!-- Base complex type for Person --> <xs:complexType name="PersonType"> <xs:sequence> <xs:element name="FirstName" type="xs:string" /> <xs:element name="LastName" type="xs:string" /> <xs:element name="DateOfBirth" type="xs:date" /> </xs:sequence> </xs:complexType> <!-- Extended type for Employee that inherits from PersonType --> <xs:complexType name="EmployeeType"> <xs:complexContent> <xs:extension base="PersonType"> <xs:sequence> <xs:element name="EmployeeID" type="xs:string" /> <xs:element name="DateOfJoining" type="xs:date" /> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> </xs:schema> |
A PersonType is defined with basic attributes: FirstName, LastName, and DateOfBirth.
An EmployeeType extends PersonType and adds EmployeeID and DateOfJoining.
Industry data standards mainly use XML and XSD. A notable exception is FHIR by HL7. FHIR supports both JSON and XML. It even ships with a JSON schema, which can be downloaded from the website.
However, as we have discussed already, JSON does not support some of the advanced concepts of XML such as complex types or inheritance. It relies on workarounds using arrays or extensions in URLs. Here is an example of an extension in a JSON document defined as a URL.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
{ "resourceType": "Patient", "id": "12345", "name": [ { "family": "Smith", "given": ["John"], "extension": [ { "url": "http://example.org/fhir/StructureDefinition/preferred-language", "valueCode": "en" } ] } ] } |
The extension is nested inside the name element. indicating that this preferred language extension specifically relates to the patient’s name.

What are some common industry data standards using XML?
Sonra’s XML conversion software Flexter is very popular in insurance, healthcare, mutual funds, finance, and travel. Some of the world’s largest asset managers use Flexter.
I have listed some common industry standards grouped by industry. Some industries have multiple standards and some of them even compete with each other.
I have listed some common industry data standards in insurance and asset management / finance.
Data standards in asset management / funds management
FpML (Financial products Markup Language): This is the industry standard for electronic dealing and processing of derivatives. It establishes the protocol for sharing information on, and dealing in, financial derivatives and structured products.
FIXML: The FIX Protocol is a messaging standard developed specifically for the real-time electronic exchange of securities transactions. FIXML is the XML representation of the FIX Protocol.
ISO 20022: While not limited to asset management, ISO 20022 is a standard for electronic data interchange between financial institutions. It describes a metadata repository containing descriptions of messages and business processes, and a set of XML and ASN.1 based message formats.
SWIFT Messages: While SWIFT is best known for its traditional tag-based messaging format, they have been moving towards XML-based messages for various financial communication purposes.
FundXML: This is a global data standard for the investment fund industry, providing a consistent and efficient exchange of data between fund manufacturers, distributors, data vendors, and regulators.
Data standards in insurance
ACORD is a global standards-setting body for the insurance and related financial services industries. It provides standardised XML message formats for various insurance processes, from policy application to claims processing.
Global Reinsurance Standard Accounting & Settlement (GRSAS): This standard is developed for the reinsurance industry to standardise technical accounting and claims processes using an XML-based message format.
Guidewire’s suite of applications (like PolicyCenter, ClaimCenter, and BillingCenter) supports multiple integration mechanisms, and XML is a prominent one among them.
Duck Creek also supports XML-based integrations, especially when interfacing with external systems or third-party data providers.
What is XML conversion?
Now that we have some good background knowledge on XML and understand its use cases we can move to the main topic of this blog post: XML conversion and XML conversion software.
Let’s first define what we mean by XML conversion so that we sing from the same hymn sheet for the rest of this post.
When we talk about XML conversion we mean the translation of data stored and serialised in XML to another format.
Let’s look at some common target formats
XML to tabular format
XML to tabular format in text (CSV, TSV etc). Converting complex XML structures to CSV is challenging since XML can represent hierarchical data, while CSV is flat. Our own XML conversion tool Flexter converts XML to text and imposes a relational format on top of CSV. It also creates parent and foreign key columns between the CSV files. Flexter does not just flatten the XML file to text but it creates multiple files with parent child relationships.
For your help we have also written a detailed guide on XML to CSV conversion here, we have also compared the best XML to CSV converters here and a guide on how to convert XML to CSV and open it with Excel.
XML to JSON
XML to another hierarchical format. We often see that developers convert XML to JSON as they lack the skills to properly process XML. This works for simple scenarios but not for complex scenarios that involve industry data standards.
XML to relational format
XML to a relational format. This is the most common scenario. We need to convert XML to a relational format in a database for easier analysis and querying. Flexter converts XML to all common relational databases such as Oracle, MS SQL Server, PostgreSQL, MySQL and all common data platforms such as Snowflake, Databricks, BigQuery, Redshift, Teradata, Azure Synapse etc.
XML to binary big data format: Delta table, Parquet, ORC, Avro
Over the last few years some new data serialisation formats have evolved. All of them are open source.
- Parquet and ORC are both columnar storage formats and have their roots in the Hadoop ecosystem. They are used for use cases in data analytics such as data lakes and data warehouses.
- Databricks evolved Parquet into the Delta Lake format. It adds features such as time travel (data versioning), update, delete, merge to Parquet. Delta Lake is used for data analytics use cases.
- The Avro format is a row based storage format. Avro’s compact binary format and fast serialisation/deserialisation make it suitable for real-time data processing systems, where low latency is a priority. It is heavily used in Kafka.
With Flexter you can convert XML to Delta Lake, Parquet, ORC, Avro.
Why do we convert XML?
The main use case for XML is data exchange between enterprises, e.g. as part of an industry data standard. Internally different organisations use different tools and technologies for data processing and data storage. As a text based format, XML is a common denominator for data exchange.
An example
As part of a data exchange in healthcare, the sending party converts data from an Oracle database to HL7 XML. The receiving party needs to convert the data into their data warehouse on Snowflake for data analytics.
While XML is well suited for data exchange it is not a good fit for data analytics and transactional processing. Relational databases are a much better fit for these use cases.
XML is good for transporting data. It is not good for processing data.
I have outlined the limitations of XML for common data processing scenarios: transaction processing aka OLTP and data analytics use cases aka OLAP.
XML limitations for transaction processing (OLTP)
XML is not a good fit for transaction processing for various reasons.
- Processing XML can require loading the entire document into memory, which can be inefficient, especially for large XML files.
- The time taken to parse XML documents can be detrimental in high-throughput transaction processing systems.
- Poor ACID capabilities. Ensuring atomic updates to XML, especially in distributed systems, can be challenging.
- Managing concurrent access to XML is very challenging. Traditional databases use row-level or page-level locking to manage concurrent access. In the context of XML implementing efficient fine-grained locking mechanisms can be challenging. Coarse-grained locks (like locking an entire document) can lead to contention and reduced system throughput.
XML limitations for data analysis (OLAP)
XML is not a good fit for data analytics use cases such as BI reporting, dashboards, KPIs or data warehousing.
While it is possible to query XML using XPath (XML Path Language) and XQuery (XML Query Language) it is only recommended for simple use cases and scenarios.
I have listed some of the limitations of XML for data analytics use cases
- Columnar Storage: Modern data analytics often relies on columnar storage formats (e.g., Parquet, ORC) because they allow for efficient compression and faster query performance.
- Related to the previous point – Storage Costs: Given its verbosity, storing large datasets in XML format can lead to higher storage costs compared to more compact formats.
- XML does not integrate with BI tools
- Querying data I: XML allows for nested, hierarchical structures, which can sometimes make query expressions complicated, especially if you’re trying to navigate through deeply nested elements.
- Querying data II: Unlike relational databases, XML files aren’t indexed. This will make queries much much slower.
- Querying data III: Both XPath and XQuery can sometimes require verbose expressions to access data, especially when dealing with namespaces or deeply nested elements.
In summary, while XML is a good fit for exchanging data between organisations due to its universal format it is not a good format for data processing, transactions, or data analysis.

Why is XML conversion hard?
In theory XML is a human readable format but the reality can be quite different as this XML joke points out.
“Some languages can be read by humans, but not by machines, while others can be read by machines but not by humans.
XML solves this problem by being readable by neither.”
The joke gives us a hint of why XML conversion is hard. It plays on the idea that while XML is technically human-readable, its verbosity and often complex structure can make it cumbersome and hard to understand, especially when XML documents are large or deeply nested.
Let’s go through the various reasons why XML conversion and XML conversion projects are hard.
Complexity of data standard = complexity of XSD
The number one reason why XML conversion projects are hard is related to the inherent complexity of industry XML data standards.
The complexity of the industry data standard translates to a complex XSD, which in turn translates to a complex conversion project. Complexity in general makes any task hard. This is no different for XML conversion projects. Let’s have a look at some of the features we come across in complex XSDs.
- Most XSDs defined for industry standards make extensive use of advanced XML schema features like inheritance, polymorphism, and complex types. These provide power and flexibility but can make the schema harder to understand for newbies or engineers not familiar with XSD.
- XSDs can be modularized by splitting them into multiple files. One XSD can then import or include another XSD. By using import and include, you can create a modular schema architecture, effectively nesting or chaining XSDs together. We have seen instances with more than 100 modular XSD files that are nested and embedded. This makes it very hard to see the forest from the trees and to get a helicopter view of the schema.
- Include another XSD file in the same namespace
|
1 |
<xs:include schemaLocation="otherSchema.xsd" /> |
Import another XSD file in a different namespace
|
1 |
<xs:import namespace="http://example.com/namespace" schemaLocation="externalSchema.xsd" /> |
- XSD used in industry standards often provide a mechanism (<xs:redefine>) to allow elements or types from an external XSD to be redefined in the current XSD schema. It is very hard to track these redefinitions.
- To ensure data quality, XSDs include numerous constraints and validation rules. This can include patterns, allowable value ranges, dependencies between fields, and more.
- Redundancy: Sometimes, for the sake of accommodating different stakeholders or historical reasons, there might be redundant elements and structures in the XSD.
- Namespaces in XML, and by extension in XML Schema Definitions (XSD), are a mechanism to qualify element and attribute names by associating them with a namespace identified by a URI. This ensures global uniqueness of names and avoids naming conflicts, especially when integrating XML documents or schemas from various sources.
FpML as an example of a complex XML standard
As an example we reverse engineered the XSDs of the FpML standard in an XML editor. We got 18 pages of instances and attributes.
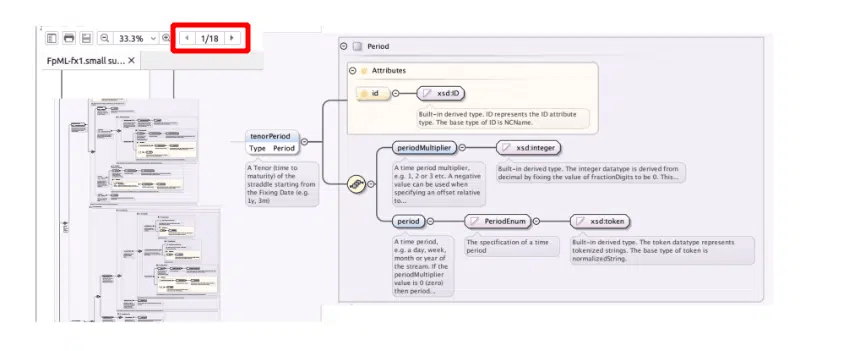
We then used Flexter to generate a relational target schema from just a subset of the FpML XSD. To put it into perspective this would translate to thousands of tables in a database.
Flexter generated the following target schema. An unintelligible spider web of tables and relationships. And this was just for a subset of FpML.
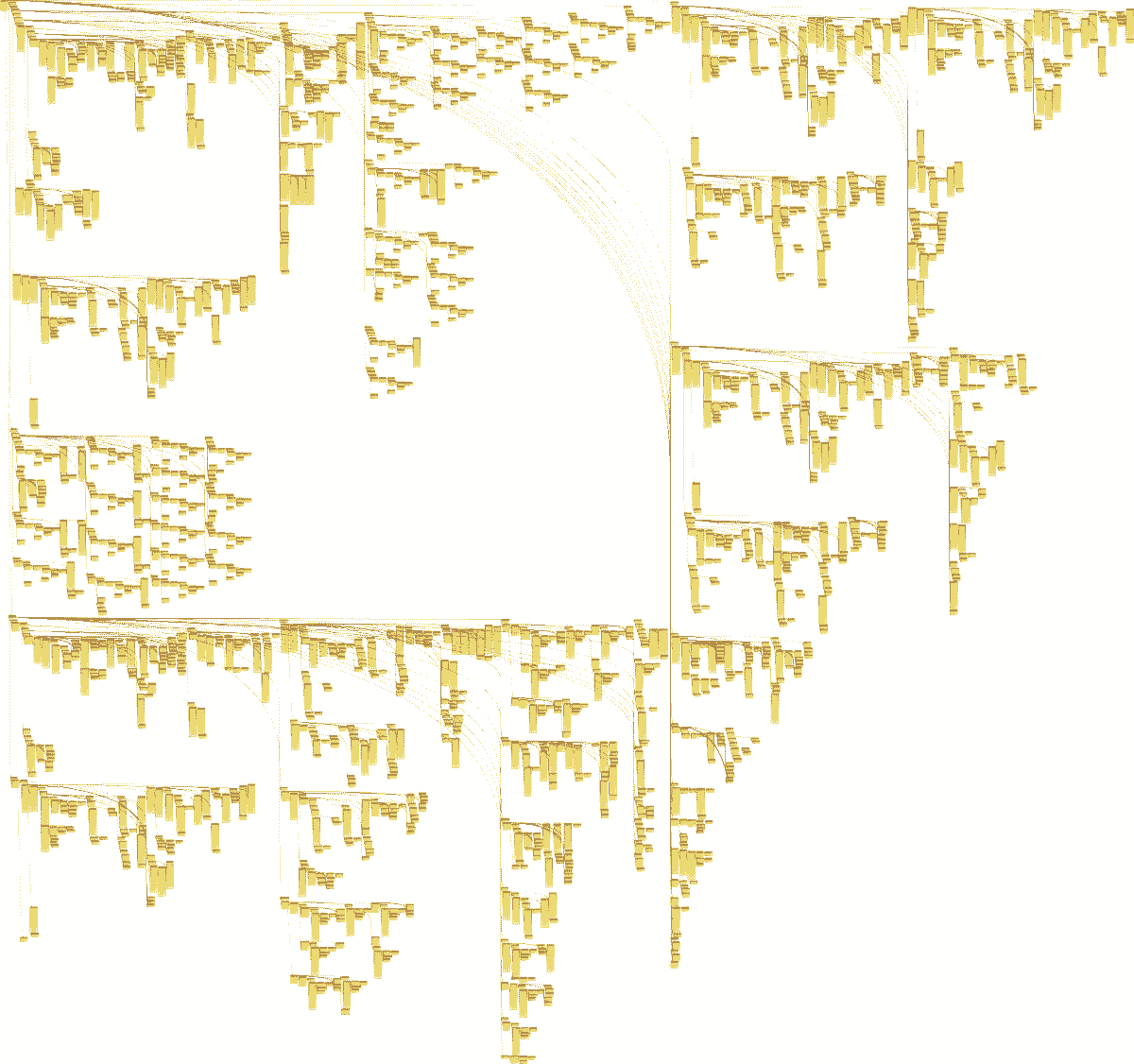
Each of the dots represents a separate table, Imagine going through this process manually.
We created a separate blog post where we convert the FpML XSD to a relational schema in a data modeling tool. It shows you each step in more detail.
Handling very large XML files
Individual XML files that exceed 1 GB are generally considered to be very large.
Processing these huge files can pose significant challenges to your XML conversion project for the following reason.
Traditional XML parsers, like DOM (Document Object Model) parsers, load the entire XML document into memory to create a navigable tree structure. For large XML files, this can lead to excessive memory usage and may even exceed the available memory, causing the system or application to crash.
For converting very large XML files you will need to apply a streaming approach to XML processing. Read the XML sequentially and emit events for start tags, end tags, text, etc. as you go. This allows processing very large XML files with a constant memory footprint.
Flexter uses a SAX parser for any scenario. It’s efficient and consumes less memory than DOM parsers. Flexter has a parameter –byte-stream that loads the file byte-by-byte to the SAX parser. This way we avoid keeping the whole file in memory while it parses and converts.
Designing the relational target schema and generating keys
When the schema is very complex it is hard to design a good relational target schema. When there are thousands or tens of thousands of XPaths it is very tricky to decide which XPaths can go to the same table and which ones should be linked as child tables.
The next problem is the generation of primary and foreign keys.
When we receive incoming data and distribute it across designated tables, we need to reconnect them using what’s called foreign key relationships. Essentially, every entry in a subsidiary table should reference its corresponding entry in the main table.
However, a challenge arises with XML data. Typically, XML doesn’t provide unique identifiers that can easily be used for this reconnecting purpose, as explained in the official XML schema documentation (cf. W3C reference on xs:key, xs:unique, xs:keyref).
To address this, we must develop a reliable method to generate unique identifiers for these main and subsidiary table entries. These identifiers must be:
- Distinct for repeated sections within the same XML file (scope: file).
- Unique across repeated sections from different XML files loaded simultaneously (scope: batch).
- Consistent and non-repeating for any sections from any XML loaded at different times (scope: full history).
All this needs to be achieved without overlapping or duplicating identifiers.
In summary, creating unique keys to link the main and subsidiary table entries is a complex task, given the nature of XML data.
XML conversion use cases in the enterprise
Enterprise XML conversion use cases broadly fall into two categories. XML conversion for data analytics and OLAP. XML conversion for transaction processing and data integration.
XML conversion for data analysis
Data that is locked away in XML needs to be analysed. As we outlined in the section on the reasons for converting XML to a relational format the XML ecosystem such as XQuery and XPath is a bad fit for data analysis.
Relational databases and SQL are a perfect fit for data analysis.
Data warehouse
XML is a common data source for data warehouse implementations.
Various enterprise platforms export data in XML format. Before this data can be analysed and queried, it needs to be converted to a relational format in the data warehouse.
Let’s go through the design and architecture of converting XML data to a data warehouse.
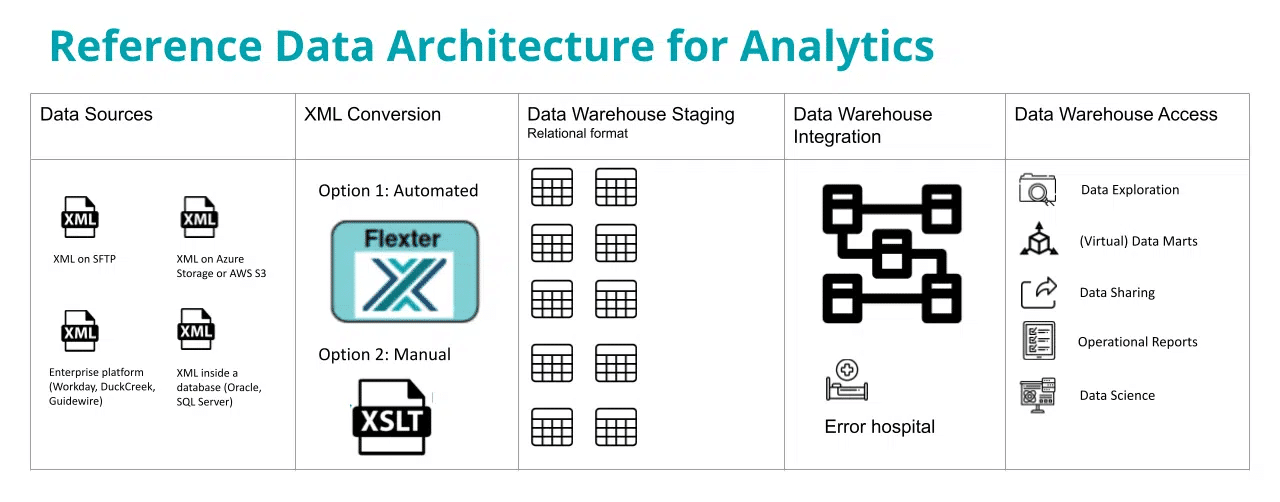
Your XML documents are one of the data sources for your data warehouse. The XML documents may land on SFTP or object storage in the cloud such as AWS S3, Azure Blob storage. Another common source for XML documents are enterprise platforms such as Workday, Duck Creek, or Guidewire. XML documents may also be stored in a relational database such as Oracle or MS SQL Server. These databases and many others have native support for XML and store XML documents in special data types such as XMLTYPE, CLOB, VARIANT, BLOB, XML etc.
Depending on the complexity you can use an automated or manual approach to convert the XML files to the Staging layer in the data warehouse. Flexter is an automation tool for XML conversion. Another option is to write code to convert XML, e.g. XSLT. For complex conversion projects we recommend an automated approach. The output of the XML conversion process are tables with rows and columns inside the Staging layer.
This layer is an integral part of data warehouse architecture. It is also referred to as the raw layer where data is stored as a copy of the data source. No business logic or column mappings should be applied between the XML source documents and the Staging layer. Any transformations to data should be applied as far downstream to the access layer as possible. This rule also applies to XML conversion. Don’t apply business logic or transformations between the XML and the Staging layer.
Once you have converted your XML files to a relational format in the Staging layer you can make the data available to consumers through the integration and access layers in your data warehouse. Please refer to our blog post on reference data architecture for data platforms for detailed design recommendations.
Data Lake and Data Lakehouse
Another popular design pattern for data analysis is the data lake and the data lakehouse.
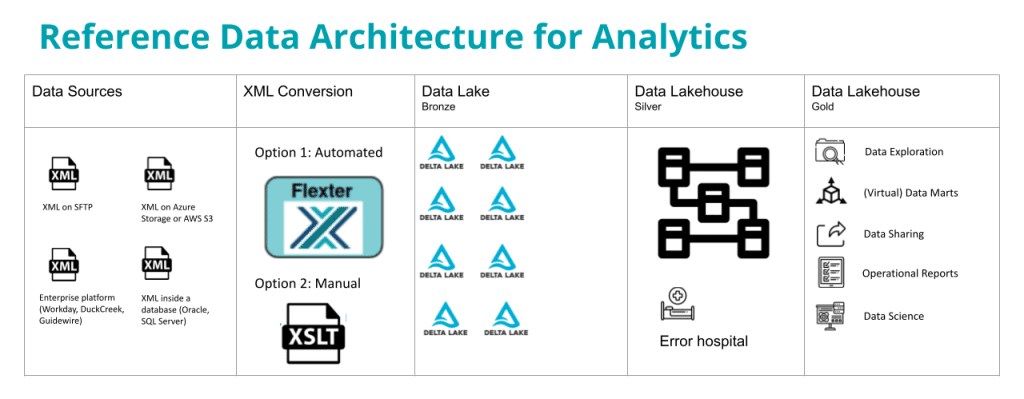
There are some minor differences between a data lakehouse and data warehouse approach. Instead of storing the raw output of the XML conversion in a database it is stored on object storage as Delta Lake or Parquet files. Flexter supports both formats as output of the conversion process.
The terminology is also slightly different. Instead of referring to the raw layer as the Staging area we refer to the raw layer as the Data Lake or Bronze layer. The Integration layer is referred to as the Curated layer or Silver layer. The access layer is referred to as the Consumable or Gold layer.
The XML conversion process follows very similar design patterns in both the data lakehouse and data warehouse approach. Flexter supports both paradigms. I have written up a separate post on XML conversion in a data lake scenario.
XML conversion for operational data integration scenarios
XML is a common format in enterprise data integration scenarios. XML messages are often processed one at a time and converted to different target formats.
SOAP, a protocol for web services, uses XML for its message format. Systems interfacing with SOAP services may convert their data to XML to communicate with these services.
Middleware and Integration Tools for operational data exchange: Enterprise tools like MuleSoft, Apache Camel, or Microsoft BizTalk can handle complex XML conversions in operational data integration scenarios.
Why do so many XML conversion projects fail?
A successful XML conversion project makes data:
- Intelligible
- Readable, and
- Analysable
And all of this at speed and high performance
Why is it, though, that so many XML conversion projects go over budget or fail completely?
From our experience, the main cause is a lack of XML expertise and skills, an inflated confidence in handling XML (not as simple as it looks), not fully grasping the intricacy of industry data standards, limitations in available XML conversion tools, and limited experience with complex XML scenarios (nested XSDs, inheritance etc.).
Existing XML conversion software also has various limitations.
Let’s go through the challenges in detail.
Lack of skills
XML and related technologies such as XSLT, XQuery, XPath, DOM, SAX are niche. Very few engineers have the in-depth knowledge that is needed for a complex XML conversion project. What is more, few engineers are interested in acquiring these skills, which are perceived as legacy without broad market demand.
Many developers claim they can easily read XML and question how challenging it could be to convert it to a database. We often encounter such sentiments. However, this overconfidence can backfire, and developers soon realise that navigating the intricacies of complex XML presents numerous challenges.
The lack of skills runs through all steps in the XML conversion lifecycle. It is not uncommon for the development lifecycle to take weeks or months. We have seen some projects taking more than a year with several failed attempts. The sad result is that data is not available to decision makers.
Analysis and requirements
Data analysts lack the skills to efficiently query the data that is locked away in industry data standards. Data analysts are great with SQL but don’t know XQuery or XSLT. As a result they often fail to accurately capture the requirements and are unable to make sense of the data or to detect data anomalies.
With Flexter, data analysts can quickly convert the XML to a database and use the tools they know to get the job done.
Development
Data engineers are good at working with relational databases and SQL. They typically lack the skills to write code to process XML efficiently.
With Flexter you get an immediate and automated analysis, an optimised relational data model and mappings between source XML elements target table columns.
Design and performance
The lack of skills leads to solutions that don’t scale well. Solutions that are developed in-house by companies may satisfy the functional requirements and work with small volumes of data but fail completely for larger volumes of data or are not able to meet SLAs.
We have seen an XML conversion pipeline running for 24+ hours using a popular ETL tool. The pipeline just converted 50,000 XML documents in this period.
Flexter has a scalable architecture. You can scale up by adding compute (vCores) to a single server. You can scale out by bundling . With Flexter we were able to bring down the execution time of the XML conversion pipeline to 5 minutes.
Documentation
In data analysis one documentation artefact is a source to target map. For complex data standards with thousands of attributes this can take a very long time.
Flexter stores any mappings from the source XML elements to the target table columns in a metadata catalogue. It can automatically generate a source to target mapping document.
If you check the staging schema generated by Flexter you will notice that tables and columns are commented. The commentary provides source to target mappings, e.g. we can see that column JOURNEY_TIME comes from /FlightPriceRS/DataLists/FlightList/Flight/Journey/Time.
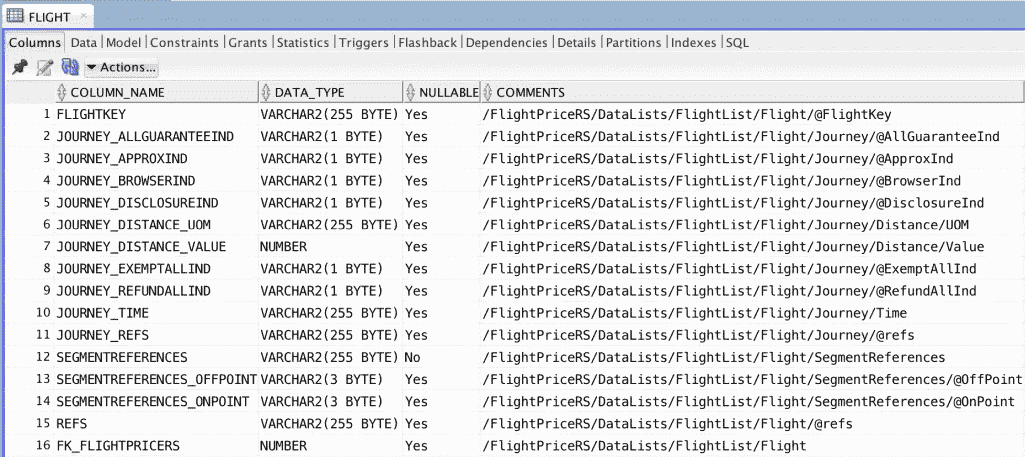
Data lineage and the source to target mapping:
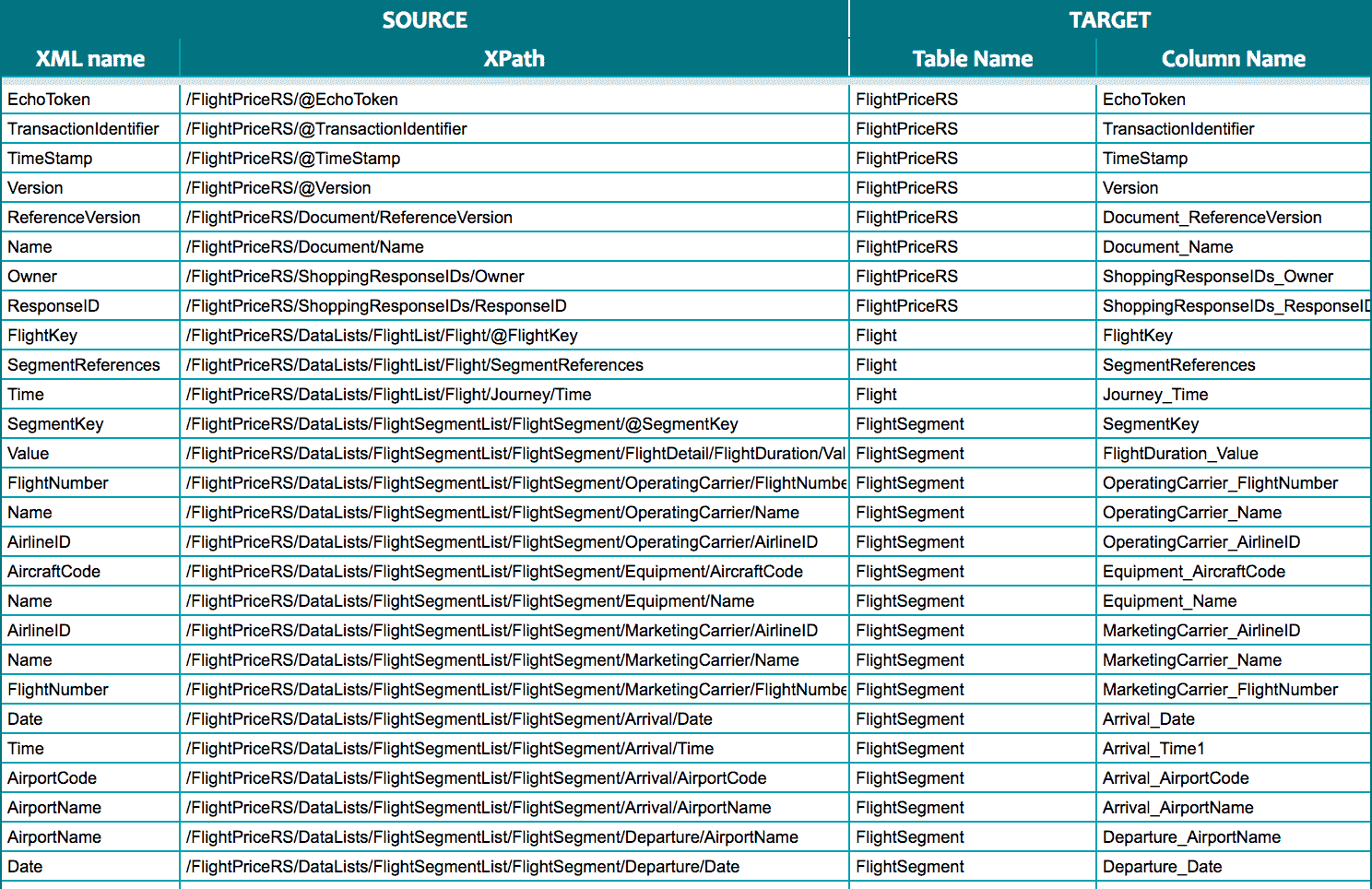
Both data lineage and the optimised target schema make it easy and fast to query, analyse, and visualise data for downstream data analytics and reporting.
Changes, schema evolution and refactoring
Problem: Change is part of life and also part of the XML and XSD lifecycle .
There are two dimensions to change:
Changes at design time: Identifying changes inside an XSD or XML can be a time consuming task even if you have the skills.
Changes identified at runtime: These are unexpected sceanrios during the actual conversion process, e.g. an XML document that does not conform to the schema.
Solution: Flexter can handle both types of changes. It automatically detects changes in an XSD at design time. It compares different versions of the schema to identify any new or changed elements. Using the metadata catalog you can semi-automate the upgrade from one version to another.
Flexter detects rogue XML files at runtime that do not conform to the schema during conversion and writes this fact to the error log. You can send out an alert or notification.
XML Conversion tools
There are four types of problems we have encountered with existing tools
Problem: Most tools do not automate the XML conversion process. Instead they have an interface to generate the conversion process in a GUI through drag, click, and point. Developers still need to manually map the XML to tables and columns in the target schema.
Solution: Flexter fully automates the XML conversion process to a relational format.
Problem: Most tools require an XSD to generate a target schema. Often no XSD exists. This is the case with many XML projects that were implemented in house.
Solution: Flexter can generate a target schema from an XSD or a sample of XML files. It can even combine an XSD with an XML sample to get the best of both worlds.
Problem: We have seen severe performance issues with tools that process XML files in sequence rather than applying a bulk approach.
Solution: Flexter processes XML in a massively parallel fashion and in bulk. It achieves huge throughput. It fully parallises the XML conversion process across multiple CPUs and even across servers in a cluster. Meet any SLA.
Problem: We have seen most conversion tools crash for very complex XSDs with dozens of XSD files and deep levels of nesting.
Solution: Flexter can handle any level of complexity
Problem: Many XML conversion tools are stuck in the past and don’t have support for the modern data stack in the cloud.
Solution: Flexter has been built from scratch with the cloud and scalability in mind. It fully supports the modern data stack and is certified on cloud data platforms such as Snowflake, BigQuery, Redshift, Athena, Databricks, Azure Synapse. It supports cloud object storage such as S3, Azure Data Lake Storage, Azure Blob Storage etc. You can run Flexter on a single machine (VM), on Kubernetes or on a Spark, Databricks or Hadoop cluster.
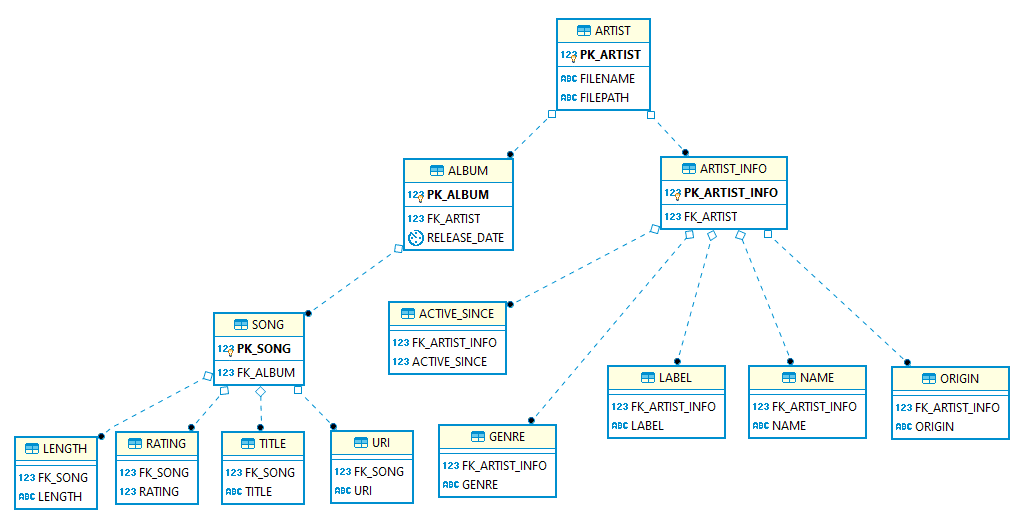
Problem: Most XML conversion tools generate an overly complex target schema. The reason for this is that they map the levels in the hierarchy of the XML to different tables, e.g. in a parent and child relationship. Often XML designers introduce artificial hierarchies or logical groupings that do not represent separate tables or entities. The tools are not able to detect these “anomalies”.
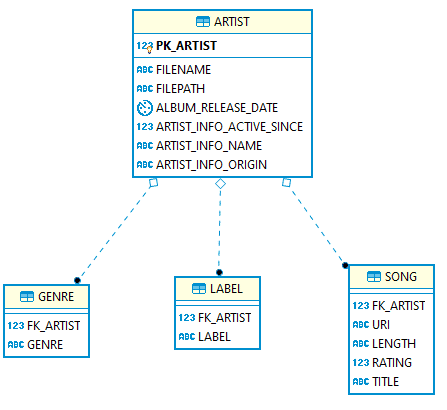
Solution: Flexter ships with two optimisation algorithms to simplify the target schema. We have put together an entire blog post to illustrate the problem and solution. Optimisation algorithms for converting XML and JSON to a relational format covers the elevate optimisation. Re-use algorithms for converting XML and JSON to a relational format covers the reuse optimisation.
Complex target schema without optimisations
More simple target schema with optimisations
We have created a white paper on 6 steps for a successful XML implementation project.
XML converters and types of XML conversion?
Two different approaches to XML conversion exist. You can write code to convert the XML or you can use an automation tool to convert XML. The approach you should take depends on the complexity of the XML, company culture, e.g. tool first philosophy, the number of XML schemas to convert, the available XML skills in the organisation, the size of individual XMLs and the XML data volume.
Let’s first go through the two types of XML conversion in detail before I make some recommendations on which of the two approaches to take.
Manual XML conversion
XML conversion steps
Manual XML conversion is very labour intensive. It involves the following steps:
Analyse the XML Structure and XSD:
Inspect the XSD and XML to understand its structure, hierarchy, and the type of data it contains.
Identify the main entities (which could potentially become tables in your database) and their relationships.
Design the Database Schema:
Based on the XML analysis, design your database schema. This includes deciding on tables, columns, data types, primary keys, and relationships.
Create the Data Definition Language (DDL) scripts for the schema creation, which includes CREATE TABLE statements, and constraints like primary and foreign keys.
Define Mappings:
Determine how the elements and attributes in the XML map to the tables and columns in your database schema. For complex XML structures, you might need intermediate parsing steps or even temporary storage.
Parse the XML:
Use an XML parsing library suitable for your programming language to read and traverse the XML structure. Extract the data in a manner based on your mappings.
Insert Data into the Database:
Once the data is extracted, insert it into your database following the designed schema.
Ensure that you respect the relationships, constraints, and any other schema-specific rules during insertion.
Data Validation:
After the conversion, validate the data in your database against the original XML to ensure accuracy and completeness.
You may want to run some sample queries or reports against both the XML (using an XML querying tool) and the database to see if they produce consistent results.
Optimisation:
If you have a large amount of XML data or need frequent conversions, consider optimising your parsing and load procedures.
Pipeline Design:
Ingestion: How is the XML data ingested?
Processing: After ingestion, the data may need pre-processing, cleansing, or validation before the actual conversion.
Conversion: The main module where XML is transformed and loaded into the database.
Post-processing: Activities after data insertion, like indexing, aggregation, or further data validation.
Scheduling:
Determine the frequency of XML data arrival and conversion requirements. Is it daily, hourly, or near real-time?
Use tools like Apache Airflow (recommended), Cron jobs (for simple schedules), or other job schedulers to automate the process.
Monitoring and Alerting:
Incorporate monitoring to check for failures, delays, or anomalies in the conversion process.
Implement alerting mechanisms to notify relevant stakeholders or systems in case of issues.
Error Handling and Recovery:
Design mechanisms to handle errors gracefully. Should the pipeline retry automatically? If an error occurs, how can you ensure data consistency or rollback?
Implement logging to capture both system and data issues for diagnosis.
Documentation:
Document your mapping rules, any transformations applied, and any challenges or peculiarities you encountered. This will be valuable for any future conversions or if the data needs to be understood by another person or team.
ETL tools
You might be surprised to find ETL tools listed in the manual conversion section. While they offer some abstraction and automation the extent can be quite limited. At the end of the day an ETL tool has features to generate code visually. Often all that is provided is a UI on top of XPath. Very limited indeed.
While most modern ETL tools support XML, not all of them do, or they might offer limited functionalities. While the ETL tool vendor claims to have support for XML it is often just a check boxing exercise for a feature list. Make sure to run a POC to check that the tool meets your specific requirements.
Here are some limitations to watch out for
A lot of manual work
ETL tools provide some abstractions to handle the conversion process. However, from our own experience the conversion process with these tools is still very manual and labour intensive.
Mappings need to be applied manually by drag, point, and click from the source XML elements and target table columns.
The XML conversion pipeline needs to be clicked together manually by an ETL engineer.
Documenting the implementation of the conversion project is also a manual process.
Schema evolution
XML data sources can evolve over time. ETL tools may require manual intervention or reconfiguration if the XML schema changes.
Complex hierarchies
XML can represent intricate hierarchical structures which may not map cleanly to the relational tables that many ETL tools are designed to populate.
Performance issues
Parsing and transforming XML, especially large or deeply nested XML files, can be resource-intensive. ETL tools might struggle with performance or consume significant resources for such tasks.
Native XML database features
Some databases offer native features for XML processing and converting XML to a relational format.
The most advanced XML features can be found in Oracle, MS SQL Server, and IBM DB2. Cloud based data platforms such as Snowflake or Spark / Databricks also have support for XML.
Other vendors such as BigQuery, Azure Synapse, or Redshift have very limited support for XML XML queries, and XML conversion. I have put together a separate blog post on converting XML to Snowflake here.
The biggest downside of XML processing inside a database is the manual nature of this work. For complex mappings you have to go through all of the steps I have outlined in the section on manual XML processing. This can take up a lot of time depending on the complexity of your schema. It is also worthwhile noting that the relationship between the complexity and the development time is not linear. Doubling the complexity of the XML does not double the development time. it generally amplifies it even more..
XSLT
XSLT can be used to convert XML to another format, e.g. HTML or CSV.
While XSLT is well suited for operational data integration in real time it is not a great fit for bulk processing and data analysis use cases.
Here are some of the limitations of using XSLT to convert XML to a tabular or relational format
Skills
Engineers often don’t have the skills to efficiently process complex XML with XSLT. While XSLT is not super hard to learn, few developers are keen to acquire this particular skill as it is viewed by many as a legacy skill. Getting to expert level on XSLT can be also challenging. XSLT has its unique syntax, and its declarative nature can be challenging to grasp for those used to procedural programming languages.
Performance Issues:
Large XML documents or large volumes of XML documents lead to performance issues during the conversion process. XSLT is not a great fit for bulk processing of XML but more suited for operational data integration requirements.
Complexity:
Writing XSLT for complex XML structures can become very involved and hard to maintain.
Expressiveness:
While XSLT is powerful, there are certain operations or patterns of logic that might be more easily expressed in procedural languages than in XSLT.
Lack of Debugging Tools:
Compared to popular programming languages, the tools available for debugging XSLT aren’t very mature.
Limited Error Handling:
XSLT’s error handling capabilities are relatively basic. Robust error handling often requires external tools or methods.
Namespace Handling:
Working with XML namespaces in XSLT can be tricky, especially when dealing with XML documents that utilise multiple namespaces or when remapping namespaces.
Automated XML conversion
Build your own XML converter
You could of course build your own XML converter. Ralph Kimball, one of the fathers of data warehousing, does not recommend this. I agree.
“Because of such inherent complexity, never plan on writing your own XML processing interface to parse XML documents.
The structure of an XML document is quite involved, and the construction of an XML parser is a project in itself—not to be attempted by the data warehouse team.”
Kimball, Ralph: The Data Warehouse ETL Toolkit. Practical Techniques for Extracting, Cleaning, Conforming, and Delivering Data
XML conversion: automation tools
XML converters that offer complete automation for XML conversion overcome the challenges and constraints of manual conversion methods dependent on coding. However, they may be excessive for many situations. I will outline the criteria to apply when choosing between and automation tool and manual coding in a minute
Let’s first look at benefits of automation in general and in particular for for XML conversion
Benefits of automation
Automation, or robotization, involves executing processes with minimal human intervention. To automate successfully, one must:
- Identify a consistent, recurring pattern in the process.
- Ensure the process is frequent enough to warrant automation.
- Have a well-understood, stable process that doesn’t require constant changes.
However, not all tasks are fit for automation, especially those requiring human expertise or judgement, e.g. modelling an enterprise data model. Benefits of automation include increased productivity, faster time-to-market, enhanced accuracy, and the alleviation of tedious tasks, allowing personnel to focus on more value-adding activities.
Please refer to my articles on the benefits of data warehouse automation and ETL automation for a more detailed discussion of these topics.
XML conversion is a use case that can be fully automated.
Web based XML converters
There are two types of tools that automatically convert XML. Tools you can find on the web. You upload an XML document and the tool returns the output as CSV. These tools are ok for casual use and very simple XML but have significant limitations.
- They only work with very simple XML. Most of these converters can’t even handle multiple branches in an XML
- They don’t handle XSDs
- They lack an SDK or API
The web based tools are not fit for purpose for enterprise use cases.
Generic versus specific XML converters
🎥 Flexter Online Demo – XML to CSV Conversion Made Simple
Wondering how to easily convert XML files to structured CSV/TSV without writing a single line of code? In this quick demo, I show you how Flexter Online, the free version of Flexter, automates the conversion of XML (even with complex structures) into ready-to-use CSV files.
✔️ 100% No-code
✔️ Supports XSD
✔️ Normalised output with lineage documentation
👉 Watch the Flexter Online walkthrough below to see it in action:
Custom XML converters exist for specific industry data standards. They have been built for a specific standard only and do not support any other XML schemas or industry data standards. They do not have full support for all XSD features and the XSD specification.

Automated versus manual XML conversion. What to do?
Should you use an automation tool for XML conversion or manually convert XML by writing code?
There are various dimensions to this question.
Complexity
If you are dealing with a complex XML / XSD based on an industry data standard I recommend to use an automated and tool based approach to convert your XML. Complexity of the XML is the single biggest indicator for using an automated approach.
Here are some criteria to determine the level of complexity of your XSD / XML
- Elements and Attributes:
- Count: The sheer number of elements and attributes can be a primary indicator.
- Depth: The depth of nested elements. Deeper nesting often implies more complex structures.
- XSD Types:
- Simple Types: These define restrictions on text and attribute values.
- Complex Types: These define the structure of XML elements and can be more challenging to interpret, especially if deeply nested or if they contain a mixture of attributes and child elements.
- Inheritance:
- The use of extension and restriction elements within XSD can introduce complexity. If the schema heavily uses inheritance, understanding it might require tracing types back to their base definitions.
- Namespaces: The number of namespaces used and the manner in which they are employed can introduce complexity. XML documents and schemas that make extensive use of multiple namespaces can be trickier to understand and process.
- Imports & Includes: Multiple XSDs interlinked via import or include statements can complicate understanding, as one would need to traverse multiple files.
Number of XML schemas
If you have multiple XML schemas I recommend investing in an XML converter even if the schemas are simple.
Available skills
Do you have skills on your engineering team to efficiently work with XML? If not you might be better off investing in an XML converter. In particular if some of the other criteria indicate use of an automated approach.
Size of XML files
Processing very large XML files is challenging without the right XML skills. This is probably the hardest
Volume of XML files
It is much quicker to run a pilot to determine if a tool can handle the XML data volumes in your organisation than to hand code the conversion process and find out after a few weeks that the implementation does not meet the SLA requirements and can’t handle large volumes of XML.
Company culture
Some companies have a strong engineering culture and prefer to build their own solutions instead of buying off the shelf applications.
JSON
Most XML converters also have support for JSON. If you also have JSON documents that need to be converted an XML converter might make sense
Conclusion
If your XML / XSD is complex, go for an automated solution using an enterprise XML converter.
If your XML / XSD is simple and you tick two or more of the following boxes, also opt for an automated approach.
- No XML skills on engineering team
- Large XML files
- Large number of XML files
- Large number of XML schemas
- JSON needs to be converted as well
- Company culture favours buy over build
For any other scenarios opt for a manual approach using coding.



