How to Insert XML into SQL Tables (2026 Guide)

XML is harmless right up until you try putting it into an SQL table.
Then the nesting shows up. The attributes show up. The inconsistencies show up.
And suddenly you’re staring at a file that needs twelve joins, three XPath tricks, and possibly a small prayer.
For simple XML conversions, if you’re looking for a quick-win:
Upload your XML (or XML + XSD) to Flexter Online (for FREE) and get clean SQL tables instantly.
There is also a step-by-step guide to help you avoid getting lost.
And I promise: No XPath or SQL/XML. No manual flattening. No surprises.
Just your XML in SQL in seconds.
But if you’re dealing with larger workloads, complex nested structures, or you want to understand the SQL/XML, schema-on-read, and schema-on-write approaches behind the scenes, this guide breaks them all down step by step. And I have also covered an Automated solution for complex and nested XML to SQL conversion requirements.
Here’s what I’ll cover:
- XML to SQL: Foundational concepts,
- XML Data Types and Storage,
- How to load XML into SQL with Schema-on-read (flexible, but manual),
- How to convert XML into SQL tables with Schema-on-Write (Structured, SQL-friendly):
- Using SQL-native tools like SQL/XML for XML handling,
- When Python works (and when it becomes a maintenance nightmare),
- How ETL tools and XSLT fit into the process,
- The fastest, most scalable option: automated converters.
- I’ll also provide you with a comparison table so that you can easily compare options and decide what’s best for your XML to SQL project.
And just to be clear: this post is all about transforming XML data into a relational SQL format (and not the other way around).
Let’s jump in.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Core Concepts You Need Before Converting Complex and Nested XML
Before diving headfirst into XML conversion and SQL statements, let’s take a breath.
XML might appear to be just another data format, but underneath those angle brackets lies a very different beast from typical tabular data with rows and columns.
Understanding of a few core concepts can make or break your workflow. Get hold of them now, and you’ll save hours of debugging and frustration later.
Regardless of whether you’re looking to convert from XML to SQL, XML to a database, or XML to a table, your conversion is underpinned by a shared goal: converting XML and its native hierarchical structure into a tabular or relational format for easier querying, data analysis and integration with other data in relational format.
But the terminology can be confusing, so let’s clear up a few common misconceptions right away:
- XML to SQL involves transforming XML into a relational database while preserving its original structure (i.e., similar to schema-on-read), allowing the data to be queried later using SQL/XML.
SQL/XML, by the way, is a set of ISO-standard SQL extensions that allow querying and generating XML data using familiar SQL syntax.
Heads up: Some tools claiming to convert XML to SQL simply generate raw INSERT INTO statements from XML. Technically, that counts.. but this approach is rarely practical and suffers from significant performance limitations.
- The term XML to database is broader and usually covers converting and normalising XML into multiple tables within a database before actually writing the data to the database (i.e., closer to schema-on-write). I cover this topic in both the current post and a separate one (in more detail).
- XML to table typically refers to converting XML into a table within a database (e.g., Snowflake) by flattening its hierarchical structure into a tabular format.
It can also mean converting XML to formats like CSV, TSV, or Excel.
Conceptually, this is closer to a schema-on-write approach, as it involves defining table structures rather than querying raw XML directly. Tabular data and, thus, generic XML to table conversion have several use cases nowadays.
In short: the same XML source can land in your database through very different paths.
How you choose to convert, structure, and query your data depends on several factors, which I’ll break down in the next sections.
Pro tip
If you don’t want to wrestle with nested XML (or XML at all), let Flexter Online do it for you.
Just drag and drop your XML (or XML + XSD) to generate SQL tables instantly.
I promise you, you won’t touch any XPath or craft mappings by hand.
It’s just faster, cleaner, stress-free.
Why convert XML to SQL?
XML is great at storing and exchanging data, but not so great when you want to query it, join it, or do data analysis (make sense of it at scale).
That’s where SQL comes in.
Relational databases power the core of several modern applications, from data analytics (OLAP) and machine learning to transactional systems (OLTP).
SQL makes your data accessible, fast, and ready for business logic, something raw XML simply wasn’t designed for.
I’ve written in detail why you would bother converting XML to a database, whether that is an OLAP or OLTP database, elsewhere in this blog.
I would suggest taking a look there as well, before continuing here.
Use Cases for inserting XML into SQL
Now that you know why converting XML to SQL makes sense, let’s talk about when it’s actually useful.
Not every XML file needs to land in an SQL database.
But when it does, it’s usually one of these two scenarios:
XML to SQL for Data Warehouse / Data Lake / Data Lakehouse
XML is a frequent source format in data warehousing projects, especially when data is coming from third-party APIs, flat files, or legacy exports.
Before that data can be aggregated, analysed, or visualised, it needs structure.
By converting XML into normalised SQL tables, you make it warehouse-ready, fit for BI dashboards, and complex joins.
XML to SQL for Enterprise Application Integration
In large enterprise environments, XML is everywhere: passed between CRMs, ERPs, finance systems, and supply chains. But raw XML doesn’t play well with downstream applications.
Instead of every system parsing XML on its own, you can convert XML to SQL and centralise the data in a relational format that other apps can query directly.
Pro Tip
Setting up a cloud warehouse or data lake and looking to store your XML in it?
If yes, then depending on the platform that you intend to use, you should check out my detailed guides on:
- How to convert XML into a clean, queryable format in Redshift,
- How to Parse XML in Spark and Databricks (Guide),
- Ultimate Guide to Parsing XML to Google BigQuery (2026),
- How to Parse & Flatten XML in Snowflake with Examples.
Fewer bottlenecks. Better queries. Less maintenance & smaller bills.
What makes Nested XML to SQL so Hard?
Nested XML is difficult to convert because its hierarchical structure doesn’t align with SQL’s flat, relational model.
Deep nesting, repeating groups, and mixed content create branches that don’t map cleanly to rows and columns, requiring extra tables, joins, and normalisation.
The problem gets worse when real-world XML isn’t consistent. Elements appear or disappear across files, breaking XPath, SQL/XML queries, and ETL mappings.
Even with a stable structure, nested XML often requires long, fragile XPath or CROSS APPLY logic where small path errors silently produce empty or duplicate results.
These issues make manual approaches to nested XML to SQL conversion far more complex than expected.
Pro tip
Building your own manual workflow for inserting XML into SQL almost always turns into a bigger project than expected, especially if you’re new to XML.
Deep hierarchies, branching structures, and constantly shifting schemas can turn SQL/XML, XSLT, or ETL-based solutions into a maze of fragile logic.
A far simpler and more reliable option is to use a tool purpose-built for automated XML to SQL conversion.
That’s where Flexter comes in, giving you clean, ready-to-query SQL tables without the heavy lifting, and freeing your time for work that actually moves your project forward.
XML as a Database
Modern databases offer varying degrees of XML support. Some treat it natively, and others… well, let’s say that they just tolerate it.
Understanding the different options for working with XML in a database is key when deciding how to insert or query your XML data in SQL.
XML-enabled databases
These are your traditional relational databases, like SQL Server, Oracle, or PostgreSQL, that have incorporated XML-handling capabilities while still relying on a fundamentally relational model.
Modern cloud platforms, such as Snowflake and Databricks (version 14.3 and later), also offer native XML support, enabling XML data to be ingested, parsed, and queried alongside structured and semi-structured data.
There are two common ways XML is handled in this context:
- Storing as a LOB (Large Object):
The entire XML document is stored in a single field, often as a CLOB, TEXT, or vendor-specific type such as XMLTYPE or XML.
This approach preserves the XML structure but can be inefficient for querying, especially with nested or large documents.
- Shredding XML into Tables:
When you map XML into relational tables, you get fast, SQL-friendly queries. But you’ll often need an upfront schema, and some of the original structure might get lost.
XML-enabled databases are a solid choice when you’re working with both relational and semi-structured XML data and want everything managed inside a single system.
Native XML Databases
These systems, like eXist-db or BaseX, are purpose-built to store and query XML natively.
Usually, databases with native XML handling capabilities:
- Support XQuery and XPath natively.
- Offer indexing, validation (with XSD), and full document storage.
- They’re suitable for use cases like content management and document archiving.
That said, native XML databases aren’t relational, and usually don’t support SQL out of the box, so they’re less useful in typical transactional or BI-heavy environments.
SQL/XML Standard vs. Proprietary Tools
If you want to work with XML in an SQL database, then you need a toolbox to store, query, and manipulate XML data.
One such option is the SQL/XML standard.
In the bigger picture, you can view SQL/XML as SQL for XML.
In technical terms, SQL/XML is a standard that defines how relational databases should work with XML using SQL syntax. It includes functions like:
- XMLQUERY() – run embedded XQuery inside SQL
- XMLTABLE() – project XML nodes into rows and columns
- XMLEXISTS() – check for specific XML paths
- XMLNAMESPACES – manage namespace contexts in queries
These features are supported to varying degrees by major databases, such as Oracle, DB2, and SQL Server, and are preferred when portability across platforms is desired.
On the other hand, you should also know that many vendors offer proprietary alternatives. For example:
- SQL Server offers OPENXML, .nodes(), .query(), .value(), and,
- Oracle offers EXTRACTVALUE and XMLTYPE methods.
These proprietary options are considered legacy nowadays, but may still be supported for backwards compatibility. In any case, I would not recommend them for new projects.
And while they offer useful functionality with some strong capabilities, they come with the trade-off of vendor lock-in.
Pro tip: Do these concepts already sound alienating?
If these concepts already feel overwhelming, skip the manual battle entirely. Flexter handles the heavy lifting for you.
The free online version of Flexter automatically processes hierarchies, attributes, repeated elements, and branching logic, then delivers clean SQL tables you can use immediately for analytics or loading into your warehouse.
And to make everything effortless, there’s a step-by-step guide that walks you through the process.
It really is that simple.
How can XQuery be used inside a database?
An alternative to SQL/XML is XQuery, which can be used as a powerful tool to manipulate XML data directly in native XML databases.
Unlike SQL/XML, which integrates XML querying into relational systems, native XML databases, such as BaseX, eXist-db, or MarkLogic, allow you to run pure XQuery expressions without any SQL wrapper.
Think of XQuery as your XML scalpel: precise, expressive, and ideal for slicing through complex, nested XML documents with ease.
In relational databases, only Oracle, DB2, and SQL Server offer XQuery support, although it is embedded within SQL through functions such as XMLQUERY() or XMLTABLE().
SQL/XML vs. XQuery: When to choose which option?
To get straight to the point:
- SQL/XML is SQL extended to work with XML (SQL for XML). It’s great when your main data model is relational, but you occasionally need to store or query XML fields.
- XQuery is a standalone XML-native query language. It is ideal when XML is the primary format, and the structure is complex or deeply nested.
Use SQL/XML when you’re in a relational environment that sometimes handles XML. Use XQuery when XML is at the centre of your data model or application.
If you prefer having key information neatly organised in one place, here’s a quick comparison table breaking down XMLQUERY (SQL/XML’s standard function for embedding XQuery) vs. raw XQuery itself.
|
XMLQUERY versus XQuery | |||
|---|---|---|---|
|
Feature |
Part of XQuery Standard? |
Part of SQL/XML Standard? |
Description |
|
XQuery |
✅ Yes (W3C Standard) |
❌ No |
A standalone language for querying and transforming XML. |
|
XMLQUERY() |
❌ No |
✅ Yes |
A SQL function that executes XQuery from within a SQL query. |
If you want to take a look at an example of how this works, here’s the same logic written in both SQL/XML using XMLQUERY, and pure XQuery.
SQL/XML Example (using XMLQUERY inside Oracle):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
VAR myxml CLOB; BEGIN :myxml := '<employees> <employee><name>John</name><salary>7000</salary></employee> <employee><name>Jane</name><salary>4500</salary></employee> </employees>'; END; / SELECT XMLQUERY( 'for $e in /employees/employee where $e/salary > 5000 return $e/name' PASSING XMLTYPE(:myxml) RETURNING CONTENT ) AS result FROM dual; |
Pure XQuery Example:
|
1 2 3 4 5 |
let $doc := doc("employees.xml") return for $e in $doc/employees/employee where xs:decimal($e/salary) > 5000 return $e/name |
The role of XSD (validation and schema generation)
Before we go any deeper, there’s one last foundational concept you need to know: the role of XSD in an XML to SQL conversion.
XML Schema Definition, or XSD in short, does more than keep your XML clean: it acts both as a gatekeeper and a blueprint in the process.
This means that you can use your XSD for:
- Validation: XSD enforces structure: elements, types, order, and cardinality. When linked to your database (e.g. via schema collections in SQL Server), it blocks malformed or non-compliant XML before it touches your tables.
- Schema Generation: Automated tools can read the XSD and auto-generate SQL schemas, complete with columns, constraints, and relationships, based on the XML’s hierarchy. No more reverse-engineering XML by hand.
Your XSD is your source of truth. It validates what’s coming in and shapes the SQL model you build around it.
Got an XSD, or able to create one? Then put it to work!
Automated schema generation is one of those must-have features that saves hours of manual work, and even more in future maintenance and debugging.
Instead of reverse-engineering XML by hand, use an automated tool that can turn your XSD into clean, relational SQL tables in minutes.
Less guesswork, fewer headaches.
There is also a guide that walks you through the process step by step.
XML Data Type and Storage
Once you’ve wrapped your head around how XML fits into relational databases, the next step is understanding how to load and store XML inside your SQL tables properly.
This unlocks everything from querying with SQL/XML to integrating XML with your existing data.
What Does It Mean to Load XML to a Database?
Loading XML means bringing XML content, whether from files, APIs, exports, or third-party systems, into your database environment.
To achieve that, you will usually need to make use of the native XML data types that are offered by some database systems.
Most platforms rely on proprietary tools to handle the initial load, like:
- COPY INTO for Snowflake,
- SQL*Loader for Oracle,
- BULK INSERT or OPENROWSET for SQL Server.
These tools handle the raw movement of your XML content into the database, making it ready for storage or further processing.
What Does It Mean to Store XML in a Database?
Once loaded, storing XML means writing that XML content into a column inside your tables.
Depending on your database, this could involve:
- A dedicated XML data type for structured storage (e.g., XML, XMLTYPE, or Snowflake’s VARIANT),
- Or, storing the XML content as plain text inside a VARCHAR (in Redshift) or CLOB column (in Oracle).
Keep in mind that while the second option technically works, practically, it’s like stuffing your XML into a storage closet and locking the door.
You’ll lose structural awareness of your data, and your database’s performance will suffer; querying will turn into a frustrating game of string manipulation.
Pro tip
Once your XML data is stored inside the database, you have two options for further processing: schema-on-read and schema-on-write.
- For schema-on-read, the XML data must already reside inside the database; only then can you apply structure when querying with SQL/XML functions or proprietary tools.
- With schema-on-write, storing the XML in the database is optional. You can transform or flatten the XML outside the database using tools like Flexter, XSLT, or custom pipelines, then insert structured, ready-to-query data directly into relational tables.
In the next sections, we’ll unpack both approaches, compare their strengths, and help you choose the right fit for your project.
Why Would You Want to Store XML in a Database?
The primary reason for loading and storing XML in your database is to leverage the SQL/XML standard (which I described a bit earlier in this post).
By storing XML in your database and using SQL/XML:
- You centralise structured and semi-structured data,
- You unlock native functions for working with XML data,
- You preserve original XML data for compliance, audits, or downstream processes,
- You can combine XML content with relational queries for hybrid use cases.
If your platform supports a proper SQL XML type, this gives you a powerful, portable way to manage XML alongside your relational data.
Examples of Loading and Storing XML by Platform
SQL Server
Loading XML:
You can load XML from a file using OPENROWSET with BULK, combined with SINGLE_CLOB for character data, and insert it into an XML column:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE Orders ( OrderID INT PRIMARY KEY, OrderData XML ); INSERT INTO Orders (OrderID, OrderData) SELECT 1, CAST(BulkColumn AS XML) FROM OPENROWSET(BULK 'C:\Path\To\File.xml', SINGLE_CLOB) AS X; |
Store XML:
SQL Server offers a native XML data type for structured XML storage:
|
1 2 3 4 |
CREATE TABLE Orders ( OrderID INT PRIMARY KEY, OrderData XML ); |
Oracle
Loading XML:
Use SQL*Loader for bulk loading:
|
1 2 3 4 5 6 7 8 |
LOAD DATA INFILE 'data.txt' INTO TABLE Customers FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' ( CustomerID, CustomerXML CHAR(1000000) ) |
Where “data.txt” can have the following content:
|
1 |
1,"<customer><name>John</name></customer>" |
And to run SQL*Loader, you would need to run the command:
|
1 |
sqlldr userid=username/password control=load.ctl |
Store XML:
Oracle provides XMLTYPE, a robust native xml data type:
|
1 2 3 4 |
CREATE TABLE Customers ( CustomerID NUMBER PRIMARY KEY, CustomerXML XMLTYPE ); |
Snowflake
Loading XML:
Snowflake uses COPY INTO to load XML files as plain text:
|
1 2 3 |
COPY INTO Events FROM @mystage/event_data.xml FILE_FORMAT = (TYPE = CSV); |
Store XML:
Snowflake lacks a dedicated SQL XML type, but XML can be stored as VARIANT, which supports semi-structured data:
|
1 2 3 4 |
CREATE TABLE Events ( EventID INT, EventXML VARIANT ); |
Working with XML in Snowflake is supported through native functions like PARSE_XML and XMLGET, but these tools do not comply with the SQL/XML standard, which can limit portability and advanced XML operations.
Pro tip
If your database supports native XML types, like SQL Server’s XML, Oracle’s XMLTYPE, or PostgreSQL’s XML, you unlock powerful SQL/XML querying, validation, and manipulation routines directly within SQL.
Without that, XML is just text inside a database.
Platforms such as Redshift (only VARCHAR/SUPER) and MySQL (stores in TEXT/CLOB) lack native XML types, so XML becomes a second‑class citizen in those systems.
Especially in those cases, seriously consider an XML to database converter (like Flexter) to avoid being buried in string-handling traps.
Querying and Data Manipulation in SQL (Schema on Read)
Let’s be honest: storing XML in your database is only half the battle. The real fun (or frustration) starts when you actually need to query and work with that data.
Enter: Schema-on-Read.
This approach lets you bring XML data into your database without locking it into a rigid structure upfront.
Think of it as the “don’t stress now, we’ll sort it out later” strategy.
What is the idea behind Schema-on-Read?
The answer is very simple: flexibility.
Instead of forcing your data to fit a strict model at the moment of loading, Schema-on-Read lets you apply structure only when you access or analyse the data.
This makes it ideal for working with semi-structured or unpredictable sources, such as XML or JSON, where the structure can vary or evolve.
Where does Schema-on-Read come from?
Schema-on-Read emerged from big data environments and data lakes, places like Hadoop and S3, where raw data is ingested first, and structure gets applied “on-demand”.
The concept has since made its way into relational systems that handle semi-structured formats, especially heavyweight databases like Oracle, SQL Server, or Snowflake, which offer specialised types like XML in SQL Server or XMLTYPE in Oracle.
Pro Tip
Who’s the classic counterpart of Schema-on-Read? You guessed it: Schema-on-Write.
No drama, just two different approaches for taming your XML.
With Schema-on-Read, you load your XML as-is and only apply structure at query time.
It’s flexible and perfect for data profiling or ad hoc queries to explore and understand your XML before deciding how to structure it for long-term storage.
Schema-on-Write, on the other hand, means you apply structure before querying, but here’s the nuance: that structure doesn’t always have to be defined before loading the data.
You can load your XML first, then flatten or normalise it inside the database using SQL, XML functions, or tools like Flexter.
When we say “structure” here, we’re talking about more than just tables; we mean a well-defined data model, including table Data Definition Language (DDL), relationships, constraints, and optimised mappings that transform hierarchical XML into relational format.
Quick rule of thumb:
- Need to explore your data or run quick queries? Schema-on-Read is ideal.
- Need performance, consistent results, and clean, relational tables for long-term use? Schema-on-Write (whether applied before or after loading) is your go-to.
We’ll dive deeper into Schema-on-Write and how to use it effectively in the next section.
Steps for a Schema-On-Read approach
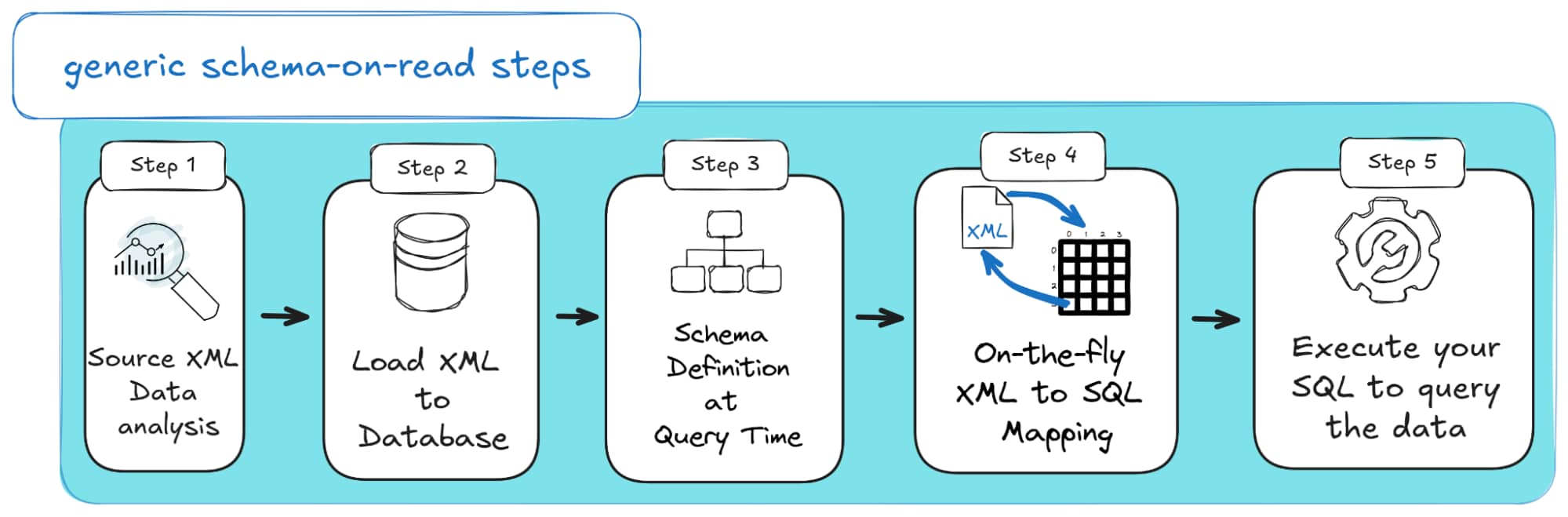
Here’s how a typical schema-on-read workflow looks when dealing with XML:
- [Step 1] Source XML Data analysis: First, get familiar with your XML. Understand the structure, tags, and what info you need to extract.
- [Step 2] Load XML to Database: You import XML into SQL without worrying about its structure yet. It sits there in an XML data type, text field, or binary blob.
- [Step 3] Schema Definition at Query Time: After you import XML to SQL Server, there will come a time when you actually need to run a query. At that time, you can decide what structure matters to you and your project and apply it. You can target specific tags, attributes, or elements on the fly.
- [Step 4] Data mapping on the fly: You dynamically map XML elements to columns as part of your query logic; no rigid, predefined schema needed upfront.
- [Step 5] Execute your SQL statements to query the data: Use SQL extensions like SQL / XML to slice, dice, and pull data from the XML (that lives inside your database).
If you’re more of a visual learner, here’s a quick diagram to illustrate the concept:
A Practical Example for Schema-on-Read
Inserting XML into an SQL Table (SQL Server)
You’ll first need to run the following SQL statement:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
CREATE TABLE [dbo].[University_Details]( [Id] [int] NULL, [University_Data] [xml] NULL ) INSERT INTO [dbo].[University_Details] (Id, University_Data) VALUES (1, ' <University id="TUD"> <Faculty id="Engineering"> <Department id="ComputerScience"> <Course>Introduction to Programming</Course> <Course>Algorithms and Data Structures</Course> </Department> <Department id="ElectricalEngineering"> <Course>Circuit Analysis</Course> <Course>Electromagnetics</Course> <Course>Control Systems</Course> </Department> </Faculty> </University> ') |
Here, we create a table with the xml data type for the University_Data column. This allows us to store the full, original XML document while preserving all its lovely nested structure.
This is how it looks inside your database. A table with one row and XML as text.

Querying the XML
Now comes the cool part: extracting data using SQL extensions designed for XML:
|
1 |
SELECT @xml.value('(/University/@id)[1]', 'nvarchar(max)') AS UniversityID; |
This query reaches into the XML and retrieves the university ID using SQL Server’s XML functions.
To make it work, I had to write an XPath expression directly inside the SQL statement to target the exact element I wanted.
Sure, mixing SQL and XPath for XML can get tedious fast, but there’s a workaround.
You can wrap these queries inside a reusable database view, making the XML look like a clean, relational schema to anyone querying the view.
It’s a classic schema-on-read trick: you hide the XML complexity behind views and keep things SQL-friendly.
And the nice part? From there, it’s a small step to transition to schema-on-write with actual physical tables, which will give you better performance and fewer headaches down the road!
Pro tip
Did this practical example look alienating and hard? You don’t need to wrestle with any of it.
Flexter handles the entire XML to SQL process for you. Online and automated, just by using your browser, in a few minutes.
Just upload your XML (or XML + XSD), and it automatically flattens hierarchies, resolves branching, and outputs clean SQL tables you can use straight away.
No XPath, no mapping, no guesswork; just instant results.
Data Transformation and Conversion (Schema on Write)
We’ve covered how Schema-on-Read lets you delay structure decisions until query time.
But what if flexibility isn’t your top priority? What if you need fast queries, consistent results, and clean relational tables from day one?
That’s where Schema-on-Write comes in.
With Schema-on-Write, you can define structure early (or generate it automatically) and convert hierarchical XML into normalised, SQL-friendly tables, ready for querying and downstream integration.
What is the idea behind Schema-on-Write?
The core idea is simple: apply structure before you need to query the data.
That structure entails a well-defined data model, comprising table DDL, relationships, constraints, and mappings that transform your XML into a relational format.
It reduces complexity, boosts query performance, and ensures your data is consistent and easier to maintain, especially for long-term projects or high-volume environments.
Steps for a Schema-On-Write approach
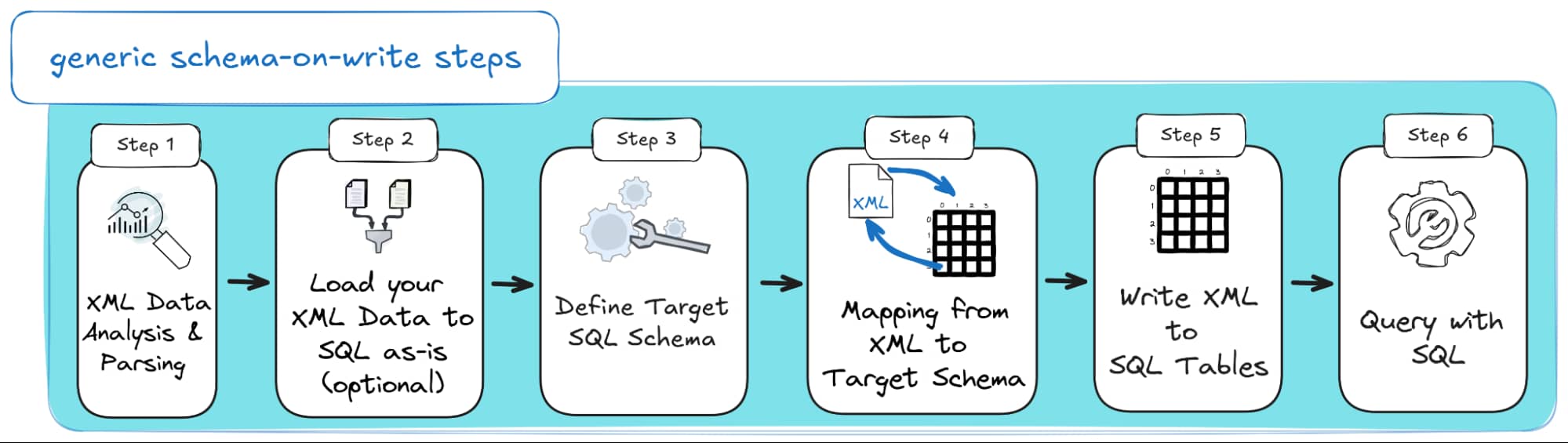
Here’s how a typical Schema-on-Write workflow looks when converting XML into a relational SQL format:
- [Step 1] XML Data Analysis & Parsing: Start by analysing your XML structure, tags, relationships, and any constraints.
If available, use an XSD to accelerate the process and reduce manual guesswork.
Parsing your XML at this stage ensures you fully understand how to reshape it into a relational format.
- [Step 2] Load your XML Data to SQL as-is (Optional): You can load your raw XML directly into the database, storing it in an XML column, text field, or blob.
Some teams prefer this to stage the data before transforming it; others skip this step entirely and transform the XML outside the database.
- [Step 3] Define Target SQL Schema: Design your database schema based on the XML analysis.
This includes table structures, data types, relationships, constraints, and keys.
In Step 3, you can create the schema manually (if you enjoy manual coding) or let tools like Flexter handle it using your XSD, a sample of your XML files, or both for extra precision. Here’s how it works.
- [Step 4] Data Mapping from XML to Target Schema: Map XML elements and attributes to the appropriate tables and columns in your target schema.
Whether flattening or normalising, this ensures your hierarchical XML converts cleanly into a relational structure.
- [Step 5] Write XML to SQL Tables: Insert the transformed, structured data into your relational tables.
You can perform the transformation outside the database and load only clean data, or transform and write in stages if you opted to store the XML raw in Step 2.
- [Step 6] Query with SQL: Once your XML is converted and written to SQL tables, you can query the data using standard SQL; no XPath, XQuery, or complex parsing required.
The structure is already applied, making querying efficient and easy to maintain.
And if you’re a visual learner, here’s a diagram with the steps for Schema-on-Write:
Now, keep these steps in mind, and keep on reading the next few subsections, where I’ll explore and show you how to apply Schema-on-Write for XML using various options:
Native XML to SQL with SQL/XML
Let’s kick things off with one of the most native ways to perform Schema-on-Write inside your database, using SQL/XML.
If your database supports the SQL/XML standard, you don’t need to rely on complex pipelines to apply structure to your XML.
Instead, you can use built-in functions to extract, map, and insert XML data into relational tables as part of your SQL workflows.
If you’ve actually followed my previous practical example for Schema-on-Read, then you’re already halfway there.
We’ll use the same starting point: load your raw XML into the database. But this time, we’ll apply Schema-on-Write to flatten the XML and store it in clean SQL tables.
A Practical Example of Schema-on-Write with SQL/XML
The first two steps for this example are very similar to the Schema-on-Read example.
We’ll load raw XML into the database, then apply structure using SQL/XML.
Step 1: Create a Table to Store Raw XML
|
1 2 3 4 |
CREATE TABLE Raw_XML_Store ( Id INT PRIMARY KEY, XMLData XML ); |
Step 2: Insert Raw XML into the Table
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
INSERT INTO Raw_XML_Store (Id, XMLData) VALUES (1, ' <Company id="C001"> <Department> <Name>IT</Name> <Employee> <Name>John</Name> <Salary>7000</Salary> </Employee> <Employee> <Name>Jane</Name> <Salary>4500</Salary> </Employee> </Department> </Company> '); |
And now comes the difference compared to Schema-on-Read: instead of querying the raw XML repeatedly with XPath, we convert the data into a proper relational schema, applying structure upfront so that everything is SQL-friendly and ready for fast queries.
Step 3: First, create the SQL Table to include your flattened data
|
1 2 3 4 5 6 |
CREATE TABLE Company_Flat ( CompanyID NVARCHAR(50), Department NVARCHAR(50), EmployeeName NVARCHAR(100), Salary INT ); |
Step 4: Apply Schema-on-Write to Flatten the XML
The following SQL query transforms the hierarchical XML to tabular format, making your data ready for querying:
|
1 2 3 4 5 6 7 8 9 |
INSERT INTO Company_Flat (CompanyID, Department, EmployeeName, Salary) SELECT XMLData.value('(/Company/@id)[1]', 'NVARCHAR(50)') AS CompanyID, D.Dept.value('(Name)[1]', 'NVARCHAR(50)') AS Department, E.Emp.value('(Name)[1]', 'NVARCHAR(100)') AS EmployeeName, E.Emp.value('(Salary)[1]', 'INT') AS Salary FROM Raw_XML_Store CROSS APPLY XMLData.nodes('/Company/Department') AS D(Dept) CROSS APPLY D.Dept.nodes('Employee') AS E(Emp); |
No more XML parsing is needed at query time; the structure is already applied and ready for you or your users to query.
Step 5: Query the Flattened Table
|
1 |
SELECT * FROM Company_Flat; |
The expected output should be:
|
CompanyID |
Department |
EmployeeName |
Salary |
|---|---|---|---|
|
C001 |
IT |
John |
7000 |
|
C001 |
IT |
Jane |
4500 |
Although this may look easy for the small XML test case I’ve shown you here, what happens if you need to convert a nested XML with multiple branches?
I’ll give you a hint: It’ll require a lot of manual work to get your SQL statements and XPaths correct until you actually flatten your XML in an SQL table.
And don’t even think about normalised schemas.
Pro tip
If you’re stuck between “hack together a script” and “build a full ETL job,” choose neither.
Flexter Online converts XML to SQL tables in a few clicks, making it perfect for quick tests, prototypes, or validating complex data before production.
Schema-on-Write with Python
If you’re anything like me, you’ve probably reached for Python when dealing with XML to SQL conversion.
Libraries like ElementTree or lxml make it tempting to dive right in and start parsing.
And for quick wins or smaller XML files, that’s perfectly fine.
You can parse the XML, pull out what you need, maybe even flatten some structures manually, and push the data into your database or data pipeline.
But let’s be real: once your XML gets deeply nested, filled with mixed content or you’re dealing with industry-standard XML (hello, XSDs), the cracks start to show.
Here’s what “manual” with Python really means:
- Write manual code to parse the XML,
- You map elements to SQL tables (by hand),
- You handle weird nesting or edge cases (let’s hope you won’t resort to regex),
- You build the SQL inserts or load files yourself.
If you want to roll up your sleeves, I’ll walk you through exactly how to do this in my guide:
That approach might work for small XML files or one-off jobs, but for bigger projects, I wouldn’t be so sure. Unless you’ve got a team of XML conversion specialists on standby.
Once your XML grows in size or complexity, relying on pure Python becomes a time sink. Full stop.
Stick with me in the next sections, and I’ll show you how to handle Schema-on-Write the smarter way, with automated tools that save you time, hassle, and countless lines of code.
How to insert XML to SQL with ETL (And Where Automation Fits In)
ETL (Extract, Transform, Load) tools such as Talend, Informatica, or SSIS offer a way to manage Schema-on-Write for XML to SQL.
The process is simple (in principle):
- Extract your XML from files or APIs,
- Transform it by flattening or normalising the structure,
- Load relational data into the SQL tables of your target database.
In practice? Deeply nested XML with complex branching and mixed content often turn that process into manual mapping, schema headaches, and maintenance overhead.
That’s why many teams pair their ETL with a specialised automated XML to database solution that handles:
- Complex parsing,
- Schema discovery and optimisation,
- Evolving Schemas,
- Auto-generated documentation along with several other important automation features.
- Your ETL is the detailed road atlas and a car: You have the information and means to plan a route and travel absolutely anywhere (handle any ETL task).
- The specialised automated solution is the route-planning software, built to optimise complex, multi-stop deliveries of your XML with minimal effort.
So, in summary: For simple XML, your ETL might be enough. For complex structures, you need automation to do the heavy lifting. It will be faster, smarter, and… with fewer detours.
If you’d rather skip the details and jump straight to the step-by-step guide for using the automated solution, click here.
Pro tip
Working with an unfamiliar XML source? Run it through Flexter Online first.
You’ll immediately see your converted data in a relational SQL structure.
This will help you discover any hidden complexities and avoid hours of trial-and-error with SQL/XML or custom scripts.
How does XSLT fit into XML to SQL conversion?
XSLT lets you transform XML into SQL-friendly formats using rule-based stylesheets.
It’s a solid choice when you need precise control over how XML gets flattened before reaching your database.
But XSLT doesn’t move the data. You’ll still need additional tools or scripts to insert the transformed output into SQL tables.
For small XML jobs or one-off conversions, XSLT works. But for large, evolving XML or complex data pipelines, it quickly becomes impractical.
Converting XML to SQL with XSLT is unlikely to suit your project. If you’re after a fully automated way to convert XML to SQL without the manual headaches, I’ll show you exactly how that works next.
Skip the Manual Work: Automated XML and Nested XML Conversion to SQL
I promised you an automated solution. And now it’s time to show you what I meant by that.
If you’ve made it this far, you already understand that manually converting XML to SQL tables is tedious, error-prone, and hard to scale. But it doesn’t have to be.
Flexter Enterprise is built for exactly this challenge: converting complex XML into clean SQL tables “automa-gically”.
No coding, no XPath struggles with SQL/XML, no manual reverse-engineering of schemas.
Whether you’re dealing with a single XML file or processing enterprise-scale datasets, Flexter handles the entire conversion process and gets your data into a ready-to-query SQL format.
Sounds like the shortcut you’ve been looking for? Let me show you how it works.
Getting hands-on with automated XML conversion
You’ll be surprised to find out that this process consists of only two steps. “Automa-gically”, as I like to say (because yes, it looks like magic, but under the hood, it’s just rock-solid engineering).
Step 1: Create Data Flow
In the first step, we create a Data Flow from one of the following:
- An XSD: Flexter has full support for the XSD specification and can work with any type of XSD,
- A sample of your XML files,
- An XSD and a sample of your XML files. This third option will give you the best results.
Once set, this data flow generates the logical target schema and the corresponding XML to SQL mappings. This information is then stored in the Flexter MetaDB for future conversions.
Data Flow creation is a one-off process. It is only repeated to evolve the schema if something changes (e.g., the location of the source XML files).
Pro tip
Flexter doesn’t just work with XML. It handles CSV, TSV, PSV, and JSON as source formats.
The 2-step process stays the same: Flexter analyses your source files, generates a clean relational schema, builds the source-to-target mappings, and produces full documentation.
All “automa-gically” (I promise it’s the last time I say it 😅).
You can convert a single file or scale up to process millions, whether you’re writing to Oracle, SQL Server, PostgreSQL, Snowflake, BigQuery, or any other supported database.
You may find the full Flexter Capability Sheet here.
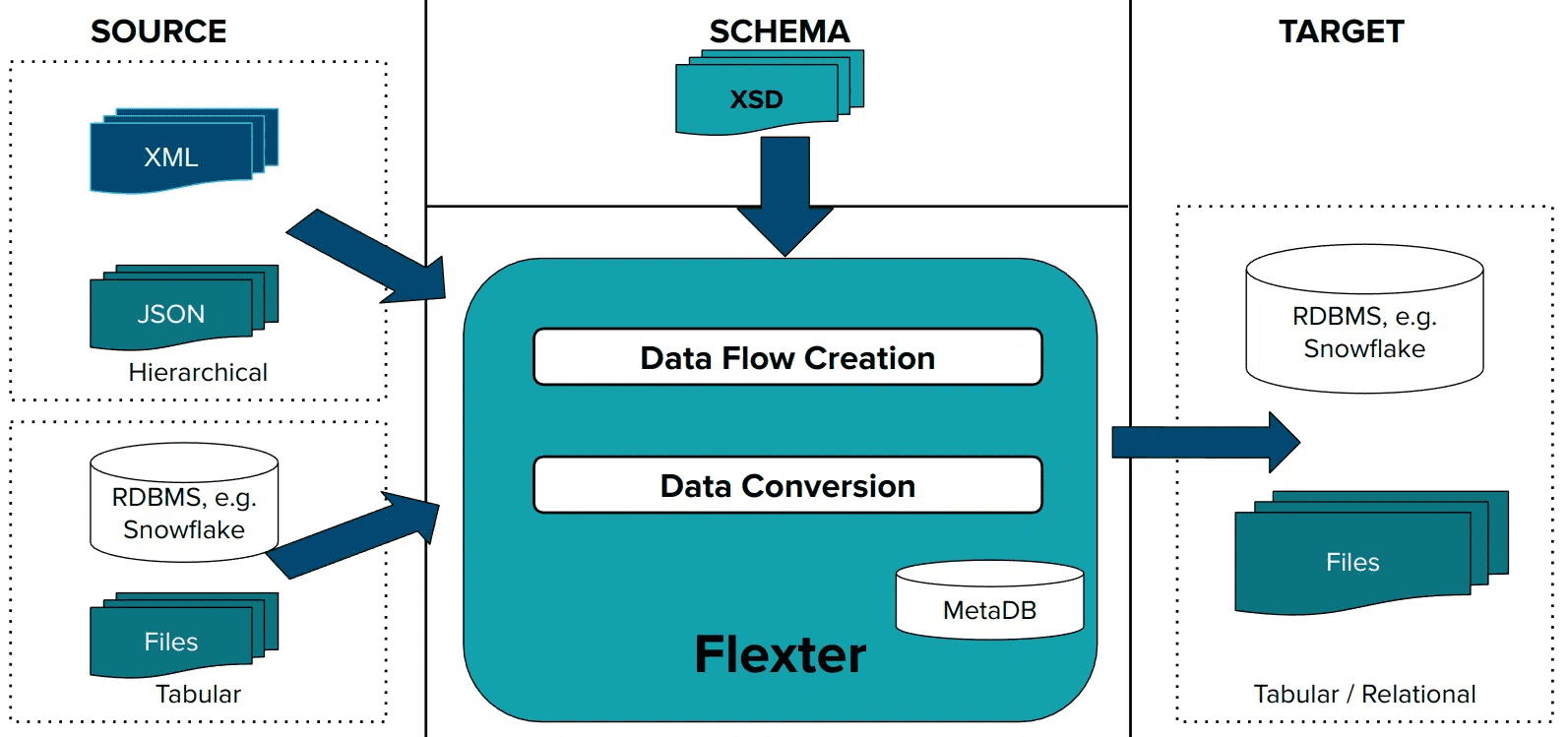
Step 2: Convert your XML to SQL
In the second step, Flexter converts XML to a relational database, such as Oracle, SQL Server, Snowflake, or any other supported database or file-based format.
As part of the conversion process, Flexter monitors any incoming XML for schema changes or unexpected XPaths, writes warnings to the error log and sends alerts.
This is how it looks:
We have created a video to show the XML conversion process to SQL tables in Snowflake. We use FpML as an XML source.
FpML is an industry data standard in finance. It is one of the most complex XML schemas. The XML and XSD may generate thousands of tables depending on which part of the FpML standard you convert.
The principles are the same for any other supported target or any industry data standard other than FpML.
Want to See Schema-on-Write Live in Action?
What if you could skip all the technical jargon and watch it unfold on your screen right now?
With Flexter Online, your XML transforms into clean Snowflake tables in minutes. No code. No setup. No headaches.
And if you find it hard to navigate (though I doubt you will), check out our step-by-step guide!
How to Choose the Best Method for Converting XML (and Nested XML) to SQL
On paper, inserting XML into SQL sounds easy until your XML actually shows up.
First, you try SQL-native methods like SQL/XML, and suddenly, your query looks like a tangled mess of XPath expressions (even for very simple XML test cases).
Next, you reach for Python: perfect for small XML files (and if you’re in the mood for debugging your afternoon away).
But introduce deep nesting, mixed content, or a constantly evolving XSD?
That “quick script” quietly transforms into your weekend disappearing act… followed by Monday’s regret and a backlog of broken data.
Next, you may rely on your ETL tool, only to spend days manually mapping XML branches, fixing schema mismatches, and rewriting pipelines every time the XML changes.
And XSLT? It may work for small conversions, but maintaining rule-based transformations for real-world XML? That’s a full-time job in itself.
It’s highly unlikely that any of these approaches will work for you for enterprise-scale projects.
The only one that may come close to working is an ETL tool. However, there are several disadvantages compared to a dedicated and automated XML to SQL solution.
Here’s a comparison table to simplify things:
|
Feature |
Generic ETL Tools (e.g. Talend, Informatica, SSIS) |
Flexter Enterprise |
|---|---|---|
|
No-Code XML to SQL Conversion |
Partial (requires manual schema mapping and logic). |
Fully automated, no manual mapping required. |
|
Handles Deeply Nested XML |
Limited, requires manual workarounds. We have seen tools crash with very complex industry data standards |
Yes. Built to handle deeply nested XML natively |
|
Supports XML Schema (XSD) Input |
Rare, mostly manual schema creation. |
Yes. Uses XSD to auto-generate optimised schemas |
|
Normalisation Algorithms |
Manual setup. Will require expert support. |
Automatic. Relational, optimised output |
|
Mixed Content & Complex Branches |
Complex to handle, requires specialist intervention. |
Fully supported out of the box. |
|
Documentation Generation (ERD, Source-to-Target Maps) |
Manual |
Auto-generated with every conversion. |
|
Scalability (Millions of Files) |
Limited: Parallelism often requires extra configuration. |
Enterprise-grade scale-up and scale-out included. |
|
XML, JSON, CSV, TSV, PSV Input |
Varies because some formats may require separate pipelines. |
Supported natively across all formats. |
|
Database Outputs (Oracle, SQL Server, Snowflake, Redshift, PostgreSQL, etc.) |
Supported, you will need to manually create DDL. |
Automated output to multiple databases. |
|
Schema Evolution Support |
Manual (and will be prone to errors). |
Automatic schema evolution tracking. |
|
Maintenance Overhead |
High (ongoing adjustments required) |
Low. Set it, automate it, done. |
Stop Wasting Time: Manual XML to SQL Conversion Doesn’t Scale
If you’ve made it this far, you already know getting XML into SQL tables isn’t exactly a walk in the park.
Between tangled hierarchies, unpredictable structures, and endless manual work, it’s easy to burn hours just trying to make your data usable.
The good news? You don’t have to do it the hard way.
Flexter Enterprise takes care of the heavy lifting, converting XML to ready-to-query SQL tables: no XPath puzzles, no endless debugging, no guesswork.
Here’s the difference Flexter will make for you and your team:
- Converts XML automatically: no more writing custom scripts, XPath expressions, or reverse-engineering structures by hand. Flexter is a no-code solution.
- Handles both simple and complex XML: from flat files to deeply nested documents with multiple branches and mixed content.
- Works with or without XSDs: use your existing schema, sample XML files, or a combination to generate accurate table structures.
- It automatically adapts your database schema as your XML, XSD, or project requirements evolve.
- Normalises your data, so you avoid One Big Table (OBT) pitfalls and keep your SQL efficient and clean.
- It will optimise your target database schema using its state-of-the-art optimisation algorithms, without requiring any manual intervention.
- Scales effortlessly: whether you’re converting one file or processing large XML datasets for enterprise data projects.
- Supports other conversions to and from XML, including formats like CSV and JSON.
At this stage, you probably fall into one of two camps:
- Camp 1: You see the value, you’re tired of wrestling with XML, and you’re ready to shortcut the process. If that’s you, let’s talk.
Book a quick call, and we’ll show you exactly how Flexter can slot into your project, no guesswork required.
- Camp 2: You’re intrigued, but not fully convinced yet. Fair enough, take your time:
- Try Flexter’s online XML to SQL converter, which will spin up a Snowflake instance that includes your real XML files as SQL tables.
- Prefer to read before diving in? Here are some more resources for you:
- Flexter FAQ & Guide – Automate XML & JSON Conversions
- XML to Database Converter – Tools, Tips, & XML to SQL Guide
- XSD to Database Schema Guide – Create SQL Tables Easily
- How to Use the Flexter XML to SQL Database Converter Online
- XML to Redshift – Parsing, Loading, & Schema Tips (Guide)
- SQL Visualisation Guide – Query Diagrams, Lineage & ERD
- SQL Challenge: Tackling the Island Problem in Time Series Data
Frequently Asked Questions on XML to SQL (and Nested XML)
- What’s the difference between XML to SQL, XML to database, and XML to table?
These terms may sound similar, but they refer to different workflows, and if you’re not careful, you can select the wrong one for your use case.
When someone mentions XML to SQL, they typically mean storing raw XML in a database and querying it using SQL extensions, such as XMLTABLE or XMLQUERY.
XML to database is a broader term that refers to transforming XML into relational tables and inserting the clean data into a database.
XML to table? That’s usually flattening the XML into a single table in a database.
In short:
- So if you’re OK with querying raw XML and deciding the structure at query time, go with XML to SQL (aka Schema-on-Read).
- If you want structured data that is also more maintainable in the long term, go with XML to database (aka Schema-on-Write).
- If it’s just a one-off analysis with a simple XML, XML to table might be enough.
- What’s the difference between Schema-on-Read and Schema-on-Write?
This is all about when you apply structure to your data.
With Schema-on-Read, you store the XML as-is, then define the structure at query time. It’s flexible, but you’ll pay for that flexibility in performance and query complexity.
Schema-on-Write flips that: you define the structure upfront and insert normalised data into tables. It’s faster to query, easier to maintain, and just cleaner overall.
If you ask me, Schema-on-Read is for exploration. Schema-on-Write is for production.
- Do I need an XSD to convert XML into SQL?
Not technically. But if you have an XSD, use it. It’ll make everything easier.
XSDs give tools (and people) a reliable blueprint for how the XML is structured. Without it, you’re guessing or writing a lot of fragile logic to infer structure from sample files.
That’s fine in simple cases, but a recipe for problems at scale (except if you use a specific dedicated tool).
- What’s the fastest way to insert XML into SQL tables?
If you’re in a rush or just value your time, use Flexter.
You give it XML and/or XSD, and it hands you clean, relational tables: ready for SQL.
No scripts, no schema headaches, no “Why is this value NULL in half the rows?” moments.
I’ve seen teams save days (.. and nights) of dev time by switching to it.
- If I still want to try Schema-on-Read, should I store XML in a text column or use a native XML type?
You can shove XML into a CLOB column or a TEXT column, but you’ll regret it the moment you need to query it.
If your database supports native XML types (like XMLTYPE) use them. They retain structure, support indexing, and let you run XPath and SQL/XML functions directly.
If you don’t care about querying and you’re just archiving XML, text columns are fine.
- Can I just use Python to insert XML into SQL tables?
Yes, and I’ve done it myself. For small XML files, it’s quick and flexible.
But here’s the catch: the moment your XML becomes large, nested, or schema-driven, your Python script turns into a maintenance nightmare.
So if it’s one-and-done? Go ahead.
If you’re building a pipeline or dealing with dozens of files? Use something built for the job.
- What’s SQL/XML, and how is it different from XQuery?
If you’re already in a relational database, SQL/XML is your friend.
XQuery, on the other hand, is a whole separate query language for XML. It’s insanely powerful and great for deeply nested structures, but it lives outside your SQL workflow.
I’ve actually written more about the SQL/XML vs XQuery debate here.
- Why is automated XML to SQL conversion better than manual approaches?
Manual approaches seem fine until they aren’t.
You start with a small XML and a simple script. Then the XML changes.
Or doubles in size. Or adds a new nested layer.
Suddenly, your pipeline’s brittle and your weekend’s gone.
Automated tools like Flexter handle much more complex cases of XML insertion in SQL with:
- Deep nesting.
- Schema inference or XSD.
- Normalisation of the source XML into a relational schema.
- Documentation (lineage, ERDs, mappings).
And they do it without writing XPath or reinventing your logic every time.
Trust me: automation pays for itself in stability and sleep.



