Advanced Spark Structured Streaming – Aggregations, Joins, Checkpointing
In this post we are going to build a system that ingests real time data from Twitter, packages it as JSON objects and sends it through a Kafka Producer to a Kafka Cluster. A Spark Streaming application will then parse those tweets in JSON format and perform various transformations on them including filtering, aggregations and joins. A table in a Snowflake database will then get updated with each result.
Table of Contents
Delivering real-time data using Kafka
To simplify the data ingestion pipeline we will re-use the setup from a previous post that showed you how to stream tweets into a Snowflake data warehouse using Spark Structured Streaming and Apache Kafka.
This is the Python code which produces the data Spark will ingest:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import tweepy from kafka import KafkaProducer import json import time # twitter setup consumer_key = "<your consumer key>" consumer_secret = "<your consumer secret>" access_token = "<your access token>" access_token_secret = "<your access token secret>" # Creating the authentication object auth = tweepy.OAuthHandler(consumer_key, consumer_secret) # Setting your access token and secret auth.set_access_token(access_token, access_token_secret) # Creating the API object by passing in auth information api = tweepy.API(auth) producer = KafkaProducer(bootstrap_servers='localhost:9092') topic_name = 'data-tweets' important_fields = ['created_at', 'id', 'id_str', 'text', 'retweet_count', 'favorite_count', 'favorited', 'retweeted', 'lang'] def get_twitter_data(): res = api.search("iphone") for tweet in res: # iterate over results json_tweet = {k: tweet._json[k] for k in important_fields} # extract interesting fields json_tweet['text'] = json_tweet['text'].replace("'","").replace("\"","").replace("\n","") producer.send(topic_name, str.encode(json.dumps(json_tweet))) def periodic_work(interval): while True: get_twitter_data() time.sleep(interval) periodic_work(60 * 0.15) # get data every couple of seconds |
In case you want a more detailed explanation of exactly how this works, please check out this related blog post in which we explained this set up in more details
Spark Structured Streaming
Introduction
Structured Streaming is the new streaming model of the Apache Spark framework. It was inspired by Google open sourcing it’s Cloud Dataflow SDK as the open source project Apache Beam. The Dataflow Model, invented by Google, says that you should not have to reason about streaming, but rather use a single API for both streaming and batch operations. It allows you to write batch queries on your streaming data.
You can read a more detailed introduction to Spark Streaming Architecture in this post.
Goal
The goal of the streaming architecture is to present a realtime view with how many tweets about iPhones were made in each language region during the day.
Spark configuration
In the following code snippets we will be using Scala with Apache Spark 2.2.0.
To start the application we are going to define the usual spark entry point that gives us both Spark SQL and Spark Structured Streaming functionality:
|
1 2 3 4 5 |
val spark = SparkSession .builder() .appName("Advanced Spark Structured Streaming") .master("local[*]") .getOrCreate() |
Defining the data source
Next we are going to define the data input for our Streaming applicatioin. We will ingest data by reading latest messages from the “data-tweets” topic on the Kafka broker we previously developed.
|
1 2 3 4 5 6 7 |
val data_stream = spark .readStream // constantly expanding dataframe .format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "data-tweets") .option("startingOffsets","latest") //or earliest .load() |
This is the schema of incoming data from Kafka:
|
1 2 3 4 5 6 7 8 9 |
StructType( StructField(key,BinaryType,true), StructField(value,BinaryType,true), StructField(topic,StringType,true), StructField(partition,IntegerType,true), StructField(offset,LongType,true), StructField(timestamp,TimestampType,true), StructField(timestampType,IntegerType,true) ) |
Watermarking
Firstly we will introduce a Watermark in order to handle late arriving data. Spark’s engine automatically tracks the current event time and can filter out incoming messages if they are older than time T. In our use case we want to filter out messages that just arrived but are more than 1 day old. We can do that with the following code:
|
1 2 |
var data_stream_transformed = data_stream .withWatermark("timestamp","1 day") |
Parsing JSON data
Since the incoming tweets are packaged inside of the “value” column (of the schema shown above), we have to first extract them out of that column and then parse the JSON content into a table with a schema containing the following columns that describe a tweet:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
val schema = StructType(Seq( StructField("created_at", StringType, true), StructField("id", StringType, true), StructField("id_str", StringType, true), StructField("text", StringType, true), StructField("retweet_count", StringType, true), StructField("favorite_count", StringType, true), StructField("favorited", StringType, true), StructField("retweeted", StringType, true), StructField("lang", StringType, true), StructField("location", StringType, true) )) |
The following code will first cast the “value” column (originally of byte type) into a string.
Then the from_json() function parses the JSON string into a table with columns based on the schema that we just defined above.
Lastly we use selectExpr() function to do a few datatype casts.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
data_stream_transformed = data_stream_transformed .selectExpr("CAST(value AS STRING) as json") .select(from_json(col("json"),schema=schema).as("tweet")) .selectExpr( "tweet.created_at", "cast (tweet.id as long)", "tweet.id_str", "tweet.text", "cast (tweet.retweet_count as integer)", "cast (tweet.favorite_count as integer)" , "cast(tweet.favorited as boolean)" , "cast(tweet.retweeted as boolean)", "tweet.lang as language_code" ) |
Now our JSON tweets are nicely formatted as rows in a dataframe that we can query.
Transforming incoming data
We will first filter out the rows whose authors have less than five retweets. We are doing this in order to remove less influential or bot accounts from our consideration.
|
1 |
data_stream_transformed = data_stream_transformed.filter("retweet_count > 5") |
Next we are going to group the tweets by their language code (this is the best proxy for a location of a tweet) and then calculate the count of unique id’s and the sum of times each tweet was favorited.
|
1 2 3 |
data_stream_transformed = data_stream_transformed .groupBy("language_code") .agg(sum("favorite_count"), count("id")) |
Now the outcoming data looks as following:
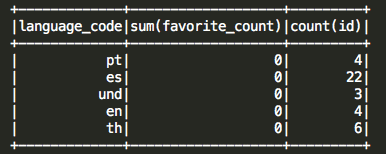
Unfortunately language codes are not very informative so we will join this table with a table containing ISO language codes associated with a human readable description. The table is sitting on a local machine and will be read using the batch oriented Spark SQL commands.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
val schema_csv = StructType(Seq( StructField("language_code", StringType, true), StructField("language_name", StringType, true) )) val languages_translation = spark .read .format("csv") .option("header","false") .schema(schema_csv) .load("/Users/dbg/Desktop/languages.csv") .as("languages_translation") data_stream_transformed = data_stream_transformed .join(languages_translation, Seq("language_code"),"left") |
To make the transformation logic a bit more clear, I will rewrite all of the transformations we just applied into a single code block:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
val data_stream_transformed = data_stream .withWatermark("timestamp","5 day") .selectExpr("CAST(value AS STRING) as json") .select(from_json(col("json"),schema=schema).as("tweet")) .selectExpr( "tweet.created_at", "cast (tweet.id as long)", "tweet.id_str", "tweet.text", "cast (tweet.retweet_count as integer)", "cast (tweet.favorite_count as integer)", "cast(tweet.favorited as boolean)" , "cast(tweet.retweeted as boolean)" , "tweet.lang as language_code") .filter("retweet_count > 5") .groupBy("language_code") .agg(sum("favorite_count"), count("id")) .join(languages_translation, Seq("language_code"),"left") |
Analyzing the execution plan
Now it would be interesting to analyze the execution plan of this query to gain a better understanding of how the query is executed and how the computations are optimized.
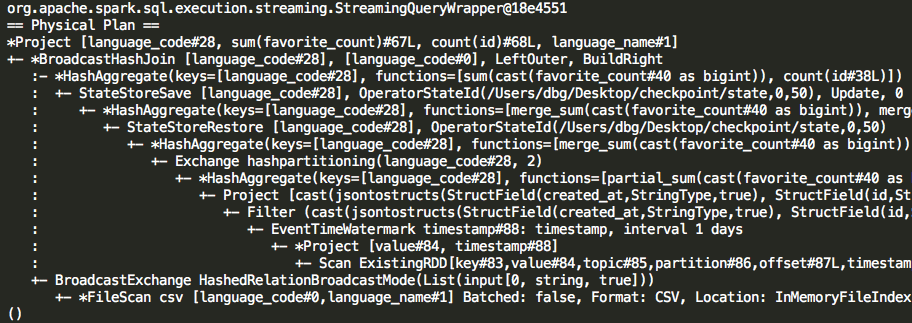
In the execution plan we can observe that the query starts by scanning new for new data (in the form of RDDs).
It then filters the data older than 1 days based on the Kafka message timestamp column that captures when the message was made.
The data is then filtered based on “retweet_count > 5” condition we set.
After that Spark will materialize the JSON data as a new dataframe.
The sum and count aggregates are theb performed on partial data – only the new data.
The Spark Streaming engine stores the state of aggregates (in this case the last sum/count value) after each query in memory or on disk when checkpointing is enabled.
This allows it to merge the value of aggregate functions computed on the partial (new) data with the value of the same aggregate functions computed on previous (old) data.
After the new states are computed, they are checkpointed and only then the join is performed with the table containing language codes.
We can see that overall this is a very efficient execution plan as the engine tries to operate on as little data as possible.
Exporting data into Snowflake
In the next steps we will define the output of our streaming pipeline and export it into a Snowflake database.
Spark allows us to use three output modes:
- Append mode – Only the new rows added to the Result Table since the last trigger will be outputted to the sink
- Complete Mode – The whole Result Table will be outputted to the sink after every trigger (only supported for aggregate queries)
- Update Mode – Only the rows in the Result Table that were updated since the last trigger will be outputted to the sink
We are going to use the Update mode to export only the rows that changed in the result of aggregations.
It is also important that we define a trigger which determines how often the streaming pipeline will run. For this use case we will use a trigger of 10 seconds in order to run the pipeline every 10 seconds.
The following code defines what we mentioned:
|
1 2 3 4 5 6 7 |
val query = data_stream_transformed .writeStream .option("checkpointLocation","/Users/dbg/Desktop/checkpoint") .foreach(writer) .trigger(Trigger.ProcessingTime("10 seconds")) .outputMode("update") .start() |
Upserting data to a JDBC sink
The writer variable which we used with foreach() method represents a custom made JDBC sink. In a previous post we covered in more detail how to create custom JDBC sinks. Essentially the foreach() function processes every row in the Result Table with the logic we define with process() function of a JDBC sink.
The process function (located in the JDBC sink class) is in our case applied to every updated row in the Result Table.
The code below shows the exact implementation:
|
1 2 3 4 5 6 7 8 |
def process(value: org.apache.spark.sql.Row): Unit = { statement.executeUpdate( "delete from tweet_aggregates where tweet_aggregates.language_code = '" + value(0) + "' ; " ) statement.executeUpdate( "insert into tweet_aggregates values('" +value(0)+ "', " +value(1)+ ", " +value(2)+ ", '" +value(3)+ "');" ) } |
You can observe that we are essentially performing an upsert. If the row already exists, we will update it (and Spark’s engine guarantees it to have changed) by deleting and then inserting it. If it was not already present in the Result Table, we will simply insert it.
In this way we can capture the same state in Snowflake as is kept in Spark’s Streaming model.
Checkpointing
The Checkpoint option we defined for our streaming application will make sure that our streaming application can easily resume it’s operations without any loss of state while still maintaining the proper offsets for Kafka messages. This is done using a Write ahead log.
We can actually explore the contents of the checkpoint folder:

The Checkpoint directory contains folders which are populated with data required to restore the current state after every query is ran.
In the offsets folder the last offsets of messages we read from Kafka are written. In the state folder the latest state of aggregate counters is caputred. The information about source of data stream can be found in sources folder and the commits we made are noted in the commits folder.
In case we turn off our streaming application for 8 hours (while new tweets are being produced and stored in the Kafka broker) our application could easily be restarted and no information would be lost.
Querying the data in Snowflake
The resulting data can now be easily queried in Snowflake using a simple query:
|
1 |
SELECT * FROM tweet_aggregates; |
You can observe the result in Snowflake’s SQL Worksheet: