Converting Duck Creek XML to a relational database
Duck Creek makes extensive use of XML. All Policy data is locked away in XML just to give one example.
XML is a great format for exchanging data and for recording transactions against a Policy. However, it is not a good fit for data analysis, reporting, or querying data. If you want to display common insurance industry KPIs such as Policy Retention Rate, Policyholder Churn Rate, or Claims Settlement Rate on a dashboard XML is not a good fit. For analytics requirements we need to convert Duck Creek XML to a relational format in a database.
Duck Creek ships a separate product called Duck Creek Insights. It is licensed separately. Its other limitation is the choice of database. You can’t pick the database technology or storage format of your choice. As a result, customers of Duck Creek opt to convert Duck Creek XML themselves.
What are some Duck Creek XML conversion options?
In the past, Duck Creek shipped with an XML shredding option. This feature is being phased out slowly.
Another option for converting Duck Creek XML for data analysis purposes is to write your own XML conversion code.
Manual XML conversion is very labour intensive. It involves the following steps:
- Analyse the XML Structure and XSD
- Design the Database Schema: Based on the XML analysis, design your database schema. This includes deciding on tables, columns, data types, primary keys, and relationships.
- Create the Data Definition Language (DDL) scripts for the target schema
- Define Mappings: Determine how the elements and attributes in the XML map to the tables and columns in your database schema.
- Parse the XML: Use an XML parsing library or XML native database features to read and traverse the XML structure.
- Insert Data into the Database
- Ensure that you respect the relationships, constraints, and any other schema-specific rules during insertion.
- Data Validation: After the conversion, validate the data in your database against the original XML to ensure accuracy and completeness.
- Optimisation and tuning for performance: If you have a large amount of XML data or need frequent conversions, consider optimising your parsing and load procedures.
- Data Pipeline Design: Ingestion: How is the XML data ingested? How does the data flow and what are the dependencies?
- Processing: After ingestion, the data may need pre-processing, cleansing, or validation before the actual conversion.
- Post-processing: Activities after data insertion, like indexing, aggregation, or further data validation.
- Scheduling: Determine the frequency of XML data arrival and conversion requirements. Is it daily, hourly, or near real-time?
- Monitoring and Alerting: Incorporate monitoring to check for failures, delays, or anomalies in the conversion process. Implement alerting mechanisms to notify relevant stakeholders or systems in case of issues.
- Error Handling and Recovery: Design mechanisms to handle errors gracefully. Should the pipeline retry automatically? If an error occurs, how can you ensure data consistency or rollback?
- Implement logging to capture both system and data issues for diagnosis.
- Documentation: Document your mapping rules, any transformations applied, and any challenges or peculiarities you encountered. This will be valuable for any future conversions or if the data needs to be understood by another person or team.
Why do so many Duck Creek XML conversion projects fail or run over budget?
Ralph Kimball, the father of data warehousing has the following warning in relation to XML conversion:
“Because of such inherent complexity, never plan on writing your own XML processing interface to parse XML documents.
The structure of an XML document is quite involved, and the construction of an XML parser is a project in itself—not to be attempted by the data warehouse team.”
Kimball, Ralph: The Data Warehouse ETL Toolkit. Practical Techniques for Extracting, Cleaning, Conforming, and Delivering Data
This quote aligns with our own experience. It is one of the reasons we created Flexter.
In a nutshell Duck Creek XML conversion projects can fail for the following reasons:
- Duck Creek XML is super complex, which makes it hard and time consuming for engineers to work with.
- Lack of XML expertise and skills is another reason, e.g. limited experience with complex XML scenarios (nested XSDs, inheritance etc.). This is often paired with an inflated confidence in working with XML.
Automating Duck Creek XML conversion to a relational database
When it comes to Duck Creek the better alternative to manual coding is to use an automation tool to convert XML to a relational format. Duck Creek XML is super complex. It lends itself well to automation.
We have created Flexter for this purpose. Flexter is a great fit for Duck Creek XML conversion. It automatically converts XML for data analysis, e.g. converting Duck Creek to a data warehouse, data lakehouse, or a data lake.
You get various benefits from automating the Duck Creek conversion process with Flexter:
- You can meet deadlines instantly and immediately consume data for reporting and dashboards. Flexter reduces the time to market for your solutions: Flexter fully automates the conversion process of XML and eliminates long and costly development life cycles. Flexter shortens the development life cycle from weeks or months to hours or days. Data becomes available immediately for decision making. Data becomes available quicker for analysis. Insights can be generated earlier and important decisions can be made with access to the right data. What is the cost of not having the data available or not having it available in a timely manner for making important decisions?
- Reduce cost and expensive conversion project costs. Custom building an equivalent process requires 1-4 full time jobs for a specified period of time depending on the complexity of the documents (weeks or months). Often this is impossible without acquiring expensive third party niche skills increasing the costs even further
- You can eliminate the risk of project failure or running over budget. XML conversion projects have a very high rate of failure.
- Reliability and business improvement: At Sonra, we have decades of experience working with XML. We have poured all of our knowledge into Flexter. The XML conversion process has gone through years of testing and quality control. Flexter eliminates any manual coding and virtually eliminates the risk of bugs in the code.
- New Duck Creek versions require changes to the XML conversion process. Flexter detects any changes automatically and automates the change process.
- By using Flexter you free up your data engineers to focus on delivering real value and insights to your business users instead of working on a complex project that converts data from one format to another. Your data engineers can deliver real insight to your business users and thereby improve the decision making process. Using Flexter may also reduce the turnover in data engineering staff as it makes their job easier and does not force them to acquire legacy skills that have a low demand in the market.
- Meet your SLAs and tight conversion process deadlines. Flexter scales to any number of Duck Creek XML documents
One of our customers summarised the benefits in one simple sentence: “You did in one day what we could not do in 3 years”, Aer Lingus.
Duck Creek XML conversion with Flexter
Let’s first dive into some important Flexter features before we show you how Flexter works hands on.
Flexter XML converter features
In this section we go through some of the features of Flexter.
Automated Target Schema:
You can use an XSD and / or a sample of XML documents to generate a target schema and mappings.
Flexter supports XML schema specifications (XSD), including advanced features like polymorphism and xsi types.
It handles XML data of any complexity and depth in its hierarchy.
It should be able to create a relational target schema either from an XSD or from a sample of XML documents, which can be a helpful bonus feature.
Automated Mappings:
As part of automatically generating the target schema, Flexter automatically maps XML source elements to the corresponding columns in the target table.
Automated Documentation:
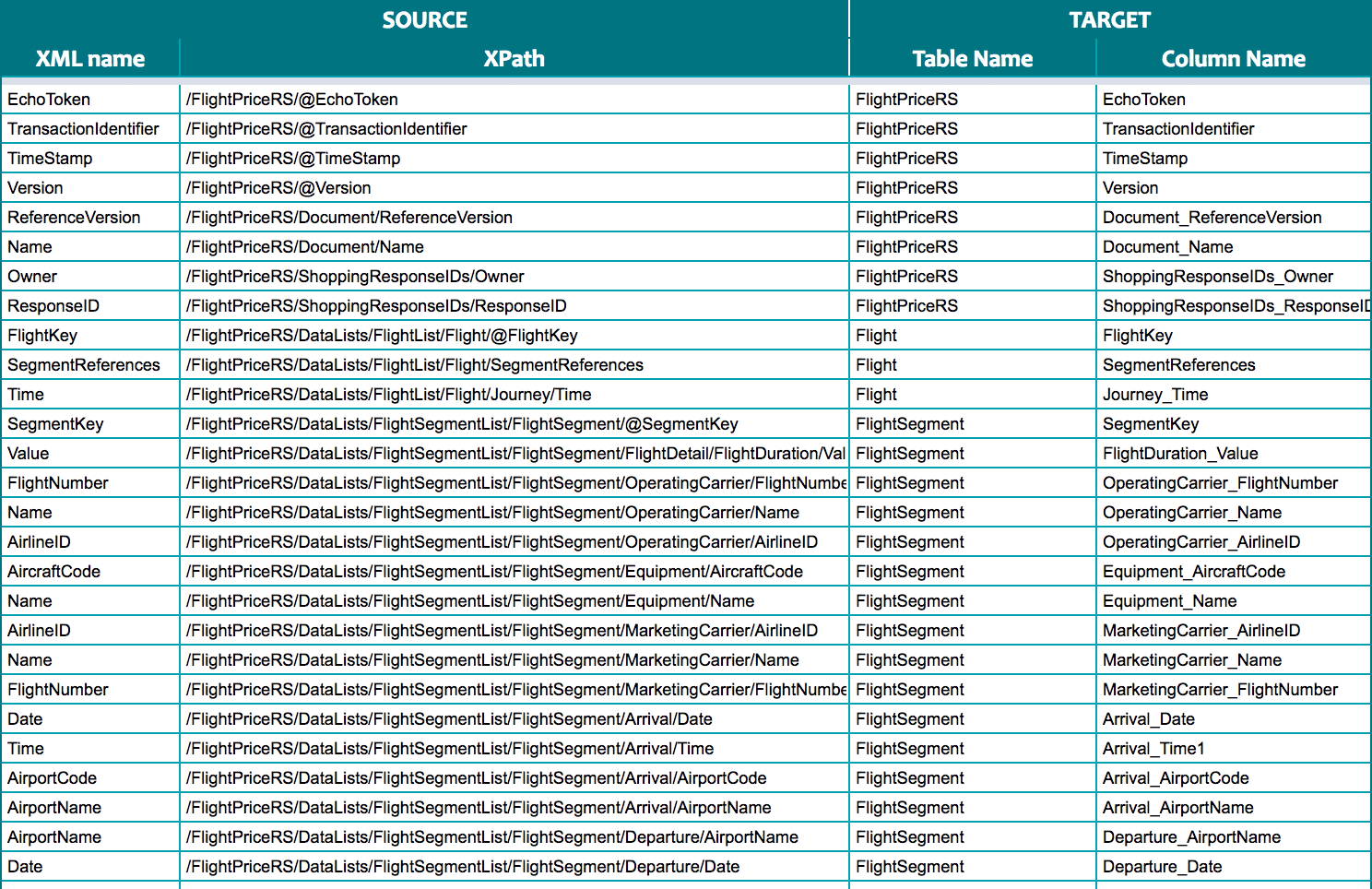
Flexter automatically creates documentation, including data lineage, entity-relationship diagrams (ER diagrams), source-to-target mapping, and data models.
Source to target map
Er Diagram
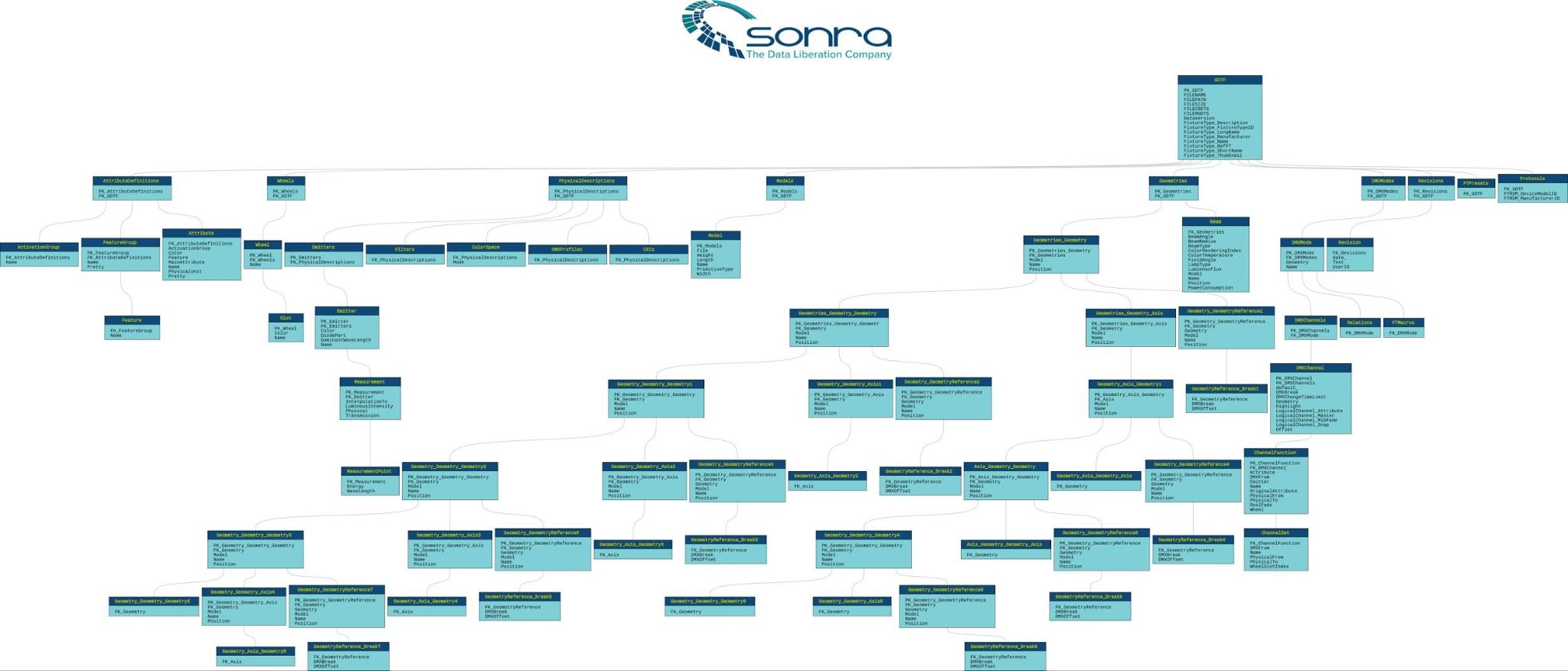
Automated foreign key generation
During the conversion the converter should create parent child relationships and foreign keys.
Connector support
Keep an eye out for extensive connector support. You want the converter to be compatible with cloud requirements and support for object storage, e.g. S3, Blob storage, Azure Data Lake Storage.
Support of the so-called modern data stack such as Snowflake, BigQuery, Databricks should be a core feature on top of support for traditional RDBMS such as Oracle and MS SQL Server. The data landscape changes quickly and you want your converter to go with the times.
Support for open source data formats such as Parquet, Iceberg, Delta Lake, Avro, ORC should also feature.
Optimisation for simplified target schema
The XML converter should simplify the target schema as much as possible to make it easier to work with the target model. The less tables the easier it gets to read the data model. The less table joins in the target schema the better the performance.
API / programmatic access
You will need programmatic access via an API, SDK, or command line interface. This is important to embed the automated XML conversion in your data pipelines and workflows.
Metadata catalog
A metadata catalog is useful to store the mappings between source and target. It can be used to compare different versions of your XSD and target schema. Industry data standards and XSDs change. Having the ability to quickly identify what exactly has changed between different versions of say HL7 is very useful.
A metadata catalog can also be used to generate DDL for the target schema and to auto generate upgrade scripts between different versions of a target schema.
Error handling and error logging
The XML converter should have built in features for error logging and error handling. Runtime errors should be logged to an error log
Pipeline and workflow integration
The conversion of the XML files is just a step in a bigger pipeline. Other steps include archiving, handling failed loads, restartability, handling errors, detecting XML documents with unknown XPaths, alerting, downstream ETL to create data marts and many more.
You need to make sure you can integrate the automated XML conversion in your data pipelines and wider data orchestration requirements.
Scalability and performance
The XML converter should be able to process any volume of data and meet any Service Level agreements. On top of this it should be able to convert very large XML files.
Schema evolution
XSDs change. Schema evolution and code refactoring should be an automated or semi automated process.
Full XSD support. Generic XML conversion
Flexter has full support of the XSD specification. It can convert any type of XML to a database. Flexter has you covered for any type of XML and not just Duck Creek XML. It converts any type of XML to a relational format or database.
Book a demo to find out more about benefits, features, pricing, and how to try Flexter for free.

Converting Duck Creek XML to Snowflake
For this example we used Snowflake to create the relational target model. We could have used any of the other supported databases such as BigQuery, Databricks, Oracle, SQL Server etc. or one of the supported storage formats such as Parquet, Delta Tables, CSV etc.
Converting Duck Creek XML data can be performed in a couple of simple steps
Step 1 – Create target schema and mappings
Flexter collects Statistics (information such as data types, constraints, and relationships) and creates a Data Flow (Mapping data attributes in the XML source elements to the columns in the relational target schema)
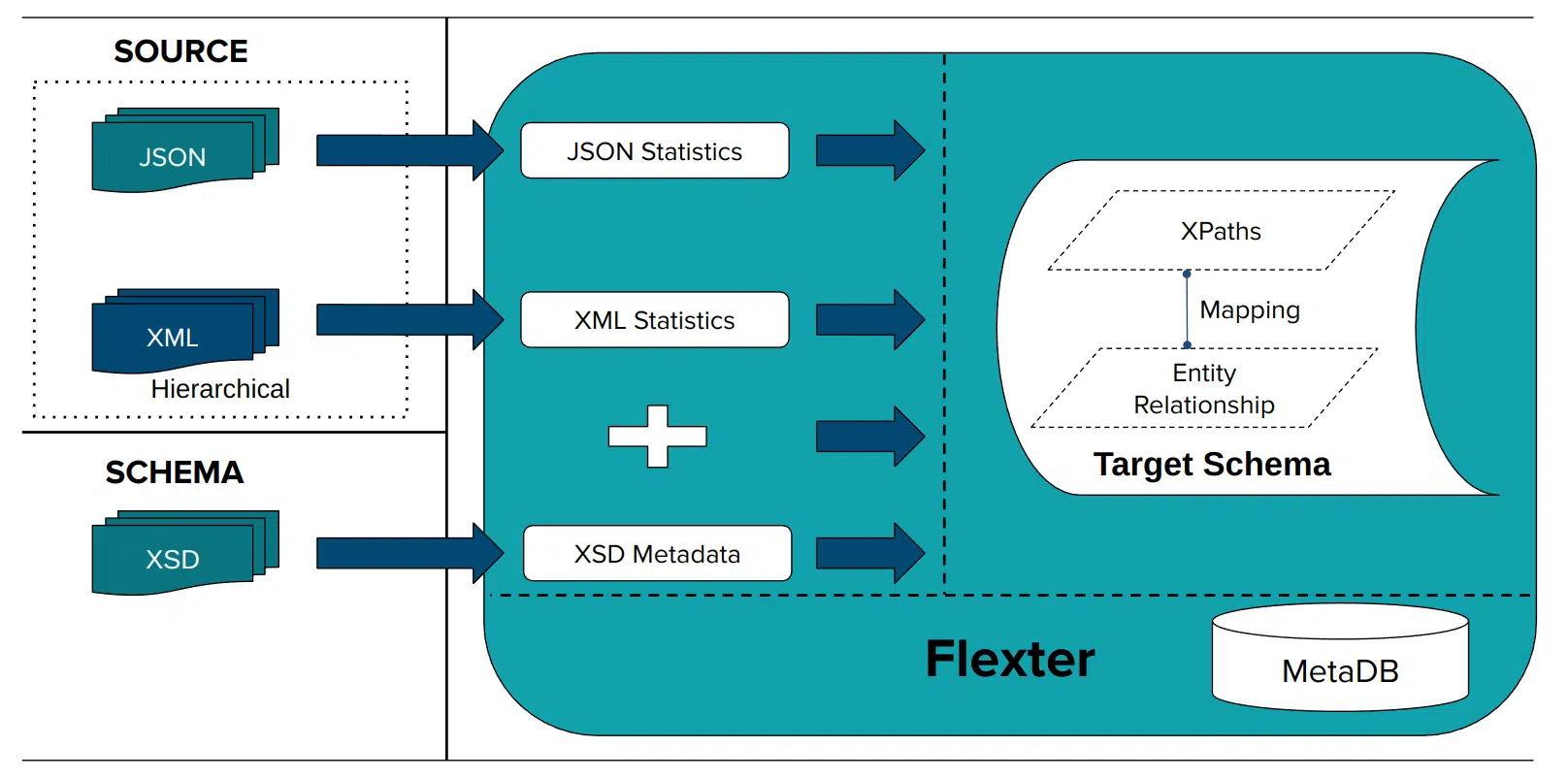
In this step we will read XML data, collect metadata, and create a data flow (a logical target schema and the mappings from source to target). We used a couple of Duck Creek XML documents and obfuscated the data with Paranoid. It is an open source tool to mask data in XML and JSON.
|
1 |
xml2er -g1 /DuckCreek.zip |
Example of output
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# schema origin: 8748 logical: 3254 job: 53642 # statistics startup: 1895 ms load: 160 ms xpath stats: 9474 ms doc stats: 1609 ms parse: 123 ms write: 9232 ms xpaths: 35 | map:0%/0 new:100%:35 documents: 2 | suc:100%/2 part:0%/0 fail:0%/0 size:4.2KB |
Step 2 – Convert data
In a second step we convert the data to the output folder which we created. We also define the output format, e.g. TSV, ORC, Parquet, Avro files, or in our case a relational database such as Snowflake.
In this particular instance we did not use a Duck Creek XSD to convert the data. Flexter can work with an XSD, a sample of XML files or both. The last option will give you the best of both worlds.
We run the following command:
|
1 |
xml2er -l3254 /DuckCreek.zip -S o “snowflake://https://abc.eu-central-1.snow flakecomputing.com/?warehouse=ware&db=db&schema=DuckCreek” -U abc -P def |
Commands can also be triggered programmatically via the API
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
18:21:13.316 INFO Registering success of job 62 18:21:13.331 INFO Finished successfully in 6894 milliseconds # schema origin: 8749 logical:3255 job: 53643 # statistics startup: 458 ms load: 154 ms xpath stats: 3489 ms doc stats: 2489 ms parse: 1897 ms write: 284 ms xpaths: 35 | map:100%/35 new:0%/0 documents: 2 | suc:100%/2 part:0%/0 fail:0%/0 size:4.2KB |
Final step: Analyse and query your Duck Creek Policy data in Snowflake
Do you want to see the XML conversion process with Flexter end to end? Have a look at this video where we convert data locked away in FpML to Snowflake.
What about ACORD XML, Guidewire XML or any other type of XML? What about JSON?
ACORD is a common industry data standard. Industry data standards are known for their complexity and ACORD is no exception. It is at a similar level of complexity to Duck Creek. Developers and engineers get quickly frustrated as you can see from this discussion a Stackoverflow ACORD question:
“This standard is HUMONGOUS and very convoluted. A total chaos to my eyes.”
“the average coder will not ‘get it’ for about 3-4 months if they work at it full time (assuming anything but inquiry style messages).”
Guidewire is a Duck Creek competitor and has even more complex XML structures.
Duck Creek, Guidewire, and ACORD all share the following characteristics:
- They make extensive use of XML
- The XML and XSD is super complex
- You need to convert it to a relational database for data analysis
The good news is that Flexter can automatically convert all three of them to a relational database or storage format.
In fact, Flexter has full support for the XSD specification and can handle any type of XML or XSD.
Even better, it can handle any hierarchical data such as JSON as well.



