The Ultimate Guide to XML Mapping in 2026


XML mapping is a critical process in data integration, ETL, and system interoperability. As an architect, analyst, engineer, or manager involved in XML mapping projects, you’re likely familiar with the challenges of this process. As the complexity and volume of data increases, manually mapping methods become less feasible. This is where the power of automation in XML mapping shines through as a scalable alternative.
In this comprehensive guide to XML mapping in 2024, we delve deep into why an automated approach to XML mapping is often the most effective and efficient strategy for businesses.
We will explore the key components of XML mapping. We’ll also provide a step-by-step guide to navigating the XML mapping process and data mapping techniques, from analysing the structure of XML and XSD to translating between hierarchical structures and target formats.
Additionally, we’ll cover practical examples such as XML mapping to Excel and databases. A special focus will be on the advantages of automated tools and scenarios where they are most beneficial.
By the end of this guide, you’ll have a thorough understanding of when, why and how automated approaches of XML mapping, exemplified by tools like Flexter, are more suitable than a manual approach.

What is XML mapping?
XML mapping refers to the process of creating a relationship or mapping between elements in an XML schema and elements in another data format. XML mapping is a fundamental technique in XML Data Transformation, facilitating the conversion of data from XML to other formats.
Several key components are crucial in this process, each playing a specific role in ensuring the mapping is effective and accurate:
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Direction of XML mapping
The direction of XML mapping refers to the flow of data transformation between the source and the target format. This directionality is an important aspect of the mapping process, as it defines how and where the data conversion or transformation occurs. There are typically two primary directions in XML mapping:
XML to Other Formats: In this direction, the data starts in an XML format and is mapped to another format.
Other Formats to XML: This is the reverse process, where data in various formats is converted into XML.
XML mapping use cases
Here are some examples of common use cases for XML mappingsThe data that is locked away in XML needs to be extracted in an ETL process to a relational format in the data warehouse database.
Database to/from XML Mapping: This process involves mapping database fields to XML elements and attributes, and can also work in the reverse direction. For instance, when exporting data from a relational database to an XML file, each database column might be mapped to a corresponding XML element. Conversely, when importing XML data into a database, XML elements and attributes are mapped to appropriate table columns. For a practical guide on how this works inside SQL Server specifically, using OPENXML, XQuery, and BULK INSERT, see this guide to parsing XML data in SQL Server.
XML to/from CSV conversion: XML to CSV Conversion is another practical application of XML mapping, especially for data analysis purposes. If you are deciding between CSV, JSON, and XML for your project, this CSV vs JSON vs XML comparison guide explains the key differences with real-world examples.
Object to/from XML Mapping (OXM): In object-oriented programming, OXM is a frequent requirement, where objects in a programming language (like Java or C#) are mapped to XML elements, and vice versa. This is useful for configuration, data storage, or communication in web services. Frameworks such as JAXB (Java Architecture for XML Binding) facilitate this process by handling the conversion between objects and XML. XML Serialization is a key aspect of OXM, converting objects to XML format for storage or transmission
XML to/from XML Mapping: This process involves transforming one XML schema into another and can also involve the reverse transformation. This is necessary when integrating systems with differing XML formats. Tools like XSLT (eXtensible Stylesheet Language Transformations) are employed to define the rules for this transformation.
XML Mapping in Spreadsheets and Data Analysis Tools: Applications like Microsoft Excel allow users to import XML data and map it to spreadsheet cells, and to export data from spreadsheets to XML. This feature enables the analysis and manipulation of XML data using standard spreadsheet operations.
Web Services and APIs: In the realm of web services and APIs, XML mapping is crucial for transforming the XML structure used by one service to match that of another, facilitating seamless data exchange and integration. This includes both transforming incoming XML data to the service’s internal format and converting internal data structures to XML for outgoing responses.
XML data exchange and industry data standards: XML mapping plays a big role in the context of industry data standards such as XBRL (eXtensible Business Reporting Language), FpML (Financial products Markup Language), FHIR (Fast Healthcare Interoperability Resources), HL7 (Health Level Seven International) and many more. These standards are designed to ensure consistency, accuracy, and interoperability in their respective industries, and XML mapping is key in achieving these objectives:
Extraction in ETL Processes for data warehousing or a data lake: The data that is locked away in XML needs to be extracted in an ETL process to a relational format in the data warehouse database. XML mappings are used to interpret and extract relevant data from these XML files. This involves understanding the structure of the XML (using XSDs or other schema definitions) and identifying the specific elements and attributes that need to be extracted. In the context of a data warehouse the XML mapping does not include transformation and business logic. It just maps the hierarchical structure to a relational schema and extracts the data to a Landing or Staging area.
As a general best practice business and transformation logic is applied as far downstream to the actual data consumers as possible. The main reason is to limit the amount of refactoring when changes to the business logic are applied. The further downstream the business logic is applied the less impact on the data pipeline and the amount of code refactoring needed.
XML to/ from JSON: Another common use case is XML to JSON conversion, where XML data is transformed into JSON format for various applications.
XML Integration: XML Integration into different systems and platforms is a vital application of XML mapping.
Source and target schema
In the context of XML mapping, especially when considering the direction of mapping (either from XML to another format or from another format to XML), the concepts of source schema and target schema are important. Let’s break it down based on the direction of the mapping:
Mapping from XML:
- Source Schema: In this scenario, the source schema is the structure of the original XML data. It includes the XML elements, attributes, and the hierarchical relationships between them. This schema represents the data as it is initially available before the mapping process.
- Target Schema: The target schema, in this case, is the structure of the data in its new format after the mapping. This new format could be another XML structure with different element names and hierarchy, a database schema, a JSON structure, or any other data format. The mapping process involves transforming the XML data from its source schema to this target schema, which could entail element renaming, hierarchy restructuring, or even data type conversion.
Mapping to XML:
- Source Schema: Here, the source schema refers to the structure of the data in its original format before being converted into XML. This could be a database schema, a JSON format, a CSV file structure, or any other data format.
- Target Schema: The target schema in this direction of mapping is the XML structure. The mapping process involves transforming the data from its original format (source schema) into the XML format (target schema). This may involve creating XML elements and attributes that represent the data structures in the source schema and ensuring the XML output conforms to the desired XML structure.
In both directions, the mapping process requires a clear understanding of both the source and target schemas. It often involves a set of rules or a mapping definition that dictates how each piece of data in the source schema is transformed and represented in the target schema. This process is crucial in data integration, ETL (Extract, Transform, Load) processes, and when exchanging data between different systems or applications.

Relevance of XSD in XML schema mapping
The relevance of an XSD (XML Schema Definition) in XML mapping is significant. An XSD plays a critical role in defining the structure, constraints, and data types of the elements in an XML document. In the context of XML mapping, its relevance can be outlined in several key aspects:
- Inferring Target Structures: In XML mapping, whether it’s XML to XML, database to XML, or object to XML, the XSD serves as the blueprint that defines the structure of the XML data. For both the source and target XML documents, XSDs ensure that the data adheres to a specified structure, which is crucial for consistent and error-free mapping.
- Data Validation: An XSD allows for the validation of XML data against defined structures and rules. This ensures that the XML data being mapped conforms to the expected format, which is vital for the integrity of the data during the transformation process. This validation can prevent errors that might occur due to incorrect data structures or types.
- Type Safety: XSDs define not just the structure but also the data types of the elements and attributes in an XML document. This ensures type safety during the mapping process, meaning that data types are consistently maintained from source to target, reducing data type mismatch errors.
Challenges in XML mapping
Mapping XML between source and target schemas can be quite challenging and result in the failure of XML mapping projects. This is due to a variety of reasons.
XML and XSD complexity
The primary challenge in any XML mapping project is XMP parsing of complex XMLs and XSDs in particular in the context of industry data standards.
Size of the XSD and number of XSD files
Large XSD files can be challenging to manage and understand. They may define thousands of elements, complex types, and attributes, making the schema incredibly dense and difficult to navigate.
In many industry standards, the schema is not confined to a single XSD file. It often spans multiple files with imports and includes, creating a network of interdependent definitions.
Managing dependencies and ensuring consistency across multiple XSD files add to the complexity, especially if different parts of the schema are maintained or updated independently.
Let’s have a look at a complex industry data standard such as FpML

FpML in version 5.12 contains 35 XSD documents. These are deeply nested. The entry point is fpml-main-5-12.xsd
Let’s open this XSD file
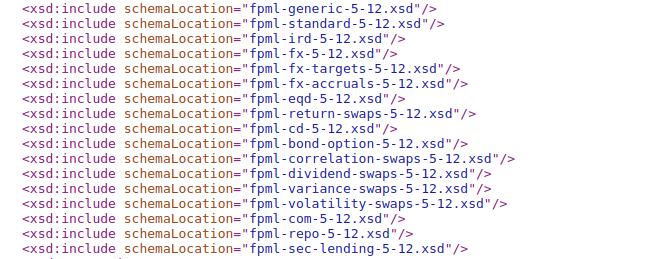
As you can see this file references various other XSD files, e.g. fpml-generic-5-12.xsd. Opening this file shows additional dependencies

Converting this file to another format, e.g. a relational database will result in thousands of tables, an almost impossible task when done manually.
Complex Type Definitions and Hierarchies:
XSDs often include complex type definitions with intricate hierarchies. This can include extensive use of inheritance, abstract types, and polymorphism, which require sophisticated handling during XML parsing and mapping.
Extensive Use of Namespaces:
To avoid name collisions and to ensure clarity, XSDs in industry standards often use multiple namespaces. Managing these, especially in the context of a large number of elements, can be challenging.
Abstract Elements and Types:
XSDs can define abstract elements and complex types, which are not used directly in XML documents but serve as base types for other elements. Understanding the inheritance hierarchy and the role of these abstract definitions can be complex.
Substitution Groups:
These allow one element to be substituted for another in the XML document. This feature, while powerful for flexible document design, can make it difficult to understand which elements might appear in a given context.
Use of xs:choice and xs:sequence:
These elements define how child elements are ordered and whether they are optional or required. They can create complex rules for the presence and order of elements in the XML document, adding to the complexity of understanding the schema.
Multiple branches
If the target format of the mapping process is a flat structure like a database or a CSV file, transforming hierarchical and branched XML data into a flat format can be particularly challenging or even impossible. This often involves decisions about how to represent hierarchical data in a flat structure.
The following XML can not be fully flattened into a denormalised structure as it contains multiple branches.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
<University id="TUD"> <Faculty id="Engineering"> <Department id="ComputerScience"> <Course>Introduction to Programming</Course> <Course>Algorithms and Data Structures</Course> </Department> <Department id="ElectricalEngineering"> <Course>Circuit Analysis</Course> <Course>Electromagnetics</Course> <Course>Control Systems</Course> </Department> <ResearchGroup id="ArtificialIntelligence"> <Project>Machine Learning Advances</Project> <Project>Neural Network Optimization</Project> <Project>AI Ethics and Society</Project> </ResearchGroup> <ResearchGroup id="Nanotechnology"> <Project>Nano-materials Engineering</Project> <Project>Quantum Computing</Project> </ResearchGroup> </Faculty> <AdministrativeUnit id="Library"> <Service>Book Lending</Service> <Service>Research Assistance</Service> </AdministrativeUnit> <AdministrativeUnit id="IT"> <Service>Campus Network</Service> <Service>Helpdesk</Service> </AdministrativeUnit> </University> |
Here is the binary tree for this XML
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
University | +-- Faculty | | | +-- Department | | | | | +-- Course | | | +-- ResearchGroup | | | +-- Project | +-- AdministrativeUnit | +-- Service |
As you can see there are multiple branches inside this tree.
Using our free online XML converter Flexter you can convert the data into an optimised structure that balances normalisation and denormalisation.
Let’s have a look at the output of Flexter
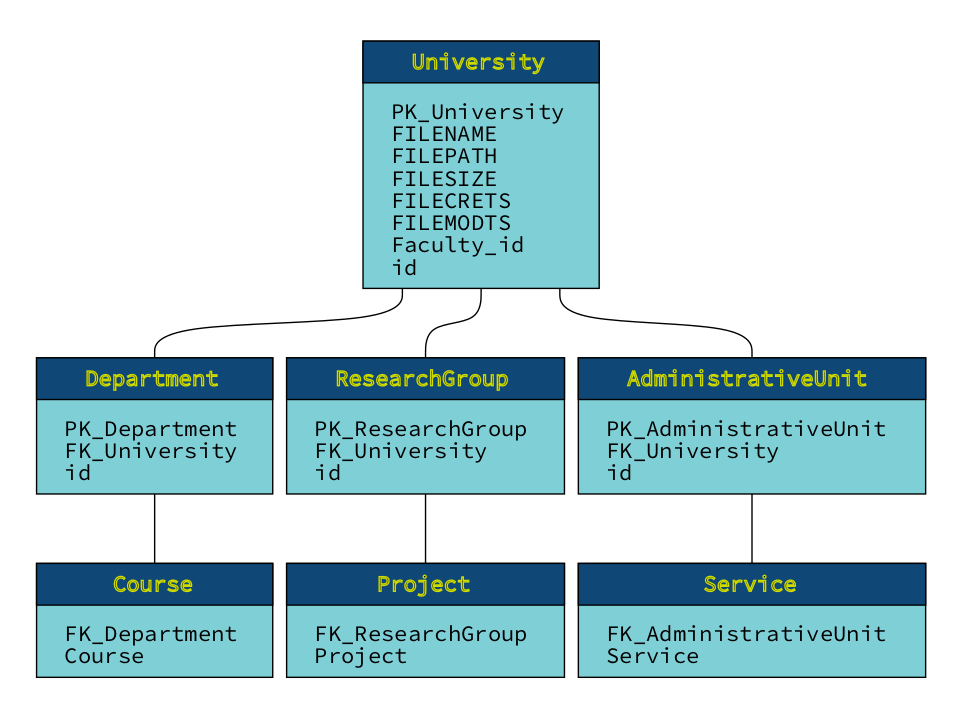
Flexter effectively creates an accurate branching structure from the XML file. You may have noticed that ‘Faculty_id’ was placed inside the University table. This is because in the XML, there’s only one instance of Faculty. Flexter intelligently analyses the data relationships and determines that the connection between University and Faculty is one-to-one. As a result, it incorporates ‘Faculty_id’ into the University table. This approach effectively flattens and simplifies what would otherwise be more complex parent-child relationships, leading to a cleaner and more streamlined target schema.
XSD not available
A further complication arises if no XSD is available at all
Without the guidance of an XSD, there’s a higher risk of misinterpreting the XML data, especially if the XML tags are not self-explanatory or if the data has complex relationships that are not obvious from the XML alone.
If the XML documents vary in structure, identifying and handling these variations can be challenging without a schema to define the allowed differences.
Mapping XML data to other systems (like databases or other XML formats) is more complex without an XSD, as the schema provides a blueprint for such mappings. You’ll need to manually determine the structure and types for proper mapping.
Using Flexter online you can convert XML documents with or without an XSD. For a full overview of all XML conversion options and tools available beyond mapping, the XML converters and conversion guide covers every approach in detail.
XML data volumes and performance
If not done correctly, large XML files or a high quantity of XML data can significantly slow down the processing speed. XML parsing and mapping are resource-intensive tasks, and as the data volume increases, the time and computational resources required to process the data also increase.
Lack of XML skills
XML and its related technologies like XSLT, XQuery, XPath, DOM, and SAX are specialised areas. There are only a few engineers with the deep knowledge required for complex XML conversion projects, and even fewer are interested in developing these skills, often seen as outdated with limited market appeal. Understanding XPath Queries is essential for effectively querying and analysing XML data.
Many developers believe they can easily understand XML and underestimate the complexity of mapping it into another format, such as a relational database. This overconfidence is common, but they quickly find that dealing with complex XML is fraught with challenges.
This skills gap affects every stage of the XML conversion process. Projects can drag on for weeks, months, or we have even seen projects that drag on for years, with multiple failed attempts. This results in crucial data being inaccessible for decision-making.
Analysis and Requirements
Data analysts, proficient in SQL, often lack the expertise to effectively query data trapped in industry-specific XML formats. They typically don’t know XQuery or XSLT, leading to struggles in accurately defining requirements, understanding the data, or identifying data anomalies.
Development
Data engineers are skilled with relational databases and SQL but usually don’t have the expertise to process XML efficiently.
Projects might suffer in terms of quality if the team lacks expertise in XML. Poorly structured XML, inefficient data models, and incorrect use of XML schemas can lead to issues in both the short and long term.
Design and Performance
The skills shortage often leads to solutions that don’t scale effectively. In-house solutions developed by companies might meet functional needs and handle small data volumes, but they often fail with larger datasets or can’t meet Service Level Agreements (SLAs).
Impact of XML mapping challenges
The impact of the challenges outlined is significant.
Data and business analysts get lost in the complexity and size of the XSD and XML. Sometimes the documentation for a set of XSDs that are part of an industry data standard covers several hundred or even several thousand pages.
Data engineers implement solutions of poor quality that are hard to maintain.
Data architects come up with poor designs which lead to performance issues.
This often leads to project failures or projects running over time and budget. More significantly, it indirectly affects the availability of crucial data for business decisions. This lack of data can lead to poor decision-making, ultimately affecting the financial bottom line of an organisation.
XML mapping techniques
XML mapping approaches
There are two primary approaches to XML mapping: automated and manual. Let’s describe and contrast these two approaches.
Manual XML mapping requires human Involvement and coding: This approach involves a person (or team) manually creating the mappings by analysing the XML schema, creating the target format and mapping how each XML element corresponds to the target.
Automated XML mapping involves using specialised software or XML mapping tools that can interpret XML schemas (XSD) and generate mappings automatically or with minimal user input. They can also infer the schema from a sample of XML files in case you don”t have an XSD.
Advantages of automated XML mapping
- Complexity: An automated approach can handle any XML and XSD complexity. It even works for scenarios where you don’t have an XSD.
- Faster go-live: Automated mapping significantly reduces the time required to map large and complex XML files. Data ends up quickly in the hands of decision makers
- Consistency: Ensures uniform mappings across different projects or parts of the same project.
- Scalability: Some tools such as Flexter can scale up and out
- Ease of Use: User-friendly interfaces in automated tools can make the process more accessible. This reduces dependency on specialised skills which can be hard to find and can be a point of vulnerability for a project.
In summary, an automated mapping approach minimises the risk of failing with your XML mapping project.
Steps of XML mapping: Manual versus automated
The following step by step guide contrasts the steps between a manual approach based on coding with an automated approach using Sonra’s enterprise XML converter Flexter.
Explore a practical demonstration of Flexter’s capabilities in mapping complex XML into a relational database format by watching our hands-on video demo.
In this example we cover the steps to create a mapping and conversion from XML documents to a relational database. While these steps closely resemble those used for mapping XML to other formats, there may be some differences in the finer details.
|
Manual approach using code |
Automated approach with Flexter |
|---|---|
|
Step 1: Analysis to understand structure of XML and XSD | |
|
For complex schemas this process can be super time consuming. The analysis can take more time than all the other steps combined. Go through documentation of industry data standard if available. Understanding XML Schema/Structure. Pinpoint the main elements, attributes, and their hierarchies within the XML. Understand how different elements and attributes relate to each other. Identify any hierarchical structures, such as parent-child relationships, within the XML data. Checking for Repeating and Optional Elements: Identify elements that occur multiple times and understand their significance. Note any optional elements that may or may not appear in the XML. Understanding Namespaces Evaluate the size of the XML files and the complexity of the structure, as this will impact the mapping process. Evaluate XML for Anomalies or Irregularities | Running a single command covers steps 1-3 This creates a Flexter Data Flow, which analyses the XSD and/or XML, creates a relational target data model, and creates the mappings between XML source elements and target table columns Option 1: Generating a data flow from an XML. We apply the elevate and reuse optimisation algorithm (g3 switch) $ xml2er -g3 donut.xml Option 2: Generating a Data Flow from an XSD $ xsd2er -g3 donut.xsd Option 3: Generating a Data Flow from an XML and XSD to get the best of both worlds $ xml2er donut.xml $ xsd2er -a4 -g3 donut.xsd In this example we create the Data Flow from the command line. You can also use the Flexter API or Flexter UI to create a Data Flow. |
|
Step 2: Model and create target schema | |
|
Once you have completed the analysis you need to use your findings to create a relational schema for the target format. Translate between the hierarchical structure to the relational format Map data types Define and implement naming and naming conventions Define and implement parent-child relationships Define and implement constraints |
Already covered under Step 1 |
|
Step 3: Create mapping | |
|
Manually map the XML elements to the target table columns |
Already covered under Step 1 |
| Step 4: XML Conversion | |
| This is another very time consuming step. Developers write the code to convert the data that is locked away in XML to the relational database tables and columns. | A single command is run to convert the data. The switch l3 references the ID of the Data Flow that was generated in the previous step. $ xml2er -l3 donut.zip In this example we create the XML Conversion from the command line. You can also use the Flexter API or Flexter UI to convert the XML. |
|
Step 5: Error handling and alerting | |
|
In XML mapping error handling, there are two crucial checks to perform. Firstly, ensure that the XML to be converted is valid. Secondly, verify that the XML adheres to the target schema. This means it should not have any additional XML elements and must comply with the specified data types. |
This is automatically handled as part of Step 4 XML Conversion |
|
Step 6: Documentation | |
|
The most important documentation artefact is a Source to Target Map (STM). The STM acts as a blueprint that defines how each piece of data is transformed and transferred from the source to the target. It specifies how each field in the XML corresponds to the target including any data type conversions. |
Already covered under Step 1 When creating the Data Flow Flexter stores all of the information in its metadata catalog. The metadata can then be used to auto generate Source to Target Maps, ER diagrams, and diffs and deltas between different versions of a schema. |
|
Step 7: Refactoring for changes | |
|
If changes are made to the XML or the XML schema you need to repeat steps 1-6 to cater for the change |
Flexter ships with a metadata store that semi-automates the upgrade between different versions of an XML or XSD. |
The figure below represents a Source to Target Map that maps an XML source document to a relational target schema.

The figure below shows a sample ER diagram of the relational target schema generated by Flexter.
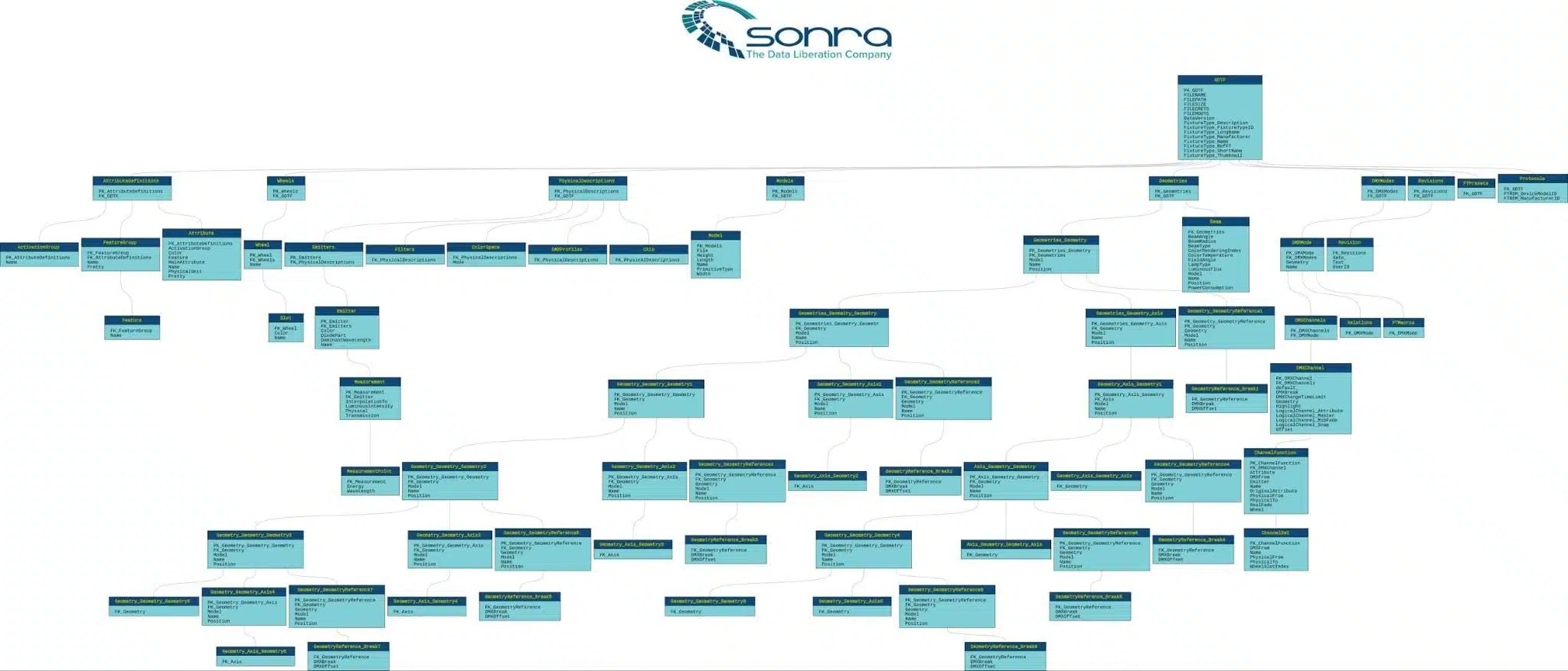
Automated XML mapping: Knowing when it’s the right option
Using a tool to automate the XML mapping and conversion process has many advantages. Let’s quickly summarise the benefits:
- Quicker implementation: The process enables faster project completion and go-live times.
- Scalable solution: It’s designed to handle varying data volumes and meet specific Service Level Agreements (SLAs) efficiently.
- Versatility in Handling Complexity: The system can manage any level of complexity and any type of XML or XSD.
- Reduced need for specialised skills: There’s no need for rare XML expertise, nor is there a requirement for additional staff training.
- Less code refactoring: The approach minimises the need for code changes in response to changes.
- Lower risk of project failures or budget overruns: It significantly reduces the likelihood of project delays and budgetary issues.
However, all of these benefits have to be weighed against the additional licence costs of the XML mapping software. Purchasing an off the shelf XML mapping software is overkill for the following scenarios:
- If your XML / XSD is complex, go for an automated solution using an enterprise XML converter.
- If your XML / XSD is simple but you have at least 5 different types of XML documents and schemas opt for an automated solution
- If your XML is simple opt for a manual approach
If your criteria tell you to opt for an automated solution you should consider and evaluate Flexter. Our XML mapping and conversion tool is the only tool that fully automates and optimises the mapping process.
Try Flexter online for yourself, have a look at our product and product data sheet page, or book a Flexter demo to find out more.