Mastering SQL: How to detect and avoid 34+ Common SQL Antipatterns

Overview
Are you looking for reasons why your SQL queries are slow or costly. Look no more. This blog post showcases a comprehensive list of 34 SQL antipatterns. Use it as a reference to improve your own SQL queries.
What is an SQL antipattern?
SQL antipatterns can lead to poor performance, maintainability issues, and incorrect results in database applications. They are practices or patterns that should be avoided in favor of more efficient and effective SQL query and database design approaches.
What are the benefits of fixing SQL antipatterns?
Detecting SQL antipatterns is called SQL analysis. SQL analysis inspects SQL code for common mistakes and antipatterns. It is not just a technical exercise. It has a direct impact on the bottom line of a business. It directly contributes to the operational efficiency, cost-effectiveness, and strategic agility.
Here is a list of the main benefits of SQL analysis.
- Quality Assurance: SQL code analysis helps ensure the quality and consistency of SQL code, which is crucial for reliable database operations.
- Cost Reduction: By identifying issues like syntax errors, potential performance inefficiencies, or deviations from coding standards, businesses can avoid costly runtime errors and system downtimes.
- Time Efficiency: Developers can quickly identify and rectify issues before the code goes into production, saving time and resources.
- Scalability: Ensures that the SQL code is scalable and maintainable, which is important for businesses as they grow and handle more data.
- Resource Management: SQL code analysis helps in optimizing the use of database resources, which can lead to cost savings, especially in cloud-based or pay-per-use environments.
- Data Accuracy: It ensures that the SQL code not only runs but also produces the correct and expected results, which is crucial for business decision-making
Not convinced yet?
The next section goes through a case study of a real world example to show you the differences hands on. SQL analysis can have a direct impact on the bottom line.
SQL antipattern case study. Slashing Compute Costs. Preventing Database Meltdown.
JOIN explosion is a phenomenon in databases that can have adverse effects on query performance and system resources. It occurs when multiple tables are joined in a way that results in a much larger number of rows than expected. Here are the most important adverse effects of join explosion:
- Increased Compute Costs: Join explosion significantly increases the computational load on the database server. When tables are joined, each row in one table is combined with every row in the other table, resulting in a large number of intermediate rows to process.
- As the number of rows in the result set grows exponentially due to join explosion, query performance can degrade significantly. Queries can become extremely slow and may time out or never complete.
- Resource Consumption: Join explosion consumes significant system resources, including CPU, memory, and disk space. This can lead to resource contention, slowing down other database operations and causing system-wide performance meltdown.
- Risk of Data Inaccuracy: Join explosion can lead to incorrect results if not handled properly. Duplicate or incomplete data may be generated in the result set, leading to data quality issues.
We scanned the query history of a client and came across the following SQL code. In this case a small difference can have a huge impact.
The mistake of the SQL developer was to mix up the table alias names resulting in an incorrect join and the dreaded join explosion.
|
Bad SQL* |
Good SQL | |
|---|---|---|
|
SQL Code |
SELECT * FROM PATIENT PT LEFT JOIN CEXAM CE ON PT.CLINIC_NM=CE.CLINIC_NM AND PT.CEXAMID=CE.CEXAMID LEFT JOIN CTEST CT ON PT.CLINIC_NM=CE.CLINIC_NM AND PT.TESTID=CT.TESTID |
SELECT * FROM PATIENT PT LEFT JOIN CEXAM CE ON PT.CLINIC_NM=CE.CLINIC_NM AND PT.CEXAMID=CE.CEXAMID LEFT JOIN CTEST CT ON PT.CLINIC_NM=CT.CLINIC_NM AND PT.TESTID=CT.TESTID |
|
Execution time |
30 minutes |
5 seconds |
|
Cost savings |
99.75% | |
We created FlowHigh for SQL analysis.
Use FlowHigh SQL Analyser to protect you from bad performance and incorrect query results.
34 of the most common SQL Antipatterns.
Below is a comprehensive list of common antipatterns sorted by severity. FlowHigh has three levels of severity:
- Level 1 – Warning
- Level 2 – Caution
- Level 3 – Notice
The greater the severity level, the more significant the impact on SQL performance and, in some cases, the accuracy of the data output.
Antipatterns that trigger a warning
Avoid ANSI-89 join syntax
Type
Readability
Problem
The ANSI-89 Join syntax of joining tables in the WHERE clause is difficult to read and has been superseded in the ANSI-92 release of the standard by a more readable syntax. In particular, the (+) operator used in Oracle to define Outer Joins can be confusing because its use is not intuitive.
|
1 2 3 4 5 6 7 |
SELECT sc.customerid ,sc.customername ,sb.buyinggroupname ,sb.deliverymethodname FROM sales_customers sc ,sales_buyinggroups sb WHERE sc.buyinggroupid(+)=sb.buyinggroupid |
Solution
Only use the ANSI-92 compliant join syntax.
|
1 2 3 4 5 6 7 8 |
SELECT sc.customerid ,sc.customername ,sb.buyinggroupname ,sb.deliverymethodname FROM sales_customers sc LEFT JOIN sales_buyinggroups sb ON sc.buyinggroupid=sb.buyinggroupid |
Legitimate use of the anti pattern
None
Avoid count(*) in the outer join
Type
Performance
Correctness
Problem
All rows—including those in the outer join—are counted when the COUNT(*) aggregate function is used in an outer join. The count of the outer rows is typically not something you want to include in your query.
|
1 2 3 4 5 6 7 8 |
SELECT a.product _name ,COUNT(*) num_orders FROM product a LEFT JOIN orders b ON a.product_id=b.product_id GROUP BY a.product_name |
With this query, we want to count the number of orders for each product. If the query uses count(*), it will also count products that don’t have any orders. The result of the query will be wrong and not what was expected.
|
product_name |
product_id |
order_id |
|---|---|---|
|
sofa |
1 |
1 |
|
sofa |
1 |
2 |
|
chair |
2 |
NULL |
The query would return the following result:
|
product_name |
num_orders |
|---|---|
|
sofa |
2 |
|
chair |
1 |
Solution
You can fix this by using the count(<column_name>) function. For <column_name>, give a column that can’t be NULL from the table with non preserved rows (the table in the outer join). A primary key column is an example.
|
1 2 3 4 5 6 7 8 |
SELECT a.product _name ,COUNT(b.order_id) num_orders FROM product a LEFT JOIN orders b on a.product_id=b.product_id GROUP BY a.product_name |
Legitimate use of the anti pattern
None
Avoid nesting scalar subqueries in the SELECT statement
Type
Performance
Readability
Correctness
Problem
Scalar subqueries have an impact on readability and performance when used in a SELECT statement.
|
1 2 3 4 5 6 7 |
SELECT purchaseorderid ,orderdate ,deliverymethodid ,(SELECT deliverymethodname FROM application_deliverymethods dm WHERE dm.deliverymethodid=ppo.deliverymethodid) FROM purchasing_purchaseorders ppo; |
Solution
Most of the time, you can change a scalar subquery in a SELECT statement into a join.
|
1 2 3 4 5 6 7 8 |
SELECT ppo.purchaseorderid ,ppo.orderdate ,ppo.deliverymethodid ,dm.deliverymethodname FROM purchasing_purchaseorders ppo LEFT OUTER JOIN application_deliverymethods dm ON ppo.deliverymethodid=dm.deliverymethodid |
Legitimate use of the anti pattern
None
Avoid filtering attributes from the non-preserved side of an outer join
Type
Correctness
Problem
Trying to filter the non preserved side of an outer join is a bug in the logic of your code. The WHERE clause filters out unknown values. This means that all outer rows will be filtered out irrespectively. In essence you nullify the outer join.
|
1 2 3 4 5 6 7 |
SELECT a.col1 ,b.col2 FROM Customer a LEFT JOIN orders b ON a.customer_id = b.customer_id WHERE b.order_number <> 'x2345' |
The value ‘x2345’ for the OrderID column in the Orders table filters out all rows from the OrderDetails table, implicitly converting your outer join to an inner join.
Solution
Rewrite your logic to cater for NULLs
|
1 2 3 4 5 6 7 8 |
SELECT a.col1 ,b.col2 FROM Customer a LEFT JOIN orders b ON a.customer_id=b.customer_id WHERE b.order_number<>'x2345' OR b.order_number IS NULL |
An alternative solution would replace NULLs with a dummy value and then check against the dummy value. This solution is less readable than the previous solution
|
1 |
WHERE COALESCE(b.order_number,'unique')<>'x2345' |
If you only wanted to show customers whose names were in the order table, you should make your outer join an inner join.
|
1 2 3 4 5 6 7 |
SELECT a.col1 ,b.col2 FROM Customer a INNER JOIN orders b ON a.customer_id=b.customer_id WHERE b.order_number<>'x2345' |
Legitimate use of the anti pattern
The only time when putting a condition in the WHERE clause does not turn a LEFT JOIN into an INNER JOIN is when checking for NULL
Beware of filtering for NULL
Type
Correctness
Problem
Many software developers are caught off-guard by the behaviour of NULL in SQL. Unlike in most programming languages, SQL treats NULL as a special value, different from zero, false, or an empty string.
In SQL, a comparison between a NULL value and any other value (including another NULL) using a comparison operator, e.g. =, !=, < will result in a NULL, which is considered as false for the purposes of a where clause (strictly speaking, it’s “not true”, rather than “false”, but the effect is the same).
The reasoning is that a NULL means “unknown”, so the result of any comparison to a NULL is also “unknown”. So you’ll get no hit on rows by coding where my_column = NULL.
Incorrect usage of NULL with comparison operato
|
1 2 3 4 5 |
SELECT a ,b ,c FROM table_1 WHERE a=NULL |
Solution
SQL provides the special syntax for testing if a column is NULL, via IS NULL and IS NOT NULL, which is a special condition to test for a NULL (or not a NULL).
Correct usage of NULL with IS NULL operator
|
1 2 3 4 5 |
SELECT a ,b ,c FROM table_1 WHERE a IS NULL |
Legitimate use of the anti pattern
None
Avoid implicit column references
Type
Readability
Correctness
Problem
Don’t use implicit columns references in queries with multiple table joins.
|
1 2 3 4 5 |
SELECT col3 ,col4 FROM tableA a JOIN tableB b ON col1=col2 |
In the example above it is not clear if the columns col1, col2, col3, col4 belong to tableA or tableB. Readability suffers and you increase the risk of introducing bugs in the code.
Solution
Explicitly reference each column
|
1 2 3 4 5 |
SELECT a.col3 ,b.col4 FROM tableA a JOIN tableB b ON a.col1=b.col2 |
In this example each column is referenced by its table alias.
Legitimate use of the anti pattern
If you only have one table in your query you can use implicit column references.
Avoid inner join after outer join in multi-join query
Type
Correctness
Problem
If an outer join is followed by an inner join, all rows from the outer join are thrown away if the predicate in the inner join’s ON clause compares an attribute from the non-preserved side of the outer join and an attribute from a third table. Let’s go through an example
|
1 2 3 4 5 6 7 8 9 |
SELECT a.col1 ,b.col2 FROM Customer a LEFT JOIN orders b ON a.customer_id=b.customer_id INNER JOIN order_line c ON b.order_id=c.order_id |
In this query, we left outer join the orders table to the customer table and then inner join the order_line table to the orders table. As a result, only preserved rows from both tables were retained in the result set. In other words we implicitly converted the outer join to an inner join.
The preceding query is equivalent to the following query
|
1 2 3 4 5 6 7 8 9 |
SELECT a.col1 ,b.col2 FROM Customer a INNER JOIN orders b ON a.customer_id=b.customer_id INNER JOIN order_line c ON b.order_id=c.order_id |
Solution
Do not use an inner join against a non preserved table. Here is the correct query to preserve the rows of the order table.
|
1 2 3 4 5 6 7 8 9 |
SELECT a.col1 ,b.col2 FROM orders a INNER JOIN order_line b ON a.order_id=b.order_id RIGHT JOIN customer c ON a.customer_id=c.customer_id |
Legitimate use of the anti pattern
None
Avoid implicit cross join
Type
Readability
Correctness
Problem
It is possible to generate a cartesian product using CROSS JOINs. However, you should avoid writing implicit CROSS JOINS with the ANSI-89 syntax.
|
1 2 3 4 |
SELECT t1.col1 ,t2.col1 FROM t1 ,t2 |
Tables t1 and t2 are cross joined implicitly without specifying the CROSS JOIN clause.
By using the implicit CROSS JOIN syntax you run the risk of creating cartesian products by accident. This can be catastrophic for query performance and might even crash your database.
Solution
Follow the ANSI-92 SQL syntax when writing explicit CROSS JOINs by using the CROSS JOIN syntax.
|
1 2 3 4 5 |
SELECT t1.col1 ,t2.col1 FROM t1 CROSS JOIN t2 |
Legitimate use of the anti pattern
Never use the implicit CROSS JOIN syntax
Use an alias for derived columns
Type
Readability
Problem
Any derived value, including aggregates, should be given a unique name unless the query is completely ad hoc. The query is now easier to read. The alias may be directly referred to in the filter if the database engine supports it.
|
1 2 3 4 5 |
SELECT col1 ,SUM(col2*1.23) FROM sales GROUP BY col1 HAVING SUM(col2*1.23)>10500 |
Solution
We assign SUM(col2*1.23) the alias gross_price. We use the alias gross_price in the HAVING filter.
|
1 2 3 4 5 |
SELECT col1 ,SUM(col2*1.23) gross_price FROM sales GROUP BY col1 HAVING gross_price>10500 |
Note: Using the alias in the HAVING clause is not supported by all databases.
Legitimate use of the anti pattern
None
Beware of NULL in combination with not equal operator (!=, <>)
Type
Correctness
Problem
When filtering with the Not Equal operator (!=, <>) rows with NULL values in the filtered column are not returned.
Let’s go through an example.
Table with sample data
| customer_id | age |
|---|---|
| 1 | NULL |
| 2 | 18 |
| 3 | 25 |
The following query only returns the row with customer_id 3. It does not return the row with cutsomer_id 1. For this row the age is unknown (NULL) and we don’t know what the age is. It may be 18 or it may not be 18.
|
1 2 3 |
SELECT customer_id FROM customer WHERE age<>18 |
|
1 2 3 |
SELECT car_name FROM car WHERE car_type NOT IN('Coupe') |
The query will skip the cars which don’t have their type defined, irrespectively whether that was intentional or not.
Solution
However, if the intention is to also return records where we know the customer age is not 18 (so not 18 or where we don’t know the age of the customer) then we need to rewrite our query:
|
1 2 3 4 |
SELECT customer_id FROM customer WHERE age<>18 OR age IS NULL |
The ANSI SQL 99 standard also introduced the IS DISTINCT FROM function. However, it is not supported by all database vendors
|
1 2 3 |
SELECT customer_id FROM customer WHERE age IS DISTINCT FROM 18; |
|
1 2 3 4 |
SELECT car_name FROM car WHERE car_type NOT IN('Coupe') AND car_type is NOT NULL |
Legitimate use of anti pattern
The anti pattern is legitimate if we want to exclude records where the age is unknown (NULL) from our result set.
If the column has a NOT NULL constraint then you can possibly ignore the anti pattern. However, in the spirit of a defensive programming style it is good practice to cater for NULLs. The business rule might change and the NOT NULL constraint dropped in the future.
Avoid unused Common Table Expressions (CTE)
Type
Performance
Readability
Problem
One of the Common Table Expressions (CTEs) that the query defines is not used anywhere else in the query.
Example
The CTE sum_students has been defined but is not referenced in other parts of the query. Only avg_students has been referenced in the query
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
WITH avg_students AS( SELECT district_id ,AVG(fee) AS average_students FROM schools GROUP BY district_id) ,sum_students AS( SELECT district_id ,SUM(fee) AS sum_students FROM schools GROUP BY district_id) SELECT s.school_name ,s.district_id ,avg.average_students FROM schools s JOIN avg_students avgs ON s.district_id=avgs.district_id |
There are two issues:
- Including an unused CTE makes the query more complex and less readable. It may confuse other SQL developers
- It may cause a performance degradation with some databases. Some databases materialise CTEs by default. Other databases inline the CTE. When the database materialises the CTE it will set down the resultset physically or in memory. For some databases you can specify if you want to materialise or inline a CTE. Materialising a resultset allows the database to reuse the result multiple times. Some databases even materialise the resultset of unreferenced CTEs. This requires extra work for no good reason.
Solution
Remove CTEs that aren’t being used, or at least comment them out for future use.
Legitimate use of the anti pattern
None.
Avoid the natural join clause
Type
Readability
Correctness
Problem
The SQL natural join is a type of equi-join that implicitly combines tables based on columns with the same name and type. The join predicate arises implicitly by comparing all columns in both tables that have the same column names in the joined tables.
The following issues may arise:
- You may accidentally join on the wrong columns, e.g. it is common to add a generic column create_date_time to tables. The natural join would include these column in the join which is most likely incorrect
- It takes the CBO extra time to parse the query to identify the join column candidates
- It reduces readability by introducing a non-standard syntax
|
1 2 3 4 5 |
SELECT col1 FROM d1 NATURAL INNER JOIN d2 |
Solution
Use an ANSI-92 compliant join syntax
|
1 2 3 4 5 |
SELECT col1 FROM d1 INNER JOIN d2 ON(d1.id=d2.id) |
Legitimate use of the anti pattern
None
Use LIKE instead of REGEX where LIKE is possible
Type
Performance
Problem
The regular expression engine is much more powerful than the LIKE operator when it comes to pattern matching. However, the regular expression engine requires significantly more resources than LIKE. Whenever you use a regular expression in a filter (WHERE clause), you should carefully assess whether a particular regular expression pattern has its LIKE equivalent or if available LIKE functionality is enough to meet your specific filtering requirement.
|
1 2 3 |
SELECT * FROM tableX WHERE col1 RLIKE 'DOMAIN.+END' |
|
1 2 3 4 5 |
SELECT * FROM tableY WHERE REGEXP_LIKE(col2 ,'DOMAIN.{3} ) |
Solution
We have rewritten the queries using the regular expression with LIKE
|
1 2 3 |
SELECT * FROM tableX WHERE col1 LIKE 'DOMAIN%END%'] |
|
1 2 3 |
SELECT * FROM tableY WHERE col2 LIKE '%DOMAIN___' |
Legitimate use of the antipattern
The following regular expression can not be rewritten with LIKE
|
1 2 3 |
SELECT * FROM tableX WHERE col1 RLIKE 'DOMAIN\s+(alpha|beta)[0-9A-z]_?END' |
Avoid using WHERE to filter aggregate columns
Type
Performance
Readability
Problem
The WHERE clause in combination with a subquery can be used instead of the HAVING clause.
This makes the query hard to read and more complex.
|
1 2 3 4 5 6 7 |
SELECT col1 ,sum_col2 FROM( SELECT col1 ,SUM(col2) sum_col2 FROM table1 GROUP BY col1) WHERE sum_col2>10 |
Solution
Use the HAVING clause when filtering on aggregates
|
1 2 3 4 5 |
SELECT col1 ,SUM(col2) FROM table1 GROUP BY col1 HAVING SUM(col2)>10 |
Legitimate use of the anti pattern
None
Antipatterns that trigger a Caution
Beware of SELECT *
Type
Performance
Readability
Problem
Whenever a developer uses SELECT *, they commonly pick more columns than they need. Without any justification, the database must free up more system resources. The use of this anti-pattern could cause performance problems, reduce concurrency, and increase costs.
The SELECT * anti pattern has the following impact
- When columns are renamed or dropped, downstream processes may break in your data engineering and BI work loads
- More database resources need to be used to scan data at the table level. The impact is significantly worse for databases with columnar storage.
- More data travels across the network
- Running SELECT * is expensive. Some database providers, like Google BigQuery, charge customers according to the volume of data accessed. It can literally cost you hundreds of dollars to run a query across a TB-sized table with dozens of columns when we only need four or five. While the extra cost for BigQuery is obvious, you will pay comparable compute costs with other database vendors and have fewer resources available for other users.
Solution
- Fix the anti pattern for small tables that are part of an ETL or BI application.
- Apply the LIMIT clause to only retrieve a subset of the data for data exploration use cases. The implementation of LIMIT differs by database vendor and you are advised to consult the explain plan.
SQL without LIMIT takes minutes on a 500 GB table
|
1 2 3 4 |
SELECT * FROM web_sales a JOIN item b ON(a.ws_item_sk=b.i_item_sk) |
SQL with LIMIT takes milliseconds for the same query
|
1 2 3 4 5 |
SELECT * FROM web_sales a JOIN item b ON(a.ws_item_sk=b.i_item_sk) LIMIT 100 |
Example SQL was created and tested on Snowflake
- Even if we know the names of the columns we need to retrieve it is much quicker to write SELECT * instead of spelling out each individual column. An SQL IDE with autocomplete feature can minimise the amount of work.
Legitimate use of the anti pattern
If this anti pattern appears during data exploration or data discovery, you can ignore it for small tables. The extra expense is probably less than the time you must spend on data engineering if you write out the full column names
For data exploration and data discovery use cases you may need to browse all of the columns in a table to get a better understanding of the data.
Avoid using functions in the WHERE clause
Type
Performance
Problem
There are two reasons to avoid using a function on a column inside a WHERE clause.
- It is CPU intensive because the function gets called for each record in your result set.
- It prevents the database from applying an index, sort key or cluster key. As a result, the database needs to read more data from the storage layer. This can have a significant impact on query performance.
The following example demonstrates the anti-pattern in SQL Server. A function wraps around the date_of_birth column.
|
1 2 3 4 5 |
SELECT emp FROM employee WHERE DATEADD(d ,30 ,date_of_birth)>GETDATE(); |
Solution
Rewrite your query to push the function to the other side of the operator.
|
1 2 3 |
SELECT emp FROM employee WHERE date_of_birth > dateadd(d,-30,getdate()) |
One alternative to this would be to pre-calculate the function as part of ETL.
In some databases, such as Oracle, you can create indexes based on functions.
Legitimate use of the anti pattern
- In some situations, you may not be able to avoid using the function in the WHERE clause.
- Your data volumes are small.
- The column you filter against does not have an index or cluster key
- You have created a function based index for the function on the column
Beware of NULL with arithmetic and string operations
Type
Correctness
Problem
Using arithmetic and string operations on NULLable columns could have side effects that you didn’t plan for.
Table with sample data:
| customer_id | first_name | middle_name | last_name | age |
|---|---|---|---|---|
| 1 | hans | peter | wurst | NULL |
| 2 | edgar | NULL | uelzenguelz | 18 |
We concatenate the first_name, middle_name and last_name to illustrate the anti pattern for string operations.
|
1 2 3 4 5 |
SELECT customer_id ,CONCAT(first_name ,middle_name ,last_name) AS full_name FROM customer |
As the middle_name is unknown for customer_id 2 the concat string operation also results in an unknown value (NULL). We might have expected “edgar uelzenguelz” as the full name for that customer_id
| customer_id | full_name |
|---|---|
| 1 | hans peter wurst |
| 2 | NULL |
Solution
We recommend using a defensive programming style when writing SQL queries. As a rule, you should always assume any column can be NULL at any point. It’s a good idea to provide a default value for that column. This way you make sure that even if your data becomes NULL the query will work.
For the string operation we can use the COALESCE function to achieve our objective
|
1 2 3 4 5 6 7 8 |
SELECT customer_id ,CONCAT(first_name ,' ' ,COALESCE(middle_name ,'') ,' ' ,last_name) AS full_name FROM customer |
If you want to be very careful, you can use COALESCE for all of the columns in the string concatenation, not just the ones that can be NULL. This will make sure that your code will still work even if the NULLability of a column changes.
|
1 2 3 4 5 6 7 8 |
SELECT customer_id ,CONCAT(first_name ,' ' ,COALESCE(middle_name ,'') ,' ' ,last_name) AS full_name FROM customer |
Legitimate case
The columns used in the expression are NOT NULLable.
Beware of implicit self-joins in a correlated subquery
Type
Performance
Readability
Problem
Using an implicit self-join in a correlated subquery in the WHERE clause can cause two problems.
- Most SQL developers find correlated subqueries difficult to read or debug.
- Using a correlated subquery may cause a performance issue.
An example. The employee table is used both in the outer and inner query
|
1 2 3 4 5 6 7 |
SELECT lastname ,firstname ,salary FROM employee e1 WHERE e1.salary>(SELECT avg(salary) FROM employee e2 WHERE e2.dept_id=e1.dept_id) |
Solution
Using a window function instead of an implicit self-join will improve the query performance for most cases and also make it easier to understand.
|
1 2 3 4 5 6 |
SELECT lastname ,firstname ,salary ,AVG(salary) OVER(PARTITION BY dept_id) AS avg_sal FROM employee QUALIFY salary>avg_sal |
If your database does not support the QUALIFY operator use a subquery
|
1 2 3 4 5 6 7 8 9 |
SELECT lastname ,firstname ,salary FROM( SELECT lastname ,firstname ,salary ,AVG(salary) OVER(PARTITION BY dept_id) AS avg_sal FROM employee) WHERE salary>avg_sal |
Legitimate use of the anti pattern
In some edge situations the implicit self-join can be more performant. The window function is generally more performant under the following conditions
- You are dealing with a non-equi join, e.g. >, <, >=, <=. For Non-equi joins the CBO can not use a hash join, which may impact performance.
- The columns involved in the join condition do not contain indexes or cluster keys.
- In a self join, there are no table partitions on the columns involved in the join.
- The self join table is large and has not been reduced on one side of the join by filtering or aggregation. In the example above the inline view has been reduced by aggregation. The resulting self-join is less expensive and may be legitimate.
It is a good idea to run a performance test to compare performance of the query with the self join to the performance of the window function.
Use IN / NOT IN for multiple OR operators
Type
Readability
Problem
Chaining multiple OR operators makes SQL code less readable
|
1 2 3 4 5 |
SELECT col1 FROM t1 WHERE c1=9 OR c1=5 OR c1=10 |
Solution
Use the IN / NOT IN operator instead of chaining OR operators. It makes your SQL code more readable.
|
1 2 3 4 5 |
SELECT col1 FROM t1 WHERE c1 IN(9 ,5 ,10) |
Legitimate use of the anti pattern
None
Avoid ordinal numbers when using ORDER BY or GROUP BY
Type
Readability
Correctness
Problem
You can order or group the result set based on the ordinal positions of columns that appear in the SELECT clause
ORDER BY
|
1 2 3 4 5 6 7 |
SELECT col1 ,col2 ,col3 FROM table ORDER BY 1 ,2 ,3 |
GROUP BY
|
1 2 3 4 |
SELECT col1 ,COUNT(9) FROM table GROUP BY 1 |
Using the ordinal positions of columns in the ORDER BY / GROUP BY clause is considered an anti pattern
- Your SQL becomes much harder to read for other people
- When you modify the SELECT list, you may forget to make the corresponding changes in the ORDER BY / GROUP BY clause, which will result in errors and bugs.
Solution
Always reference columns by their name and not their ordinal position.
ORDER BY
|
1 2 3 4 5 6 7 |
SELECT col1 ,col2 ,col3 FROM table ORDER BY col1 ,col2 ,col3 |
GROUP BY
|
1 2 3 4 |
SELECT col1 ,COUNT(9) FROM table GROUP BY col1 |
Legitimate use of the anti pattern
For ad hoc queries where you need to quickly write up some SQL that you don’t share with other developers and then discard, the anti pattern is legitimate.
Split multi join queries into smaller chunks
Type
Performance
Readability
Problem
The human brain can only store a small set of items in short term memory. That’s why we break longer pieces of information into smaller parts. This is commonly referred to as chunking, e.g. when we break up a long phone number into smaller pieces of information to remember it. The same problem exists with SQL when dealing with a large number of table joins. It gets hard for people to read, understand, and debug the code. As a rule of thumb we should not join more than five tables at a time. If possible, even reduce the number of tables you join to 3-4.
You may also get performance issues when joining a large number of tables. Each time you add a new table join, the number of possible explain plans that the CBO needs to look at grows exponentially. The optimizer might get overwhelmed as it does not have enough time to explore all of the possible plans. This may lead to poor explain plans and poor performance.
Solution
As a rule of thumb we should not join more than 5 tables together at a time. For queries with a large number of tables you should break down the query into smaller chunks that are easier to read and debug.
You can do this by using Common Table Expressions (CTE) or inline views. Let’s go through an example query with overloaded joins.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT sb.buyinggroupname ,SUM(sordl.quantity*sordl.unitprice) total_sales ,SUM(sinvl.quantity*sinvl.unitprice) total_invoice FROM SALES_CUSTOMERS sc LEFT JOIN SALES_BUYINGGROUPS sb ON sc.buyinggroupid=sb.buyinggroupid LEFT JOIN APPLICATION_DELIVERYMETHODS ad ON sc.DELIVERYMETHODID=ad.DELIVERYMETHODID LEFT JOIN SALES_ORDERS sord ON sc.customerid=sord.customerid LEFT JOIN SALES_ORDERLINES sordl ON sord.orderId=sordl.orderid LEFT JOIN SALES_INVOICES sinv ON sord.orderid=sinv.orderid LEFT JOIN SALES_INVOICELINES sinvl ON sinv.invoiceid=sinvl.invoiceid GROUP BY sb.buyinggroupname |
In this query we join seven tables. The query becomes hard to understand and debug. Let’s break it up into smaller chunks.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
WITH customer AS( SELECT sc.customerid ,sc.customername ,sb.buyinggroupname ,ad.deliverymethodname FROM SALES_CUSTOMERS sc LEFT JOIN SALES_BUYINGGROUPS sb ON sc.buyinggroupid=sb.buyinggroupid LEFT JOIN APPLICATION_DELIVERYMETHODS ad on sc.DELIVERYMETHODID=ad.DELIVERYMETHODID) ,sales_order AS( SELECT sord.orderid ,sord.customerid ,sordl.quantity ,sordl.unitprice ,sordl.taxrate ,sordl.stockitemid ,sordl.orderlineid FROM SALES_ORDERS sord JOIN SALES_ORDERLINES sordl ON sord.orderId=sordl.orderid) ,invoice AS( SELECT sinv.invoiceid ,sinv.customerid ,sinv.orderid ,sinvl.invoicelineid ,sinvl.quantity ,sinvl.unitprice FROM SALES_INVOICES sinv JOIN SALES_INVOICELINES sinvl ON sinv.invoiceid=sinvl.invoiceid) SELECT customer.buyinggroupname ,SUM(sales_order.quantity*sales_order.unitprice) total_sales ,SUM(sales_order.quantity*sinvl.unitprice) total_invoice FROM customer LEFT JOIN sales_order ON customer.customerid=sales_order.customerid LEFT JOIN invoice ON sales_order.orderid=invoice.orderid GROUP BY customer.buyinggroupname |
We have broken the query up into three logical parts
- Information related to customer
- Information to sales
- Information to invoice
Using a CTE we can query each of the components separately for debugging purposes. Let’s look at visual representation of the query
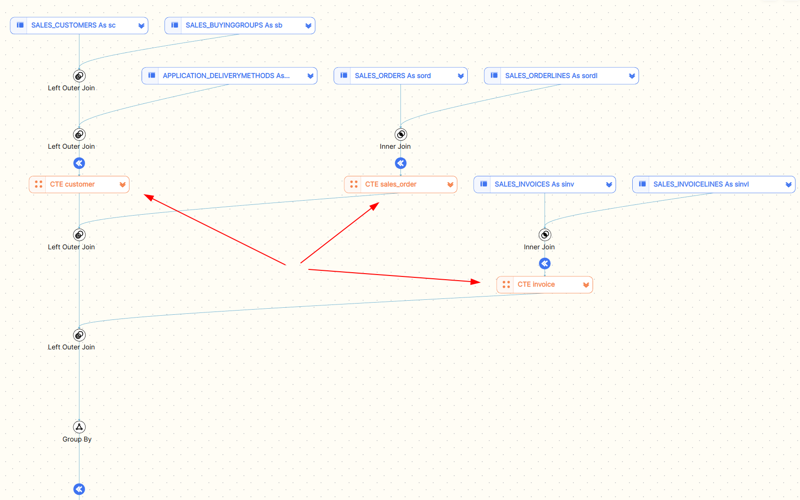
Visual representation of the query
Let’s zoom in on customer CTE
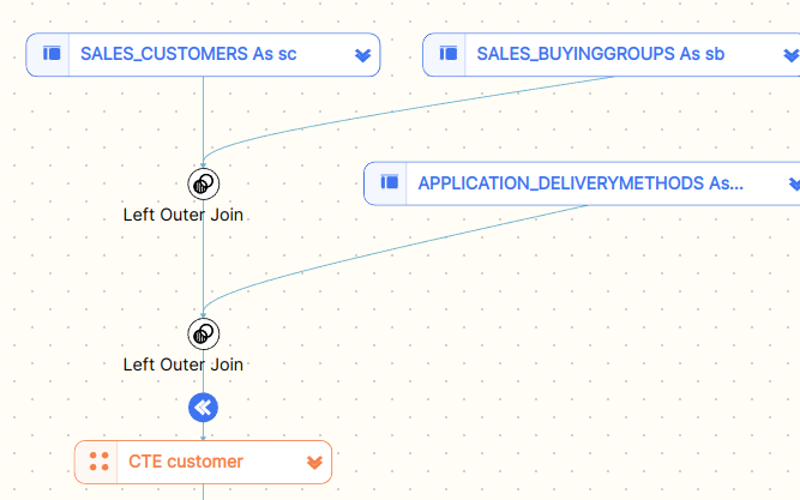
Customer CTE
We can collapse the CTEs

Collapse CTEs
Legitimate use of the anti pattern
None
Use window functions instead of self joins
Type
Performance
Readability
Problem
Self-joins are frequently used to perform inter row calculations to look forward or backward across row boundaries in a table.
Self joins increase the number of records fetched and the number of table scans
Self-joins are hard to read and understand for most SQL developers in particular if they contain non-equi joins
Self-joins can be hard to debug
Here is an example of a self-join using a non-equi join condition (>).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT wv1.vehicleregistration ,wv1.chillersensornumber ,wv1.recordedwhen ,MAX(wv2.recordedwhen) AS previous_recordedwhen ,DATEDIFF('second' ,MAX(wv2.recordedwhen) ,wv1.recordedwhen) AS TIME_ELAPSED FROM warehouse_vehicletemperatures wv1 LEFT JOIN warehouse_vehicletemperatures wv2 ON wv1.vehicleregistration=wv2.vehicleregistration AND wv1.chillersensornumber=wv2.chillersensornumber AND wv1.recordedwhen>wv2.recordedwhen GROUP BY wv1.vehicleregistration ,wv1.chillersensornumber ,wv1.recordedwhen; |
Solution
Most self joins can be replaced by using window functions.
Window functions generally do not suffer from the issues of self-joins
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT vehicleregistration ,chillersensornumber ,recordedwhen ,LAG(recordedwhen) OVER(PARTITION BY vehicleregistration ,chillersensornumber ORDER BY recordedwhen) AS previous_recordedwhen ,DATEDIFF('second' ,LAG(recordedwhen) OVER(PARTITION BY vehicleregistration ,chillersensornumber ORDER BY recordedwhen) ,recordedwhen) AS TIME_ELAPSED FROM warehouse_vehicletemperatures; |
Legitimate use of the anti pattern
In rare cases a self-join can be more performant than a window function. The more of the following conditions your query meets, the more efficiently the window function will operate compared to the self join.
- Your self join uses a non-equi join, e.g. >, <, >=, <=. For Non-equi joins the CBO can not use a hash join, which is a very expensive operation.
- The self-join can not make use of indexes or cluster keys on the columns involved in the join condition
- There are no table partitions on the columns involved in the self join
- The self join table is large and has not been reduced on one side of the join by filtering or aggregation.
Most of the time, it’s a good idea to run a performance test to compare how well the query with the self-join works to how well the window function works.
Avoid UNION for multiple filter values
Type
Performance
Readability
Problem
Instead of specifying an IN operator to filter on multiple values a UNION (ALL) query is created to scan the table for each filter value
|
1 2 3 4 5 6 7 |
SELECT * FROM tablex WHERE col1=3 UNION ALL SELECT * FROM tablex WHERE col1=5; |
|
1 2 3 4 5 6 7 |
SELECT * FROM tablex WHERE col1<3 UNION ALL SELECT * FROM tablex WHERE col1>5; |
Solution
Use the IN operator to filter on multiple values
|
1 2 3 4 |
SELECT * FROM tablex WHERE col1 IN(3 ,5) |
|
1 2 3 4 |
SELECT * FROM tablex WHERE col1<3 OR col1>5; |
Legitimate use of the anti pattern
None
Use UNION ALL instead of UNION
Type
Performance
Problem
UNION is used to return the unique result across two tables.
This is not only unnecessary in most cases, but it could also lead to wrong results. Also, using UNION instead of UNION ALL by accident can have a big impact on performance.
Solution
Use UNION ALL instead of UNION
Legitimate use of the anti pattern
The UNION operator is what you need if you want to get rid of duplicate records in two different data sets.
Use an alias for inline views
Type
Readability
Problem
You should follow best practices and add an alias to inline views
|
1 2 3 |
select x from(select y as x from t) |
Solution
Use an alias for your inline view
|
1 2 3 |
select x from(select y as x from t) a |
Note: Some databases will even raise an error if you don’t use an alias for an inline view.
Legitimate use of the anti pattern
None
Avoid using functions in the Join clause
Type
Performance
Problem
There are two reasons to avoid using a function on a column inside a Join clause.
- It is CPU intensive because the function gets called for each record in your result set.
- It prevents the database from applying an index, sort key or cluster key. As a result, the database needs to read more data from the storage layer. This can have a significant impact on query performance.
In the example below we need to apply a function to convert the order_date column with data type string to a number. The function makes any index on the order_date column unusable.
|
1 2 3 4 5 6 |
SELECT b.sales_month ,sum(a.sales_amt) sales_amt FROM orders a JOIN date_dim b ON TO_NUMBER(a.order_date) =b.date_id |
Solution
The proper solution depends on the exact nature of your scenario. Properly design your data model and make foreign keys the same data type as the parent keys, e.g. in the example above make both columns a date or number. Certain scenarios may require you to precompute the function as part of ETL or a batch job. Some databases, such as Oracle offer index based functions. Last but not least you can rewrite the query so that the function is used on the side of the join with the smaller table. This will allow the index to be used on the side of the bigger table.
|
1 2 3 4 5 6 |
SELECT b.sales_month ,sum(a.sales_amt) sales_amt FROM orders a JOIN date_dim b ON a.order_date_id =TO_CHAR(b.date_id) |
Legitimate use of the anti pattern
- In some situations, you may not be able to avoid using the function in the WHERE clause.
- Your data volumes are small.
- You are dealing with an ad-hoc query
- The column with the function inside the join condition does not have an index or cluster key
Use parentheses when mixing ANDs with ORs
Type
Readability
Problem
There are a few important rules about how operators and conditions precede each other. The most important rule for conditions is that AND comes before OR.
Don’t make complicated expressions that require the reader to know the rules perfectly. Use spaces and parentheses to make the logic clear.
|
1 2 3 4 5 |
SELECT c1 FROM table1 WHERE x=1 OR z=5 AND y=2 |
Solution
Use parentheses when mixing ANDs with ORs to improve readability
|
1 2 3 4 5 |
SELECT c1 FROM table1 WHERE x=1 OR(z=5 AND y=2) |
Please note it’s very different to:
|
1 2 3 4 5 6 |
SELECT c1 FROM table1 WHERE( x=1 OR z=5 ) AND y=2 |
and in the above case the logic can’t be expressed without brackets.
Legitimate use of the anti pattern
None
Avoid or delay ORDER BY in inline views
Type
Performance
Problem
As a rule of thumb you should leave ordering until the very end. Frequently it is not needed at all. Sorting data is generally an expensive operation in databases. It should be reserved for when you really need it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
WITH customer AS( SELECT sc.customerid ,sc.customername ,sb.buyinggroupname ,ad.deliverymethodname FROM SALES_CUSTOMERS sc LEFT JOIN SALES_BUYINGGROUPS sb ON sc.buyinggroupid=sb.buyinggroupid LEFT JOIN APPLICATION_DELIVERYMETHODS ad on sc.DELIVERYMETHODID=ad.DELIVERYMETHODID ORDER BY sc.customerid) ,sales_order AS( SELECT sord.orderid ,sord.customerid ,sordl.quantity ,sordl.unitprice ,sordl.taxrate ,sordl.stockitemid ,sordl.orderlineid FROM SALES_ORDERS sord JOIN SALES_ORDERLINES sordl ON sord.orderId=sordl.orderid) SELECT customer.buyinggroupname ,SUM(sales_order.quantity*sales_order.unitprice) total_sales FROM customer LEFT JOIN sales_order ON customer.customerid=sales_order.customerid GROUP BY customer.buyinggroupname |
There is no point in ordering the CTE customer by customerid. It does not
Solution
Avoid ORDER By in subqueries, common table expressions and inline views
If you know that your data will be used by a business intelligence tool or another client then you should leave the ordering to the client tool
Remove the ORDER BY clause
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
WITH customer AS( SELECT sc.customerid ,sc.customername ,sb.buyinggroupname ,ad.deliverymethodname FROM SALES_CUSTOMERS sc LEFT JOIN SALES_BUYINGGROUPS sb ON sc.buyinggroupid=sb.buyinggroupid LEFT JOIN APPLICATION_DELIVERYMETHODS ad on sc.DELIVERYMETHODID=ad.DELIVERYMETHODID) ,sales_order AS( SELECT sord.orderid ,sord.customerid ,sordl.quantity ,sordl.unitprice ,sordl.taxrate ,sordl.stockitemid ,sordl.orderlineid FROM SALES_ORDERS sord JOIN SALES_ORDERLINES sordl ON sord.orderId=sordl.orderid) SELECT customer.buyinggroupname ,SUM(sales_order.quantity*sales_order.unitprice) total_sales FROM customer LEFT JOIN sales_order ON customer.customerid=sales_order.customerid GROUP BY customer.buyinggroupname |
Legitimate use of anti pattern
Window functions require ORDER BY
Some databases have hacks to filter the top n number of records by using pseudo columns, e.g. Oracle
The following query will select the top 1 records from sales table ordered by sales amount. While this query works in principle it is also best avoided and replaced with a window function
|
1 |
SELECT * FROM (SELECT * FROM sales ORDER BY sales_amt DESC) WHERE rownum <= 1 |
|
1 |
SELECT * FROM (SELECT * FROM sales ORDER BY sales_amt DESC) WHERE rownum <= 1 |
WHERE NOT IN without NOT NULL check in subquery
Type
Correctness
The problem
If any row of a subquery using NOT IN returns NULL, the entire NOT IN operator will evaluate to either FALSE or UNKNOWN and no records will be returned. NOT IN will not match any rows if the subquery just returns a single row with NULL.
Let’s look at an example
We have an orders table

and an order_details table with one NULL for order_id
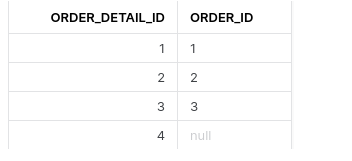
You create a query that returns orders in the orders table without a record in the order_details table
|
1 2 3 4 |
SELECT order_id FROM orders WHERE order_id NOT IN(SELECT order_id FROM order_details); |
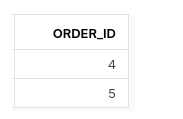
You might expect the following result

but you get back the following result

The query returns no rows at all. NOT IN will not match any rows if the subquery just returns a single row with NULL.
Solution
You can rewrite your query using a defensive programming style to check for NULL in the subquery
|
1 2 3 4 5 |
SELECT * FROM orders WHERE order_id NOT IN(SELECT order_id FROM order_details WHERE order_id IS NOT NULL); |
This query will give you the correct answer to your question.
Alternatively, you could use NOT EXISTS instead of NOT IN.
|
1 2 3 4 5 |
SELECT * FROM orders o WHERE NOT EXISTS(SELECT NULL FROM order_details od WHERE o.order_id=od.order_id); |
Exists cannot return NULL. It’s checking solely for the presence or absence of a row in the subquery and, hence, it can only return true or false. Since it cannot return NULL, there’s no possibility of a single NULL resulting in the entire expression evaluating to UNKNOWN.
While NOT and EXISTS are equivalent, NOT IN and NOT EXISTS have different behaviour when it comes to NULL.
Legitimate use of the antipattern
If you know that the column in question has a NOT NULL constraint you can leave out the extra check for NULL values in your NOT IN subquery. However, in the spirit of defensive programming you should still add it. The constraint may be dropped in the future
JOIN condition linking the compound key to multiple, different tables.
Type
Performance
Correctness
Problem
An ANSI join for a table has been specified, but the conditions specified link it to multiple, different tables simultaneously.
Example
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT RT.TransactionID ,U.UserName ,V.VehicleType ,U.PreferredLocation FROM RentalRegion R JOIN RentalDepot D ON D.RegionID = R.RegionID JOIN RentalTransactions RT ON RT.DepotID = D.DepotID AND RT.RegionID = R.RegionID ; |
The RentalTransactions (RT alias) table is being joined on a compound key but those keys link to more than one prior table:
|
1 2 3 |
ON RT.DepotID = D.DepotID --this joins to Depot AND RT.RegionID = R.RegionID --this joins to Region ; |
Frequently, it’s an easily missed error that can lead to significant performance problems because the database can’t execute a join across several distinct tables simultaneously. While the optimizer might intervene to internally rewrite the query plan as needed, it’s typically recommended to rectify the query where feasible. It’s also prudent to join multi-key columns to the same, single primary table for both readability and consistency reasons.
Solution
Specify a join condition that consistently links the multi-keys to the same, driving table. Among the options, it’s typically the one positioned lower in the hierarchy, both in terms of the data model and the JOIN sequence. Assuming a hierarchical structure like the Snowflake Dimensional Model is in place, it would simply take swapping the key being compared from the top-level table to its equivalent at a finer granularity. To illustrate, consider how the RentalRegion is joined to the RentalDepot using the RegionID columns. In subsequent joins, the RegionID from RentalRegion can be substituted with its equivalent column from RentalDepot therefore making RT being consistently joined to the latter table only.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT RT.TransactionID ,U.UserName ,V.VehicleType ,U.PreferredLocation FROM RentalRegion R JOIN RentalDepot D ON D.RegionID = R.RegionID JOIN RentalTransactions RT ON RT.DepotID = D.DepotID AND RT.RegionID = D.RegionID ; |
Legitimate use of the anti pattern
There might be some rather rare cases where a tables could be joined using different, independent keys all together, effectively creating a cycle (eg. triangle when looking at the data model). Here the transactional table can be naturally joined to its dimensions Vehicles and Users but the last two have some extra link (preferences) that potentially closes the cycle:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT RT.TransactionID ,U.UserName ,V.VehicleType ,U.PreferredLocation FROM Users U JOIN Vehicles V ON V.Location = U.PreferredLocation AND V.VehicleType = U.PreferredVehicleType; JOIN RentalTransactions RT ON RT.VehicleID = V.VehicleID AND RT.UserID = U.UserID ; |
In the given scenario, it would be arguably justified enough to keep linked to multiple tables as shown. However, for improved readability, it is still advisable to break the loop and shift that less commonly used, additional JOIN condition to the WHERE clause as an additional filter:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT RT.TransactionID ,U.UserName ,V.VehicleType ,U.PreferredLocation FROM RentalTransactions RT JOIN Vehicles V ON V.VehicleID = RT.VehicleID JOIN Users U ON U.UserID = RT.UserID WHERE V.Location = U.PreferredLocation AND V.VehicleType = U.PreferredVehicleType; ; |
Antipatterns that trigger a Notice
Beware of count distinct
Type
Performance
Problem
The Count distinct operation is computationally expensive and decreases database performance. BigQuery defaults to approximating the distinct count, using a HyperLogLog algorithm. But BigQuery also supports exact distinct count in a separate function.
One of two algorithms is typically used for distinct counts.
- Sorting: Records are sorted, duplicate records then are identified and then removed. The number of target expression values in the remaining set of tuples would then represent a distinct count of the target expression values.
- Hashing: Records are hashed and then duplicates are removed within each hash partition. Implementing hashing may be less computationally intensive than the sorting approach and may scale better with a sufficiently large set of records. However, it is still computationally expensive
Solution
There are two possible solutions to the problem.
If you don’t require 100% accuracy you can use approximate count distinct aka HyperLogLog. Most modern databases support this functionality.
Here is an example of approximate count distinct in SQL Server
|
1 2 |
SELECT approx_count_distinct(O_OrderKey) AS approx_distinct_order_key FROM Orders |
Bitmap-based distinct counts can be performed incrementally, combining them with Snowflake Materialized Views for query rewrite in databases that support such functionality. Snowflake and Oracle are two examples of databases that support bitmap-based distinct counts.
If you do not have an approximate count distinct (HyperLogLog) or bitmap based count distinct as part of your database, you could precompute the distinct counts as part of ETL.
Legitimate use of the anti pattern
For small data volumes you will not see a performance problem when using count distinct.
As the number of distinct values increases, the elapsed time and memory usage of standard count distinct increases significantly (non-linear growth).
The elapsed time and memory usage of approximate count distinct on the other hand remains consistent regardless of the number of distinct values in the data set (linear growth).
Beware of SELECT DISTINCT
Type
Performance
Correctness
Problem
Incorrect use of the DISTINCT operator by SQL developers and analysts is common.
In the vast majority of query scenarios where it is used, using DISTINCT is problematic.
SELECT DISTINCT is used incorrectly to work around the following types of problems:
- Data quality issues in the underlying data
- Data quality issues because of a badly designed data model
- Mistake in the SQL statement, e.g. Join or Filtering
- Incorrect usage of SQL features
Solution
When you have duplicate values, resist the urge to use DISTINCT.
When you find duplicates in your data, instead of using DISTINCT, you should first make sure you understand the data model and the data itself.
- Make sure to check that your table joins are correct. Do you need to join on compound keys instead of single key columns?
- Make sure to apply the correct filters.
- Make sure that you understand the data model
- Make sure to check for data quality issues
Legitimate use of the anti pattern
There are times when it makes sense to use DISTINCT. As a general rule, the pattern is correct if your goal is to find the unique values in one or more columns. But if you use DISTINCT to get rid of a large number of duplicates that you didn’t expect, you’ve hit an anti pattern.
Further reading
SQL antipatterns: SELECT DISTINCT
Pseudo join condition results in a CROSS join.
Type
Performance
Correctness
Problem
A join condition exists but it does not link the joining table resulting in a cross join.
Example
|
1 2 3 4 5 |
SELECT * FROM TEST PCT JOIN EXAM PCE ON 1=1 AND PCE.AUDIT_CD<>'D' |
Some conditions have been specified following the ON clause. However, none of them are actually joining: the first condition uses a constant (1=1). The second join condition does not reference the joining table PCE.
|
1 2 |
ON 1=1 AND PCT.CRUD_CD<>'D' |
This results in an implicit cross join and performance issues.
Solution
Specify a join condition that links the joining table to another table defined earlier in the scope.
|
1 2 3 4 5 |
SELECT * FROM TEST PCT JOIN EXAM PCE ON PCT.ID=PCE.ID AND PCE.AUDIT_CD<>'D' |
Legitimate use of the anti pattern
None. Once a table is explicitly joined (JOIN with ON keyword used) at least one of the condition expressions should bind the table being joined with at least one table specified before.
Avoid nested CTEs
Type
Readability
Problem
It is possible to nest CTEs, but that does not mean you should write queries with them. Nesting CTEs can make the SQL query harder to read and understand, especially when multiple levels of nesting are involved.
|
1 2 3 4 5 6 7 |
WITH CTE1 AS ( WITH CTE2 AS ( SELECT col1 FROM table1 WHERE col1 > 10 ) SELECT col1 FROM CTE2 WHERE col1 < 50 ) SELECT * FROM CTE1; |
Solution
Instead of nesting CTEs, list them sequentially in the WITH clause. This makes the query more readable and easier to maintain.
|
1 2 3 4 5 6 7 |
WITH CTE2 AS ( SELECT col1 FROM table1 WHERE col1 > 10 ), CTE1 AS ( SELECT col1 FROM CTE2 WHERE col1 < 50 ) SELECT * FROM CTE1; |
Legitimate use of the anti pattern
None
How can we automatically identify SQL antipatterns?
You now understand the importance of fixing SQL antipatterns. But how do we find SQL antipatterns in SQL code?
We have created FlowHigh, which is an SQL analysis tool for static and dynamic SQL analysis.
We offer three distinct versions of our FlowHigh SQL Analyzer. The primary version is integrated into our online FlowHigh platform. The second version is available as a Python SDK. Lastly, we have a variation designed specifically for Snowflake Native apps.
FlowHigh UI
You can identify antipatterns using the FlowHigh UI in your web browser. In this flavour, you can easily spot query lines that contain antipatterns and manually review them.
Register for FlowHigh to check your queries for bad SQL code.
FlowHigh SDK
We have also created the FlowHigh SDK. This is a python SDK package for programmatic access. One of the many use cases is to automate the detection of bad SQL.
We can detect anti patterns by running this python code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
from flowhigh.model import AntiPattern from flowhigh.utils import FlowHighSubmissionClass """ This Snippet shows how to use the SDK to print the list of anti-patterns """ def print_anti_pattern(anti_pattern: AntiPattern): """ Utility to format and print the anti-pattern's properties :param anti_pattern: the Anti-pattern to be printed out to the console :return: """ print(f"Anti pattern: {anti_pattern.name}") severity = "Notice" if anti_pattern.severity == 3 else ("Caution" if anti_pattern.severity == 2 else "Warning") print(f"Severity: {severity}") print(f"Position: {anti_pattern.pos}") print(f"Link: {anti_pattern.link}") print(f"Performance: {anti_pattern.performance if anti_pattern.performance != ' ' else 'N'}") print(f"Readability: {anti_pattern.readability if anti_pattern.readability != ' ' else 'N'}") print(f"Correctness: {anti_pattern.correctness if anti_pattern.correctness != ' ' else 'N'}") # Your SQL query from editor sql = """%sqlEditor%""" # Initializing the SDK fh = FlowHighSubmissionClass.from_sql(sql) # Get all antipatterns and print them for ap in fh.get_all_antipatterns(): print_anti_pattern(ap) |
For this example we will run this script on this query:
|
1 2 3 4 5 6 7 8 9 |
SELECT DISTINCT C.CUSTOMERNAME AS Customer, SP.STOCKITEMID FROM SALES_CUSTOMERS c LEFT OUTER JOIN SALES_ORDERS o ON c.CUSTOMERID = o.CUSTOMERID INNER JOIN SALES_ORDERLINES ol ON o.ORDERID = ol.ORDERID INNER JOIN STOCKITEM_PRICE sp ON ol.STOCKITEMID = sp.STOCKITEMID; |
Output:
|
AP_ID |
AP_NAME |
SEVERITY |
PERFORMANCE_FLAG |
READABILITY_FLAG |
CORRECTNESS_FLAG |
|---|---|---|---|---|---|
|
AP_13 |
Avoid inner join after outer join in multi-join query |
Warning |
N |
N |
Y |
|
AP_06 |
Beware of SELECT DISTINCT |
Warning |
Y |
N |
Y |
FlowHigh Snowflake Native App
FlowHigh SQL Analyser is also available as Snowflake Native App, which enables us to detect antipatterns within Snowflake. It can analyze Snowflake’s query history to identify problematic SQL queries and schedule regular scans, running them every few minutes.
Using this sample code, we can pinpoint anti-patterns and determine the frequency of their occurrence within queries.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT QUERY_ID ,QUERY_TEXT ,AP_TYPE ,POS ,STATUS ,STATUS_MSG ,AP_QUERY_PART FROM snowflake.account_usage.query_history corpus CROSS JOIN TABLE(FLOWHIGH_APP.CODE_SCHEMA.get_ap(corpus.QUERY_TEXT ,TRUE ,FALSE)) ap WHERE query_type='SELECT' |
To learn more about FlowHigh SQL Analyser Native App you can check our blog where we explain how to prevent surges in your Snowflake compute usage.
Conclusion
Avoiding these and other anti-patterns in SQL can lead to more efficient, reliable, and maintainable database operations. Always aim for clarity, efficiency, and accuracy to ensure optimal query performance.