Converting Google Analytics JSON to S3 on AWS
In this guide we will show you how to process Google Analytics JSON files with Enterprise Flexter and convert it to Amazon AWS S3.
Google Analytics
Google Analytics is a freemium web analytics service offered by Google that tracks and reports website traffic.Google launched the service in November 2005 after acquiring Urchin. Google Analytics is now the most widely used web analytics service on the Internet.
Amazon AWS S3
Amazon S3 (Simple Storage Service) is a web service offered by Amazon Web Services (AWS). Amazon S3 provides storage through web services interfaces.
Amazon S3 uses the same scalable storage infrastructure that Amazon.com uses to run its own global e-commerce network.
Setting up Amazon S3 Data Storage
Before we start the conversion process let’s set up S3 storage buckets.
- In the search box on the AWS console type S3 as shown below.

- Click on S3 – Scalable storage in the cloud. You will be redirected to the S3 web service as shown below.
- We create a data bucket in the next step. The bucket is a logical unit of storage on the AWS platform and provides the user with an option to store objects consisting of data and metadata which can be accessed from other utilities like Athena (a query service on AWS) and QuickSight (a visualisation tool on AWS). The bucket offers users the option to create an unlimited number of objects. The create bucket page is shown below. The bucket name is specified as ‘gaoutput’
- The properties can be setup as necessary in the next page.
- The permission/access levels can be set up in the next page as shown below.
[flexter_button]
Setting up API Access Key
Now we will have to setup Access Key. You can find detail instructions on Amazon AWS website if you want.
- First we will go to ‘My Security Credentials’
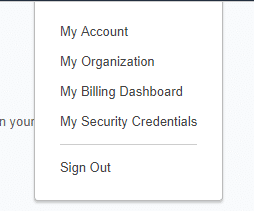
- Then we will ‘ Add User ‘
- Call it ‘ Flexter ‘ and select Programmatic Access
- Select permission for that user
- And SAVE your Access Key and Secret Key somewhere safe.
Processing JSON with Enterprise Flexter
We will be using the Docker Version of Enterprise Flexter .
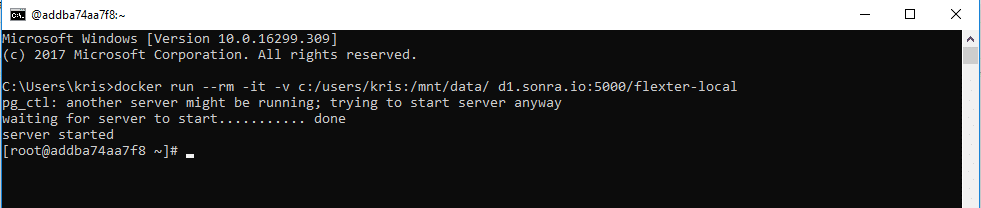
- We run docker with the below command and create a container that will be destroyed when we exit it
|
1 |
docker run --rm -it -v c:/users/kris:/mnt/data/ d1.sonra.io:5000/flexter-local |
- Next we download a couple of JARs that will alow us to interact with S3 from Flexter
|
1 2 3 4 5 6 7 |
1) Download hadoop curl -O http://www-eu.apache.org/dist/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz 2) Unzip it tar zxvf hadoop-2.7.5.tar.gz 3) copy libs cp ~/hadoop-2.7.5/share/hadoop/tools/lib/aws-java-sdk-1.7.4.jar /usr/share/flexter/json2er/lib/ cp ~/hadoop-2.7.5/share/hadoop/tools/lib/hadoop-aws-2.7.5.jar /usr/share/flexter/json2er/lib/ |
- Next we generate the target model
|
1 |
json2er -g1 /mnt/data/Desktop/ga.json |
- We can now extract data to our S3 bucket.
|
1 |
json2er --conf spark.hadoop.fs.s3a.access.key=<insert your access key> --conf spark.hadoop.fs.s3a.secret.key=<insert your secret key> -- /mnt/data/Desktop/ga.json -f csv -o s3a://gaoutput/ga_out/ -S o -l1 |
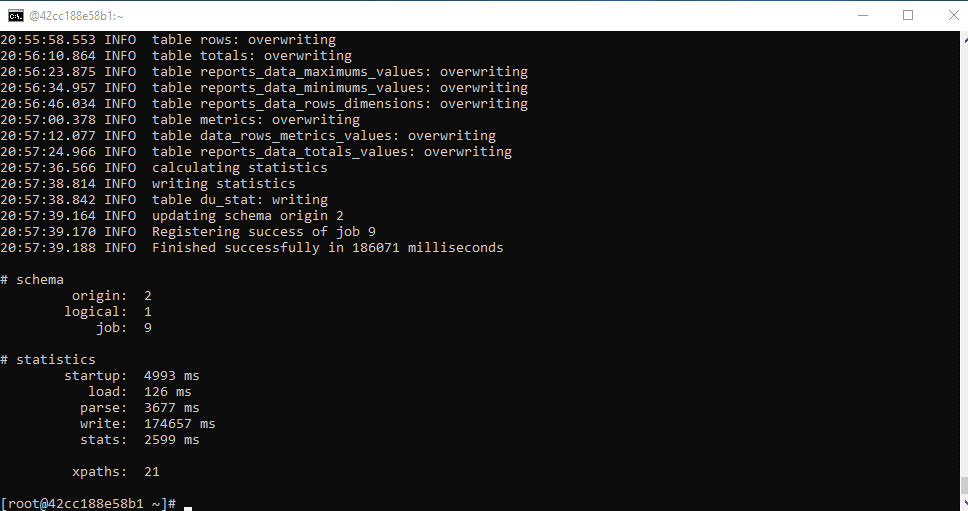
- Once processing is finished we can check the output on S3.

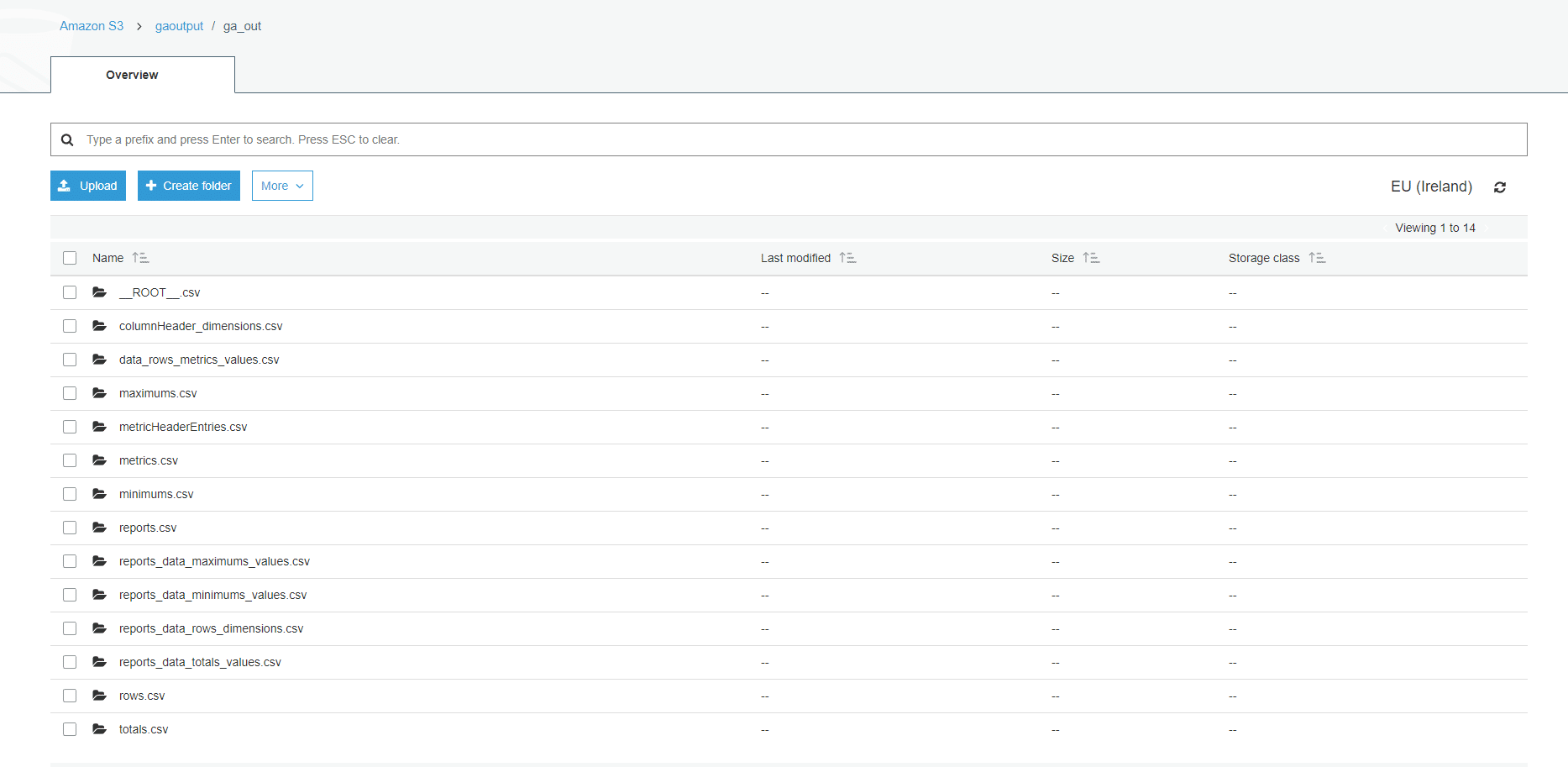
ER Diagram
We have generated ER Diagram with Flexter.
Conclusion
We can easily process complex JSON data with Flexter and process the output to S3. With Enterprise Flexter we can also process JSON files in realtime and stream the output to S3 buckets. The possibilities are endless.
If you are interested in Enterprise Flexter version, feel free to contact us.
Do you have any complex JSON files that need to be converted for data analysis? Please leave a comment with your experience or reach out to us.
{kind=link}