Converting Trello JSON to Redshift
In this blog post we will show case Flexter, Sonra’s data warehouse automation solution for complex XML and JSON documents. We will process Trello JSON for this showcase.
Flexter is a Spark application written in Scala. For this blog post we will use the managed cloud version of Flexter. Flexter SaaS is built on top of container technology. You can make calls to its endpoints via a RESTful API. It currently supports Snowflake, S3, and Redshift as targets. We will add onto this list over time and will also add calls to APIs to transform JSON and XML on the fly. This will let you generate a relational data model from any API in seconds.
Trello
Trello is a web-based project management application created by Fog Creek Software in 2011. The company was spun out to form the basis of a separate company in 2014 and later sold to Atlassian in January 2017.
Redshift
Redshift is built to handle large scale data sets and database migrations, based on technology from the massive parallel processing(MPP) data warehouse company ParAccel (later acquired by Actian). It differs from other Amazon’s hosted database offering, in its ability to handle analytic workloads on big data data sets stored by a column-oriented DBMS principle.
The service can handle connections from most other applications using ODBC and JDBC connections.
[flexter_banner]
Inside Trello JSON
We have exported a Trello JSON file from a Trello Board. Trello is based on Kanban, and each card represent a task that needs to be completed.
The file contains over 3000 cards. We have selected one of those cards to and will later show you how you can find the card details in the Redshift tables that Flexter generates.
Processing data with the Flexter API
Flexter exposes its functionality through a RESTful API. Converting XML/JSON to Redshift can be done in a few simple steps.
Step 1 – Authenticate
Step 2 – Create a File Source
Step 3 – Generate schema (target data model)
Step 4 – Define your sink, e.g. Redshift
Step 5 – Process your XML/JSON data
Now we can go through steps and process our data.
Step 1 – Authenticate
To get an access_token you need to make a call to /oauth/token with Authorization header and 3 form parameters:
- username=YOUR_EMAIL
- password=YOUR_PASSWORD
- grant_type=password
|
1 2 3 4 |
curl --location --request POST "https://api.sonra.io/oauth/token" \ --header "Content-Type: application/x-www-form-urlencoded" \ --header "Authorization: Basic NmdORDZ0MnRwMldmazVzSk5BWWZxdVdRZXRhdWtoYWI6ZzlROFdRYm5Ic3BWUVdCYzVtZ1ZHQ0JYWjhRS1c1dUg=" \ --data "username=XXXXXXXXX&password=XXXXXXXXX&grant_type=password" |
Example of output
|
1 2 3 4 5 6 7 8 |
{ "access_token": "eyJhbG........", "token_type": "bearer", "refresh_token": "..........", "expires_in": 43199, "scope": "read write", "jti": "9f75f5ad-ba38-4baf-843a-849918427954" } |
[flexter_button]
Step 2 – Create a source
A source is the location and type of your source documents. Sources are referenced in the next step when we create the target data model.
Currently, we support file upload and S3 as location for sources.
Three different types of documents are supported.
- XML
- XSD
- JSON
The type of source determines by which algorithm it will be processed during Schema generation or data processing.
|
1 2 3 4 5 |
curl --location --request POST "https://api.sonra.io/source/create/file" \ --header "Authorization: Bearer <access_token>" \ --form "type=json" \ --form "name=trello" \ --form "file=@<file path>" |
Example of output
|
1 2 3 4 5 |
{ "status": "ok", "file": "trello", "type": "json" } |
Step 3 – Generating target data model
In this step we create our Schema (target data model).
You can generate Schema based on :
- XML Source entry ( Source with type xml )
- XML Source entry + XSD Source entry ( Sources with types xml and xsd accordingly )
- JSON Source files ( Source with type json )
|
1 2 3 4 5 6 7 |
curl --location --request POST "https://api.sonra.io/schema/create" \ --header "Authorization: Bearer <access_token>" \ --header "Content-Type: application/json" \ --data "{ \"name\": \"trello_schema\", \"json\": \"trello\" }" |
Example of output
|
1 2 3 4 |
{ "status": "ok", "uuid": "trello_schema" } |
Example of ER Diagram
You can download the full ER Diagram for our Trello sample file from here.
Step 4 – Creating a sink
A sink is a connection to a target data store. In this step we create a connection to Redshift.
To create a Redshift sink provide the following mandatory parameters:
name – is a unique name of Sink, which you will use in other calls as a reference to it.
path – a path to Redshift database (jdbc), should be in format jdbc:redshift://cluster-name.xxx.region.redshift.amazonaws.com:5439/database_name (for example jdbc:redshift://sonra-test.xxx.eu-west-1.redshift.amazonaws.com:5439/testdb)
username – username (user must have WRITE access for selected database)
password – user’s password
|
1 2 3 4 5 6 7 8 9 |
curl --location --request POST "https://api.sonra.io/sink/create/redshift" \ --header "Authorization: Bearer <access_token>" \ --header "Content-Type: application/json" \ --data "{ \"name\": \"redshift_sink\", \"path\": \"jdbc:redshift://sonra-test.xxxx.eu-west-1.redshift.amazonaws.com:5439/testdb\", \"username\": \"your_user\", \"password\": \"password\" }" |
Example of output
|
1 2 3 4 5 |
{ "status": "ok", "file": "redshift_sink", "type": "REDSHIFT" } |
Step 5 – Processing Trello JSON data
In this step we will process our data.
This endpoint is used to create a Data Processing entry. It requires 2 mandatory parameters and 1 optional parameter:
- Parameter schema is a reference to a Schema entry
- Parameter source is a reference to a XML Source
- (Optional) Parameter sink is a reference to a Sink, if you want the output of processing to be saved somewhere, you should specify a Sink reference, otherwise the output will be saved in our cloud for download
|
1 2 3 4 5 6 7 8 |
curl --location --request POST "https://api.sonra.io/data/process" \ --header "Authorization: Bearer <access_token>" \ --header "Content-Type: application/json" \ --data "{ \"schema\": \"trello_schema\", \"source\": \"trello\", \"sink\": \"redshift_sink\" }" |
Querying the data in Redshift
The data has been loaded to Redshift. Let’s have a look at the tables that were generated.
We can now run a query to find the Trello card from earlier on. This data has been loaded to the Cards table.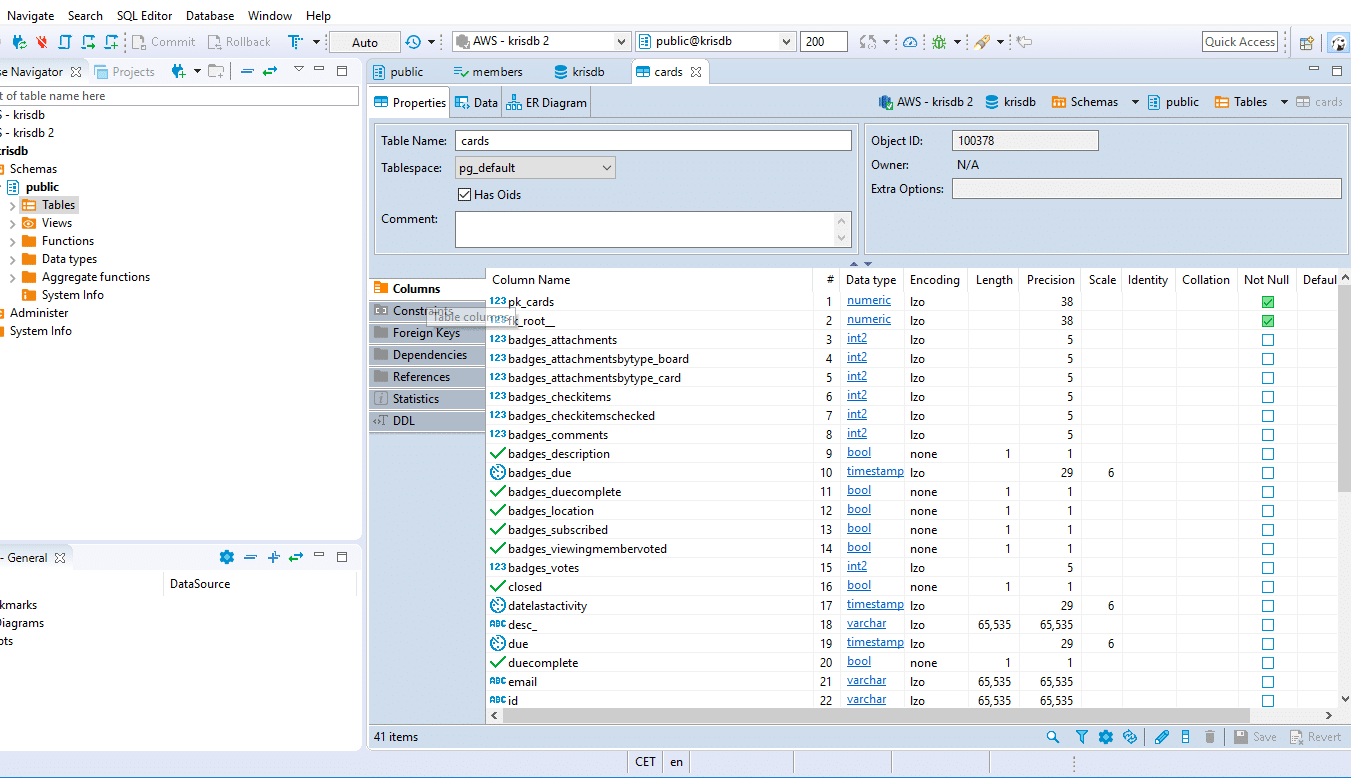
We can now query the Cards table to find the card from earlier on. We run SQL statement:
|
1 2 3 4 |
SELECT c.id, c.name, c.shorturl FROM root__ r JOIN cards c ON r.pk_root__ = c.fk_root__ WHERE c.id = '5ca48462a9150782f404d444' |
And by running SQL statement we have got our Card.
Conclusion
We have processed JSON data with ease. Flexter auto-generated the target schema, the target tables, the mappings from JSON elements to target table attributes, and globally unique foreign key relationships. Last but not least we automatically processed the JSON data into Redshift. We did in a matter of minutes what would normally take a few days.
If you have any questions please refer to the Flexter FAQ section. You can also request a demo of Flexter.
Contact us for expert services on Redshift.