Converting IRS Form 990 XML to text and Excel
In 2016, the IRS released data in electronic form to the nonprofit sector. Each of these files, contains data about nonprofit finance and more. You can get all that data from Amazon Web Services ( AWS).
Researchers could now analyze data without time and the cost-consuming process of converting paper records to digital records by manual data entry or Optical Character Recognition (OCR) (image-to-text).
While the IRS has made the data available, it is still not accessible as it is locked away in complex eXtensible Markup Language (XML) structures. In this post, we use Flexter, for converting xml to excel. Flexter, our ETL tool for XML liberates the data from the XML structures and make it available for data analysis in TSV / Excel.
Inside Datasets
Inside datasets, you could find three forms: 990, the 990EZ and the 990PF.
All tax-exempt organizations that have gross receipts of at least $200,000 or assets worth at least $500,000 are required to yearly file Form 990 (“Return of Organization Exempt from income Tax”) with the IRS. Smaller organizations can file a modified version of Form 990, called the IRS Form 990EZ, if they aren’t subject to special regulations as are schools and hospitals. Form 990PF is used to figure the tax base on investment income, and to report charitable distributions and activities.
Organizations are able to send information the IRS electronically as e-files, which are sent to MeF (IRS Modernized e-File), the electronic filing system. MeF is a web-based system that allows filling through the internet. MeF uses XML which is widely accepted because of its standardized way of identifying, storing and transmitting data.
Overview of the 990 form
Form 990 is a 12-page form that provides insight to the government and the public organization’s activities each year. An extensive amount of information is needed to fill out this form, which is 100 pages.
Parts of the 12-page form are:
- Part I is a summary of the organization.
- Part II is the signature block where an officer of the organization attests under penalty of perjury that the information is true, correct and complete to the best of his/her knowledge.

- Part III is a statement of the organization’s accomplishments, including its mission statement and the expenses and revenues for the organization’s three largest program services.
- Part IV is a checklist of schedules that must be completed and accompany the form (explained later).
- Part V is for statements about other IRS filings and tax compliance.
- Part VI requires information about the governing body and management of the organization as well as its policies.
- Part VII lists the compensation paid to current and former officers, directors, trustees, key employees, employees receiving more than $100,000 in compensation and up to five independent contractors receiving more than $100,000 in payment from the organization.
- Part VIII is a statement of the organization’s revenue from related or exempt funds and unrelated business income (which requires the filing of Form 990-T; this income is not exempt)
- Part IX is for reporting the organization’s expenses.
- Part X is the organization’s balance sheet.
- Part XI is a reconciliation of the net assets of the organization.
- Part XII explains the organization’s financial statements and reporting (e.g., whether it uses the cash, accrual or other method of reporting to prepare the form and whether its financial statements were compiled and reviewed by an independent accountant).
All pages you can find here.
[cloud_book_banner]
And then on top of that, we have Schedules.
For example, Schedule A is used to provide required information about public charity status and public support by organizations that file 990 form or 990EZ form.
Schedule B is used to provide information on contributions organizations reported:
- Form 990-PF, Return of Private Foundation;
- Form 990, Return of Organization Exempt from Income Tax; or
- Form 990-EZ, Short Form Return of Organization Exempt from Income Tax.
And there are more. All the schedules can be found in the XML schema files.
IRS 990 schema files (XSDs)
Finding IRS 990 XSD schemas
The latest schemas are available only if you register with the IRS and have an e-services account that is listed on an e-File application with the provider option of Software Developer, but older schemas are hosted by Charity Navigator on GitHub and can be downloaded.
Mapping the XML elements to the schema (XSD)
The XSD files contain descriptions and document the purpose of the individual XML elements. We can map XML element names to the XSD and get the description, e.g. TotalVolunteersCnt in the XML maps to xsd:element name=”TotalVolunteersCnt” in the IRS990.xsd file.
As you can see in the image below, the XSD schema consists of multiple nested XSD files that target specific parts of the form submission and correspond to the various parts in the XML files.
File IRS990.xsd is nested inside the IRS990 folder.
The IRS Schedule XSDs that relate to Schedules A-R are contained in the Common folder.
Here is a corresponding XML for Schedules.
Here is an expanded version of the XML for Schedule A.
[blogBannerBigData]
Processing IRS 990 XML with Flexter
Now, we will show you how easy it is to process the IRS XML with corresponding Schema with Flexter, Sonra’s ETL tool for XML. It converts large volumes of complex XML or JSON to text, a relational database or Hadoop (ORC, Parquet, Avro).
We downloaded some IRS sample data from the AWS website for 2014v5.0 schema. We first upload our XML data to Flexter, and at the end of this process we will get our data in a tabular output.
We upload an archive file of XML files that correspond to schema 2014v5.0.
We upload our 2014v5.0 zipped Schema files.
Next, we submit our e-mail address. You will get an e-mail with a download link to your converted data once Flexter has finished parsing the IRS 990 XML.
That’s it.
Once we have downloaded our tab separated output (TSV) files, we can extract them.
With Flexter, we have achieved in minutes what normally would take days or weeks of manual coding.
[da_services_banner]
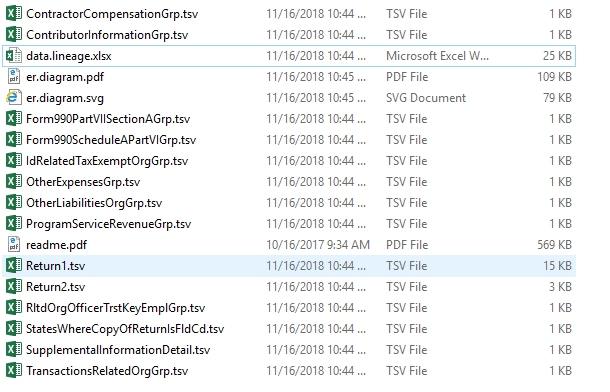
In our output folder, we receive a couple of different files: an ER diagram that illustrates data structure, text file with data in TSV format, and a data lineage xlsx file which is used as a source to target map. That means we can use it to map source elements in the XML to table target attributes.
Versions of IRS Form 990 and differences
Whenever the IRS makes a change to the form, it also releases a new version of the XSD. Some of the changes to the XSD became necessary after the IRS standardised on the naming’s and abbreviations for elements in the XSD.
We can identify the version that an XML file corresponds to by looking at the <Return> tag in each XML file. It has an attribute called ‘returnVersion’.
We showed you how we processed 2014v5.0 version schema, but for this post, we processed two versions of IRS 990 form, from 2014, and now we will look into the differences between those two schemas.
As part of processing XML files with Flexter, we get a source to target map with data.lineage.xls, which we will use to compare differences between different versions of schemas, using a tool such as WinDiff.

As we can see in this comparison of two data lineage files, “KeyEmpoyeeInd” on the line 23 is in the 2014.v5 schema file, but it is not in 2014v6 schema file. There are a lot more of differences which you can check pretty easy.
[snowflake_service]
Conclusion
We have processed IRS Form 990 data in a few minutes and have provided files that can help you with comparing different versions of IRS Form 990 schemas.
In subsequent posts, we will process IRS Form 990 data and show you how Flexter can create a unified schema across the different XSD versions. If you would like to find out more about Flexter, you can contact us.
You can download some sample XML files, the corresponding schemas and the TSV output.
Sample XML files submitted in 2015 and corresponding to schema version 2014v5.0 XML_2014v5.0_2015.zip
XSD files for schema version 2014v5.0: XSD_2014v5.0
The converted output including ER diagram
Have you worked with IRS Form 990 data? What was your use case? What challenges did you run into?


