Ultimate Guide to Parsing XML to Google BigQuery (2024)

While XML is frequently considered a legacy file format it is still widely used as part of industry data standards such as HL7 or ACORD. Another use case is for document management. Did you know that all of your spreadsheet and word processing documents are all based on XML. It is not correct to label XML as a legacy format. It is not going away any time soon. In fact most new industry data standards are still based on XML. Rather than treating XML as legacy you should treat it as a niche data format.
Most data management projects we have worked on have XML as a source for the data warehouse. So it comes as a surprise that BigQuery does not offer any native features of parsing XML to tables that can be queried via SQL. Competitors such as Snowflake have native XML parsing features and so does Databricks. While both of these platforms have limitations and can’t compare to XML parsing features in Oracle and MS SQL Server they have some basic features for simple scenarios and you can get started quickly.
BigQuery does not have native support for loading, unloading, querying, parsing or converting XML. You need to apply a workaround for processing XML in BiqQuery.
But let’s focus on BigQuery.
For simple scenarios we have documented some workarounds of converting XML to BigQuery tables in a relational format.
- Workaround 1: Create an Apache Beam pipeline for parsing XML to BigQuery tables. Then use the Google Dataflow runner for Apache Beam to execute the XML conversion pipeline
- Workaround 2: Convert the XML to JSON using a BiGQuery UDF and then use BigQuery native features to convert JSON to BigQuery tables
These workarounds require a lot of manual coding and don’t scale well for more complex scenarios and conversions for large data volumes.
Hence, we also cover a third option using Flexter, an enterprise XML conversion tool. This is a no code approach of parsing XML into BigQuery tables. It fully automates the XML conversion process to BigQuery.
In the last section of this blog post we give you some guidance on when to use the workarounds with manual coding and when to use an automated approach using a no code XML converter.
Let’s get started.
For those of you in a hurry we have compiled the key takeaways of this post
Surprisingly, BigQuery does not have native support for parsing XML to tables.
Workarounds using Apache Beam, Google Dataflow, Spark, and UDFs can be applied to convert XML to BigQuery tables.
Parsing XML on BigQuery is a labour-intensive process that requires extensive coding by an engineer. The steps involved include:
- Manual Analysis of XML: The engineer needs to manually analyse the XML data to understand its structure and content.
- Creating a Target Data Model: The engineer must manually design and create a target data model to store the parsed XML data.
- Mapping XML Elements: There is a need to manually map XML elements to the corresponding tables in the target data model.
- Building a Pipeline: The engineer needs to manually build a data pipeline to handle error management, dependencies, rollbacks, and other necessary processes.
The workarounds we describe in this post also do not scale well from a performance point of view.
The workarounds do not have support for XML Schema (XSD).
For enterprise scenarios with complex XML, very large XML files, or a large volume of XML files consider an automated XML conversion approach using an XML converter such as Flexter.
Parsing XML Data in BigQuery with Apache Beam
This part of the blog post details the steps required to parse XML in BigQuery with Apache Beam.
We load an XML file stored locally into BigQuery using Apache Beam by converting it into a dictionary and from there to a BigQuery table. We also cover the necessary setup, script, and execution instructions.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
Prerequisites
Google Cloud Project:
- Ensure you have a Google Cloud Project set up.
- Enable the BigQuery and Google Cloud Storage APIs for your project.
Service Account and Authentication:
- Create a service account in your Google Cloud project.
- Grant the service account permissions for BigQuery and Google Cloud Storage (e.g., BigQuery Admin, Storage Object Admin).
- Generate a JSON key for the service account and download it.
Python Environment:
- Set up a Python environment. We recommend using a virtual environment.
- Install the required libraries:
|
1 |
pip install apache-beam[gcp] xmltodict |
Output Table:
- Create the output table in BigQuery in your desired dataset and note the table ID. For example:
|
1 |
output_table = 'xmlproject-424914:xml_dataset.xml_data_table' |
XML parsing script
As a first step we create a Google Cloud Storage bucket (e.g., xmlbucket101) which will be used as a temporary location by Apache Beam. In Apache Beam, the WriteToBigQuery transform can write data to BigQuery using different methods, one of which is FILE_LOADS . When using the FILE_LOADS method in the WriteToBigQuery transform, a temp_location is required.
This method stages the data into files in Google Cloud Storage (GCS) before loading it into BigQuery. Here’s how it works:
- Staging Data: When the FILE_LOADS method is used, Apache Beam writes the data to temporary files in a specified GCS bucket.
- Loading to BigQuery: Once the data is staged in GCS, it is then loaded into BigQuery from these files.
Here’s the complete script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
import os import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions import xmltodict import copy import argparse import logging # Set the environment variable for Google Cloud authentication os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = "C:/Users/leoan/Downloads/xmlproject-424914-fe6252bf452a.json" # Define input and output paths input_path = 'C:/Users/leoan/Downloads/company_xml.xml' output_table = 'xmlproject-424914:xml_dataset.xml_data_table' gcs_temp_location = 'gs://xmlbucket101/temp/' def parse_into_dict(xmlfile): with open(xmlfile) as ifp: doc = xmltodict.parse(ifp.read()) return doc def cleanup(x): y = copy.deepcopy(x) if '@id' in y: y['id'] = y.pop('@id') return y def get_employees(doc): for company in doc['org']['company']: company_id = company['@id'] for employee in company['employee']: employee['company_id'] = company_id yield cleanup(employee) def log_element(element): logging.info("Element: %s", element) return element table_schema = { 'fields': [ {'name': 'id', 'type': 'STRING', 'mode': 'NULLABLE'}, {'name': 'name', 'type': 'STRING', 'mode': 'NULLABLE'}, {'name': 'position', 'type': 'STRING', 'mode': 'NULLABLE'}, {'name': 'company_id', 'type': 'STRING', 'mode': 'NULLABLE'}, ] } def run(argv=None): parser = argparse.ArgumentParser() parser.add_argument( '--output', required=True, help=( 'Specify BigQuery table in the format project:dataset.table')) known_args, pipeline_args = parser.parse_known_args(argv) pipeline_options = PipelineOptions(pipeline_args) google_cloud_options = pipeline_options.view_as(GoogleCloudOptions) google_cloud_options.temp_location = gcs_temp_location with beam.Pipeline(argv=pipeline_args, options=pipeline_options) as p: employees = (p | 'files' >> beam.Create([input_path]) | 'parse' >> beam.Map(lambda filename: parse_into_dict(filename)) | 'employees' >> beam.FlatMap(lambda doc: get_employees(doc)) | 'log' >> beam.Map(log_element)) employees | 'tobq' >> beam.io.WriteToBigQuery( known_args.output, schema=table_schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND, create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED) if __name__ == '__main__': import sys logging.getLogger().setLevel(logging.INFO) run(sys.argv + ['--output', output_table]) |
Explanation of Key Parts
Authentication
In this section, we set up authentication to Google Cloud using a service account. The service account JSON key file is used to authenticate the script’s interactions with Google Cloud services such as BigQuery and Google Cloud Storage.
|
1 |
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = "C:/Users/leoan/Downloads/xmlproject-424914-fe6252bf452a.json" |
Environment Variable: GOOGLE_APPLICATION_CREDENTIALS is an environment variable that specifies the path to the service account JSON key file. Setting this variable ensures that the script uses the correct credentials for authentication.
File Paths and GCS Temp Location
These variables define the input XML file path, the output BigQuery table, and the temporary location in Google Cloud Storage for intermediate files.
|
1 2 3 |
input_path = 'C:/Users/leoan/Downloads/company_xml.xml' output_table = 'xmlproject-424914:xml_dataset.xml_data_table' gcs_temp_location = 'gs://xmlbucket101/temp/' |
input_path: The local path to the XML file that contains the data to be processed.
Sample xml looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
<?xml version="1.0" encoding="UTF-8"?> <org> <company id="1"> <employee id="1"> <name>John Doe</name> <position>Manager</position> </employee> <employee id="2"> <name>Jane Smith</name> <position>Developer</position> </employee> <employee id="3"> <name>Mike Johnson</name> <position>Designer</position> </employee> <employee id="4"> <name>Alice Brown</name> <position>Tester</position> </employee> <employee id="5"> <name>Chris Davis</name> <position>Support</position> </employee> </company> <company id="2"> <employee id="1"> <name>Hans Wurscht</name> <position>Hansel</position> </employee> <employee id="2"> <name>Eva Braun</name> <position>Developer</position> </employee> <employee id="3"> <name>Peter Pan</name> <position>Designer</position> </employee> <employee id="4"> <name>Mary Poppins</name> <position>Tester</position> </employee> <employee id="5"> <name>James Bond</name> <position>Support</position> </employee> </company> </org> |
output_table: The BigQuery table where the processed data will be loaded. It is specified in the format project:dataset.table.
gcs_temp_location: The Google Cloud Storage bucket and folder where intermediate files will be stored temporarily during processing.
Parsing and Cleanup Functions
These functions handle the conversion of XML data into a dictionary and clean up the data to match the required schema for BigQuery.
Parsing Function:
|
1 2 3 4 |
def parse_into_dict(xmlfile): with open(xmlfile) as ifp: doc = xmltodict.parse(ifp.read()) return doc |
parse_into_dict: This function reads the XML file and uses the xmltodict library to parse it into a Python dictionary.A Python dictionary is a collection of key-value pairs, where each key is unique. In our case, the XML structure is converted into a nested dictionary that mirrors the XML hierarchy.
The parse_into_dict function converts our source XML into the following Python dictionary:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
{ 'org': { 'company': [ { '@id': '1', 'employee': [ {'@id': '1', 'name': 'John Doe', 'position': 'Manager'}, {'@id': '2', 'name': 'Jane Smith', 'position': 'Developer'}, {'@id': '3', 'name': 'Mike Johnson', 'position': 'Designer'}, {'@id': '4', 'name': 'Alice Brown', 'position': 'Tester'}, {'@id': '5', 'name': 'Chris Davis', 'position': 'Support'} ] }, { '@id': '2', 'employee': [ {'@id': '1', 'name': 'Hans Wurscht', 'position': 'Hansel'}, {'@id': '2', 'name': 'Eva Braun', 'position': 'Developer'}, {'@id': '3', 'name': 'Peter Pan', 'position': 'Designer'}, {'@id': '4', 'name': 'Mary Poppins', 'position': 'Tester'}, {'@id': '5', 'name': 'James Bond', 'position': 'Support'} ] } ] } } |
In this dictionary:
- The root element <org> is represented as a key with its value being another dictionary.
- The <company> elements are represented as a list of dictionaries within the org key.
- Each <employee> element is a dictionary within the respective company’s list of employees.
- Attributes such as id in <company> and <employee> are represented with keys prefixed by @.
Cleanup Function:
|
1 2 3 4 5 |
def cleanup(x): y = copy.deepcopy(x) if '@id' in y: y['id'] = y.pop('@id') return y |
The cleanup function ensures the data conforms to BigQuery’s schema by renaming fields that contain invalid characters. Specifically, it renames the @id field to id.
Data Extraction Function
This function extracts employee data from the parsed XML document and associates each employee with their respective company ID.
|
1 2 3 4 5 6 |
def get_employees(doc): for company in doc['org']['company']: company_id = company['@id'] for employee in company['employee']: employee['company_id'] = company_id yield cleanup(employee) |
get_employees: This function iterates through the company and employee records in the parsed XML document. It adds the company ID to each employee record and applies the cleanup function to each employee.
Performance and scalability concerns
Iteratively looping multiple over nested XML elements is not a scalable approach. It will not perform well for nested XML and / or large volumes of XML
BigQuery Schema Definition
The schema defines the structure of the BigQuery table for the output of XML parsing.
|
1 2 3 4 5 6 7 8 |
table_schema = { 'fields': [ {'name': 'id', 'type': 'STRING', 'mode': 'NULLABLE'}, {'name': 'name', 'type': 'STRING', 'mode': 'NULLABLE'}, {'name': 'position', 'type': 'STRING', 'mode': 'NULLABLE'}, {'name': 'company_id', 'type': 'STRING', 'mode': 'NULLABLE'}, ] } |
table_schema: This variable defines the schema of the BigQuery table, specifying the field names, types, and constraints (nullable or not).
Apache Beam Pipeline
This section defines and runs the Apache Beam pipeline that processes the XML file and loads the data into BigQuery.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
def run(argv=None): parser = argparse.ArgumentParser() parser.add_argument( '--output', required=True, help=( 'Specify BigQuery table in the format project:dataset.table')) known_args, pipeline_args = parser.parse_known_args(argv) pipeline_options = PipelineOptions(pipeline_args) google_cloud_options = pipeline_options.view_as(GoogleCloudOptions) google_cloud_options.temp_location = gcs_temp_location with beam.Pipeline(argv=pipeline_args, options=pipeline_options) as p: employees = (p | 'files' >> beam.Create([input_path]) | 'parse' >> beam.Map(lambda filename: parse_into_dict(filename)) | 'employees' >> beam.FlatMap(lambda doc: get_employees(doc)) | 'log' >> beam.Map(log_element)) employees | 'tobq' >> beam.io.WriteToBigQuery( known_args.output, schema=table_schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND, create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED) |
Pipeline Options:
- PipelineOptions: Configures the pipeline execution, including Google Cloud-specific options.
- google_cloud_options.temp_location: Specifies the temporary location in GCS for intermediate files.
Pipeline Steps:
- beam.Create([input_path]): Creates a PCollection from the input XML file path.
- beam.Map(lambda filename: parse_into_dict(filename)): Reads and parses the XML file into a dictionary.
- beam.FlatMap(lambda doc: get_employees(doc)): Extracts and processes employee data from the parsed XML.
- beam.Map(log_element): Logs each element for debugging purposes.
- beam.io.WriteToBigQuery: Writes the processed data to the specified BigQuery table with the defined schema
Execution
The script is executed by calling the run function with the appropriate command-line arguments.
|
1 2 3 4 |
if __name__ == '__main__': import sys logging.getLogger().setLevel(logging.INFO) run(sys.argv + ['--output', output_table]) |
Logging Configuration: Sets the logging level to INFO to capture relevant information during execution.
Once we run the script it will create the target table in BigQuery and populate the table with the data from the XML.
Using Google Dataflow for XML to BigQuery Processing
Apache Beam is based on the concept of Runners.
In the previous example we used a local install of Apache Beam which uses what is called the DirectRunner to execute the Beam pipeline. The Beam pipeline is the script we created.
Beam offers other runners as well, e.g. Spark or Flink. The runner that is interesting for us in the context of BigQuery is the Google DataFlow runner. This runner is hosted on the Google cloud and can take the Beam pipeline script we created in the previous section and execute it on the Google Cloud Platform (GCP).
By selecting the Dataflow runner as your execution environment, your Beam pipeline can leverage Dataflow’s managed service, which handles resource management, auto-scaling, and job monitoring.
Running Apache Beam without Dataflow typically involves executing the pipeline locally (direct runner) or on a self-managed cluster. Both the direct runner and the Dataflow runner share the core logic: parsing XML data, extracting details, and loading this information into BigQuery. The pipeline structure—reading input, processing data, and writing output—remains the same. They both use transforms like ParDo, Map, and FlatMap, and employ xmltodict for XML parsing. Logging and error handling are similarly handled to ensure reliability.
The key difference is in how the pipeline runs. With Dataflow, your Beam pipeline runs on Google Cloud’s managed service, which automatically scales to handle large data processing tasks and integrates with other Google Cloud services. In contrast, running Beam pipelines locally gives you direct control over execution but does not automatically scale, making it better suited for smaller tasks or environments without cloud infrastructure. Additionally, when using Dataflow you need to set cloud-specific configurations like temp_location and staging_location for managing resources, while local execution uses simpler file handling without relying on cloud storage.
BigQuery XML parsing using a Javascript UDF
BigQuery supports JavaScript UDFs, which you can use to parse XML data. This approach is suitable for smaller datasets where performance is not a primary concern. It works well for simple use cases with simple XML structures.
You can store XML as a STRING data type and then use a UDF to convert the XML to JSON. Once the data is in JSON you can use BigQuery’s native features for working with JSON and arrays to query and parse the data. Once the XML is converted to JSON, you can use standard BigQuery SQL functions like JSON_EXTRACT to flatten the data.
We have written the following JavaScript User-Defined Function (UDF) to parse XML data in BigQuery. The script consists of the following steps:
- Define a JavaScript UDF to convert XML to JSON.
- Use the UDF to convert XML to JSON.
- Extract specific fields from the parsed JSON and flatten the data
Here is the code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
CREATE TEMPORARY FUNCTION XML_TO_JSON(xml STRING) RETURNS STRING LANGUAGE js AS """ var data = fromXML(xml); return JSON.stringify(data); """ OPTIONS( library="gs://xmlbucket101/from-xml.js" ); WITH xml_data AS ( SELECT xml_string FROM `xmlproject-424914.xml_dataset.xml_table` ), json_data AS ( SELECT JSON_EXTRACT_ARRAY(xml_to_json(xml_string), '$.books.book') AS books_array FROM xml_data ), flattened_data AS ( SELECT book AS book_json FROM json_data, UNNEST(books_array) AS book ) SELECT JSON_EXTRACT_SCALAR(book_json, '$.title') AS book_title, JSON_EXTRACT_SCALAR(book_json, '$.author') AS book_author, JSON_EXTRACT_SCALAR(book_json, '$.year') AS book_year, JSON_EXTRACT_SCALAR(book_json, '$.price') AS book_price FROM flattened_data; |
What follows are step by step explanations of the script
JavaScript UDF Definition
The UDF XML_TO_JSON is defined to convert XML strings to JSON strings. We use the fromXML function from an open source JavaScript XML parser to parse the XML.
|
1 2 3 4 5 6 7 8 9 |
CREATE TEMPORARY FUNCTION XML_TO_JSON(xml STRING) RETURNS STRING LANGUAGE js AS """ var data = fromXML(xml); return JSON.stringify(data); """ OPTIONS( library="gs://xmlbucket101/from-xml.js" ); |
Input: A STRING containing XML data.
Output: A STRING containing the corresponding JSON data.
External Library: The function uses from-xml.js which we put into a bucket in Google Cloud Storage (gs://xmlbucket101/from-xml.js).
Defining XML Data
The xml_data Common Table Expression (CTE) retrieves the XML data stored in table xmlproject-424914.xml_dataset.xml_table.
|
1 2 3 4 5 6 |
WITH xml_data AS ( SELECT xml_string FROM `xmlproject-424914.xml_dataset.xml_table` ) |
First make sure that XML data is loaded into a table as a string as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
-- Step 1: Create the Table CREATE TABLE `xmlproject-424914.xml_dataset.xml_table` ( xml_string STRING ); -- Step 2: Insert XML Data into the Table INSERT INTO `xmlproject-424914.xml_dataset.xml_table` (xml_string) VALUES ('''<books> <book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book> <title>Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </books>'''); |
Important limitation of STRING data type
In Google BigQuery, the STRING data type can store a maximum of 1 MB of UTF-8 encoded text. This means that your UTF-8 encoded XML documents must not be greater than 1 MB in size. The 1 MB limit is for raw rather than compressed XML.
Converting XML to JSON
The json_data CTE converts the XML string to a JSON array using the XML_TO_JSON UDF and then extracts specific parts of the resulting JSON.
|
1 2 3 4 5 6 |
json_data AS ( SELECT JSON_EXTRACT_ARRAY(xml_to_json(xml_string), '$.books.book') AS books_array FROM xml_data ) |
Explanation:
JSON_EXTRACT_ARRAY is a BigQuery function that extracts an array from a JSON string.
xml_to_json(xml_string) produces a JSON string representing the XML data.
The second argument, ‘$.books.book’, is a JSONPath expression that specifies the path to extract from the JSON string:
- $. indicates the root of the JSON document.
- books is an object at the root level.
- book is an array within the books object.
Therefore, ‘$.books.book’ extracts the array of book objects from the JSON.
Columns:
- books_array: A JSON array containing the book elements.
Flattening JSON Array
The flattened_data CTE flattens the JSON array so that each book element is in its own row.
|
1 2 3 4 5 6 7 |
flattened_data AS ( SELECT book AS book_json FROM json_data, UNNEST(books_array) AS book ) |
Purpose: Flattens the JSON array to create individual rows for each book.
Columns:
- book_json: Each book element as a JSON object.
Extracting Fields
The final SELECT statement extracts specific fields (title, author, year, price) from each book JSON object.
|
1 2 3 4 5 6 7 |
SELECT JSON_EXTRACT_SCALAR(book_json, '$.title') AS book_title, JSON_EXTRACT_SCALAR(book_json, '$.author') AS book_author, JSON_EXTRACT_SCALAR(book_json, '$.year') AS book_year, JSON_EXTRACT_SCALAR(book_json, '$.price') AS book_price FROM flattened_data; |
Purpose: Extracts and displays specific fields from each book JSON object.
Columns:
- book_title: The title of the book.
- book_author: The author of the book.
- book_year: The publication year of the book.
- book_price: The price of the book.
The resulting table looks like this in bigquery:
Automating XML parsing on BigQuery
Manual versus automated XML conversion
To convert XML data, you can choose between two main methods: manual and automatic.
When you convert XML files manually, you need to have a deep understanding of XML and be prepared to invest a lot of time and resources. You start by analyzing the XML and its schema, then you define mappings and create tables in a database. On top of that, you also have to write code to parse the XML and insert the data into these tables.
On the other hand, automating the conversion process with tools can increase the speed of the conversion, decrease the need to expertise, and automated conversion tools can handle large volumes of data, decrease errors and easily handle complex schemas. We have created a video about converting FPML data standards that can contain hundreds of tables.
Benefits of using a no-code XML conversion approach
Choosing a no-code method to XML conversion provides various benefits. It improves efficiency by automating data processing, which is much faster than manual methods. This automation not only decreases the possibility of human error, but it also saves money on labour by reducing the need for manual coding. Also, no-code tools are built to scale easily, handling increases in data volume without requiring additional resources. They simplify the conversion process by allowing people without coding skills to do complex XML transformations.
When to use manual approach
- Simple XML and Schema: Best for straightforward XML structures that are easy to convert manually.
- Occasional Conversions: Suitable for infrequent XML data conversions as needed.
- Smaller Amounts of Data: Ideal for processing limited volumes of XML data.
- Plenty of conversion Time: Ideal for extensively testing and validating the conversion.
- Dedicated XML Expertise: Ideal for teams of XML specialists who can concentrate entirely on the conversion process.
When to use an automated approach
- High Volume Data: Ideal for scenarios requiring regular processing of huge amounts of XML data.
- Complex Schemas: Useful for dealing with complex XML schemas that would be too time-consuming to manually convert.
- Frequent Updates: Useful in scenarios where XML data is often updated or received and conversion times are critical.
- Limited XML Expertise: Best suited for teams without in-depth XML schema knowledge or if resources are better directed to other areas of development.
No-code XML conversion with Flexter
In this section we automate the XML parsing on BigQuery using Flexter, our no-code XML conversion tool for enterprise use cases. We will convert a sample of SDMX-ML

SDMX (Statistical Data and Metadata eXchange) is an international initiative that aims at standardising and modernising (“industrialising”) the mechanisms and processes for the exchange of statistical data and metadata among international organisations and their member countries.
You can download a sample of SDMX-ML (XML) files and the corresponding schema files (XSD) from the SDMX website.
Converting XML to BigQuery with Flexter is a fully automated process. It requires two simple steps.
- Create a Flexter Data Flow. The whole process is fully automated and you don’t need to create manual mappings
- Convert your XML documents
The figure below summarises the two steps
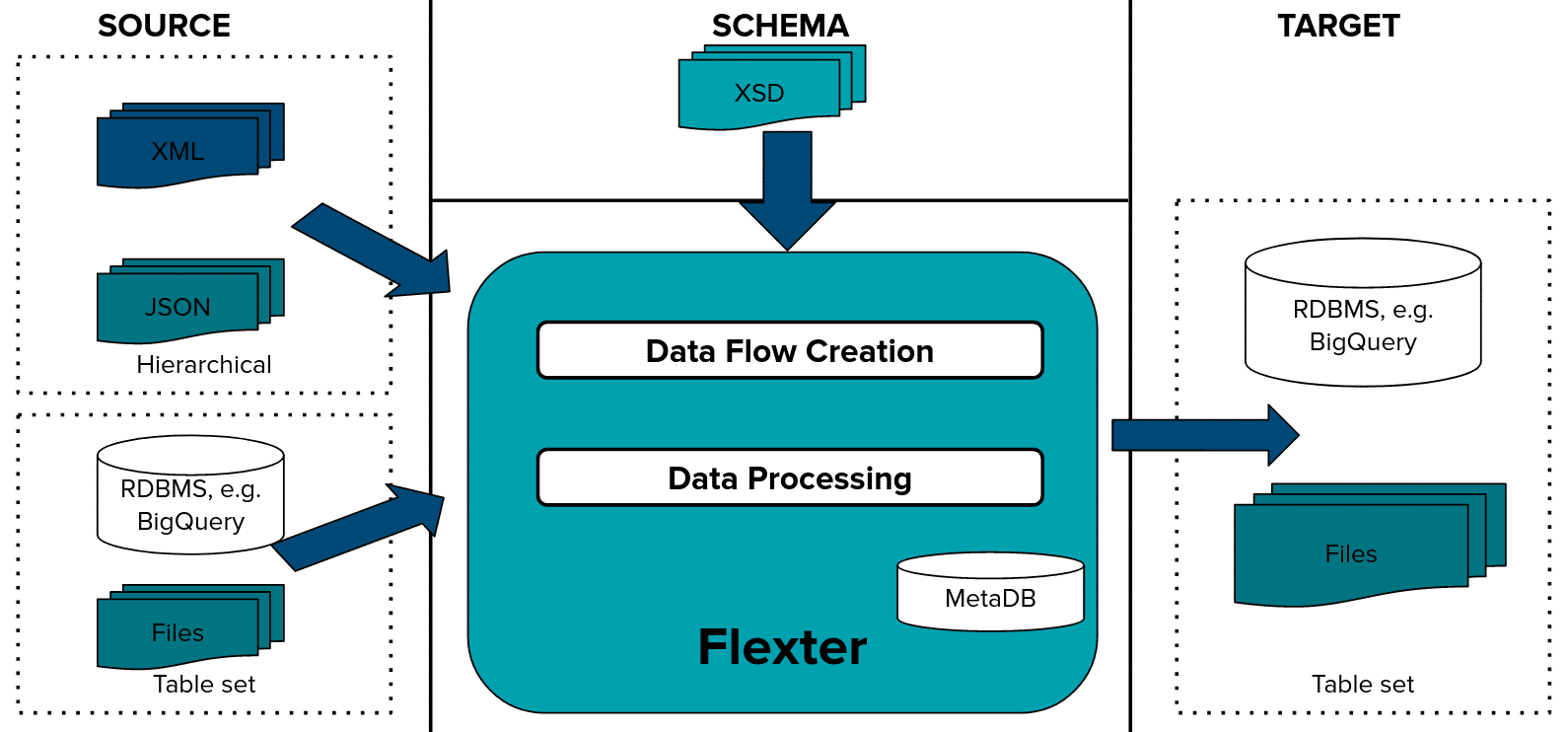
Data Flow creation
First we generate a Data Flow using an XSD and/or a sample of representative XML files. A Flexter Data Flow is a logical target schema that maps the elements from the XML documents to BigQuery table columns. Both are stored in Flexter’s metadata catalog.
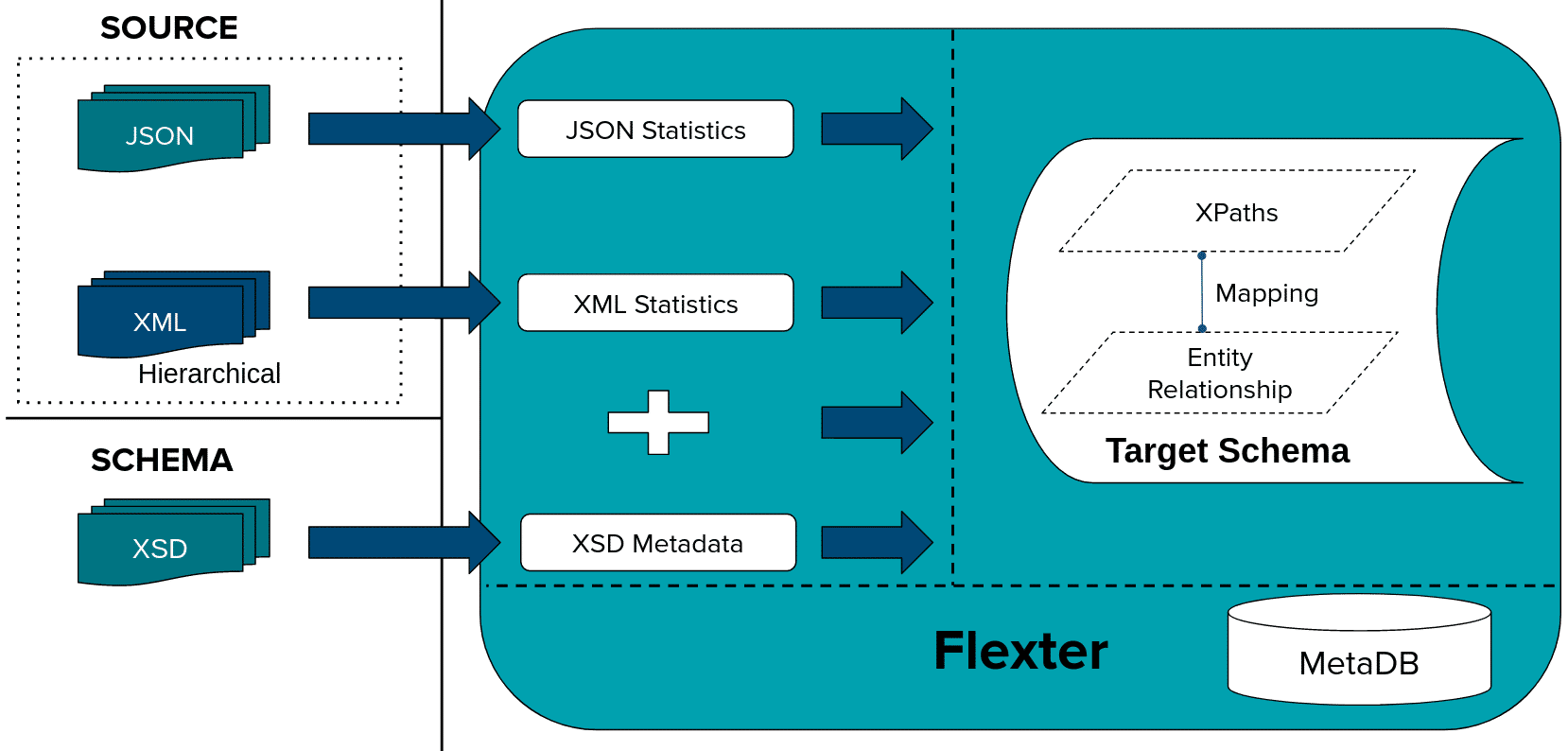
Flexter can generate a target schema from an XSD, a sample of XML files or a combination of the two.
We issue the following command to Flexter with the location of our XSD and XML files
|
1 |
xsd2er -g3 -a SDMX\ XSD.zip SDMX\ XML.zip |
XML processing
The Data Flow has been created. We are now ready to convert our XML documents to a BigQuery relational format (tables and columns).
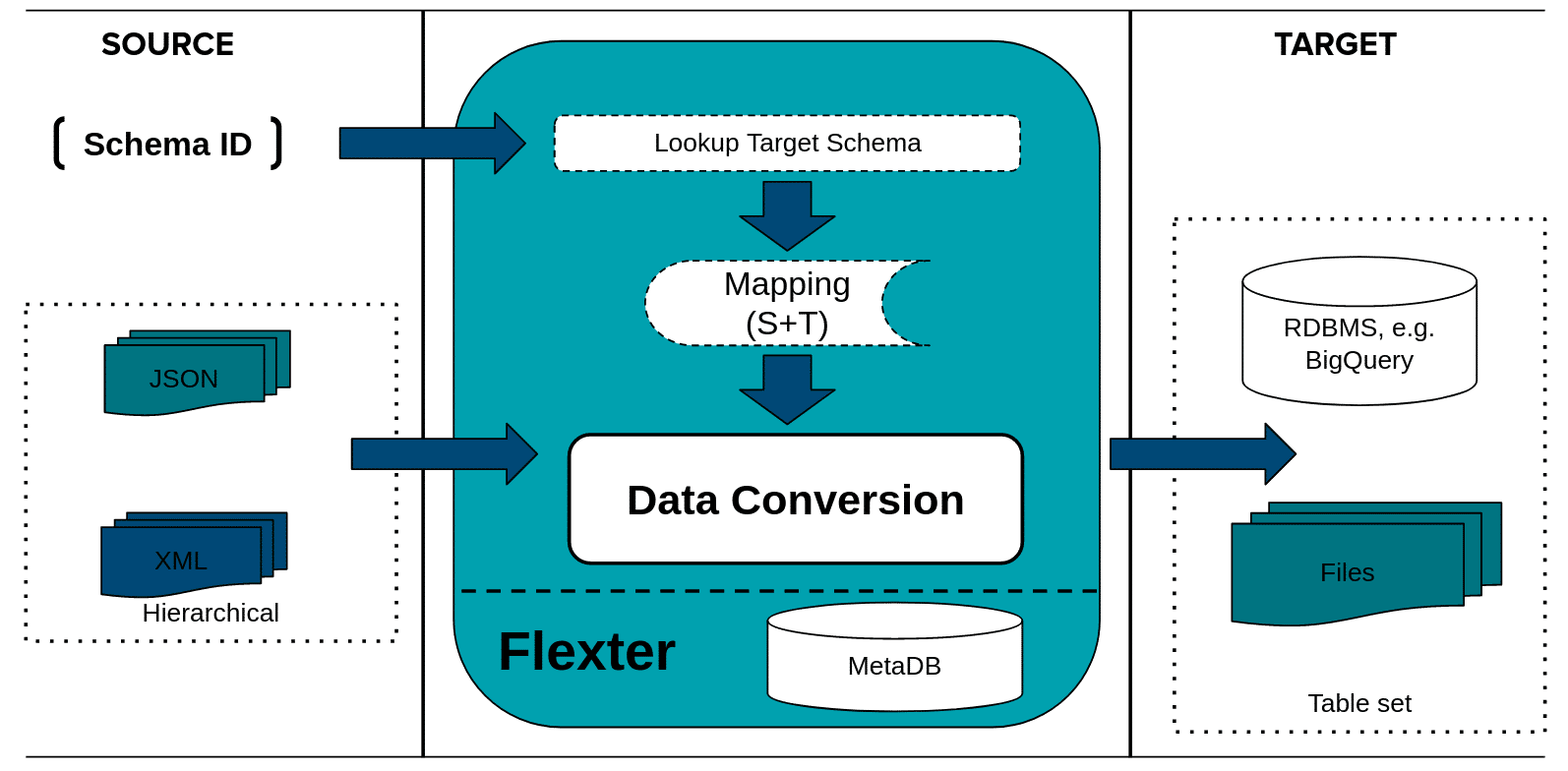
We pass in the schema_id from the Data Flow we created in the previous step, the connection details to BigQuery, and the path to the XML documents we want to convert
|
1 2 3 |
export GOOGLE_APPLICATION_CREDENTIALS="$PWD/auth.json xml2er -x <schema_id> -o "bigquery://sdmx_stats?temp=sonra_temp" SDMX\ XML.zip |
Query the data
Next we can familiarise ourselves with the target schema using the ER diagram that Flexter has generated.
In a final step we can query the data directly on BigQuery or apply some downstream processing to it.
That was easy. A simple two step process to convert complex XML data based on industry data standards to a readable format on BigQuery. Happy querying.
Try Flexter no-code XML conversion online for free.
Further Reading
XML conversion
XML Converters & Conversion – Ultimate Guide (2024)
Converting XML and JSON to a Data Lake
How to Insert XML Data into SQL Table?
The Ultimate Guide to XML Mapping in 2024
Optimisation algorithms for converting XML and JSON to a relational format
Re-use algorithms for converting XML and JSON to a relational format
Flexter
Must have XML converter features
XML on BigQuery
ecobee chooses Flexter to make valuable IoT data in XML accessible to BigQuery users for analytics


