Converting XSD to database schema: your guide to creating relational models from XML
When it comes to turning your XML/XSD into a relational schema, you’ve got a few paths you can take:
- Straight from the XSD: This method covers all possible XPaths and XML elements, which is great for completeness but can lead to a massive relational target schema that might be overkill.
- No XSD? No problem: Sometimes, you don’t have an XSD handy. In those cases, you can create a schema based on a sample of XML files.
- Best of both worlds: If you can, using both the XSD and some XML samples is a smart move. The XML samples act like a reality check for the XSD, helping you ditch the unused parts and keep what’s actually needed.
We’re going to dive into each of these methods, from their pros to their cons, so that you can figure out which one works best for you. Throughout, we’ll also be taking you through how a dedicated XML converter like Fletcher can do the heavy lifting for you.
Suggested reading: Find out everything you need to know about XML mapping in 2024 with our comprehensive guide!
Creating a relational model from XSD only
When you decide to use an XSD (AKA your Source Schema) to build a relational target schema, there are some ups and downs to think about:
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
The good
- Comprehensive coverage: Making a target schema out of an XSD means you’re all set to handle any XML document that fits the XSD. All the possible data points from the input are mapped to the output with their cardinality and datatypes known. Note this remains true as long as the XML Source Data fully conforms to the XSD definitions used.
- Speedy setup: You don’t need to have a representative sample of XML docs to show up. You can jump straight to making your target schema without them, which is a huge time-saver.
- Smart organisation: It gets even better because this method can spot shared types across your data and put them together in one table in your target schema. This neat trick makes everything cleaner and simpler to manage.
The not-so-good
- Overkill alert: If your XSD is one of those big ones used in industry standards, it’s probably covering a zillion business processes. But here’s the catch – your company is likely only using a slice of those. So, you end up with a target schema packed with tables and columns you’ll never use. It’s like having a toolbox where you only use the hammer.
- Memory munchers: Got XPaths in your XSD that go on and on, looping back on themselves? Preparing those for your target schema can be a real memory hog.

How Flexter can help you
And how do we tackle making a relational model from just an XSD with Flexter?
It’s a one-command wonder. You throw in some necessary and optional parameters, and Flexter does its magic, crafting the target schema and mapping all by itself.
Let’s look at how we can create the relational target model with the Elevate optimization.
|
1 |
xsd2er -g1 <INPUTPATH> |
Example of output:
|
1 2 3 4 5 6 7 8 9 10 11 |
# schema origin: 4 logical: 2 job: 4 # statistics startup: 4107 ms parse: 6855 ms xpath stats: 436 ms doc stats: 4744 ms xpaths: 19 | map:0.0%/0 new:100.0%/19 documents: 1 | suc:100.0%/1 part:0.0%/0 fail:0.0%/0 |
At the end of the successful XSD analysis process, Flexter prints out the ID of the generated model.
Example of target schema:
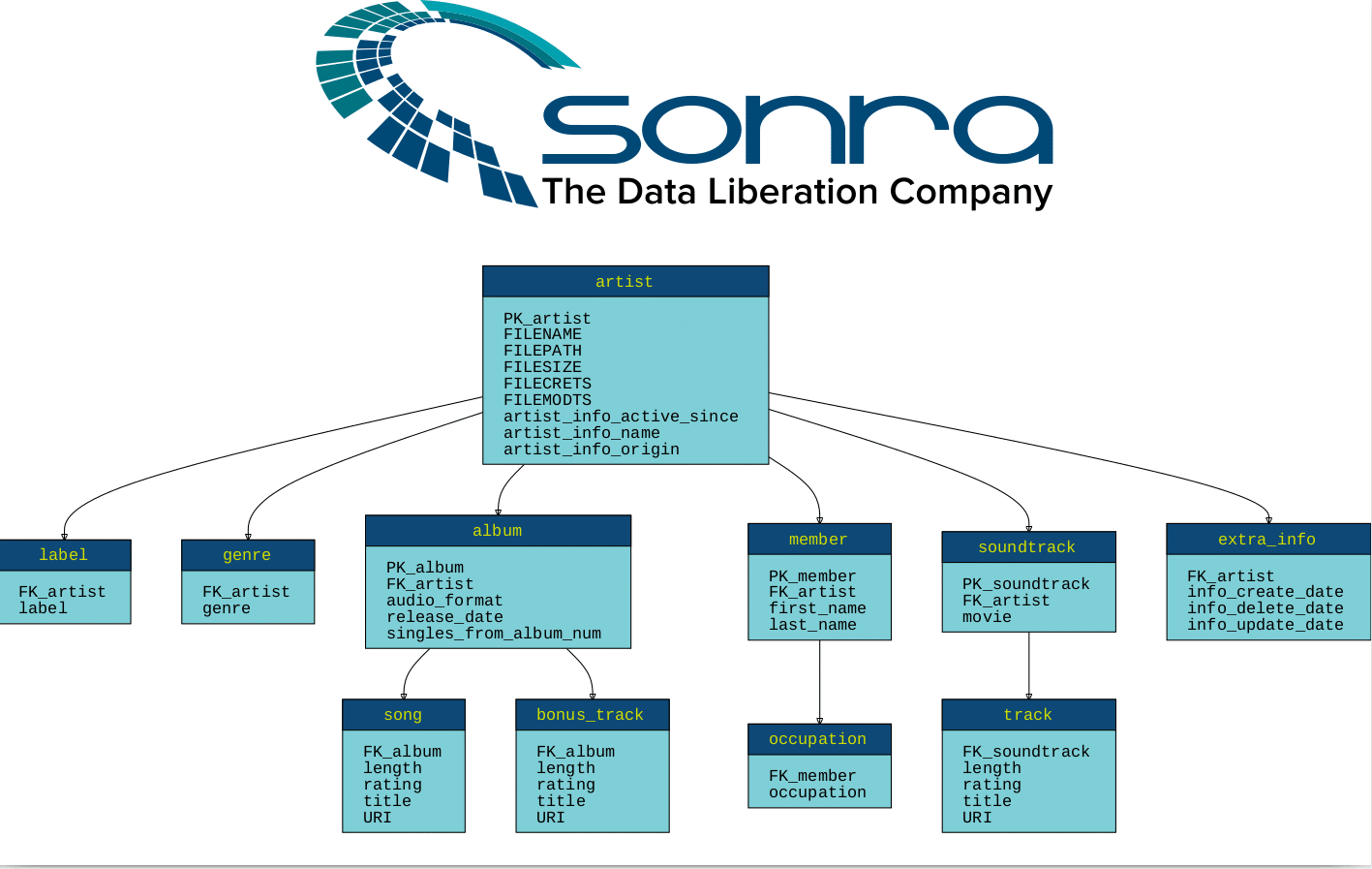
Creating target schema from XML only
You can transform XML documents even if you don’t have an XSD. And for JSON files, that’s pretty much your go-to since few JSON documents come with a JSON schema.
You need a representative sample of XML documents that have coverage of all possible XPaths. Or, if you’re feeling thorough, just use all the XML or JSON docs you’ve got.
Let’s break down the highs and lows of using XML samples inside Flexter:
The good
- XSD-independent: You can get your XML sorted out without XSD.
- JSON schema creation: You can create a target schema for JSON files as well.
- Just the essentials: The metadata it whips up is super streamlined – only includes stuff actually in your data.
- Mismatch fixer: It may offer an alternative solution for scenarios where the XSD and XML samples don’t match, or have different versions.
- Recursive depth analysis: It’s ideal for recursive XPaths to determine the depth of the hierarchy
The not-so-good
- Limited functionality: You can’t apply Flexter’s reuse optimisation.
- Homework required: You’ve got to gather some intel on your XML/JSON first, which means figuring out a good sample or, worst-case, using all your data.

How Flexter can help you
Let’s get hands-on with Flexter and create a target schema from XML documents only.
Point Flexter to your sample of XML documents and it will analyse the sample to derive data types, relationships, constraints etc. and create an optimised relational model from the sample.
|
1 |
xml2er -g1 <INPUTPATH> |
Example of output:
|
1 2 3 4 5 6 7 8 9 10 11 |
# schema origin: 4 logical: 2 job: 4 # statistics startup: 4107 ms parse: 6855 ms xpath stats: 436 ms doc stats: 4744 ms xpaths: 19 | map:0.0%/0 new:100.0%/19 documents: 1 | suc:100.0%/1 part:0.0%/0 fail:0.0%/0 |
Example of target schema:
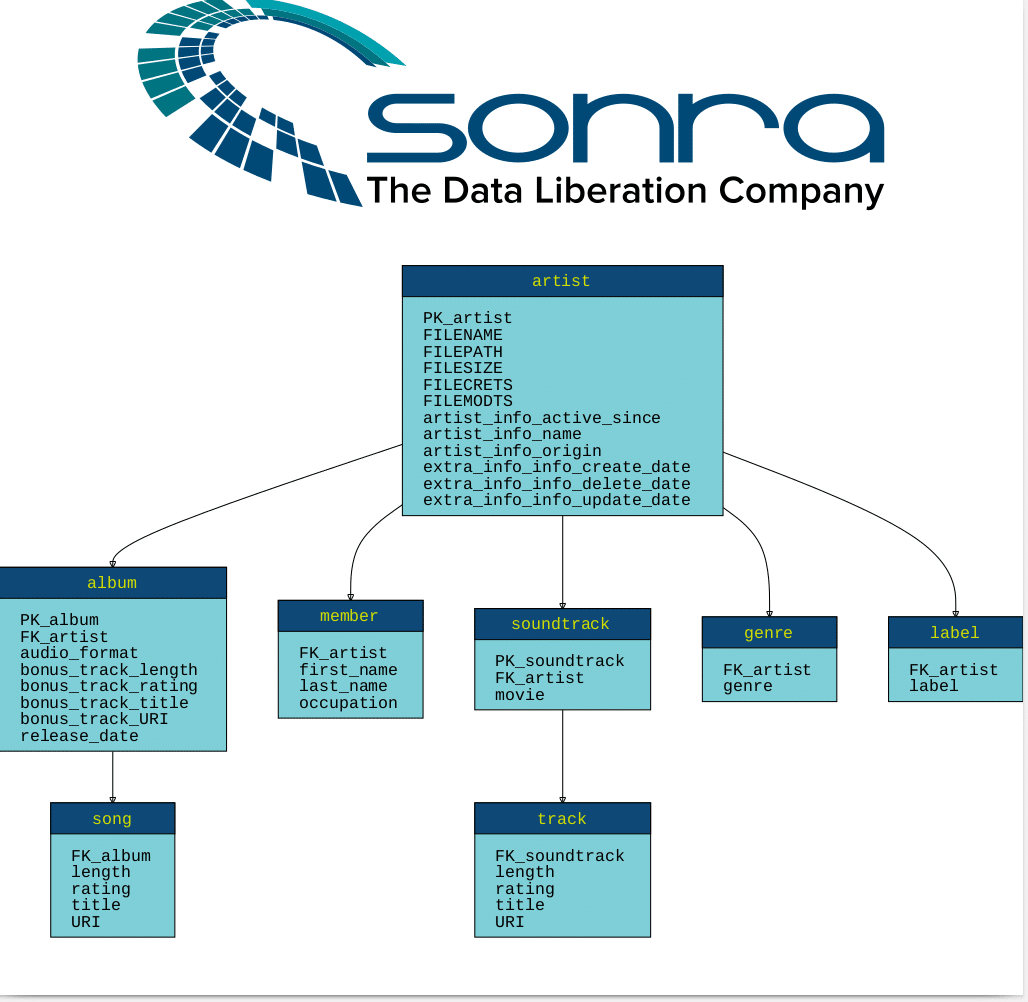
Creating target schema from XSD and XML
You can also create a target schema by combining the information from the XSD with the intel from the XML documents. This combo method is pretty neat because you get to merge insights from both the data and the schema.
The good
- Comprehensive and informed: You get a super smart logical schema, thanks to info from both sources.
- Easy to navigate: The Target Schema gets all neat and streamlined. You can spice up the XSD info with what you learn from the XML data. This means you only bother with the XPaths that are actually being used inside the XML.
- Loopy XPath expert: It’s great at handling those loopy XPaths in XSDs (deep nesting), using some stats magic. Plus, you can use Flexter’s reuse optimisations.
The not-so-good
- Heavy prep work: You need to do some homework on your XML/JSON data before it can do its thing. If getting a good mix of XML files is a headache, you might have to use all your XML data.
How Flexter can help you
Let’s have a look at how Flexter handles this.
First, Flexter gathers information from a sample of XML documents. You can repeat this step as many times as needed, feeding new samples of XML documents to Flexter each time.
|
1 |
xml2er <INPUTPATH> |
Example of output:
|
1 2 3 4 5 6 7 8 9 10 |
# schema origin: 4 job: 4 # statistics startup: 4107 ms parse: 6855 ms xpath stats: 436 ms doc stats: 4744 ms xpaths: 19 | map:0.0%/0 new:100.0%/19 documents: 1 | suc:100.0%/1 part:0.0%/0 fail:0.0%/0 |
Next we augment the information from the XML documents with intel from the XSD, combine the two and create the target schema.
|
1 |
xsd2er -k4 -g1 <INPUTPATH> |
Example of output:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# schema origin: 7 logical: 3 job: 6 # statistics load: 1608 ms stats: 40 ms parse: 368 ms build: 121 ms write: 47 ms map: 128 ms xpaths: 16 |
The generated target schema can be used in a Conversion task to convert XML documents to a relational Target Schema.
Example of target schema:
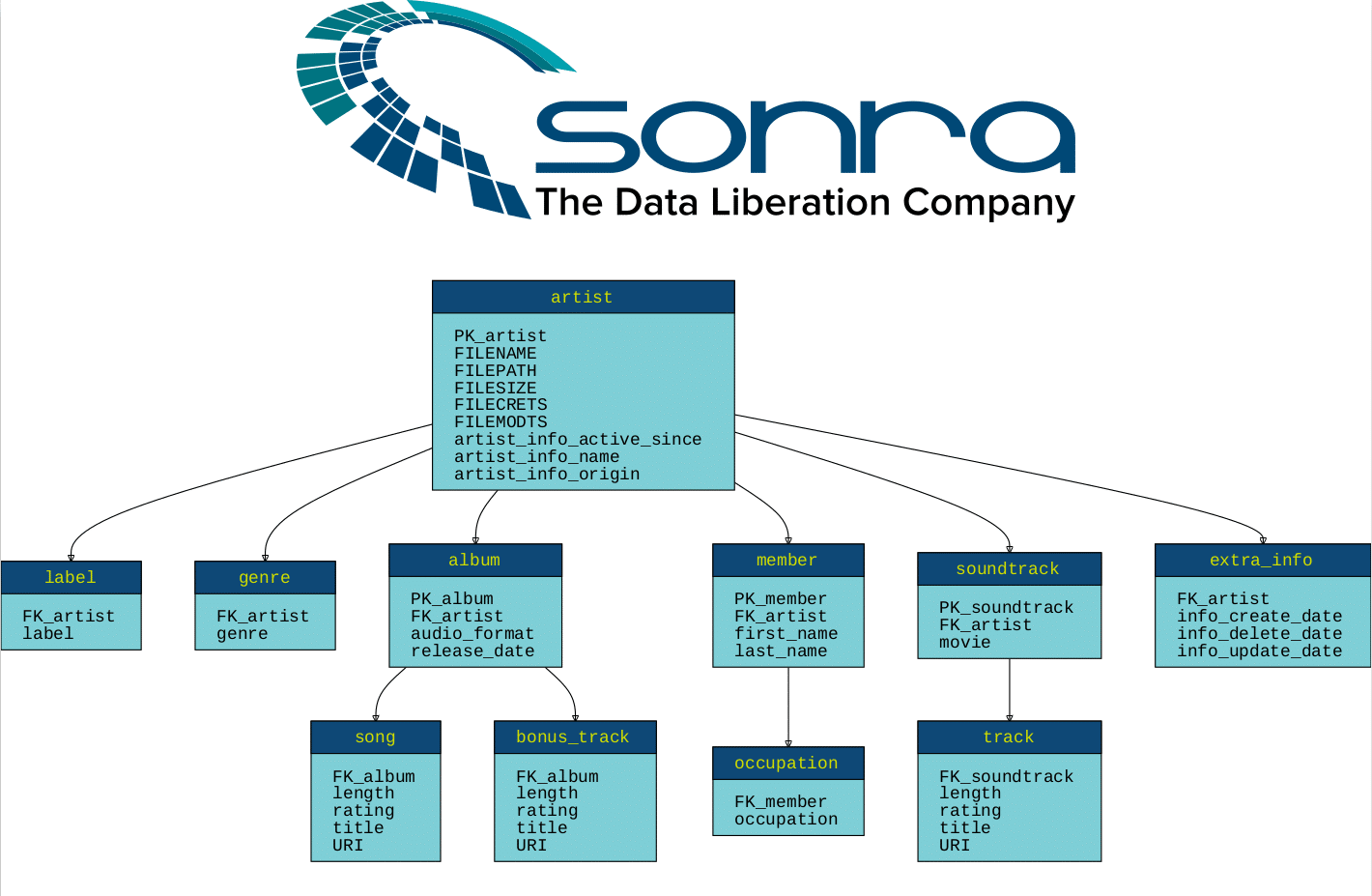
Pro tip: We have made the files we used in this blog post available for download!
Make it easy with Flexter
Getting from XML documents or XSDs to a relational data model is just one piece of the whole XML conversion puzzle. You start by analyzing the XML and any XSD you’ve got, then move on to mapping those XML elements to table columns before looking at the actual data conversion, testing, error logging, and documentation.
Doing all this by hand? Yeah, it’s a slog. But here’s a little secret: Flexter can be your shortcut.
Flexter can take your XSD, XML, or both, and do all the heavy lifting for you. It not only builds the relational model but also converts the data and even whips up some handy docs like ER diagrams and maps showing where everything came from and where it’s headed. Talk about a time saver!
Why not give the free online version of our XML converter Flexter a try? See for yourself what XML conversion software can do for you. Alternatively, talk directly to one of our XML conversion experts to discuss your use case in detail.


