Best Way to Load & Convert XML Data to Oracle Tables


It’s very easy to get lost in the Oracle features for working with XML. The following questions come up frequently:
- What are my options for working with XML in Oracle?
- What option is suitable for my use case?
In this blog post we shed some light on these questions by examining the various Oracle XML features and making recommendations which option to pick for your use case.
We deep dive into the following topics
- How to store XML inside the Oracle database using XMLTYPE and CLOB
- How to load and insert XML data to Oracle tables
- How to read XML from XMLTYPE or CLOB
- How to parse and convert XML to Oracle tables (relational format)
- How to extract values from XML
- How to fully automate the XML conversion process from XML to Oracle tables
Enjoy the article
Oracle also provides XSD support. You can register an XSD and use it to validate your XML.
For those in a hurry we have compiled the key takeaways.
Key takeaways
- Oracle XML-DB is the name of the bundle of features that developers use to build XML applications on Oracle.
- You can store XML data inside an Oracle table as XMLTYPE or CLOB.
- XMLTYPE is the recommended data type as it has dedicated support for XML such as XMLTABLE, XSD, XMLINDEX etc.
- You have four options for loading XML to an Oracle table.
- INSERT INTO…SELECT (IIS) is useful for ad hoc queries and testing
- SQL Loader is the recommended approach for bulk loads and production implementations
- External tables are another option but not recommended as they do not support XMLType
- You have three main options to query and read XML data in Oracle.
- XMLTABLE which is part of SQL/XML. This is the recommended way to read XML data in Oracle
- XQuery is useful for complex and niche requirements
- The EXTRACT and EXTRACTVALUE functions are deprecated and not recommended
- Querying XML on the fly is commonly known as schema on read. It is a good approach for sporadic ad hoc querying of XML.
- Converting XML to Oracle tables in a relational format is recommended over the schema on read approach where you frequently query the data. This is known as schema on write.
- Using the schema on write approach you can use SQL to query the data previously locked away in XML in standard Oracle tables
- For complex XML requirements with deeply nested XML, XSDs or XML that is based on industry data standards we recommend an automated approach using an XML converter.
- No code XML conversion eliminates manual coding and simplifies complex XML parsing. Flexter is Sonra’s enterprise XML conversion tool. Find out more about Flexter, try it out yourself for free, or read up on an example of no code XML parsing on Oracle.
Storing XML in the Oracle database
You can directly store XML documents inside the Oracle database. You have two basic options. You can store the data as an XMLType or a CLOB data type.
Use Flexter to turn XML and JSON into Valuable Insights
- 100% Automation
- 0% Coding
XMLType
XMLType was introduced in Oracle 9i. It is a built-in data type specifically designed to store XML data inside the Oracle database.
XMLType is the recommended way to store XML inside Oracle as it has native support for XML:
XSD support: Supports XML Schema validation, ensuring that the XML data adheres to a predefined structure.
Optimised storage: Oracle optimises the storage of XMLType for efficient querying and retrieval. It also supports binary XML storage, which is more space-efficient and faster for many operations.
Indexing: You can create XML-specific indexes (XMLIndex) on XMLType columns to improve query performance.
CLOB for XML
CLOB is a versatile data type in Oracle used to store large text data. It can store XML as plain text but lacks the XML-specific optimisations and features of XMLType
The main advantage of the CLOB data type versus XMLType is its flexibility. You can store any type of large text data, not just XML.
XMLType vs. CLOB for XML
Here is a summary comparison of XMLType to CLOB
Feature | XMLType | CLOB |
|---|---|---|
XML Support | Native XML support with schema validation, XPath, and XQuery | No native XSD support |
Storage Optimization | Optimised for XML storage, supports binary XML | General text storage, not optimised for XML |
Indexing | Support for XMLIndex | No support for XMLIndex |
Performance | Better performance for XML queries and manipulations | Slower performance for XML operations |
Complexity | More complex to set up and manage | Simpler to use and manage |
Flexibility | Designed for XML only | Can store any large text data |
Loading XML data into an Oracle table
Inserting XML into an Oracle table
This method involves inserting XML data row by row into Oracle database tables. It gives flexibility but has slow performance for large datasets.
It is great for ad hoc use cases where you need to quickly load XML data into an Oracle table for testing and on the fly querying. It is not recommended for production use cases.
Step 1. Create a table with XMLType data type to store XML data.
|
1 2 3 4 |
CREATE TABLE xml_tab ( id NUMBER, xml_data XMLTYPE ); |
Step 2. Insert XML text into the ‘xml_tab’ table
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
INSERT INTO xml_tab (id, xml_data) VALUES (1, XMLType('<University id="TUD"> <Faculty id="Engineering"> <Department id="ComputerScience"> <Course>Introduction to Programming</Course> <Course>Algorithms and Data Structures</Course> </Department> <Department id="ElectricalEngineering"> <Course>Circuit Analysis</Course> <Course>Electromagnetics</Course> <Course>Control Systems</Course> </Department> <ResearchGroup id="ArtificialIntelligence"> <Project>Machine Learning Advances</Project> <Project>Neural Network Optimization</Project> <Project>AI Ethics and Society</Project> </ResearchGroup> <ResearchGroup id="Nanotechnology"> <Project>Nano-materials Engineering</Project> <Project>Quantum Computing</Project> </ResearchGroup> </Faculty> <AdministrativeUnit id="Library"> <Service>Book Lending</Service> <Service>Research Assistance</Service> </AdministrativeUnit> <AdministrativeUnit id="IT"> <Service>Campus Network</Service> <Service>Helpdesk</Service> </AdministrativeUnit> </University> ')); |
|
1 |
SELECT * FROM xml_tab |


Loading XML files with SQL*Loader
SQL*Loader is a utility provided by Oracle that enables high-speed importing from XML files into Oracle database tables. It allows for efficient loading of large volumes of data in various formats, including XML.
SQL*Loader is the recommended tool to load XML files into Oracle tables. External tables only support the CLOB data type when loading XML files but not the more advanced XMLType data type which has specifically been created for storing XML.
When using SQL*Loader you specify a control file that defines the data format and mapping to the database table.
Step 1. Create a table with XMLType data type to store XML data.
|
1 2 3 4 |
CREATE TABLE xml_tab( FILENAME VARCHAR2(255), xml_data XMLTYPE ) |
Step 2. Prepare a control file (.ctl) for the SQL*Loader
|
1 2 3 4 5 6 7 8 9 10 11 |
LOAD DATA INFILE * REPLACE INTO TABLE xml_tab FIELDS TERMINATED BY ',' TRAILING NULLCOLS ( FILENAME, xml_data LOBFILE(FILENAME) TERMINATED BY EOF ) BEGINDATA /home/oracle/Downloads/DUMPS/sample.xml |
Step 3. Run below SQL*Loader command to load sample.xml file into the xml_tab1 table.
|
1 2 3 4 5 |
$ sqlldr system/oracle@orcl control=control_file.ctl log=loader_log.log SQL*Loader: Release 11.2.0.4.0 - Production on Fri Feb 2 10:06:46 2024 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. Commit point reached - logical record count 1 |
|
1 |
SELECT * FROM xml_tab |

Loading XML files with External Tables
External tables in Oracle offer a convenient way to access data stored in external files, treating them as if they were regular tables within the database. While DML operations aren’t supported on external tables, they work well for querying, joining, and sorting operations. XML files can integrate into a table as a CLOB column (XMLType data type is not supported for external tables). Once the external table has been created we can query the data, e.g. by creating Views.
This integration facilitates blending of XML data with relational data in Oracle databases. External tables are useful in data warehouse ETL processes, eliminating staging requirements and boosting performance through parallel querying.
Let’s guide you through the process step by step
Step 1: Create XXAA_XML directory in bin location and modify the permissions.
|
1 2 3 |
$ mkdir XXAA_XML $ chmod 777 XXAA_XML $ cd 777 XXAA_XML |
Step 2: Upload the XML files into the XXAA_XML directory
|
1 2 3 |
XXAA_XML]$ ls -lrt total 8 -rw-rw-rw-. 1 oracle oracle 1208 Feb 1 07:57 sample.xml |
Step 3: Run below command to create a data file (.dat) in the bin folder
|
1 2 3 |
$ ls -l *.xml | awk '{print "\/XXAA_XML\/"$9}' > /u01/Middleware/ODI12c/oracle_common/bin/XXAA_XML_XT_DATA.dat $ cat XXAA_XML_XT_DATA.dat /XXAA_XML/sample.xml |
Step 4. Create a directory for the bin folder
|
1 2 3 4 |
CREATE OR REPLACE DIRECTORY XXAA_XT_DIR AS '/u01/Middleware/ODI12c/oracle_common/bin'; SELECT * FROM ALL_DIRECTORIES WHERE 1=1 AND directory_name = 'XXAA_XT_DIR' |

Step 5. Create External table with above directory ‘XXAA_XT_DIR’ and SQL Loader file ‘XXAA_XML_XT_DATA.dat’
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE xml_tab( FILENAME VARCHAR2(100), XML_DATA CLOB ) ORGANIZATION EXTERNAL( TYPE ORACLE_LOADER DEFAULT DIRECTORY XXAA_XT_DIR ACCESS PARAMETERS ( FIELDS (FILENAME CHAR(100)) COLUMN TRANSFORMS (XML_DATA FROM lobfile (FILENAME))) LOCATION ('XXAA_XML_XT_DATA.dat')) |
|
1 |
SELECT * FROM xml_tab; |
Reading and querying XML data in Oracle
Now that we have loaded some XML files into our Oracle database we can start querying the data. Oracle offers three options for reading and selecting data from XML
- SQL/XML is the most commonly used option and should meet the vast majority of your requirements
- Another option for reading XML data in Oracle are the EXTRACT and EXTRACTVALUE functions. Both of these functions are deprecated and should not be used anymore.
- XQuery is for niche scenarios with complex requirements. It is very powerful but has a steep learning curve.

SQL/XML for querying XML data with XMLTABLE
SQL/XML is a standard defined by the SQL:2003 specification, which extends SQL with XML-related capabilities. It allows the integration of XML and SQL, enabling you to query and manipulate XML data using SQL.
Oracle’s SQL/XML functions provide native tools for reading XML data in Oracle.
Creating XML from tables
You can also go the other way and use the SQL/XML functions to create XML data from Oracle tables, i.e. convert a relational format to a hierarchical format.
With Oracle’s support for SQL/XML functions, developers can manage XML data alongside traditional relational data operations.
Below, you’ll find some of the most useful SQL/XML functions:
XMLQuery : This function extracts data from XML documents using XPath expressions within SQL queries.
XMLTable : This function enables you to extract data from XML documents and present it in a relational format.
XMLExists : This function checks whether an XML document contains nodes that match a specified XPath expression. It returns TRUE if at least one node exists, otherwise FALSE.
XMLAgg : This function aggregates multiple elements into a single XML element. It is commonly used with a subquery to generate XML output.
XMLCast : This function converts an XML value into another data type, such as VARCHAR2, NUMBER, DATE, etc. It’s useful for converting XML data into a more conventional data type for further processing or querying.
Examples of using XMLTABLE to query Oracle XML
In this hands-on example we use the XMLTABLE function to read XML data on the fly and flatten it into a denormalised structure. We then create database Views for reusability and sharing with other users.
XMLTABLE syntax
XMLTable maps the result of an XPath expression into rows and columns in an Oracle table. You can use it to break down an XML document into its parts and retrieve those parts in a tabular format.
XMLTABLE is super easy to use. The syntax is as follows
|
1 2 3 4 5 6 |
XMLTable( xmlnamespaces_clause, xpath_expression PASSING xml_data COLUMNS column_definition ) |
xmlnamespaces_clause: Optional. Defines XML namespaces used in the xpath_expression.
xpath_expression: An XPath expression that specifies the part of the XML to be processed.
xml_data: The XML data being queried.
column_definition: Defines the columns and their data types for the result set.
Let’s see XMLTABLE in action. We will use the sample XML file from the section about Loading XML.
Since the sample XML file contains multiple branches, we’ll have to create one view per XML branch.
View for ‘University/Faculty/Department’ branch
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
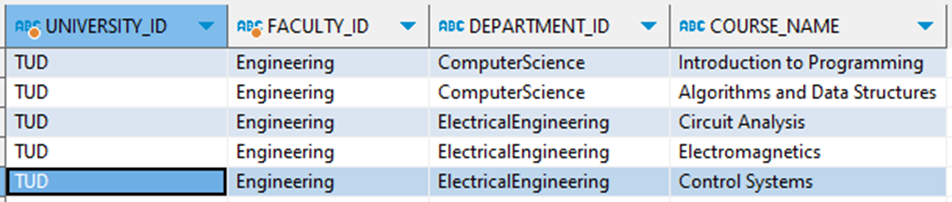
CREATE OR REPLACE VIEW dept_courses AS SELECT uni."id" as university_id, faculty."id" as faculty_id, depts."id" as department_id, courses."Course" as course_name FROM xml_tab, XMLTABLE( '/University' PASSING XML_DATA COLUMNS "id" VARCHAR(50) PATH '@id', faculty XMLTYPE PATH 'Faculty' ) uni, XMLTABLE( '/Faculty' PASSING uni.faculty COLUMNS "id" VARCHAR(50) PATH '@id', depts XMLTYPE PATH 'Department' ) faculty, XMLTABLE( '/Department' PASSING faculty.depts COLUMNS "id" VARCHAR(50) PATH '@id', courses XMLTYPE PATH 'Course' ) depts, XMLTABLE( '/Course' PASSING depts.courses COLUMNS "Course" VARCHAR(50) PATH '.' ) courses; |
Query the view :
|
1 |
SELECT * FROM dept_course |
Output-
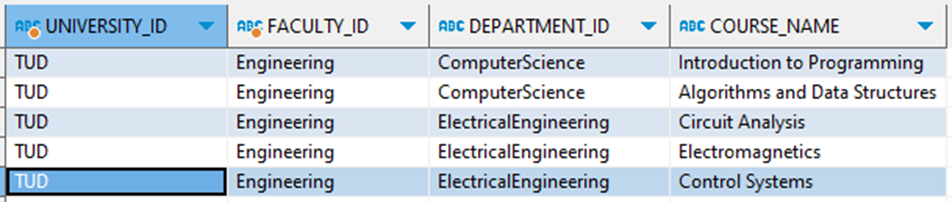
View for ‘University/Faculty/ResearchGroup’ branch
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
CREATE OR REPLACE VIEW researchgrp_projects AS SELECT uni."id" as university_id, faculty."id" as faculty_id, grp."id" as research_group_id, projects."Project" as Project_name FROM xml_tab, XMLTABLE( '/University' PASSING XML_DATA COLUMNS "id" VARCHAR(50) PATH '@id', faculty XMLTYPE PATH 'Faculty' ) uni, XMLTABLE( '/Faculty' PASSING uni.faculty COLUMNS "id" VARCHAR(50) PATH '@id', grp XMLTYPE PATH 'ResearchGroup' ) faculty, XMLTABLE( '/ResearchGroup' PASSING faculty.grp COLUMNS "id" VARCHAR(50) PATH '@id', projects XMLTYPE PATH 'Project' ) grp, XMLTABLE( '/Project' PASSING grp.projects COLUMNS "Project" VARCHAR(50) PATH '.' ) projects; |
Query the view :
|
1 |
SELECT * FROM researchgrp_projects; |
Output-
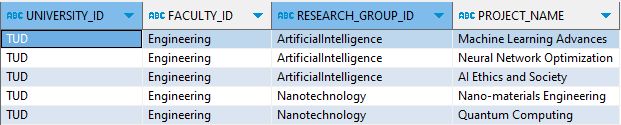
View for ‘University/AdministrativeUnit’ branch
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
CREATE OR REPLACE VIEW admin_service AS SELECT uni."id" as university_id, adminunit."id" as administrative_unit_id, services."Service" as service FROM xml_tab, XMLTABLE( '/University' PASSING XML_DATA COLUMNS "id" VARCHAR(50) PATH '@id', adminunit XMLTYPE PATH 'AdministrativeUnit' ) uni, XMLTABLE( '/AdministrativeUnit' PASSING uni.adminunit COLUMNS "id" VARCHAR(50) PATH '@id', services XMLTYPE PATH 'Service' ) adminunit, XMLTABLE( '/Service' PASSING adminunit.services COLUMNS "Service" VARCHAR(50) PATH '.' ) services; |
Query the view:
|
1 |
SELECT * FROM admin_service; |
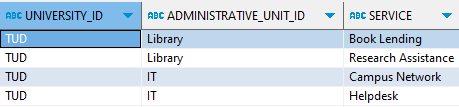
Important note
XMLTABLE only works with the XMLTYPE data type. You can convert and typecast XML data stored in a CLOB to XMLTYPE by using XMLTYPE().
Example of using XMLTYPE()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
CREATE OR REPLACE VIEW admin_service AS SELECT uni."id" as university_id, adminunit."id" as administrative_unit_id, services."Service" as service FROM xml_tab, XMLTABLE( '/University' PASSING XMLTYPE(XML_DATA) COLUMNS "id" VARCHAR(50) PATH '@id', adminunit XMLTYPE PATH 'AdministrativeUnit' ) uni, XMLTABLE( '/AdministrativeUnit' PASSING uni.adminunit COLUMNS "id" VARCHAR(50) PATH '@id', services XMLTYPE PATH 'Service' ) adminunit, XMLTABLE( '/Service' PASSING adminunit.services COLUMNS "Service" VARCHAR(50) PATH '.' ) services; |
Oracle EXTRACT and EXTRACTVALUE
Important note: Both EXTRACT and EXTRACTVALUE are deprecated and only available for backward compatibility. We do not recommend using EXTRACT or EXTRACTVALUE. We recommend using Oracle’s XMLTable or for more complex requirements XQuery to extract values from XML documents.
EXTRACT for XML
Using an XPATH expression in EXTRACT gives you a specific fragment of XML data.
Syntax :-
|
1 |
EXTRACT(XMLType_instance, XPath_string [, namespace_string ]) |
Example :-
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
CREATE TABLE XML_TABLE( xml_data XMLTYPE ); INSERT INTO XML_TABLE VALUES( '<students> <student id = "101"> <fname>John</fname> <lname>Doe</lname> <marks>98</marks> </student> </students>'); SELECT EXTRACT(XML_DATA, '/students/student/@id') ID, EXTRACT(XML_DATA, '/students/student/fname') FIRST_NAME, EXTRACT(XML_DATA, '/students/student/lname') LAST_NAME, EXTRACT(XML_DATA, '/students/student/marks') MARKS FROM XML_TABLE; |
EXTRACT returns four XML fragments, e.g. <lname>Doe</lname> for the LAST_NAME

The EXTRACT function can be used to extract XML fragments from XML data stored as either XMLType or CLOB.
EXTRACT also supports XML namespaces
EXTRACTVALUE
Use the EXTRACTVALUE function to extract the values of XML elements or attributes.
Syntax
|
1 |
EXTRACTVALUE(XMLType_instance, XPath_string [, namespace_string ]) |
This function takes two main arguments: an XMLType or CLOB instance and an XPath expression. The XPath expression specifies the path to the desired node within the XML document. The function returns the value of the node, which must be a single node and either a text node, attribute, or element.
Example
|
1 2 3 4 5 6 |
SELECT EXTRACTVALUE(XML_DATA, '/students/student/@id') ID, EXTRACTVALUE(XML_DATA, '/students/student/fname') FIRST_NAME, EXTRACTVALUE(XML_DATA, '/students/student/lname') LAST_NAME, EXTRACTVALUE(XML_DATA, '/students/student/marks') MARKS FROM XML_TABLE; |

Using the @ operator you can extract the value of an element attribute: EXTRACTVALUE(XML_DATA, ‘/students/student/@id’) ID
The EXTRACTVALUE function can be used to extract values from XML data stored as either XMLType or CLOB.
EXTRACTVALUE also supports XML namespaces.
Example of using EXTRACTVALUE with XML namespaces
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
CREATE TABLE XMLNS_TABLE( xml_data CLOB ); INSERT INTO XMLNS_TABLE VALUES( '<root xmlns:f="https://www.w3schools.com/furniture"> <f:table> <f:name>African Coffee Table</f:name> <f:width>80</f:width> <f:length>120</f:length> </f:table> </root>' ); SELECT EXTRACTVALUE(XMLTYPE(XML_DATA), '/root/f:table/f:name','xmlns:f="https://www.w3schools.com/furniture"') Name, EXTRACTVALUE(XMLTYPE(XML_DATA), '/root/f:table/f:width','xmlns:f="https://www.w3schools.com/furniture"') Width, EXTRACTVALUE(XMLTYPE(XML_DATA), '/root/f:table/f:length','xmlns:f="https://www.w3schools.com/furniture"') Length FROM XMLNS_TABLE; |

You can nest EXTRACT and EXTRACTVALUE
|
1 2 3 4 5 6 |
SELECT EXTRACT(XML_DATA, '/students/student/@id') ID, EXTRACTVALUE(EXTRACT(XML_DATA, '/students/student/fname'),'/fname') FIRST_NAME, EXTRACTVALUE(EXTRACT(XML_DATA, '/students/student/lname'),'/lname') LAST_NAME, EXTRACTVALUE(EXTRACT(XML_DATA, '/students/student/marks'),'/marks') MARKS FROM ADMIN1.XML_TABLE; |

XQuery
XQuery is a functional query language for finding and extracting elements and attributes from XML documents. Think of XQuery as SQL for XML.
When to use XQuery and when to use SQL/XML
XQuery and SQL/XML functions are useful tools for handling XML data in Oracle. XQuery is perfect for complex XML manipulation. It gives precise control over elements and relationships, making it suitable for complex hierarchical structures. On the other hand, SQL/XML functions are optimal for integrating XML tasks into relational databases, particularly for simpler processing alongside traditional SQL queries. XQuery is also recommended if you have XQuery wizards on your team as you will not have the steep learning curve typically associated with XQuery.
In summary, use XQuery for complex XML conversion projects. In particular if you have in-house skills. Use SQL/XML functions such as XMLTABLE for less complex requirements and for scenarios where you need to mix and match with SQL.
XMLIndex for fast XML querying
Oracle’s XMLIndex feature is designed to improve the performance of queries on XML documents that are stored in an XML column, making it beneficial when dealing with XML data. Unlike traditional relational indexes, which rely on specific table columns for index keys, XMLIndex uses a specific XML pattern expression to index paths and values within XML documents contained in a single column. By allowing users to create indexes on XMLType columns, XMLIndex enables quicker retrieval and processing of XML data through optimised query execution paths. However, XML indexes may not be necessary for small XML documents or situations where query performance is not a critical concern.
XMLIndex and CLOB
XMLIndex only works with columns of the XMLType. Another reason to store your XML files and data in the XMLType data type.
Using an XML Index is particularly useful for the schema on read scenario as it can speed up your queries.
Example for creating an XMLIndex
|
1 2 |
CREATE INDEX xml_data_index ON xml_tab(xml_data) INDEXTYPE IS XDB.XMLIndex; |
Converting XML to Oracle tables
In the previous section we explored how to query and read XML data stored inside an Oracle table. We exposed the data as database Views to consumers such as data analysts.
In this section we will look at how we can convert hierarchical XML and write it to relational Oracle tables.
Once converted, the relational tables will simplify the process for data consumers to query the extracted and parsed data using SQL.
We first create the DDL for the target tables and then use the Views we created in the previous section to INSERT the data to these tables.
They are then ready to be queried using SQL.
Convert XML branch ‘University/Faculty/Department’ to Oracle table
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE UNIVERSITY.Dept_Table( university_id VARCHAR2(100), faculty_id VARCHAR2(100), department_name VARCHAR2(100), course_name VARCHAR2(100) ) INSERT INTO UNIVERSITY.Dept_Table SELECT * FROM dept_courses; SELECT * FROM UNIVERSITY.Dept_Table; |
Convert XML branch ‘University/Faculty/ResearchGroup’ to Oracle table
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE UNIVERSITY.Research_Groups_Table( university_id VARCHAR2(100), faculty_id VARCHAR2(100), research_group_id VARCHAR2(100), project_name VARCHAR2(100) ) INSERT INTO UNIVERSITY.Research_Groups_Table SELECT * FROM researchgrp_projects; SELECT * FROM UNIVERSITY.Research_Groups_Table; |
Convert XML branch ‘University/AdministrativeUnit’ to Oracle table
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE UNIVERSITY.Admin_Unit_Table( university_id VARCHAR2(100), Administrative_unit_id VARCHAR2(100), service VARCHAR2(100) ); INSERT INTO UNIVERSITY.Admin_Unit_Table SELECT * FROM admin_service; SELECT * FROM UNIVERSITY.Admin_Unit_Table; |
Parsing XML from Oracle CLOB or XMLType
In this section we show you how to use Flexter to parse XML inside an Oracle CLOB or XMLType. Flexter is Sonra’s XML converter.
We first store the XML in a table with either XMLType or CLOB. Unlike Oracle which prefers XMLType, Flexter can work well with XML in either CLOB or XMLType.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
INSERT INTO xml_tab (id, xml_data) VALUES (1, XMLType('<University id="TUD"> <Faculty id="Engineering"> <Department id="ComputerScience"> <Course>Introduction to Programming</Course> <Course>Algorithms and Data Structures</Course> </Department> <Department id="ElectricalEngineering"> <Course>Circuit Analysis</Course> <Course>Electromagnetics</Course> <Course>Control Systems</Course> </Department> <ResearchGroup id="ArtificialIntelligence"> <Project>Machine Learning Advances</Project> <Project>Neural Network Optimization</Project> <Project>AI Ethics and Society</Project> </ResearchGroup> <ResearchGroup id="Nanotechnology"> <Project>Nano-materials Engineering</Project> <Project>Quantum Computing</Project> </ResearchGroup> </Faculty> <AdministrativeUnit id="Library"> <Service>Book Lending</Service> <Service>Research Assistance</Service> </AdministrativeUnit> <AdministrativeUnit id="IT"> <Service>Campus Network</Service> <Service>Helpdesk</Service> </AdministrativeUnit> </University> ')); |
In a first step we create a data flow with the logical target schema
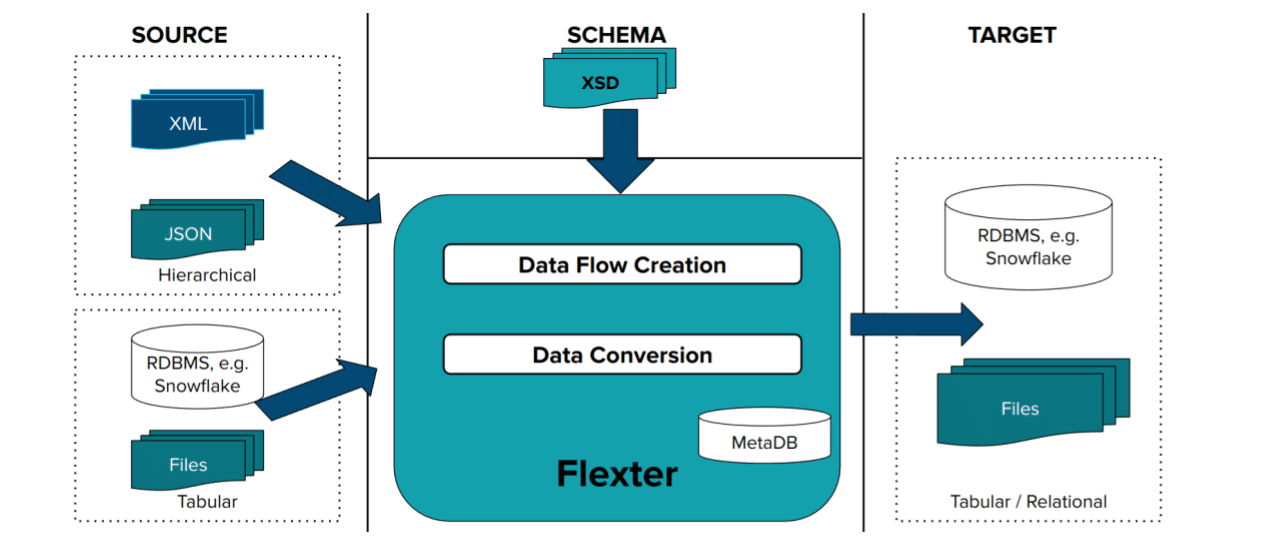
We use Flexter’s command line tool to generate the relational target schema. In case you are wondering, Flexter also ships with an API. We tell Flexter that it can find the XML to generate the schema in table (-T) xml_tab and column xml_data (-C). We also tell Flexter to use the Elevate optimisation algorithm when deriving the target schema.
|
1 |
xml2er -g1 “jdbc:oracle:thin:@//165.23.245.239:1523/flexter” -U <user> -P <password> -T xml_tab -C xml_data |
The output from this command is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# schema schema: 5964 logical: 2405 job: 22128 # statistics startup: 1895 ms load: 160 ms xpath stats: 9474 ms doc stats: 1609 ms parse: 123 ms write: 9232 ms xpaths: 12 | map:0%/0 new:100%:12 documents: 1 | suc:100%/2 part:0%/0 fail:0%/0 size:4.2KB |
The important information is the schema ID. This is the ID of the relational target schema which we will use in the next step when we convert the data.
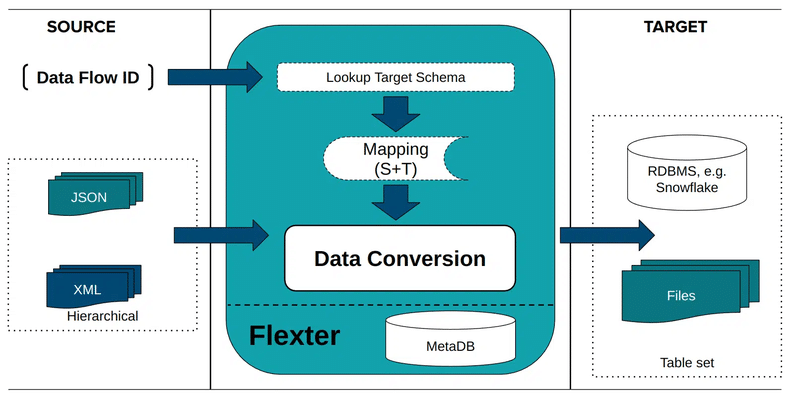
This command tells Flexter to take the XML data in table xml_tab and column xml_data and use the schema ID from the previous step to convert the XML.
|
1 |
xml2er -x 5964 -S o “jdbc:oracle:thin:@//165.23.245.239:1523/flexter” -U <user> -P <password> -T xml_tab -C xml_data |
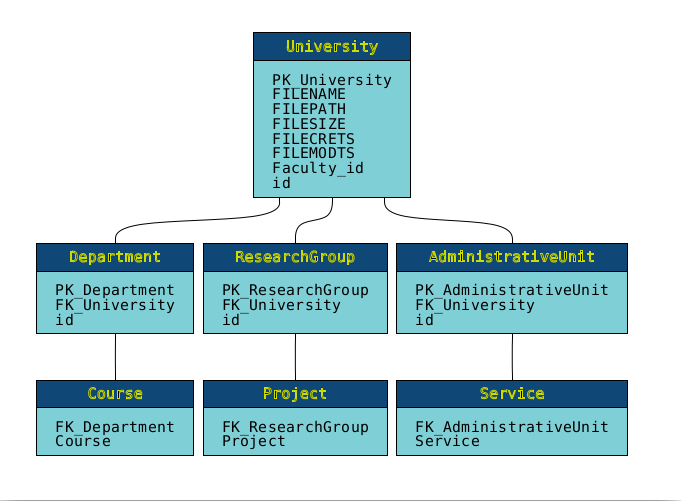
Flexter generates an ER diagram of the processed data.
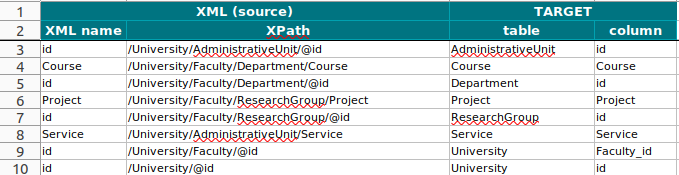
It also generates a source to target map for data lineage
No code XML conversion to Oracle
For a more detailed example of using Flexter to automatically convert XML refer to our post on No Code XML Conversion to Oracle.
Automatically loading and converting XML to Oracle tables
We have seen how we can manually convert XML to Oracle tables by writing code. I have also shown you how to use Flexter to fully automate the process.
XML conversion tools such as Flexter automate the entire process of converting XML to Oracle tables without any manual intervention. XML converters eliminate the need to load the XML data to Oracle first. They automate schema creation, mapping, and error handling, offering a fully automated solution compared to traditional methods using Oracle’s SQL/XML extensions.
Here is a summary comparison of manual versus automated XML conversion on Oracle.
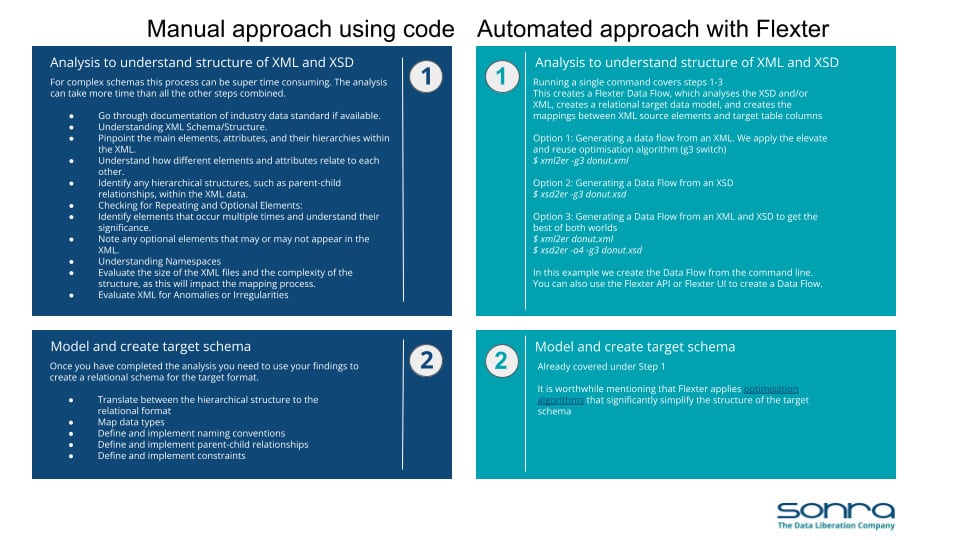
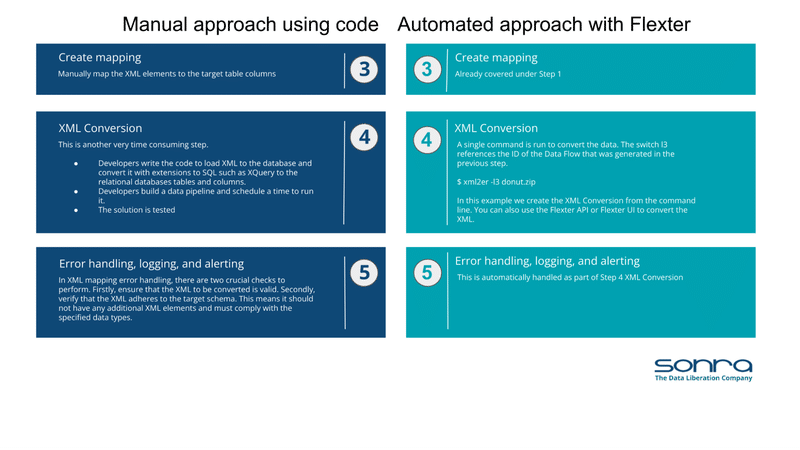

You can download the comparison as a PDF
Manual vs. automated conversion
In contrasting manual XML conversion techniques with automated processes facilitated by tools like Flexter, the advantages of automation become clear:
- Complexity Management: Automated processes handle any level of XML and XSD complexity efficiently.
- Accelerated Deployment: By automating the XML conversion lifecycle—including analysis, schema generation, and mappings—data is swiftly prepared for decision-making.
- Risk Reduction: The automation of XML parsing mitigates the risk of project delays or budget overruns, especially in complex projects based on industry standards.
- Consistency and Accuracy: Automated parsing ensures consistent and precise execution, significantly lowering the potential for human error.
- Scalability: XML automation tools are designed to meet any service level agreement (SLA) and handle large volumes of XML data.
- User Accessibility: The user-friendly interfaces of automated tools reduce the dependency on specialised XML skills, which are scarce and represent a vulnerability for projects.
- Refactoring and schema evolution: In case your XML or XSD changes XML converters can automatically evolve your schema. You don’t have to go through a lengthy refactoring process.
When to use automated XML conversion:
While automated conversion processes have clear benefits, they must be balanced against the costs of licensing tools like Flexter. For simple requirements or occasional queries, an XML automation tool may not be necessary. However, conversion software becomes invaluable when dealing with complex XML/XSD structures, processing large or numerous types of XML files, working under strict SLAs, or operating without in-house XML expertise.
Flexter. Your solution for complex XML Conversion
If you’re facing challenges with complex XML structures, large file sizes, or tight project deadlines, consider exploring Flexter’s capabilities. Our free online version offers a glimpse into the efficiency and effectiveness of XML conversion software. For more complex inquiries, our experts are ready to discuss your XML conversion needs in detail, ensuring your XML to Oracle conversion project is a success.
Further reading
Oracle
Converting the NDC XML data standard to Oracle without writing a single line of code
Complete Oracle XSD Guide – Register XSD & Validate XML
XML conversion
XML Converters & Conversion – Ultimate Guide (2026)
Converting XML and JSON to a Data Lake
How to Insert XML Data into SQL Table?
The Ultimate Guide to XML Mapping in 2026
Optimisation algorithms for converting XML and JSON to a relational format
Re-use algorithms for converting XML and JSON to a relational format
Flexter

{kind=link}